









ICML 2019 《Unsupervised Neural Multi_document Abstractive Summarization of Reviews》
对于文本摘要领域来说,已有的抽象式摘要方法(abstractive summarization)广泛的依赖于Seq2Seq模型和配对数据集,以及pointer-generator网络、copy机制和coverage机制等的应用。但在实际的应用场景中,我们并不总是可以拥有配对的数据,因此如何采用无监督的方式来生成摘要成为了一个亟待解决的问题。
当我们无法知道数据所满足的分布,或者更详细的说我们无法知道文本对应的摘要应该满足怎样的形式和分布时,传统的基于似然估计的语言建模方式就无法取得理想的效果。回顾计算机视觉中各种强大的生成模型,例如auto-encoder、VAE和GAN等,当我们的decoder或者generator能力足够强时,即使输入的是随机的表示也可以生成较高质量的图像。
因此将其推广到自然语言处理中来考虑,如果encoder有很强的信息抽取能力,那么输入的表示就应该包含输入中的大部分重要信息;那么decoder也足够好的话,生成的结果自然就不会很差。因此,作者借鉴这样的思想,在本文中利用auto-encoder来获取输入的表示,希望对应的decoder可以从中生成对应的摘要。
模型架构如下所示:

下面我们抛去详细的数学表示,而专注于模型中表达的思想。模型整体上可以分为两部分:
- auto-encoder module:希望可以学到关于输入好的表示向量
- summarization module:希望利用习得的表示生成摘要,同时保证在语义上与输入的文本接近
因为这里没有对应于文本的真实摘要,我们无法使用有监督的方式来评估生成的结果。因此,这里引入了两个损失项来迫使Encoder学到好的表示。其中 l r e c l_{rec} lrec (Autoencoder Reconstruction Loss)负责比较利用习得的表示重构后的文本和输入文本,希望两者之间的差别越小越好,不管是从词的组成还是语义。 l s i m l_{sim} lsim(Average Summary Similarity)负责比较生成的摘要重新通过Encoder编码后得到的表示和Encoder从输入中学到的表示,因为Decoder是利用Encoder学到的表示加一些变换后的结果来生成摘要,那么两者的差距自然不应很大。
假设此时的输入为 x x x,它通过Encoder得到的表示记为 ϕ E ( x ) = [ h , c ] = z \phi_{E}(x) = [h,c]=z ϕE(x)=[h,c]=z,其中 h h h表示LSTM最后的隐状态, c c c表示memory cell中的结果,Auto-encoder中的Decoder根据 z z z来计算 p ( x ∣ z ) = ϕ D ( z ) p(x|z) = \phi_{D}(z) p(x∣z)=ϕD(z)来重构输入。而在Summarization module部分,Decoder的输入 z ‾ \overline{z} z为对 h h h和 c c c求平均后的结果,即 z ‾ = [ h ‾ , c ‾ ] \overline{z}=[\overline{h},\overline{c}] z=[h,c],生成的摘要记为 ϕ D ( z ‾ ) ∼ s \phi_{D}(\overline{z}) \sim s ϕD(z)∼s。
最后来看一下损失项的设置,其中
l
r
e
c
l_{rec}
lrec 的表示为:
l
r
e
c
(
{
x
1
,
x
2
,
.
.
.
,
x
k
}
,
ϕ
E
,
ϕ
D
)
=
∑
j
=
1
k
l
c
r
o
s
s
_
e
n
t
r
o
p
y
(
x
j
,
ϕ
D
(
ϕ
E
(
x
j
)
)
)
l_{rec}(\{x_{1},x_{2},...,x_{k}\},\phi_{E},\phi_{D})=\sum_{j=1}^k l_{cross\_entropy}(x_{j},\phi_{D}(\phi_{E}(x_{j})))
lrec({x1,x2,...,xk},ϕE,ϕD)=j=1∑klcross_entropy(xj,ϕD(ϕE(xj)))
l
s
i
m
l_{sim}
lsim的表达式为:
l
s
i
m
(
{
x
1
,
x
2
,
.
.
.
,
x
k
}
,
ϕ
E
,
ϕ
D
)
=
1
k
∑
j
=
1
k
d
c
o
s
(
h
j
,
h
s
)
l_{sim}(\{x_{1},x_{2},...,x_{k}\},\phi_{E},\phi_{D})=\frac{1}{k}\sum_{j=1}^k d_{cos}(h_{j},h_{s})
lsim({x1,x2,...,xk},ϕE,ϕD)=k1j=1∑kdcos(hj,hs)
其中summarization module中的Encoder生成的过程表示为
ϕ
E
=
[
h
s
,
c
s
]
\phi_{E}=[h_{s},c_{s}]
ϕE=[hs,cs]。那么完整的损失函数即
l
m
o
d
e
l
=
l
r
e
c
+
l
s
i
m
l_{model}=l_{rec}+l_{sim}
lmodel=lrec+lsim。
由于没有真实的配对摘要的存在,我们无法使用teacher forcing方法来进行解码,因此作者这里使用的是Straight Through Gumbel-Softmax trick来从类别分布中进行采样(本文中是词汇表上的softmax分布),并允许梯度在这个离散生成过程中反向传播,同时避免了teacher forcing中的exposure bias问题。
在模型评估中,同样受限于真实摘要的缺失,我们无法使用ROUGE等指标直接进行评估。因此,作者这里使用了三种自动化统计指标和人工判断来评估模型的效果。
-
Rating accuracy:直觉上认为一个好的摘要应该能完全反映文中所表达的情感,因此这里使用了CNN-based分类模型对结果进行评级,从而来检查分类器预测的最高的级别是否和平均等级相等,它的表示为:
Rating accuracy = 1 N ∑ i = 1 N [ CLF ( s ( i ) ) = = round ( 1 k ∑ j = 1 k ) r j ( i ) ] \text{Rating accuracy} = \frac{1}{N}\sum_{i=1}^N [\text{CLF}(s^{(i)})==\text{round}(\frac{1}{k}\sum_{j=1}^k)r_{j}^{(i)}] Rating accuracy=N1i=1∑N[CLF(s(i))==round(k1j=1∑k)rj(i)] -
Word Overlap score:虽然ROUGE值高的摘要不一定是理想的,但是ROUGE值低的摘要一定存在问题。因此这里使用ROUGE-1来计算词的交叠率,它具体的表达式为:
Word Overlap score = 1 N ∑ i = 1 N [ 1 k ∑ j = 1 k ROUGE ( s ( i ) , r j ( i ) ) ] \text{Word Overlap score }=\frac{1}{N}\sum_{i=1}^N[\frac{1}{k}\sum_{j=1}^k \text{ROUGE}(s^{(i)},r_{j}^{(i)})] Word Overlap score =N1i=1∑N[k1j=1∑kROUGE(s(i),rj(i))] -
Negative Log-likelihood:为了保证生成摘要的流畅性,这里同样使用生成过程中的NLI进行评估
-
Human Evaluation:用于评估生成摘要情感的表达、信息的包含、语法规范、冗余度等
实验中最主要的就是对于模型的消融实验

实验结果如下

从结果中我们可以看出Early Cosine Loss对于模型的效果影响较好,这也符合我们的直觉。Reconstruction cycle loss有一定的作用,当然完整的模型自然效果最好。
详细的实验设置和结果可见原文。
EMNLP 2018 《Learning to Encode Text as Human-Readable Summaries using Generative Adversarial Networks》
本文同样是使用了Auto-encoder的信息压缩能力来获取输入文本的表示,希望在无配对数据集的情况下实现无监督方式的摘要生成。其中auto-encoder包含generator和reconstructor两部分,generator采用Seq2Seq的形式实现摘要的生成,reconstructor实现从generator的输出出发来重构输入文本。同时为了保证生成结果的可读性,这里加入了discriminator来约束generator的输出。
因此整个模型可以看做是auto-encoder和GAN的结合体,auto-encoder负责学习输入文本的表示并生成相应的结果,GAN负责使得生成的结果可读性良好。它在思想上和上一篇文章是类似的,至少在auto-encoder部分可以认为是完全相同的,只是在另外的约束上设置不同。
模型架构如下所示:

整体上可以看成由G(Generator)、D(Discriminator)和R(Reconstructor)三部分组成。G的输入为需要处理的文本,输出为生成的摘要;D的输入为G生成的结果和人写的句子(这里并不是对应于G输入文本的真实摘要,只是人写的句子),输入为判别的结果;R的输入为G的输出结果,输出为重构后的文本。
更详细的模型组成如下所示:

假设G的输入为 x = { x 1 , x 2 , . . . , x t , . . . , x T } x = \{x_{1},x_{2},...,x_{t},...,x_{T}\} x={x1,x2,...,xt,...,xT},其中 x i x_{i} xi表示输入中的词。G的输出记为 G ( x ) = { y 1 , y 2 , . . . , y n , . . . , y N } G(x) = \{y_{1},y_{2},...,y_{n},...,y_{N}\} G(x)={y1,y2,...,yn,...,yN},其中 y i y_{i} yi表示 x i x_{i} xi对应输出的词分布。
Auto-encoder
这一部分由G和R组成,G的输出为
y
y
y,但是它不直接作为R的输入,而是将从
y
i
y_{i}
yi中进行采样得到采样后结果
y
s
=
{
y
1
s
,
y
2
s
,
.
.
.
,
y
N
s
}
y^s=\{y_{1}^s,y_{2}^s,...,y_{N}^s\}
ys={y1s,y2s,...,yNs}做为R的输入,将R重构后的文本记为
x
^
\hat{x}
x^,那么重构损失表示为:
R
l
o
s
s
=
∑
k
=
1
K
l
s
(
x
,
x
^
)
R_{loss} = \sum_{k=1}^Kl_{s}(x,\hat{x})
Rloss=k=1∑Kls(x,x^)
那么这一部分的目标自然是最小化
R
l
o
s
s
R_{loss}
Rloss,使得重构后的文本和G的输入越相近越好。其中
R
l
o
s
s
R_{loss}
Rloss有两种设置方式:
- 计算 x x x和 x ^ \hat{x} x^之间的交叉熵损失
- 由于 x ^ \hat{x} x^生成过程中需使用teacher forcing,因此也可以计算生成过程中的负对数似然
这里之所以不直接将G的输出做为R的输入,在文本作者是这样阐述的:We found that if the reconstructor R directly takes G(x) as input, the generator G learns to put the information about the input text in the distribution of G(x), making it difficult to sample meaningful sentences from G(x).即G输出的结果只是包含了输入的主要信息,而难以从中采样得到有意义的句子。
在训练过程中作者发现:由于采样过程的不稳定性,
R
l
o
s
s
R_{loss}
Rloss的变化将变得很大。为了解决这个问题,作者采用了self-critical sequence training,修改后的损失项表示为:
r
R
(
x
,
x
^
)
=
−
l
s
(
x
,
x
^
)
−
(
−
l
a
(
x
,
x
^
)
−
b
)
r^R(x,\hat{x})=-l_{s}(x,\hat{x})-(-l_{a}(x,\hat{x})-b)
rR(x,x^)=−ls(x,x^)−(−la(x,x^)−b)
其中第二项做为baseline,
l
a
(
x
,
x
^
)
l_{a}(x,\hat{x})
la(x,x^)表示的使用argmax函数来从G的输出采样得到的结果和G输入之间的重构损失。
b
b
b这里是为了解决早期奖励偏小的问题,随着模型能力的提升,
b
b
b的值会逐渐减为0。
GAN
Auto-encoder部分中G生成的结果可以认为是表述输入文本大意的有意义的句子序列,但是它的可读性不一定满足要求。因为为了使得G生成的结果是人可读的,这里引入了D来加强限制。D接收生成的序列 y s y^s ys和真实的序列 y r e a l y^{real} yreal,然后希望给真实序列较高的分数,而给生成序列降低的分数,从而达到可以正确判别的效果。
G的损失项表示为:
G
l
o
s
s
=
α
R
l
o
s
s
−
D
l
o
s
s
′
G_{loss}=\alpha R_{loss}-D'_{loss}
Gloss=αRloss−Dloss′
训练过程中使用了两种方法来训练GAN,因此这里D总共有两个。
D
1
D_{1}
D1接收G的输出序列作为输入,使用WGAN的方式进行训练;
D
2
D_{2}
D2接收采样后的离散词序列做为输入,使用RL的方式进行训练。
-
D 1 D_{1} D1:使用CNN-baesd的残差块构建,对应的损失项表示为:
D l o s s = 1 K ∑ k = 1 K D 1 ( G ( x ( k ) ) ) − 1 K ∑ k = 1 K D 1 ( y r e a l ( k ) ) + β 1 1 K ∑ k = 1 K ( △ y i ( k ) D 1 ( y i ( k ) ) − 1 ) 2 D_{loss}=\frac{1}{K}\sum_{k=1}^K D_{1}(G(x^{(k)}))-\frac{1}{K}\sum_{k=1}^K D_{1}(y^{real(k)}) \\ +\beta_{1} \frac{1}{K}\sum_{k=1}^K(\bigtriangleup_{y^{i(k)}}D_{1}(y^{i(k)})-1)^2 Dloss=K1k=1∑KD1(G(x(k)))−K1k=1∑KD1(yreal(k))+β1K1k=1∑K(△yi(k)D1(yi(k))−1)2
其中最后一项表示gradient penalty, β 1 \beta_{1} β1表示缩放系数。对应的 D l o s s ′ = 1 K ∑ k = 1 K D 1 ( G ( x ( k ) ) ) D'_{loss}=\frac{1}{K}\sum_{k=1}^K D_{1}(G(x^{(k)})) Dloss′=K1∑k=1KD1(G(x(k)))
-
D 2 D_{2} D2:使用Self-Critic Adversarial REINGORRCE进行训练,基于单向的LSTM构建,它判别每一时刻输入的好坏

y s y^s ys对应的损失项为
D 2 ( y s ) = 1 N ∑ n = 1 N s n D_{2}(y^s)=\frac{1}{N}\sum_{n=1}^Ns_{n} D2(ys)=N1n=1∑Nsn
那么D对应的损失函数表示为:
D l o s s = 1 K ∑ k = 1 K D 2 ( y s ( k ) ) − 1 K ∑ k = 1 K D 2 ( y r e a l ( k ) ) + β 2 1 K ∑ k = 1 K ( △ y i ( k ) D 2 ( y i ( k ) ) − 1 ) 2 D_{loss}=\frac{1}{K}\sum_{k=1}^K D_{2}(y^{s(k)})-\frac{1}{K}\sum_{k=1}^K D_{2}(y^{real(k)}) \\ +\beta_{2} \frac{1}{K}\sum_{k=1}^K(\bigtriangleup_{y^{i(k)}}D_{2}(y^{i(k)})-1)^2 Dloss=K1k=1∑KD2(ys(k))−K1k=1∑KD2(yreal(k))+β2K1k=1∑K(△yi(k)D2(yi(k))−1)2
在第 i i i个时间步,使用 i − 1 i-1 i−1时间步的score做为baseline。同时为了站在整个生成过程的角度来考虑生成结果的质量,这里加入了折扣系数来进行均衡评估结果。
d i = ∑ j = i N γ j − i r j D d_{i}=\sum_{j=i}^N \gamma^{j-i}r_{j}^D di=j=i∑Nγj−irjD那么对应的G的损失表示为:
G l o s s ′ = − E y i s ∼ P G ( y i s ∣ y 1 s , . . . , y i − 1 s , x ) [ d i ] G'_{loss}=-E_{y_{i}^s \sim PG(y_{i}^s|y_{1}^s,...,y_{i-1}^s,x)}[d_{i}] Gloss′=−Eyis∼PG(yis∣y1s,...,yi−1s,x)[di]
复杂的模型在实验结果中并没有看出明显的提升,而且训练时间极其的长,详细的实验结果可见原文章。
NAACL-HLT 2019 《Latent Code and Text-based Generative Adversarial Networks for Soft-text Generation》
利用GAN做文本生成的模型可以大致分为两类:
- text-based:基于RL的模型,直接从generator中生成文本
- code-based:adversarial auto-encoder(AAE)、adversarial regularized AE(ARAE)等,来学习隐空间的数据流形
本文提出了两种新的text-based的利用GAN做文本生成的新模型:
- Soft-GAN:将auto-encoder得到的关于句子的表示做为soft text
- LATEXT-GAN:一种text-based和code-based的混合GAN模型
Soft-GAN
Soft-GAN原理类似于上面两篇文章中的auto-encoder部分,只不过它所处理的是文本生成任务,因此这里Decoder的输入不再是Encoder输入的表示,而是随机噪声 z z z。
模型架构如下所示:
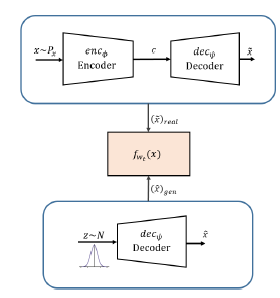
其中上面的auto-encoder部分表示的是训练文本的重构过程,它输出的结果记为 x ~ r e a l \tilde{x}_{real} x~real;而下面的部分是generator使用随机噪声生成的文本 x ^ \hat{x} x^。然后将两者的输入送到discriminator中进行判别,利用D所提供的梯度信息进行参数的更新,直到D无法判别输入的是从训练文本重构的,还是使用随机噪声生成的。
训练过程如下:
-
训练判别器k次,训练decoder 1次,使用损失项 l c r i t i c t l_{critic_{t}} lcritict来增强判别器的能力
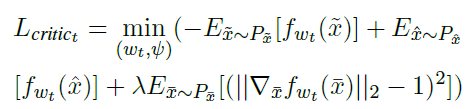
-
Decoder根据 L g e n L_{gen} Lgen来进行训练,通过提高 x ^ \hat{x} x^的表示能力来希望骗过判别器
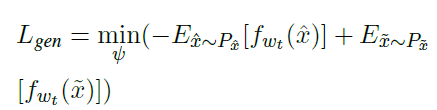
通过这样的方式,decoder最后生成的文本判别器将再无法正确判别,那么即使decoder使用随机的 z z z做为输入也可以生成较好的文本。
LATEXT-GAN Ⅰ
模型架构如下:
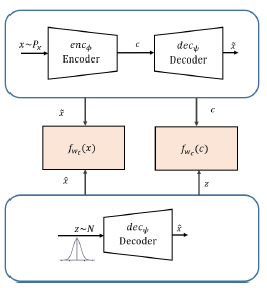
在Soft-GAN的基础上,另加了一个判别器来判别z和c,通过这样的方式进一步的加强z的表示能力,可以理解外多一个层级条件的约束。它遵循下面的训练过程:
-
f w c f_{wc} fwc使用 L c r i t i c c L_{critic_{c}} Lcriticc训练k次,目的是加强它判别z和c的能力
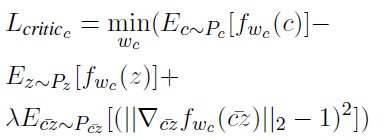
-
使用 L g e n L_{gen} Lgen训练encoder和decoder一次,目的是增强c和 x ^ \hat{x} x^的表示能力,使得它们可以骗过两个判别器
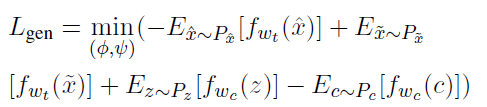
LATEXT-GAN Ⅱ
模型架构如下:
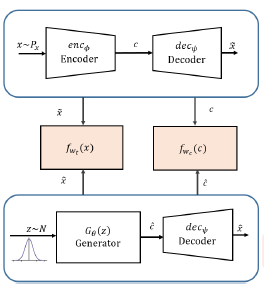
相对于上一个模型,这里的generator不是直接生成 x ^ \hat{x} x^,而是先生成 c ^ \hat{c} c^再得到 x ^ \hat{x} x^。因此和上面唯一不同的在于此时另加的判别器是用来判别c和 c ^ \hat{c} c^。如果 f w c f_{w_{c}} fwc无法正确的判别c和 c ^ \hat{c} c^,说明 G θ G_{\theta} Gθ已经学到了关于 x x x的表示。训练过程如下:
-
f w c f_{w_{c}} fwc使用 L c r i t i c c L_{critic_{c}} Lcriticc训练k次,encoder只训练1次,目的是希望增强 f w c f_{w_{c}} fwc的判别能力
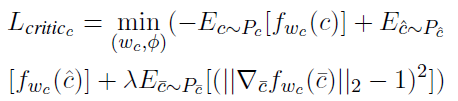
-
generator和decoder使用 L g e n L_{gen} Lgen训练1次,目的是增强 x ^ \hat{x} x^和 c ^ \hat{c} c^的表示能力,希望可以骗过两个判别器。
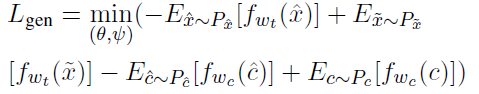
LATEXT-GAN Ⅲ
模型架构如下:
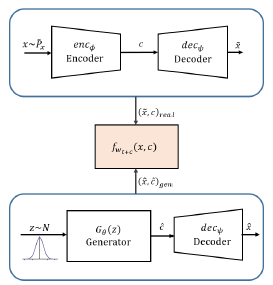
这里不再是使用独立的判别进行不同层级的判别,而是只使用 f w t + c f_{w_{t+c}} fwt+c来判别输入是来自 ( x ^ , c ^ ) (\hat{x},\hat{c}) (x^,c^)还是 ( x ~ , c ) (\tilde{x},c) (x~,c),从而同时训练增强 c ^ \hat{c} c^和 x ^ \hat{x} x^的表示能力,既希望提高generator的表示学习能力,有希望增强decoder的解码能力。训练过程如下:
-
f w t + c f_{w_{t+c}} fwt+c使用 L c r i t i c t + c L_{critic_{t+c}} Lcritict+c训练k次,decoder训练1次,目的是增强 f w t + c f_{w_{t+c}} fwt+c的判别能力

-
generator和decoder使用 L g e n L_{gen} Lgen训练1次,希望可以提高 ( x ^ , c ^ ) (\hat{x},\hat{c}) (x^,c^)的表示能力,从而骗过 f w t + c f_{w_{t+c}} fwt+c
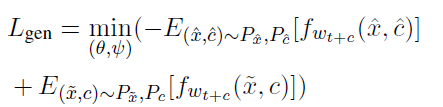
实验部分详见原论文。
最后作者提出了几点工作计划:
- 使用谱归一化等稳定GAN训练的技术来增强模型的稳定性
- 使用RL或self-attention增强模型的生成能力
- 使用attention机制来增强decoder的解码能力
总的来说,上述的几点主要是为了增强模型的性能,而非新的想法的提出~














 423
423











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









