







说明:该系列文章从本人知乎账号迁入,主要原因是知乎图片附件过于模糊。
知乎专栏地址:
语音生成专栏
系列文章地址:
【GPT-SOVITS-01】源码梳理
【GPT-SOVITS-02】GPT模块解析
【GPT-SOVITS-03】SOVITS 模块-生成模型解析
【GPT-SOVITS-04】SOVITS 模块-鉴别模型解析
【GPT-SOVITS-05】SOVITS 模块-残差量化解析
【GPT-SOVITS-06】特征工程-HuBert原理
1.概述
在 GPT-SOVITS 实现中,残差量化层是一个相对核心的改动。如前文所述,在 AR模块训练时,其semantic特征是基于预训练生成模型中残差量化层的输出。残差量化层的核心代码如下:
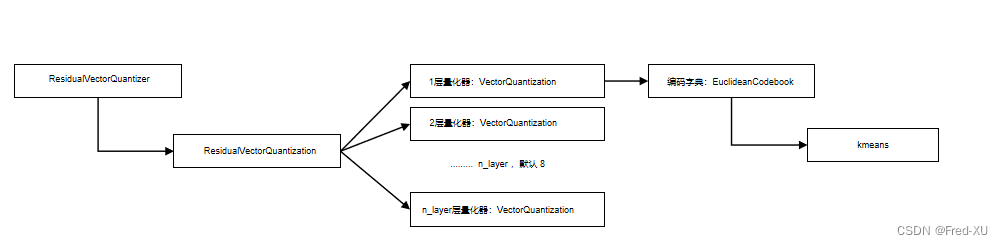
- ResidualVectorQuantizer 是残差量化编码器的封装,在生成模型中构建
- ResidualVectorQuantization 是残差量化编码器的具体实现,其默认包含8个量化编码器
- VectorQuantization。层与层之间用的是输入值和量化值的残差。
- VectorQuantization 是具体某一层的量化编码,将输入数据进行量化编码
- VectorQuantization 在进行量化编码时,其编码字典的实现为
Euclideanbook。其将输入数据做k均值聚类实现一个编码器,将k均值的中心点,作为量化字典。
2、EuclideanCodebook 实现
2.1、原理
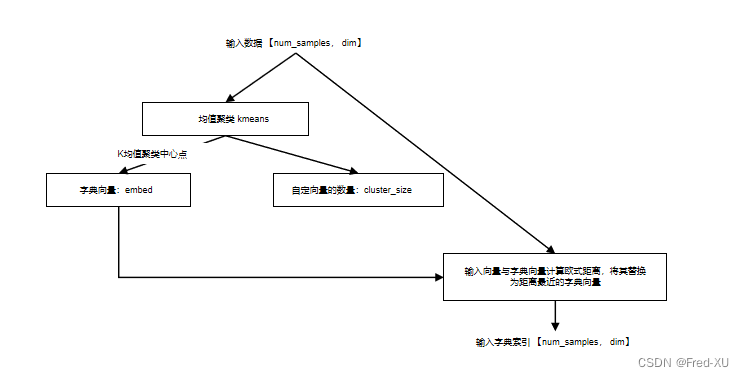
- 输入数据大小为【num_sample,dim】,前者为输入数据数量,后者为每个数据的向量维度 基于k均值聚类
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









