








1. 引入
Mysql中的索引(index)本身也是一种数据结构,它主要用来帮助Mysql提高获取数据库中数据的效率。具体来说,索引是一种满足特定查找算法的数据结构,它通过某种方式引用数据,在索引之上就可以实现高级的查找算法。
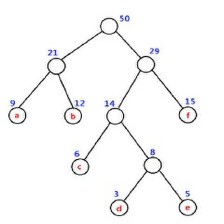
如果理解索引对于数据获取的帮助呢?如果数据库中表的记录条数很少,那么查询的效率往往都很高。然而,在复杂的业务场景下,数据库中表的记录往往非常的多,这时简单的查询操作也会受到表容量的影响,相应的速度往往会很慢。例如,对于查询操作而言,表中的数据是如下图1所示的结构,查询某个记录需要遍历整张表。假设表中记录总条数为N,那么时间复杂度就是 O ( N ) O(N) O(N)。
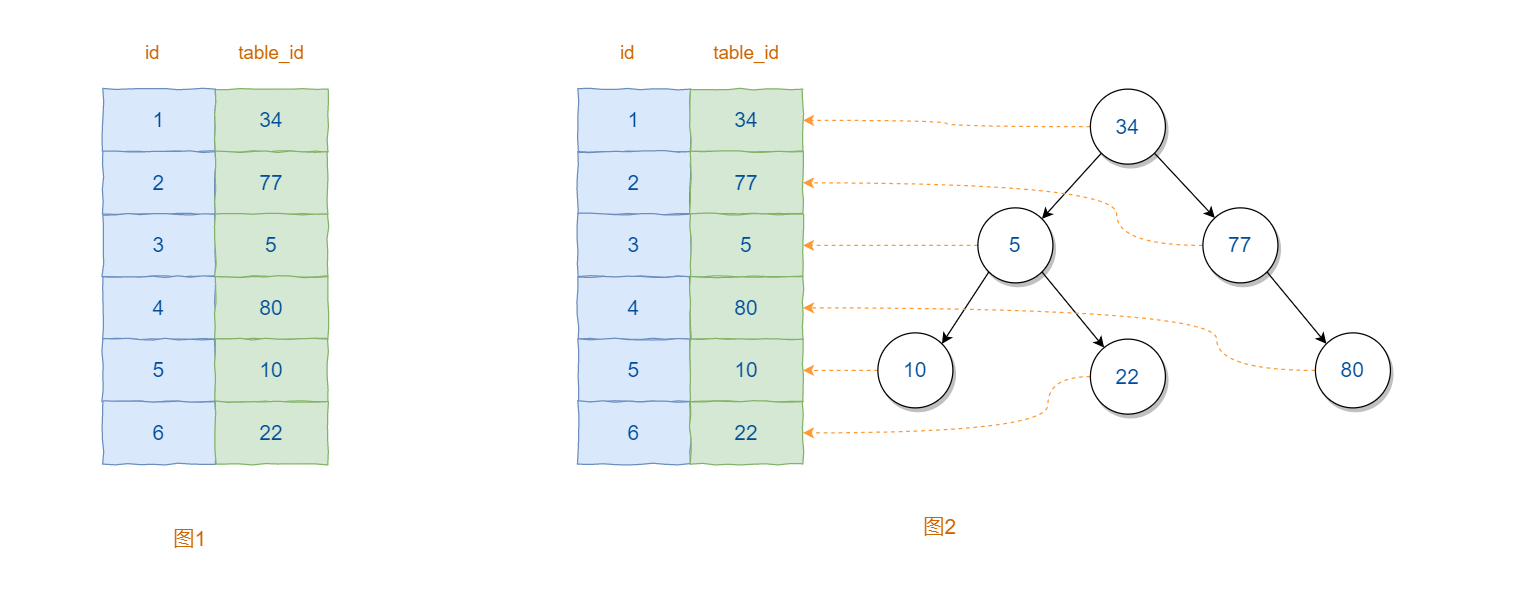
既然线程结构时间复杂度较高,那么根据数据结构的知识可知,如果将其转换为二叉树,那么时间复杂度将变为 O ( log N ) O(\log N) O(logN)。因此,可以根据现有的数据创建如上图2所示的二叉树,其中二叉树中的每个节点分别对应中表中的某一条记录。这样,利用二叉树的特性就可以有效的提升查询的效率。
2. 优缺点
索引虽然可以提升查询数据库的效率,但是它仍有不足之处:
- 索引本身也是一张表,表中保存了主键和索引字段,并指向实体类的记录。通常将索引以索引文件的形式保存在磁盘上,因此,索引也会占用一定的磁盘空间
- 索引降低了更新表的速度,更新表时,MySQL 不仅要保存数据,还要保存一下索引文件,每次更新添加了索引列的字段,都会调整因为更新所带来的键值变化后的索引信息
3. 结构
3.1 类型
索引是在MySQL的存储引擎层中实现的,目前Mysql中支持如下的四种索引类型:
- BTree索引:大部分的存储引擎都支持
- HASH索引:只有MEMORY支持
- R-tree索引,空间索引:主要用于地理空间数据类型
- FUll-text,全文索引:MyISAM和InnoDB都支持
它们之间的比较如下:
| 索引类型 | InnoDB | MyISAM | MEMORY |
|---|---|---|---|
| BETREE | 支持 | 支持 | 支持 |
| HASH | 不支持 | 不支持 | 支持 |
| R-tree | 不支持 | 支持 | 不支持 |
| Full-text | 5.6~ | 支持 | 不支持 |
通常所说的索引都是B+Tree索引。
第一部分说到,类似二叉树的树形结构可以帮助提升查询数据库的效率,那么Mysql中的索引采用的是哪种树呢?下面我们来看一下什么是BTree和B+Tree。
3.2 BTree
BTree也叫多路平衡搜索树,如果熟悉二叉树和二叉搜索树,那么理解BTree并不难。一棵BTree具有如下的特点:
- 树中每个节点最多包含 m m m个孩子
- 除根节点与叶子节点外,每个节点至少有 [ c e i l ( m 2 ) ] [ceil(\frac{m}{2})] [ceil(2m)]个孩子
- 若根节点不是叶子节点,则至少有两个孩子
- 所有的叶子节点都在同一层
- 每个非叶子节点由 n n n个key与 n + 1 n+1 n+1个指针组成,其中 [ c e i l ( m 2 ) − 1 ] < = n < = m − 1 [ceil(\frac{m}{2})-1] <= n <= m-1 [ceil(2m)−1]<=n<=m−1
假设此时 m = 5 m=5 m=5,那么每个叶子节点所包含的key的数量范围是 [ 2 , 4 ] [2,4] [2,4]。当 n > 4 n>4 n>4时,叶子节点中的中间节点需要向上分裂为父节点,两边的节点分裂为它的叶子节点。此时需要对 C N G A H E K Q M F W L T Z D P R X Y S C N G A H E K Q M F W L T Z D P R X Y S CNGAHEKQMFWLTZDPRXYS这个序列构建BTree,构建过程如下所示:
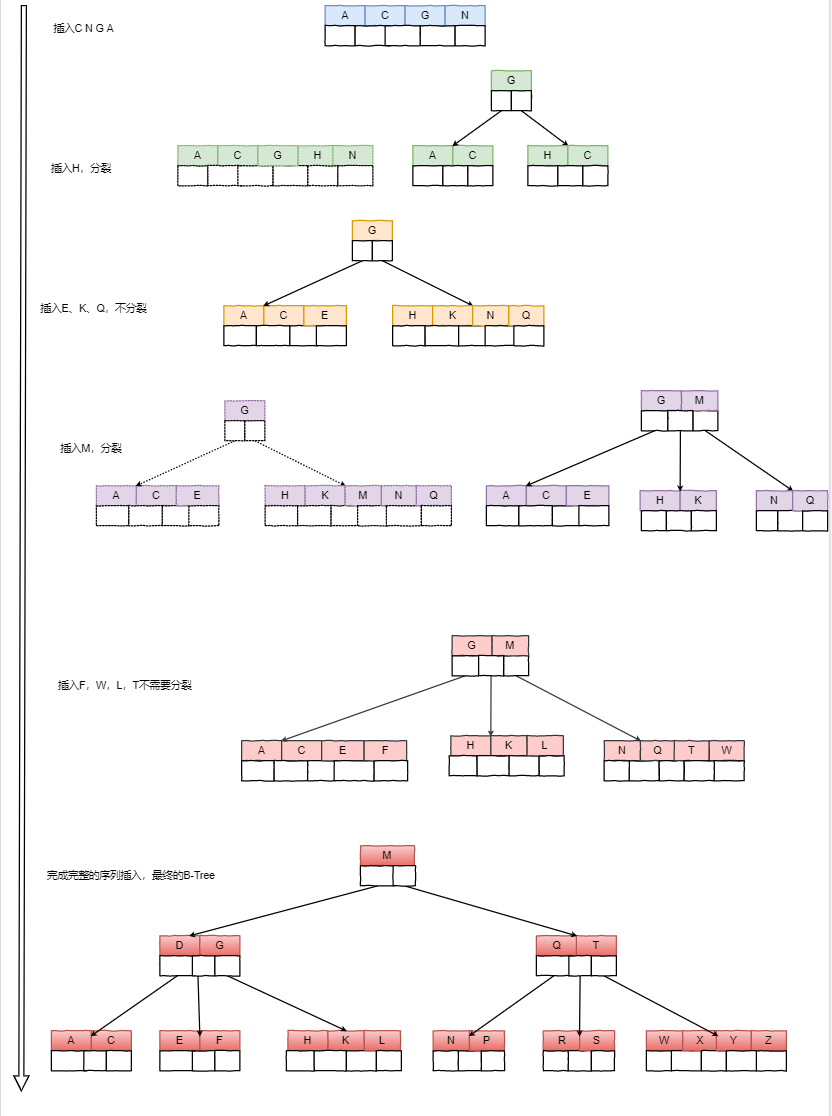
最终的BTree如上所示,BTree构建的过程就是不断插入、不断分裂的过程。根据最终的结果再去理解它的特点,也就一目了然了。
3.3 B+Tree
B+Tree是B-Tree的一个变种,它的特点有所不同,如下所示:
- n n n叉B+Tree最多含有 n n n个key,而BTree最多含有 n − 1 n-1 n−1个key
- B+Tree的叶子节点保存所有的key信息,依key大小顺序排列
- 所有的非叶子节点都可以看作是key的索引部分
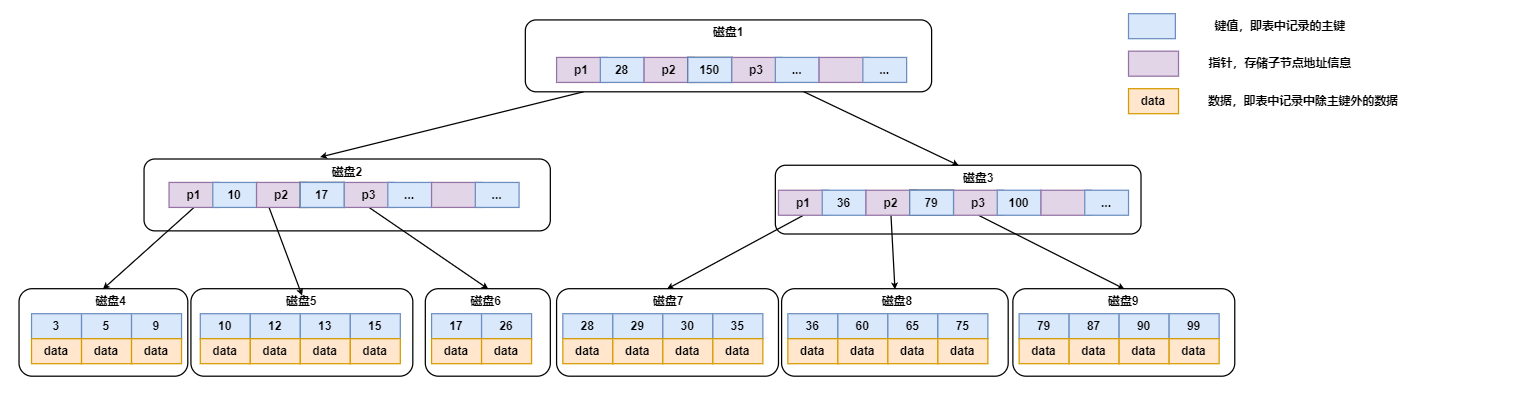
例如,下面的这棵B+Tree中,所有的非叶子节点都是key的索引,但是叶子节点包含了所有的key的信息。因此,如果想要查询某个key的信息,查询路径就必须走到叶子节点,这样查询更加的稳定。
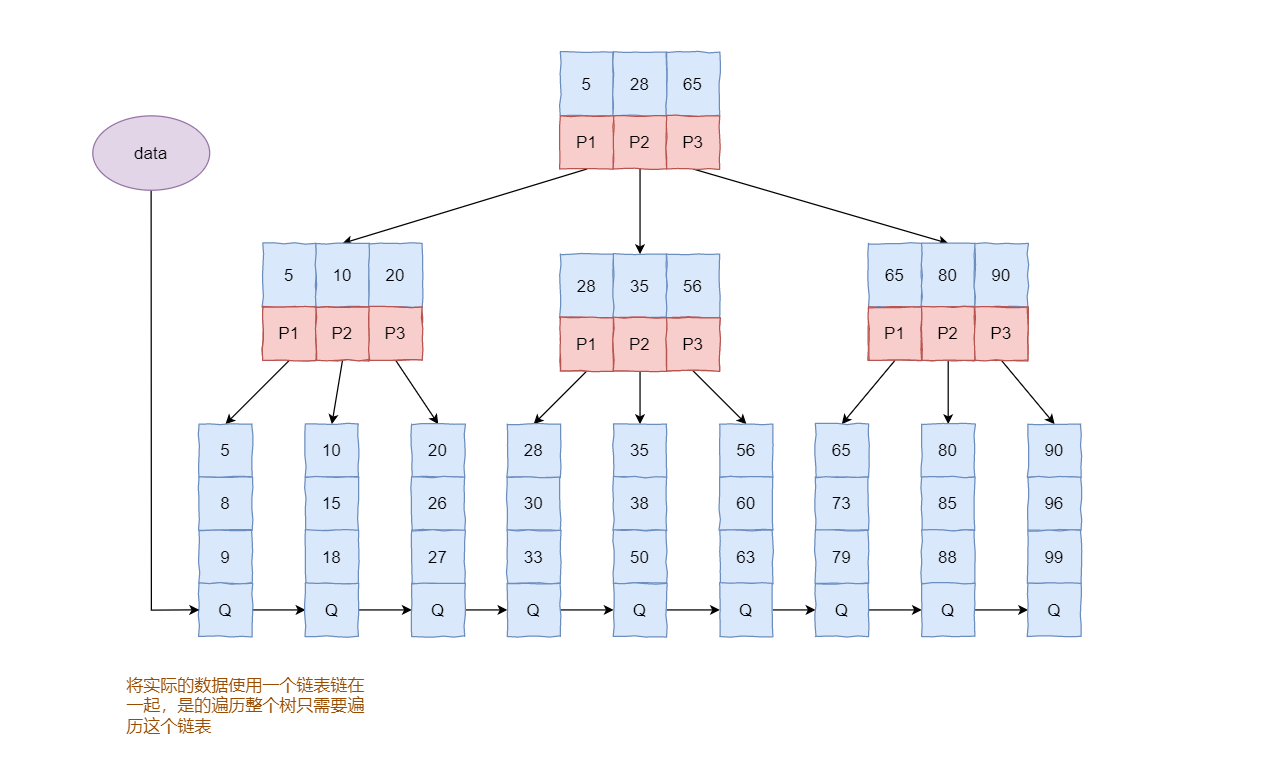
例如,此时想要查找主键为8的记录,从根节点出发找到5 < 8 < 28,因此,它会找到P1指针指向的数据块进行下一步寻找。接着它发现P1指向的块中5 < 8 < 10,继续在该块的P1指针指向的块中寻找;最后走到了叶子节点,找到主键为8的节点,并读取相应的记录。
根据上面B+Tree的特点可知,所有的查询都需要走到叶子节点,使得每个查询的路径长度是一致的,这就是为什么说B+Tree的查询更加稳定。而Mysql中所采用的的B+Tree相对于普通的B+Tree做了进一步优化,增加了一指向相邻叶子节点的链表指针,这样就形成了带有顺序指针的B+Tree,从而进一步提升了区间访问的性能。
为什么说B+树比B树更适合数据库索引?
- B+树的磁盘读写代价更低:B+树的内部节点并没有指向关键字具体信息的指针,因此其内部节点相对B树更小,如果把所有同一内部节点的关键字存放在同一盘块中,那么盘块所能容纳的关键字数量也越多,一次性读入内存的需要查找的关键字也就越多,相对IO读写次数就降低了
- B+树的查询效率更加稳定:由于非叶子节点并不是最终指向文件内容的结点,而只是叶子结点中关键字的索引。所以,任何关键字的查找必须走一条从根结点到叶子结点的路,查询的路径长度相同,导致每一个数据的查询效率相当
- B+树更便于遍历:由于B+树的数据都存储在叶子结点中,分支结点均为索引,方便扫库,只需要扫一遍叶子结点即可。但是B树因为其分支结点同样存储着数据,我们要找到具体的数据,需要进行一次中序遍历按序来扫。所以,B+树更加适合在区间查询的情况
- B+树更适合基于范围的查询:B树在提高了IO性能的同时并没有解决元素遍历时效率低下的问题,而B+树中的叶子节点之间存在着连接的指针,只需要去遍历叶子节点就可以实现整棵树的遍历。而且在数据库中基于范围的查询是非常频繁的,而B树不支持这样的操作或者说效率太低
source : MySQL用B+树(而不是B树)做索引的原因
结合BTree和B+Tree的构建过程,以及各自的特点来理解Mysql中采用B+Tree做索引结构就不难了~
4.分类
索引可以分为如下三类:
- 单值索引:一个索引只包含单个列,一个表中可以有多个单值索引
- 唯一索引:索引列的值必须唯一,但允许有空值
- 复合索引:一个索引包含多个列
5. 使用
5.1 创建索引
SET NAMES utf8mb4;
SET FOREIGN_KEY_CHECKS = 0;
-- ----------------------------
-- Table structure for account
-- ----------------------------
DROP TABLE IF EXISTS `account`;
CREATE TABLE `account` (
`id` int NOT NULL AUTO_INCREMENT,
`name` varchar(40) CHARACTER SET utf8 COLLATE utf8_general_ci NULL DEFAULT NULL,
`money` float NULL DEFAULT NULL,
PRIMARY KEY (`id`) USING BTREE
) ENGINE = InnoDB AUTO_INCREMENT = 17 CHARACTER SET = utf8 COLLATE = utf8_general_ci ROW_FORMAT = Dynamic;
-- ----------------------------
-- Records of account
-- ----------------------------
INSERT INTO `account` VALUES (1, 'Forlogen', 1000);
INSERT INTO `account` VALUES (2, 'Kobe', 1000);
INSERT INTO `account` VALUES (3, 'James', 1000);
SET FOREIGN_KEY_CHECKS = 1;
假设现在所使用的表如下所示:
mysql> select * from account;
+----+----------+-------+
| id | name | money |
+----+----------+-------+
| 1 | Forlogen | 1000 |
| 2 | Kobe | 1000 |
| 3 | James | 1000 |
+----+----------+-------+
3 rows in set (0.02 sec)
此时存在的索引如下,可以看到此时只有系统默认使用主键建立的主键索引:
mysql> show index from account \G
*************************** 1. row ***************************
Table: account
Non_unique: 0
Key_name: PRIMARY
Seq_in_index: 1
Column_name: id
Collation: A
Cardinality: 3
Sub_part: NULL
Packed: NULL
Null:
Index_type: BTREE
Comment:
Index_comment:
Visible: YES
Expression: NULL
1 row in set (0.00 sec)
这里说一下,当创建一张表之后,即时用户没有手动的创建索引,数据库也会自动的创建一个索引,具体情况如下:
- 如果表指定了主键primary key,那么数据库会创建主键索引
- 如果没有指定主键,数据库会创建对不为null的唯一字段上创建唯一索引
- 如果上面的两种情况都不满足,那么数据库会使用一些隐藏信息创建索引,如
_rowid等
我们可以使用如下的命令来根据name属性创建索引:
CREATE [UNIQUE|FULLTEXT|SPATIAL] INDEX index_name
[USING index_type]
ON tbl_name(index_col_name,...)
index_col_name : column_name[(length)][ASC | DESC]
例如:
mysql> create index account_name_index on account(name);
Query OK, 0 rows affected (0.06 sec)
Records: 0 Duplicates: 0 Warnings: 0
通过命令show index from tb_name就可以查看创建的索引:
mysql> show index from account \G
*************************** 1. row ***************************
Table: account
Non_unique: 0
Key_name: PRIMARY
Seq_in_index: 1
Column_name: id
Collation: A
Cardinality: 3
Sub_part: NULL
Packed: NULL
Null:
Index_type: BTREE
Comment:
Index_comment:
Visible: YES
Expression: NULL
*************************** 2. row ***************************
Table: account
Non_unique: 1
Key_name: account_name_index
Seq_in_index: 1
Column_name: name
Collation: A
Cardinality: 3
Sub_part: NULL
Packed: NULL
Null: YES
Index_type: BTREE
Comment:
Index_comment:
Visible: YES
Expression: NULL
2 rows in set (0.00 sec)
此外,还可以使用如下命令创建复合索引:
CREATE INDEX index_name ON tb_name(field1,field2,field3,...);
5.2 删除索引
删除索引的命令为:
drop index index_name on tb_name;
例如:
mysql> drop index account_name_index on account;
Query OK, 0 rows affected (0.03 sec)
Records: 0 Duplicates: 0 Warnings: 0
mysql> show index from account \G
*************************** 1. row ***************************
Table: account
Non_unique: 0
Key_name: PRIMARY
Seq_in_index: 1
Column_name: id
Collation: A
Cardinality: 3
Sub_part: NULL
Packed: NULL
Null:
Index_type: BTREE
Comment:
Index_comment:
Visible: YES
Expression: NULL
1 row in set (0.00 sec)
表所采用的是InnoDB,为啥显示的索引采用的是BTREE嘞?
5.3 修改索引
修改索引的命令如下所示:
alter table tb_name add primary key(column_list);
-- 添加一个主键,这意味着索引值必须是唯一的,且不能为NULL
alter table tb_name add unique index_name(column_list);
--创建索引的值必须是唯一的(除了NULL外,NULL可能会出现多次)
alter table tb_name add index index_name(column_list);
--添加普通索引, 索引值可以出现多次。
alter table tb_name add fulltext index_name(column_list);
--指定了索引为FULLTEXT, 用于全文索引
6. 设计原则
一个好的索引可以更好的提升查询数据库的效率,而一个差的索引反而会起不到它应有的效果。那么该如何设计索引呢?通常可以参考如下的几条原则:
- 对查询频次较高,且数据量比较大的表建立索引
- 索引字段的选择,最佳候选列应当从where子句的条件中提取,如果where子句中的组合比较多,那么应当挑选最常用、过滤效果最好的列的组
- 唯一索引的区分度越高,使用索引的效率越高
- 索引会对查询之外的操作带来额外的代价,因此,索引并不是越多越好
- 尽量使用短索引,索引字段较短的话,可以在给定大小的存储块中存储更多的索引值,从而更好的提升Mysql访问索引时的IO效率
- 利用最左前缀,N个列组合而成的组合索引,那么相当于是创建了N个索引,如果查询时where子句中使用了组成该索引的前几个字段,那么这条查询SQL可以利用组合索引来提升查询效率

















 449
449

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









