







Random Forest

当我们在阅读Kaggle之类竞赛的相关方案时,GDBT和Random Forest绝对是两个最为常见的机器学习算法。随机森林(Random Forest,RF)属于集成算法中Bagging(Booststrap aggregating)中一个重要的组成部分,Bagging的核心思想在于从总体样本中随机选取一部分进行训练,通过多次这样的结果进行投票获取平均值作为结果输出,从而降低噪声数据对于模型的影响,同时有效的提升准确度。
随机森林是建立在决策树的基础之上的一种集成学习算法,通过群众的智慧来提升分类或是回归的效果。顾名思义,随机森林最重要的两个部分就是随机和森林,森林很好理解,一木为树,很多很多的树就组成了森林;随机这里包含两层含义,随机选择训练样本以及随机选择训练样本用于训练的特征。假设所处理的数据集中包含 N N N个样本,每个样本都拥有 M M M个特征,随机选择训练样本是指:对于每次训练来说,总是有放回的随机抽取训练样本。而随机选择特征是指对于每个被抽取的样本来说,每次训练时总是有放回的随机选择 m m m个特征作,再从这 m m m个特征中选择一个最优的作为单棵决策树进行分裂的依据,这里 m m m要远小于 M M M。
随机有放回的选择样本用于训练很好理解,那么对于随机选择的 m m m个特征来说,如何知道哪一个特征对于最后的效果影响最大呢?在一般的使用中通常是随机选择 2 N 3 \frac{2N}{3} 32N的样本用于训练,剩下的 N 3 \frac{N}{3} 3N的样本用于测试,这 N 3 \frac{N}{3} 3N也通常称为袋外样本(out-of-bag,OOB),训练好的模型在它上面的测试误差称为袋外误差。
随机森林中每一棵树通过以下的方式得到:
- 如果训练集大小为 N N N,对于每棵树而言,随机且有放回地从训练集中的抽取 N N N个训练样本,作为该树的训练集;
- 如果每个样本的特征维度为 M M M,指定一个常数 m < < M m<<M m<<M,随机地从 M 个 M个 M个特征中选取 m m m个特征子集,每次树进行分裂时,从这 m m m个特征中选择最优的;
- 每棵树都尽最大程度的生长,并且没有剪枝过程。
优点:
- 算法准确率高
- 能够在大规模数据集上表现良好
- 能够处理具有高维特征的样本而无需降维
- 能够评估各个特征在分类问题中的重要性
- 在树的生成过程中能够获取到内部生成误差的一种无偏估计
- 对于缺省问题也可以有较好效果
- …
缺点:
- 随机森林已经被证明在某些噪音较大的分类或回归问题上会过拟合
- 对于有不同取值的属性的数据,取值划分较多的属性会对随机森林产生更大的影响
随机森林分类效果的影响因素有哪些?
- 森林中任意两棵树的相关性:相关性越大。分类错误率越高。其实这也很好理解,如果随机选择的两棵树相关性都很高,那么说明随机的机制并没有很好的起到随机的作用,每棵树的效果都差不多,那么集成后的效果也就不会太好
- 每棵树自身的分类能力:自身分类能力越强,森林的错误率就越低,这没啥好说的
- 每棵树随机选择的特征数 m m m的大小:减小 m m m,任意两棵树的相关性和树自身的分类能力都会相应的降低,反之则会增大。因此, m m m的选择对于整个森林的效果至关重要,通过选择 m = log 2 M m = \log_2 M m=log2M
sklearn中随机森林的实现主要包含RndomForestClassifier和RandomForestRegressor两个实现类:
- sklearn.ensemble.RandomForestClassifier:
- n_estimators :随机森林中树的个数 默认为10
- criterion :每一次分裂的标准,有两个可选项,默认的基尼系数(“gini”)和熵(“entropy”
- max_features :每一次生成树时使用的特征数量,默认为“auto”。若为int则为对应的数量;若为float则对应n_estimators*max_features,即此时max_features对应的一个百分比;若为“auto”或“sqrt”,max_features=sqrt(总的特征数);若为“log2”,则为log2(总的特征数);若为None,则为总的特征数。
- max_depth:决策树的最大深度,默认为None
- min_samples_split:每次分裂节点是最小的分裂个数,即最小被分裂为几个,默认为2
- min_samples_leaf:若某一次分裂时一个叶子节点上的样本数小于这个值,则会被剪枝,默认为1
- max_leaf_nodes:最大的叶子节点的个数,默认为None,如果不为None,max_depth参数将被忽
- min_weight_fraction_leaf
- oob_score、bootstrap这个两个参数决定是否使用out-of-bag进行误差度量和是否使用bootstrap进行抽样,默认都是False
- n_jobs:并行计算的个数,默认为1,若为-1,则选择为cores的个数
- random_state: 默认使用np.random
- warm_start :是否热启动,默认为True
- class_weight:权重 默认全为1
# 对比bagging和random forest性能
from sklearn.ensemble import BaggingClassifier
from sklearn.ensemble import RandomForestClassifier
from sklearn.datasets import load_breast_cancer
from sklearn.model_selection import train_test_split
from matplotlib import pyplot as plt
X, y = load_breast_cancer(return_X_y=True)
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.20, random_state=33)
estimators = [1, 5, 10, 20, 40, 60, 80, 100]
bc_score = []
rfc_score = []
for i in estimators:
bc = BaggingClassifier(n_estimators=i, random_state=1)
bc.fit(X_train, y_train)
bc_score.append(bc.score(X_test, y_test))
rfc = RandomForestClassifier(n_estimators=i, max_features="log2", random_state=1)
rfc.fit(X_train, y_train)
rfc_score.append(rfc.score(X_test, y_test))
plt.plot(estimators, bc_score, 's-', color='r', label="Bagging") # s-:方形
plt.plot(estimators, rfc_score, 'o-', color='g', label="RandomForest") # o-:圆形
plt.xlabel("n_estimators") # 横坐标名字
plt.ylabel("mean accuracy") # 纵坐标名字
plt.legend(loc="best")
plt.show()
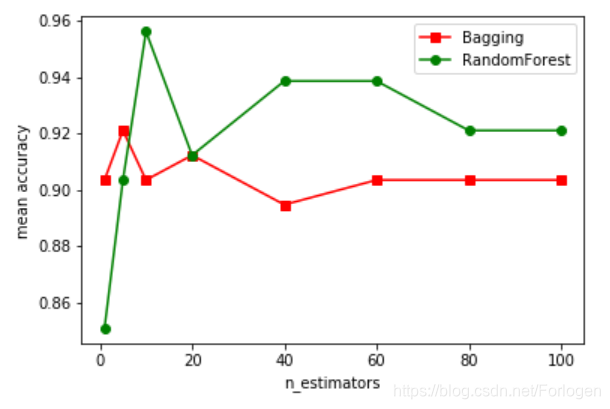
实验结果如下所示,可以看出RandomForestClassifier比BaggingClassifier效果要好一些。
code source

















 1011
1011

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









