







昨天复习了一下哈希表,今天来总结一下。
哈希表概述
哈希表,是根据关键码值(key value)而直接进行访问的数据结构。也就是说,它通过把关键码值映射到表中一个位置来访问记录。由于可以根据哈希函数直接得到对应位置,哈希表的查找时间复杂度为O(1)。这是一种以空间换时间的做法。
通常哈希表的做法是采用数组实现,利用哈希函数把key转化成整形数字,然后将该数字对数组长度进行取余,取余结果当作数组的下标,将value存储在以该数字为下标的数组空间里。
哈希表的查询同样采用哈希函数,找到key对应的数组下标,查看对应的value是否在该位置上即可。
构造散列函数
散列函数能使一个对数据序列的访问过程更加有效,通过散列函数,数据元素将被更快定位。
- 直接定址法:取关键字或关键字的某个线性函数值为散列地址。即 hash(k)=k 或 hash(k)=a∗k+b ,其中 ab 为常数(这种散列函数叫做自身函数)。
- 数字分析法:假设关键字是以r为基的数,并且哈希表中可能出现的关键字都是事先知道的,则可取关键字的若干数位组成哈希地址。
- 平方取中法:区关键字平方后的中间几位为哈希地址。比如 112=121 ,取2为哈希地址。
- 折叠法:将关键字分割成位数相同的几部分(最后一部分位数可以不同),然后取这几部分的叠加和(舍去进位)作为哈希地址。
- 随机数法
- 除留余数法:取关键字被某个不大于散列表表长m的数p除后所得的余数为散列地址。即 hash(k)=kmodp,p≤m 。不仅可以对关键字直接取模,也可以在折叠法、平方取中法等运算之后取模。对p的选择很重要,一般取素数或m,若p选择的不好,容易产生冲突。
实际工作中不同情况采用不同哈希函数,通常,考虑的因素有:
- 计算哈希函数所需的时间(包括硬件指令的因素)。
- 关键字的长度。
- 哈希表的大小
- 关键字的分布情况
- 记录的查找频率
通常我们采用除留余数法。下面来一个散列函数举例:
比如我们现在要对某个字符串进行散列。我们散列函数可以选择如下:
- 将字符串所有字符的ASCII值相加,然后对TableSize取余。这种方法如果表很大,则函数不会很好的分配关键字。如TableSize=10007,并假设所有的关键字为8个字符长。由于char类型值最多为127,那么散列函数只能取值在0~1016之间,其中1016=127×8。显然不是均匀分配。
- 将前三个字符分别乘以素数再叠加起来,然后取模TableSize。调查显示,3个字母的不同组合数实际上只有2851,所以只有表的28%被用到,显然也不合适。
- 采用关键字当中的所有字符,分别乘以素数,叠加,然后将它们的和取模TableSize作为哈希地址,这种方法一般可以分布的很好。我们在这种方法中可以尽量采用位运算减少哈希函数消耗的时间。甚至可以只使用奇数位置字符。
下面代码例程是PHP采用的DJBX33A算法,就是利用33这个素数,配合位运算实现哈希函数的。后文中哈希表的实现头文件中hash_func基类的hash成员函数用到该函数,后文不再赘述。
#include "hash_table.h"
int hash_func::hash(const std::string& key, const int table_size) const
{
int hash_val = 0;
for(auto k : key)
hash_val = ((hash_val << 5) + hash_val) + k; //PHP DJBX33A hash algorithm.
hash_val %= table_size;
if(hash_val < 0)
hash_val += table_size;
return hash_val;
}
int hash_func::hash(const int key, const int table_size) const
{
return hash(std::to_string(key), table_size);
}哈希函数有了,当多个不同元素通过哈希函数映射到同一位置,那么就会产生冲突。接下来讨论如何处理冲突。
处理冲突
分离链接法(Separate Chaining)
该方法又称为拉链法。分离链接法通常情况下是通过数组加链表实现的,将产生冲突的元素在冲突的位置用链表链接起来。新元素由于最新插入可能会最先被访问所以插入链表的前端。
采用分离链接法,执行find或insert操作我们需要先使用散列函数查找元素对应哈希表的下表,然后再遍历链表,查看元素是否已经存在。如果是insert操作,元素已经存在,我们就什么也不做(如果要插入重复元,那么通常要留出一个额外的数据成员,当出现匹配事件时这个计数增1)。
除链表外,任何的方案也都有可能用来解决冲突现象。比如红黑树,甚至是另外一张哈希表。在JAVA的HashMap中,当链表的长度超过8时,链表会转化为红黑树处理。
下面是分离链接法的实现代码:
首先是hash_table.h,其中hash_func成员函数上文已给出:
#ifndef _HASH_TABLE_H
#define _HASH_TABLE_H
#include <string>
#include <vector>
#include <list>
#include <algorithm>
class hash_func {
protected:
virtual int hash(const std::string& key, const int table_size) const;
virtual int hash(const int key, const int table_size) const;
};
template <typename HASH>
class hash_table : public hash_func {
public:
explicit hash_table(int size = 101)
: lists_(size), current_size_(0)
{ make_empty(); }
bool contains(const HASH& x) const;
bool insert(const HASH& x);
bool remove(const HASH& x);
private:
void make_empty();
void rehash();
private:
std::vector<std::list<HASH>> lists_; //the array of lists
int current_size_;
};
template <typename HASH>
void hash_table<HASH>::make_empty()
{
std::for_each(lists_.begin(), lists_.end(), [] (std::list<HASH>& lst) {
lst.clear(); } );
}
template <typename HASH>
bool hash_table<HASH>::contains(const HASH& x) const
{
const std::list<HASH>& lst = lists_[hash(x, lists_.size())];
return std::find(lst.begin(), lst.end(), x) != lst.end();
}
template <typename HASH>
bool hash_table<HASH>::insert(const HASH& x)
{
auto& lst= lists_[hash(x, lists_.size())];
if(std::find(lst.begin(), lst.end(), x) != lst.end())
return false;
lst.push_back(x);
if(++current_size_ > lists_.size())
rehash();
return true;
}
template <typename HASH>
bool hash_table<HASH>::remove(const HASH& x)
{
auto& lst = lists_[hash(x, lists_.size())];
auto target = std::find(lst.begin(), lst.end(), x);
if(target == lst.end())
return false;
lst.erase(target);
--current_size_;
return true;
}
template <typename HASH>
void hash_table<HASH>::rehash()
{
auto lists_copy = lists_;
current_size_ = 0; //don't forget this line, otherwise current_size_ will accumulate.
lists_.resize(lists_.size() << 1);
make_empty(); //the resize operation never clear the vector.
for(auto lc : lists_copy)
for(auto i : lc)
insert(i);
}在这里引入负载因子(load factor)的概念。它用来衡量哈希表的 空/满 程度,一定程度上也可以体现查询的效率,计算公式为:
负载因子λ = 总的元素个数 / bucket数目(数组的项数)
由于分离链接法冲突时使用链表解决冲突,所以它的负载因子可能>1。不过通常情况下,为了保持哈希表的高效性,我们可能会维持λ<=1。否则需要进行扩容,执行rehash。
不过,memcached源码中,它的实现机制是当λ=1.5时,才会执行rehash,也就是平均一个bucket存储1.5个元素,实际上效率也几乎没有影响。
代码中有rehash操作,后文会分析。
开放定址法
分离链接散列法的缺点是使用一些链表,由于给新单元分配地址需要时间,这就导致算法速度有些减慢。同时还需要链表这种数据结构的实现。我们现在来看一下另外的思路,也就是用来解决冲突的探测方法。
线性探测法
线性探测法的缺点是容易产生一次聚集(primary clustering)。
平方探测法
平方探测法虽然排除了一次聚集,但是散列到同一位置上的那些元素将探测相同的备选单元。这叫做二次聚集(secondary clustering)。
以上两种方法不再详述,参见维基百科即可:散列表。
双散列
双散列法就就用来解决”聚集”这个问题的,利用已产生的hash值+(一个小于数组长度的素数-hash(该素数)产生的值),得出最终的位置。双散列的公式同样参考维基百科即可:Double hashing。这里有一个双散列的图,非常形象:
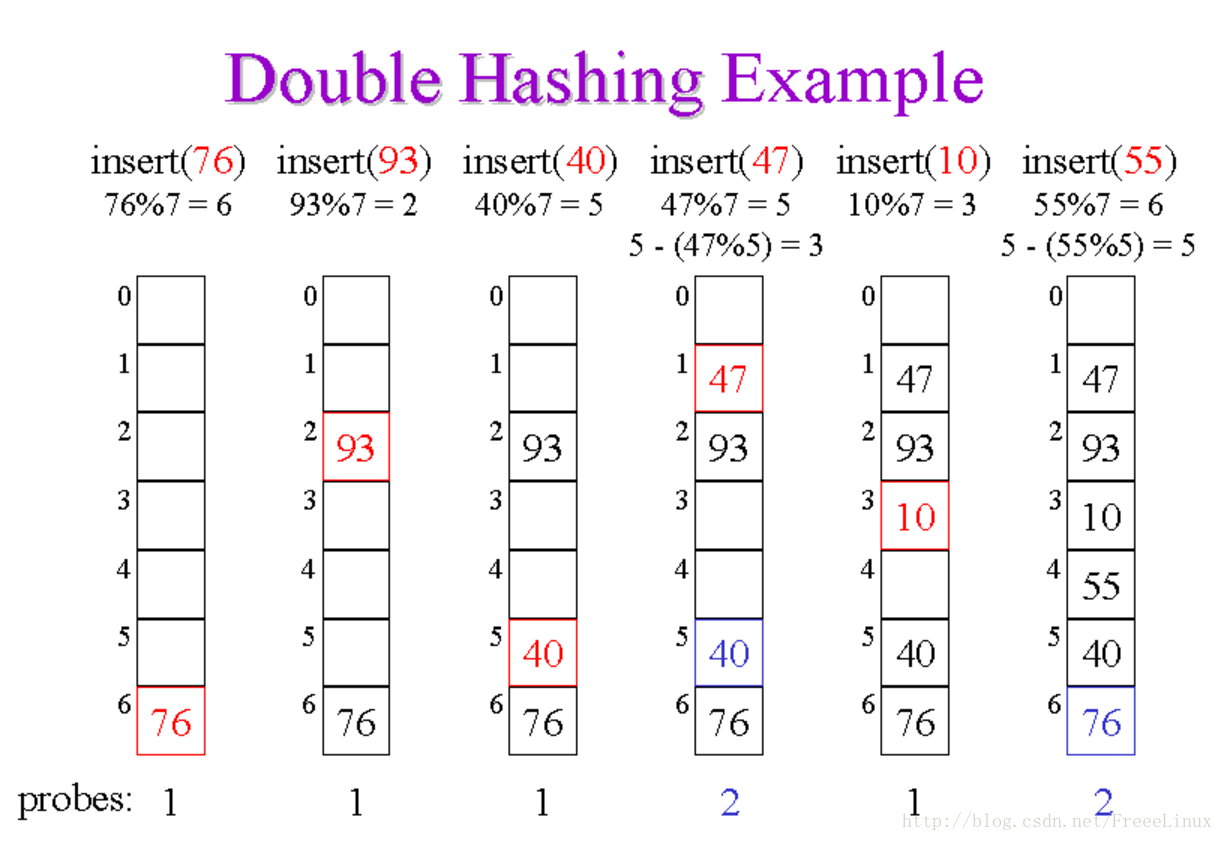
该图原址为:双散列图。页面可以左右划,还有其他图示。
双散列理论上解决冲突效果很好,但是平方探测法不需要使用第二个散列函数,从而在实践中可能更简单并且更快。
下面给出开放地址法的代码,采用了平方探测法:
#ifndef _HASH_TABLE_H
#define _HASH_TABLE_H
#include <string>
#include <vector>
#include <list>
#include <algorithm>
class hash_func {
protected:
virtual int hash(const std::string& key, const int table_size) const;
virtual int hash(const int key, const int table_size) const;
};
template <typename HASH>
class hash_table : public hash_func {
public:
explicit hash_table(int size = 3)
: array_(size), current_size_(0)
{ make_empty(); }
bool contains(const HASH& x) const;
bool insert(const HASH& x);
bool remove(const HASH& x);
private:
void make_empty();
void rehash();
bool is_active(int current_pos) const;
int find_pos(const HASH& x) const;
private:
enum EntryType {ACTIVE, EMPTY, DELETED};
struct hash_entry {
HASH element_;
EntryType info_;
hash_entry(const HASH& e = HASH(), EntryType i = EMPTY)
: element_(e), info_(i)
{}
};
private:
std::vector<hash_entry> array_; //the array of lists
int current_size_;
};
template <typename HASH>
void hash_table<HASH>::make_empty()
{
std::for_each(array_.begin(), array_.end(), [] (hash_entry& v) {
v.info_ = EMPTY; } );
}
template <typename HASH>
bool hash_table<HASH>::contains(const HASH& x) const
{
return is_active(find_pos(x));
}
template <typename HASH>
bool hash_table<HASH>::is_active(int current_pos) const
{
return array_[current_pos].info_ == ACTIVE;
}
template <typename HASH>
int hash_table<HASH>::find_pos(const HASH& x) const
{
int offset = 1;
int current_pos = hash(x, array_.size());
while(array_[current_pos].info_ != EMPTY && //first condition
array_[current_pos].element_ != x){ //second condition. you can't swap the first and the second condition.
current_pos += offset; //compute ith probe
offset += 2;
if(current_pos >= array_.size())
current_pos -= array_.size();
}
return current_pos;
}
template <typename HASH>
bool hash_table<HASH>::insert(const HASH& x)
{
//insert x as active
int current_pos = find_pos(x); //find a position
if(is_active(current_pos)) //if already inserted, failed.
return false;
array_[current_pos] = hash_entry(x, ACTIVE);
if(++current_size_ > (array_.size() >> 1)) //the load factor must less than 0.5.
rehash();
return true;
}
template <typename HASH>
bool hash_table<HASH>::remove(const HASH& x)
{
int current_pos = find_pos(x);
if(!is_active(current_pos))
return false;
array_[current_pos].info_ = DELETED; //laze delete
return true;
}
template <typename HASH>
void hash_table<HASH>::rehash()
{
auto vec_copy = array_;
current_size_ = 0; //don't forget this line, otherwise current_size_ will accumulate.
array_.resize(array_.size() << 1);
make_empty();
for(auto v : vec_copy){
if(v.info_ == ACTIVE)
insert(v.element_);
}
}
#endif使用开放定址法时,删除就不能直接删除了。我们需要采用惰性删除(lazy deleted),做个标记即可。因为该位置有可能之前产生过冲突,我们需要通过标记来寻访之前产生冲突的元素。
再散列(rehash)
如果哈希表元素填的太满,会引起哈希表的性能下降。尤其是对于开放定址法,探测的时间可能很长,且有可能插入失败。所以这个时候我们就需要执行rehash。可以建立另外一个大约两倍大的表,然后把原始表中的所有元素通过新哈希函数(TableSize已经改变)插入到新表之中。
rehash是一种非常昂贵的操作,其运行时间为O(N),因为要遍历原始表。不过,由于不经常发生,所以是效果没有这么差。
通常情况下,平方探测法可能在λ=0.75时就进行rehash,JAVA就是这样做的;而拉链法会高一些,比如memcached在λ=1.5才进行rehash。
各种冲突解决方法的优点和缺点
原文如下:

大意是:分离链接法使用链表,花费一定的时间在申请内存操作上。线性探测法容易实现,但执行效率随着负载因子的增加会出现一次聚集问题。平方探测法实现难度只有一点增加并且在实践中有很好的效率。如果表半空插入可能失败(当表大小不是素数会发生),但这不太可能。即使是这样的插入将是如此昂贵,这也没有关系,因为它暴露除了哈希函数是有问题的。双散列能消除一次聚集和二次聚集问题,但是多一次哈希函数的计算是要花费代价的。实践表明,平方探测法会带来最好的性能。
哈希表和其他数据结构的对比
优点:
记录量很大的时候,处理记录的速度很快,平均的操作时间是一个不大的常数。
缺点:
- 好的哈希函数(good hash function)的计算成本有可能会显著高于线性表或者红黑树在查找时的内部循环成本,所以数据量非常小的时候,哈希表是低效的
- 哈希表相比红黑树按照key对value有序遍历是比较麻烦的,需要先取出所有记录再进行额外的排序。
- 哈希表处理冲突的机制本身可能就是一个缺陷,攻击者可能而已构造数据,来实现处理冲突的最坏情况,即每次都出现冲突。以此大幅降低哈希表的性能。比如PHP的哈希碰撞攻击,让哈希表退化为一个单链表,请求堆积,最终演变成拒绝服务的状态。
哈希表的加锁
哈希表的rehash是一个耗时的过程,那么这个过程怎么加锁呢?
我们显然不能上全局锁,这样锁冲突不能避免,且工作线程就无法插入数据了。在哈希表迁移的时候,我们可以采用多个分段锁。比如每次上锁只针对一个buket进行迁移,迁移完毕立即释放锁。这样会减少迁移线程持有锁的时间,工作线程能更大几率抢占到锁,然后进行数据的插入。
至于数据插入到新表还是旧表,参照memcached,使用一个目前已经迁移的bucket下标,每迁移一个bucket该下表自增1。通过两个线程减共享下标的信息判断要插入的元素的位置是否已经迁移。如果已经迁移,就插入到新表之中。
关于memached的hash源码可以看这篇博客: memcached源码分析—–哈希表基本操作以及扩容过程。
另外,Redis的rehash过程虽然是单线程的,但也是采用了类似的思想。每次迁移一小部分,并且每次插入进行判断。Redis的hash参考: 深入理解哈希表(JAVA和Redis哈希表实现)。
还有一个hash的高端内容参考:谈谈面试–哈希表系列。
关于哈希表的大数据面试题
在这篇博客从头到尾彻底解析Hash表算法有很好的例子,不再赘述。















 355
355

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









