







CSS3中的2D转换中有五种方法:
- translate()
- rotate()
- scale()
- skew()
- matrix()
前四种方法比较好理解,而matrix()方法是把上面四种方法组合在一起,从而可以实现类似边平移边翻转的效果;
使用matrix(a,b,c,d,e,f)需要了解矩阵
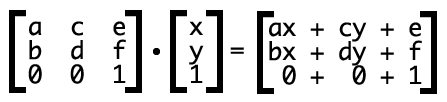
上图得到两个公式
x’=aX+cY+e
y’=bX+dY+f
这两个公式就是元素的新坐标系,(x’,y’)为元素中心。
示例
//样式
<style type="text/css">
#moving{
width: 200px;
height: 200px;
background-color: red;
transform: matrix(0,0,0,0,100,100);
}
</style>
//图形
<div id="moving"></div>1.使用matrix()平移
上面的公式用参数e和f分别是水平偏移距离和垂直偏移距离。
transform: matrix(0,0,0,0,100,100);
代入公式为:
x’=0*X+0*Y+100
y’=0*X+0*Y+100
元素中心偏移至(100,100)
2.使用matrix()放缩
a与d参数是X与Y轴上的比例
transform: matrix(0.5,0,0,0.5,100,100);
代入公式为:
x’=0.5*X+0*Y+100
y’=0*X+0.5*Y+100
元素中心偏移至(100,100),且X,Y轴比例为0.5
3.使用matrix()旋转
matrix(cosθ,sinθ,-sinθ,cosθ,0,0)
transform: matrix(1,1,-1,1,100,100);
x’=1*X-1*Y+100
y’=1*X+1*Y+100
X轴k值为1,Y轴k值为-1,元素旋转45度
4.使用matrix()拉伸
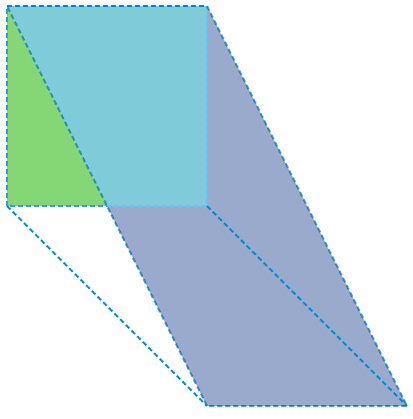
transform: matrix(1,0,1,2,100,100);
x’=1*X+1*Y+100
y’=0*X-2*Y+100
小应用
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<title>Document</title>
<style type="text/css">
#moving{
width: 200px;
height: 200px;
background-color: red;
transform: matrix(0,0,0,0,100,100);
}
</style>
</head>
<body>
<div id="moving"></div>
</body>
<script type="text/javascript">
var i = 0;
function move(){
var cos = Math.cos(i*Math.PI/180);
var sin = Math.sin(i*Math.PI/180);
var div = document.getElementById("moving");
div.style.borderRadius = i+"%";
div.style.backgroundColor = "#"+i+"00000";
div.style.transform = "matrix("+cos+","+sin+","+-sin+","+cos+","+i+",10)";
i++;
}
setInterval("move()",100)
</script>
</html>自己试吧。。。。















 1056
1056

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









