






在多媒体制作和音频编辑的世界里,能够从一段音频中提取出纯净的人声或特定乐器声,对于创作者来说是一项宝贵的技能。
但并非所有人都拥有昂贵的音频编辑软件或专业的音频处理技能。
不过好在,现在市面上有一些免费的软件,它们提供了强大的音频提取功能,让这一过程变得简单易行。接下来,分享几款提取音频免费软件给大家,记得码好~

【剪辑魔法师】:音频处理的魔术师
◎软件介绍:
剪辑魔法师是一款专为音频处理设计的软件,无论是音乐制作人还是视频编辑者,都能通过这款软件轻松实现音频的精细化处理。
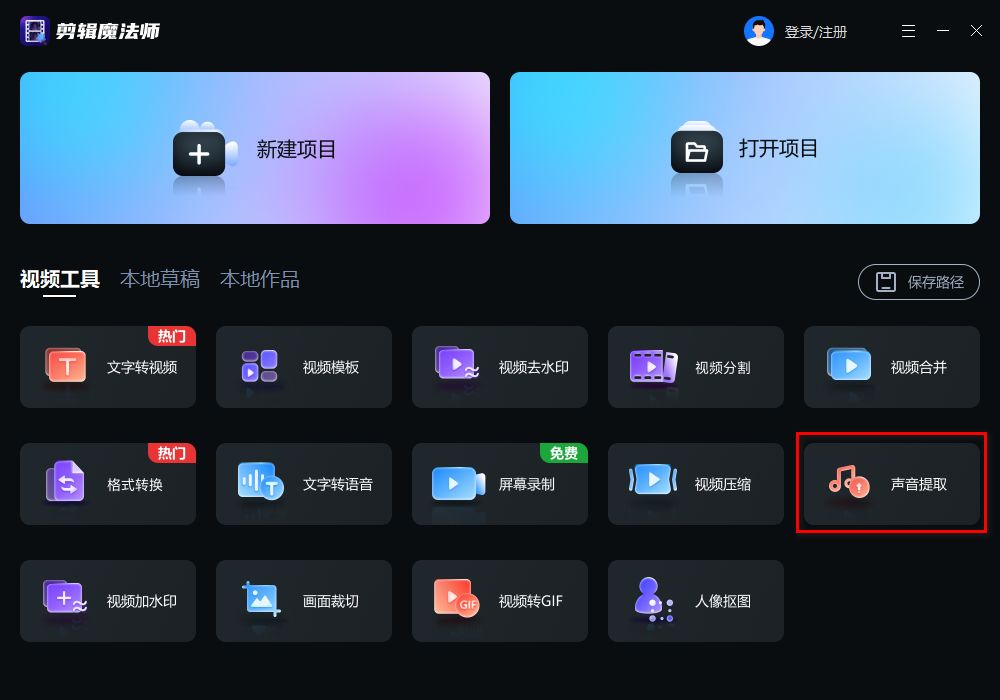
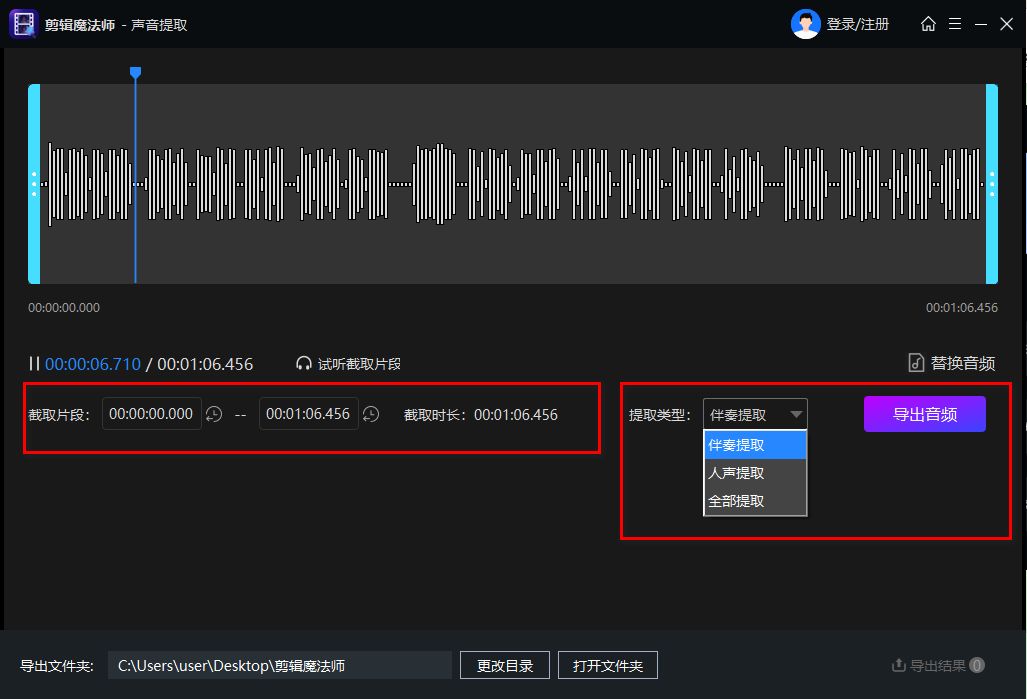
◎功能特点:
- 多格式支持:支持多种音频格式,如MP3、WAV等,满足不同使用者的需求。
- 一键提取:提供简洁直观的操作界面,实现一键快速提取,无需复杂的设置。
- 精确分离:能够从复杂的音频背景中精确分离出人声或伴奏。
【Audiosauna】:音频处理的艺术家
◎软件介绍:
Audiosauna它不仅处理速度快,而且在分离精度上表现出色,即使是复杂的旋律也能准确分离。
◎功能特点:
- 高效处理:可快速分析导入的音频文件,并准确分离出伴奏和人声。
- 界面友好:界面设计直观,操作简单,易于上手。
- 音质保持:在提取过程中保持原始音质的纯净度。
【AIVA】:人工智能的音频助手
◎软件介绍:
AIVA是一款结合了人工智能技术的伴奏提取工具,它通过深度学习算法来识别和分离音频中的不同元素,提供高效且精确的音频处理服务。
◎功能特点:
- 智能识别:利用AI技术自动识别音频中的伴奏和人声。
- 简单操作:上传音频文件后,根据指示设置参数即可进行提取。
- 高效提取:提供快速且高质量的伴奏提取服务。
【Adobe Audition】:音频编辑的全能战士
◎软件介绍:
Adobe Audition是Adobe公司推出的专业音频编辑软件,以其全面的音频处理功能和卓越的音质处理能力,成为音频专业人士的首选。
◎功能特点:
- 多轨编辑:支持多轨音频编辑,提供强大的音频处理能力。
- 高级提取工具:提供高级的声音提取工具,能够精确分离音频中的人声和伴奏。
- 音质卓越:能够确保提取的声音保持高质量,满足专业音频制作的标准。

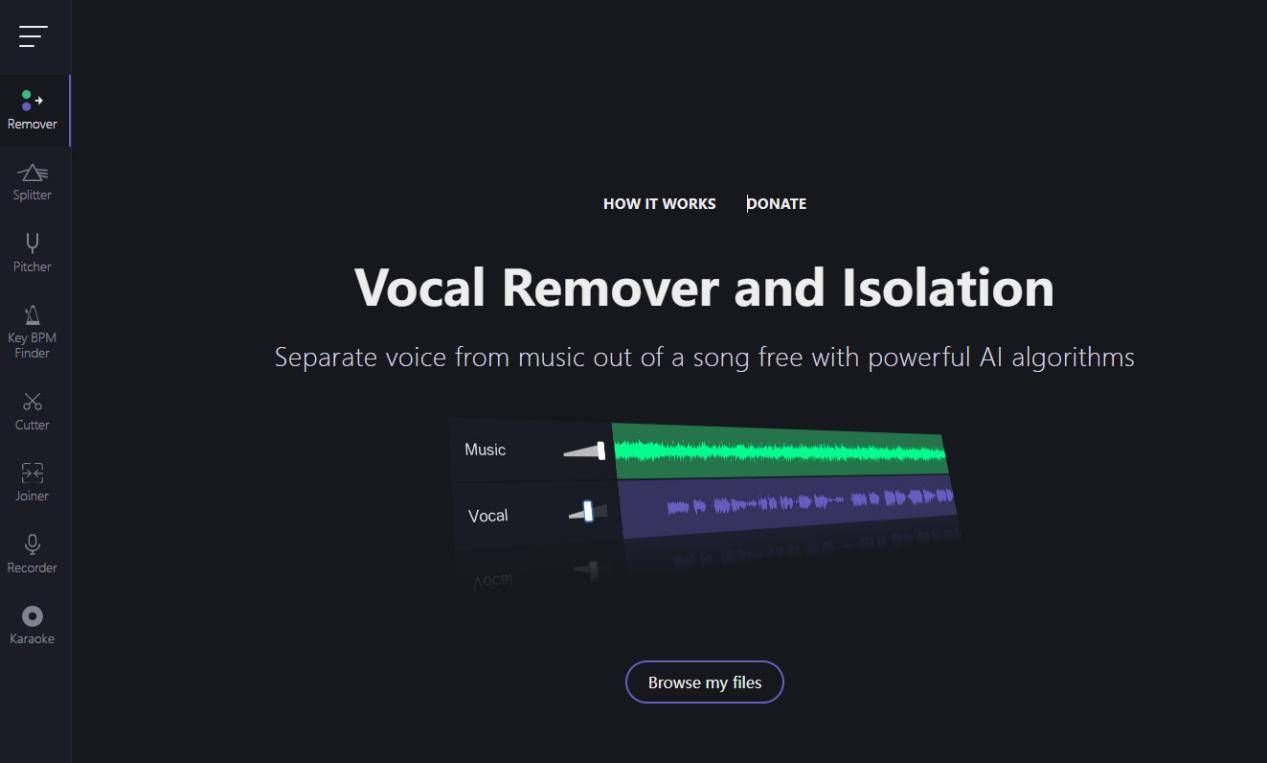
【VocalRemover and Isolation】:音频提取的便捷工具
◎软件介绍:
VocalRemover and Isolation是一款利用AI技术自动分离人声和伴奏的软件,适用于非专业人士。
◎功能特点:
- AI分离技术:自动分离人声和伴奏,简化操作流程。
- 实时预览:支持实时预览效果,方便调整设置。
- 易用性:适合初学者使用,无需复杂的设置即可完成音频提取。
以上便是对五款提取音频免费软件的详细介绍啦,快去挑选一款软件使用吧~















 5843
5843

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









