







 写在前面因为喜欢玩儿音乐游戏,所以打算研究一下如何用深度学习的模型生成音游的谱面。这篇文章主要目的是介绍或者总结一些音频的知识和代码。恩。如果没玩儿过的话,音乐游戏大概是下面这个样子。下面进入正题。我Google了一下,找到了这篇文章:Music Feature Extraction in Python。然后这篇文章介绍完了还有一个歌曲分类的实践:Classification of Music into different Genres using Keras。下面的内容会主要参考一下这两篇文章
写在前面因为喜欢玩儿音乐游戏,所以打算研究一下如何用深度学习的模型生成音游的谱面。这篇文章主要目的是介绍或者总结一些音频的知识和代码。恩。如果没玩儿过的话,音乐游戏大概是下面这个样子。下面进入正题。我Google了一下,找到了这篇文章:Music Feature Extraction in Python。然后这篇文章介绍完了还有一个歌曲分类的实践:Classification of Music into different Genres using Keras。下面的内容会主要参考一下这两篇文章
写在前面
因为喜欢玩儿音乐游戏,所以打算研究一下如何用深度学习的模型生成音游的谱面。这篇文章主要目的是介绍或者总结一些音频的知识和代码。
恩。如果没玩儿过的话,音乐游戏大概是下面这个样子。
下面进入正题。
我Google了一下,找到了这篇文章:Music Feature Extraction in Python。然后这篇文章介绍完了还有一个歌曲分类的实践:Classification of Music into different Genres using Keras。
下面的内容会主要参考一下这两篇文章,并加入一些我的理解。内容如下:
- 声音信号介绍
- 使用Python对音频进行特征提取
- 使用Keras对歌曲的题材进行分类
主要涉及的背景知识有:
- 傅里叶变换
- 采样定理
- Python
- 机器学习
声音基础知识
音频信号
首先先百度一下音频信号,
音频信号是(Audio)带有语音、音乐和音效的有规律的声波的频率、幅度变化信息载体。 根据声波的特征,可把音频信息分类为规则音频和不规则声音。其中规则音频又可以分为语音、音乐和音效。规则音频是一种连续变化的模拟信号,可用一条连续的曲线来表示,称为声波。声音的三个要素是音调、音强和音色。声波或正弦波有三个重要参数:频率 、幅度和相位 ,这也就决定了音频信号的特征。

这里多说一句,小编是一名python开发工程师,这里有我自己整理了一套最新的python系统学习教程,包括从基础的python脚本到web开发、爬虫、数据分析、数据可视化、机器学习等。想要这些资料的可以关注小编,并私信“01”即可领取。
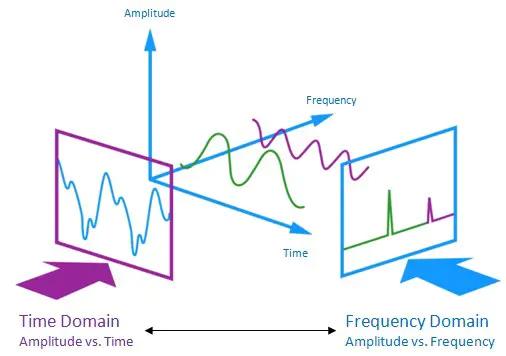
总体来说:音频信号就是不同频率和相位的正弦波的一个叠加。
一般的声音大概就是这个样子。
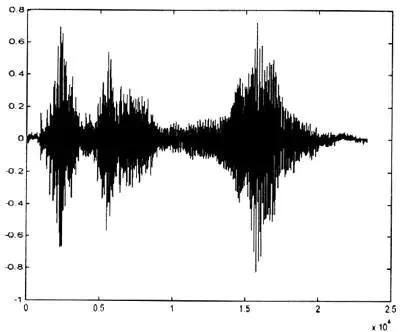
横轴是时间,纵轴是声音的幅度。因为本质上就是正弦波的一个叠加,所以看到其实是有正有负的。
人耳听力频率范围
生活中存在各种正弦波,但并不是所有的波都能被人耳听到。比如说我们手机通信的信号,wifi信号,以及阳光都是一种波,但并不能被人听见。
正常人耳听见声音的频率范围是 20Hz 到 2 万 Hz 。相同强度的声音如频率不同的话,听起来的响度是不一样的。至敏感的频率是 3000 和 4000Hz 。
所以声波的信号基本上只要关注2wHz以内就好了。
奈奎斯特采样定理
声音本质上是一种模拟信号,但在计算机或者在其他数字设备上传输时,我们要把模拟信号转换为数字信号,需要进行采样。
奈奎斯特采样定理如下:
在进行模拟/数字信号的转换过程中,当采样频率fs.max大于信号中最高频率fmax的2倍时(fs.max>2fmax),采样之后的数字信号完整地保留了原始信号中的信息。
这个定理描述的很简单,证明其实也不难,对于声音信号,只要采样的频率大于2*2wHz=4WHz的话,我们就可以听到无损的音质了。
上面说人耳听力敏感的范围主要是在4000Hz,所以我们一般听到的音乐其实是使用8000Hz频率进行采样的。这里可以看下最近比较火的芒种这首歌。
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 334
334











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









