







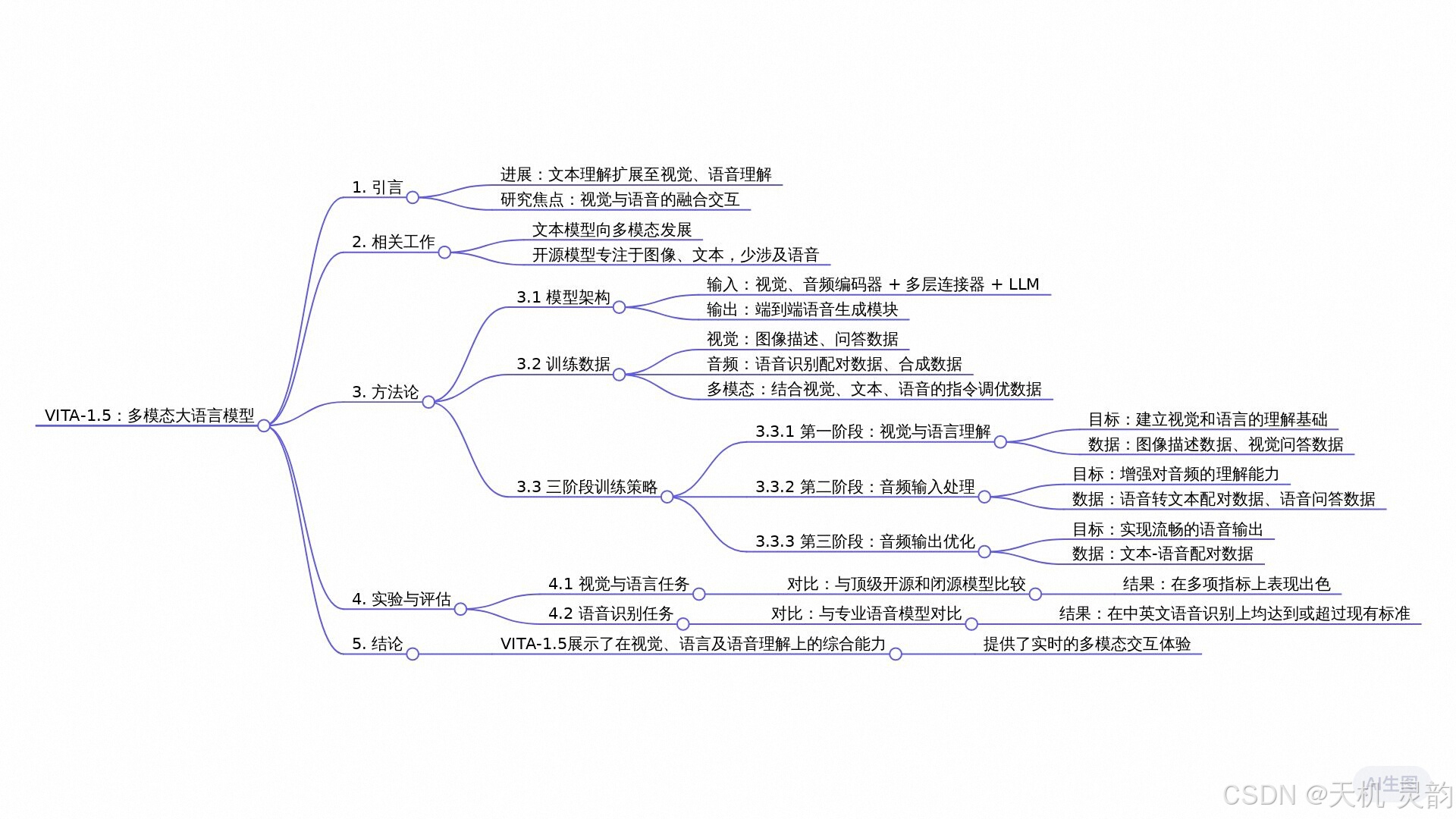
VITA-1.5:迈向GPT-4o级实时视觉和语音交互
傅超友1,♠,林浩佳3,王雄2,张艺帆4,沈云航2刘晓宇1,曹皓宇2,龙祖伟2,高赫婷2,李科2,马龙2,郑夏武3,吉荣荣3,孙兴2,†,山彩凤1,何冉4
1南京大学,2腾讯优图实验室,3厦门大学,4中国科学院自动化研究所
♠ 项目负责人 † 对应作者
源代码:https://github.com/VITA-MLLM/VITA
摘要
最近的多模态大型语言模型 (mlms) 通常侧重于整合视觉和文本模态,较少强调语音在增强交互中的作用。然而,语音在多模态对话系统中扮演着至关重要的角色,由于基本的模态差异,在视觉和语音任务中实现高性能仍然是一个重大挑战。在本文中,我们提出了一种精心设计的多阶段训练方法,逐步训练LLM理解视觉和语音信息,最终实现流利的视觉和语音交互。我们的方法不仅保留了强大的视觉语言能力,而且还实现了高效的语音对话能力,无需单独的ASR和TTS模块,显著加快了多模态端到端的响应速度。通过将我们的方法与图像、视频和语音任务基准上最先进的方法进行比较,我们证明了我们的模型具备强大的视觉和语音功能。进行近乎实时的视觉和语音交互。训练和推理代码已在 https://github.com/VITA发布-MLLM/VITA (到目前为止已有2k颗星)。
1 引言
最近MLMS [13,31, 67, 10, 49, 61, 42, 17] 的进展导致了重大进展,特别是在视觉和文本模态的整合方面。将视觉信息引入LLMs中,显著增强了模型在各种多式联运任务中的能力。然而,随着人机交互吸引力的不断增强,言语模态的作用日益凸显,尤其是在多模态对话系统中。在这样的系统中,语音不仅作为信息传递的关键媒介,而且极大地提高了交互的自然性和方便性。因此,整合视觉和语音模式以实现高性能的多模态交互已经成为一个重要的研究重点。 在MLLMs中,视觉和语音的集成并非直接由于它们的本质差异[40]。例如,视觉数据如图像传达空间信息,而语音数据则传达时间序列中的动态变化。这些根本差异对同时优化这两种模式提出了挑战,通常会导致训练期间出现冲突。例如,加入语音数据可能会降低视觉任务的表现,反之亦然。此外,传统的语音到语音系统依赖于自动语音识别模块进行语音处理。

识别(ASR)和文本到语音,这可能会增加延迟并降低连贯性,限制了它们在实时应用中的实用性[44、16、63]。
在本文中,我们介绍了VITA-1.5,这是一个通过精心设计的三阶段训练方法将视觉、语言和语音整合在一起的多模态lm。训练策略逐步结合视觉和语音数据,缓解模态冲突,同时保持强大的多模态性能。在第一阶段,我们通过训练视觉适配器并使用描述性标题和视觉QA数据对模型进行微调来关注视觉语言。这一步建立了模型的基本视觉功能,实现了强大的图像和视频理解。第二阶段介绍了音频输入处理,通过使用语音转录配对数据训练音频编码器,然后使用语音QA数据进行微调。这个阶段使模型具备有效理解和响应音频输入的能力。最后,在第三阶段,我们训练音频解码器以启用端到端语音输出,无需外部TTS模块。这使得VITA-1.5能够生成流畅的语音回复,增强多模态对话系统的自然性和交互性。 我们对图像、视频和语音理解相关的各种基准进行了广泛评估,将结果与开源模型和专有模型进行比较。VITA-1.5展示了可与领先的基于图像/视频的MLLMs相媲美的感知和推理能力,并在语音能力方面取得了显著提升。
2 相关工作
最近,由于语言模型的快速发展,如GPTs[41,3],LLaMA[52,53],羊驼 [48],Vicuna[12],和Mistral[24],研究人员通过多模态对齐和指令调优等技术成功地将文本理解扩展到多模态理解/推理。例如,诸如lllava [31] 、Qwen-VL[2] 、Cambrian-1[51] 、mini-gemini [28] 、MiniCPM-V 2.5[23] 等模型,deepreek-VL[36] 和SliME[66] 在图像感知和推理方面取得了重大进展,而像LongVA[65] 和Video-LLaVA[29] 这样的模型展示了视频理解的最新进展。这些模型越来越能够处理不同的数据类型,推动了多模态感知和理解能力的不断提高。 然而,与支持多种模式的专有模型相比,包括音频、图像和文本(例如GPT-4o [42] 和Gemini-Pro 1.5 [50]),大多数开源模型主要
专注于图像和文本模式 [61]。此外,很少有开源模型涉及多通道交互功能,这是一个相对未开发的领域。虽然像VITA-1.0这样的作品 [16] 已经初步尝试为人机交互引入语音,但引入额外的语音数据对模型的原始多模态能力构成了挑战。此外,语音生成通常依赖于现有的TTS系统,这通常会导致高延迟,从而影响用户体验。在本文中,我们提出了利用精细训练策略的VITA-1.5,它在感知四种模态 (视频、图像、文本和音频) 的数据方面表现出色。同时还实现了近乎实时的视觉和语音交互。
3.1 模型架构
VITA-1.5的整体架构如图所示。2.输入端与VITA-1.0版本 [16] 的输入端相同,即采用 “多个timodal编码器-适配器-LLM” 的配置。它将视觉/音频变压器和多层连接器与用于联合训练的LLM相结合,旨在增强对视觉、语言和音频的统一理解。关于输出端,VITA-1.5有自己的端到端语音模块,而不是像原始VITA-1.0版本那样使用外部的TTS模型。
3.1.1 视觉模态
视觉编码器。VITA-1.5采用InternViT-300M1作为视觉编码器,输入图像大小为448×448像素,每张图像生成256个视觉令牌。对于高分辨率的图像,VITA-1.5采用了动态补丁策略来捕捉局部细节,提高了对图像的理解精度。
视频处理。 视频被当作一种特殊的多图像输入类型进行处理。 如果视频长度短于4秒,均匀采样4帧;对于在4到16秒之间的视频,每秒采样一帧;对于长于16秒的视频,均匀采样16帧。 不对视频帧应用动态修补以避免过多视觉标记妨碍处理效率。
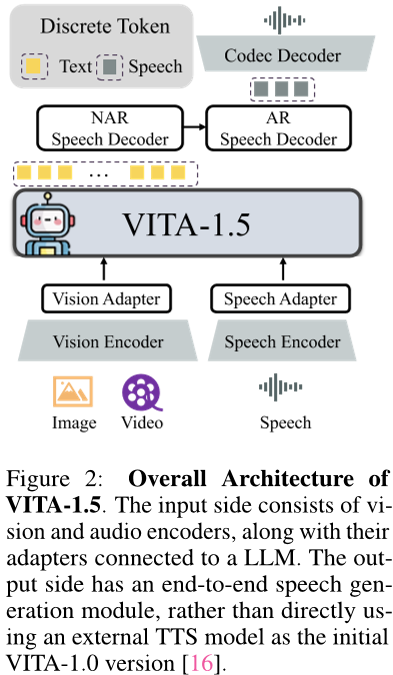
图2:VITA-1.5的整体架构。输入端包括视觉和音频编码器,以及连接到LLM的适配器。输出端有一个端到端语音生成模块,而不是直接使用外部TTS模型作为最初的VITA-1.0版本[16]。
视觉适配器。使用两层MLP将视觉特征映射到适合后续LLM理解的视觉标记。
3.1.2 音频模态
语音编码器。类似于 [56],我们的音频编码模块由多个缩减采样卷积层 (4倍缩减采样) 和24个变压器块 (隐藏大小为1024) 组成。下采样层有助于降低音频功能的帧率,提高lm的处理速度。音频编码器有大约350m的参数和12.5hz的输出帧率。梅尔滤波器组功能被用作音频编码器的输入,窗口大小为25毫秒,移位为10毫秒 [56]。 语音适配器。它由多个具有2倍下采样的卷积层组成。
语音解码器。我们使用TiCodec [45]作为我们的编解码模型,定制一个大小为1024的单个代码本。这种单代码本设计简化了推理阶段的解码过程。编解码模型负责将连续语音信号编码成离散语音令牌。
以40赫兹的频率,同时具备解码成语音信号的能力,采样率是2.4万赫兹。
当前的lm只能输出文本令牌,语音生成功能要求lm能够输出语音令牌。为此,我们在 [56] 之后的文本标记后添加了两个语音解码器: 1) 非自回归 (NAR) 语音解码器,全局处理文本标记并对语义特征进行建模。目的是生成语音令牌的初始分布; 2) 自回归 (AR) 语音解码器逐步生成更高质量的语音令牌,基于NAR解码器产生的语音信息。然后,使用编解码器模型的语音解码器将语音令牌的最终序列解码为连续的语音信号流 (波形)。我们为NAR和AR语音解码器采用4个LLaMA解码层,其中隐藏大小为896,参数大小约为120M。
3.2 培训数据
如表1所示,多模态指令微调的训练数据涵盖范围广泛,包括中英文两种语言的标题数据和问答数据。在不同的训练阶段,从整个数据集中选择性地采样子集以实现不同目标。具体来说,这些数据集分为以下几类:
• 图像标题数据。ShareGPT4V [9]、ALLaVA-Caption [6]、SharedGPT4o-Image2 和合成数据等数据集用于训练模型,以生成图像的描述性语言。
• 图像问答数据。LLaVA-150K3、LLaVA-Mixture-sample [31]、LVIS-Instruct [55]、ScienceQA [38]、ChatQA [35] 和从 LLava-OV [26] 中采样的子集,如通用图像问答和数学推理数据集等,用于训练模型以回答基于图像的问题并执行视觉推理任务。
•OCR和图表数据。该类别支持模型理解OCR和图表内容,使用诸如Anyword-3M [54]、ICDAR2019-LSVT4、UReader [58]、SynDOG5、ICDAR2019-LSVT-QA6以及从LLaVA-OV中采样的相应数据等数据集。
• 视频数据。ShareGemini [47] 等数据集和合成数据用于训练模型处理视频输入并执行诸如字幕和基于视频的问答等任务。
• 纯文本数据。此类别增强了模型理解并生成语言的能力,便于基于文本的问答任务。
除了表1中列出的图像和视频数据外,还加入了11万小时内部语音转录配对ASR数据,涵盖中文和英文,用于训练音频编码器,并将音频编码器与LLM进行对齐。此外,使用TTS系统生成的3000小时文本-语音配对数据来训练语音解码器。
3.3三阶段训练策略
为了确保VITA-1.5在涉及视觉、语言和音频的任务中表现良好,我们必须面对一个关键挑战,即不同模式之间的训练冲突。例如,添加语音数据可能会对对视觉数据的理解产生负面影响,因为语音的特征与视觉的特征显着不同,在学习过程中造成干扰。为了应对这一挑战,我们设计了一个三阶段培训策略,如图所示。3.核心思想是逐步将不同的模态引入模型中,使其能够在保持现有模态力量的同时增加新模态的力量。
3.3.1 第一阶段:视觉语言训练
第一阶段:视觉对齐。在这个阶段,我们的目标是弥合视觉和语言之间的差距。前者的特征是从预训练的视觉编码器InternViT-300M中提取出来的,并且
后者通过LLM引入。我们使用表1中描述性标题数据的20%进行训练,其中只有视觉适配器可训练,而其他模块是冻结的。这种方法允许LLM最初对齐视觉模态。
1.2阶段视觉理解。在这个阶段,我们的目标是教lm转录图像内容。为此,我们使用表1中的所有描述性标题数据。在此过程中,视觉模块的编码器和适配器以及LLM都是可训练的。重点是通过学习关于图像的描述性文本,使模型能够在视觉和语言之间建立强大的联系,从而通过生成自然语言描述来理解图像内容。 Stage 1.3 Vision SFT。在完成 Stage 1.2 后,模型已经对图像和视频有了基本的理解,但其指令理解能力仍然有限,并且难以应对视觉问答任务。为实现这一目标,我们使用了表 1 中的所有 QA 数据,并保留了 20% 的描述性标题数据以增加数据集的多样性和任务的复杂度。
在训练过程中,视觉模块的编码器和适配器以及LLM都是可训练的。这一阶段的关键目标是使模型不仅能够理解视觉内容,还能根据指令回答问题。
3.3.2 第二阶段:音频输入调谐
舞台2.1音频对齐。在完成第一阶段的训练后,该模型已经在图像和视频理解方面建立了坚实的基础。在这个阶段,我们的目标是根据第一阶段减少音频和语言之间的差异,使LLM能够理解音频输入。训练数据由11000个小时的语音转录对组成。我们采用两步方法 :( a) 语音编码器训练: 我们采用常见语音识别系统中使用的训练框架,使用连接主义时间分类 (CTC) 损失函数 [18] 来训练语音编码器。目的是让编码器从语音输入中预测转录文本。这一步确保了音频编码器能够提取语音特征并将其映射到文本表示空间。(b) 语音适配器训练: 在训练语音编码器之后,我们将其集成
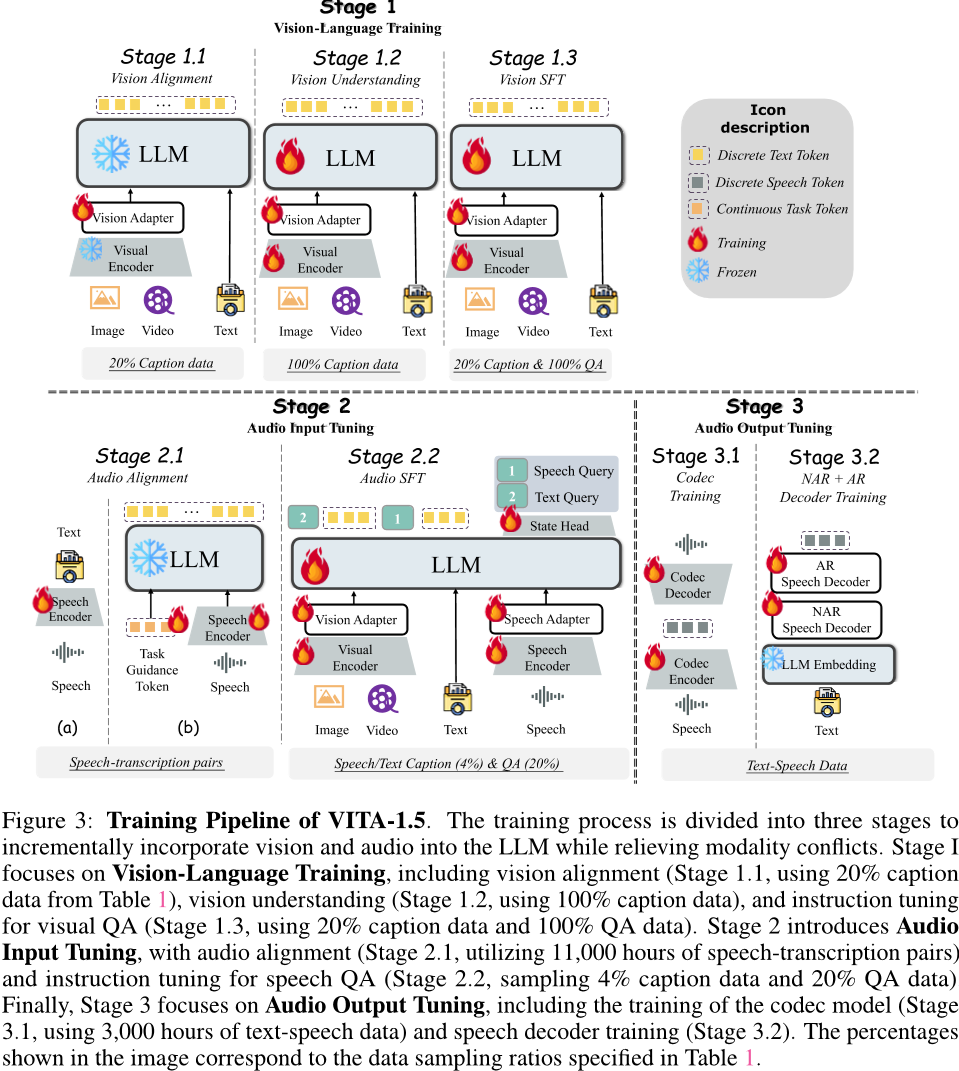
图3: VITA-1.5的训练流程。培训过程分为三个阶段,逐步将视觉和音频纳入到lm中,同时缓解模态冲突。第一阶段专注于视觉语言培训,包括视觉对准 (1.1阶段,使用表1中的20% 字幕数据),视觉理解 (1.2阶段,使用100% 字幕数据),以及针对视觉QA的指令调整 (阶段1.3,使用20% 的字幕数据和100% 的QA数据)。阶段2引入了音频输入调谐,具有音频对齐 (阶段2.1,利用11,000小时的语音转录对) 和语音QA的指令调谐 (阶段2.2,采样4% 字幕数据和20% QA数据)。最后,第三阶段的重点是音频输出调谐,包括编解码器模型的训练 (3.1阶段,使用3,000小时的文本-语音数据) 和语音解码器的训练 (3.2阶段)。图中所示的百分比对应于表1中指定的数据采样率。 使用LLM,用音频适配器将音频特征引入到LLM的输入层。这个阶段的训练目标是让LLM输出语音数据的转录文本。
此外,在步骤(b)中,我们引入了特殊的可训练输入令牌来引导语音理解过程。这些令牌提供了额外的上下文信息,以指导用于QA任务的LLM执行ASR任务。
第二阶段,音频SFT。本阶段的重点是引入带有语音问题和文本答案的QA功能。为此,我们从表1中抽取了4%的字幕数据和20%的QA数据。在数据处理方面,大约一半基于文本的问题被随机替换为使用TTS系统生成的相应语音版本。
在这个阶段,视觉编码器和适配器、音频编码器和适配器以及LLM都是可训练的,旨在提高模型对多模态输入的适应性。此外,我们还在LLM输出中添加了一个分类头。该头用于区分输入是来自语音还是文本。因此,模型可以更准确地解释语音输入,并高效灵活地处理不同模态。
3.3.3 第三阶段:音频输出调谐
在前两个训练阶段,VITA-1.5模型有效地发展了其多模态理解能力。然而,一个关键的能力,即语音输出,仍然缺失,这对于它作为交互式助手的角色至关重要。为了引入语音输出功能而不影响模型的基本能力,我们借鉴了策略 [56] ,使用了3000小时的文本语音数据,并采用两步训练方法(见图3)。
第三步,编码器训练。本步骤的目标是使用语音数据对单个码书进行编码器模型的训练。该编码器模型具有将语音映射到离散令牌的能力,而解码器可以将离散令牌映射回语音流。在VITA-1.5的推理阶段,仅使用解码器。
3.2阶段NAR解码器训练。这个阶段的训练使用文本-语音配对数据,其中文本被输入到分词器中,并在LLM的后续嵌入中获得其嵌入向量。语音被输入到编解码器模型的编码器中,以获取其语音令牌。将文本嵌入向量发送到NAR语音解码器以获取全局语义特征,然后将特征发送到AR语音解码器,由其预测相应的语音标记。请注意,在这个阶段,lm会被冻结,因此多模式性能不会受到影响。
4 评价
4.1 视觉语言评估
基线。我们比较了一系列的开源mlms,包括VILA-1.5[30] 、LLaVA-Next[25] 、CogVLM2[22] 、InternLM-XComposer2.5[64] 、Cambrian-1[51],miniCPM-V-2.6 [23] 、Ovis1.5[39] 、InternVL-Chat-1.5、InternVL-2[11] 、lllava-OV[26] 、视频-LLaVA[29] 、粘液 [66],和LongVA[65],以及5个闭源MLLMs,包括GPT-4V7、GPT-4o8、GPT-4o-mini、双子座1.5 Pro[50] 和克劳德3.5十四行诗9。 评估基准。为了评估VITA-1.5的图像感知和理解能力,我们利用了几个评估基准,包括MME[14] 、MMBench[32] 、MMStar[8] 、MMMU[60],mathVista [37] 、HallusionBench[20] 、AI2D[21] 、OCRBench[34] 和MMVet[59]。这些基准涵盖了广泛的方面,包括一般多式联运能力 (例如,MME,MMBench和MMMU),数学推理 (MathVista),幻觉检测 (halusionbench),图表 (AI2D) 和OCR(OCRBench) 理解,提供全面的 7 https://openai.com/index/gpt-4v-system-card/
8https://openai.com/index/hello-gpt-4o/
9 Introducing Claude 3.5 Sonnet \ Anthropic
表3:视频理解基准评估。尽管VITA-1.5仍然落后于
评估结果。对于视频理解,我们使用代表性评价基准包括Video-MME [15]、MVBench [27] 和TempCompass [33]。
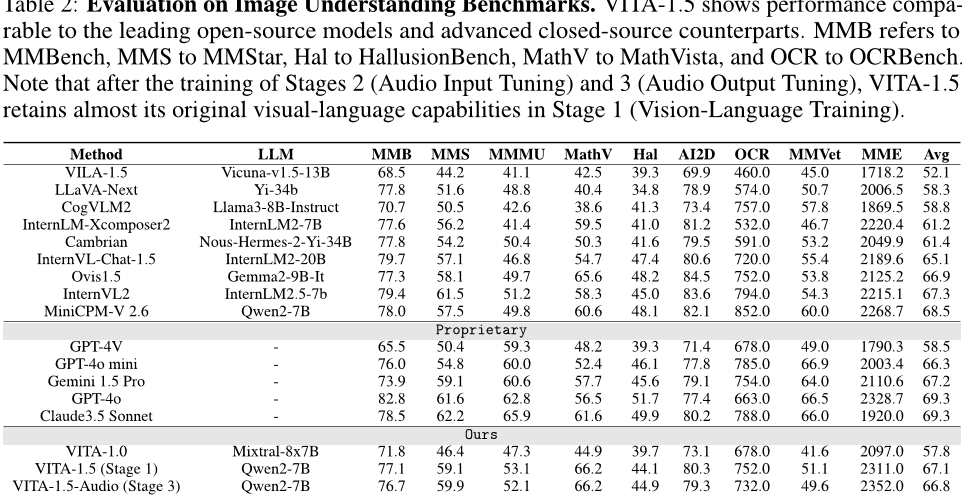
视觉语言能力。表2比较了VITA-1.5的图像理解性能。经过三个阶段的训练,VITA-1.5的表现可媲美最先进的开源模型,甚至超过了一些闭源模型,如GPT-4V和GPT-4o-mini。这一结果突出了VITA-1.5在图像语言任务中的强大功能。如表3所示,VITA-1.5在视频理解评估方面显示出与顶级开源模型相当的性能。与专有模型相比的显著差距表明,VITA-1.5仍有很大的改进空间,并有进一步增强视频理解的潜力。请注意,在经过阶段2 (音频输入调谐) 和阶段3 (音频输出调谐) 的培训后,VITA-1.5在第一阶段 (视觉语言训练) 几乎保留了其原始的视觉语言能力。
4.2 语音评估
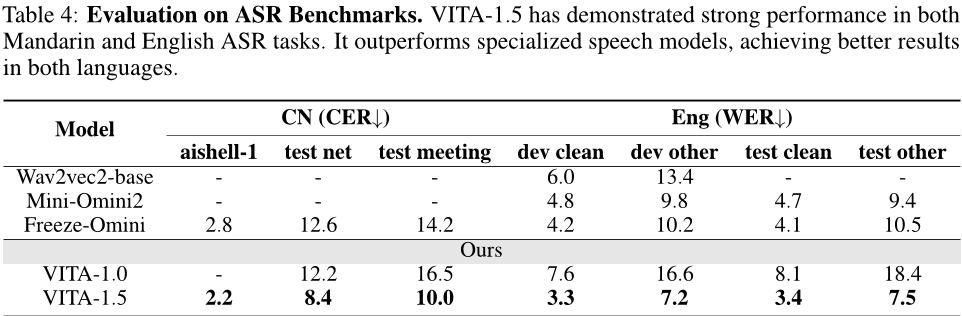
基线。以下三个基准模型用于比较:Wav2vec2-base [1],Mini-Omini2 [57],Freeze-Omini [56] 和VITA-1.0 [16]。
评估基准。普通话评估集由三个数据集组成:aishell-1 [4]、test net [7] 和 test meeting [62]。这些数据集用于评估模型在普通话语音上的性能。评估指标是字符错误率(CER)。英语评估集包括四个数据集:dev-clean,dev-other,test-clean和test-other [43],它们用于评估模型在英语语音上的性能。评估指标是词错误率(WER)。
ASR性能。表4中的评估结果表明,VITA-1.5在普通话和英语的ASR任务中都取得了领先的准确率,这证明了VITA-1.5成功地集成了先进的语音能力以支持多模态交互。
结论
在本文中,我们介绍了VITA-1.5,这是一种多模态lm,旨在通过精心设计的三个阶段训练策略来整合视觉和语音。通过缓解模态之间的固有冲突,VITA-1.5在视觉和语音理解方面实现了强大的功能,实现了高效的语音交互,无需依赖单独的ASR或TTS模块。广泛的评估表明,VITA-1.5在多模式基准测试中表现具有竞争力。我们希望VITA-1.5能够接过VITA-1.0的旗帜,继续推动实时多模式交互领域开源模型的进展。
参考文献
[1]Alexei Baevski,Yuhao Zhou,Abdelrahman Mohamed和Michael Auli。wav2vec 2.0:一种用于语音表示的自监督学习框架。NeurIPS,2020年。
[2] 白金泽,白帅,杨树生,王世杰,谭思南,王鹏,林俊阳,周常,周敬仁。Qwen-vl:一种具有多功能的前沿视觉语言模型。arXiv预印本 arXiv:2308.12966,2023年。
[3]Tom Brown,Benjamin Mann,Nick Ryder,Melanie Subbiah,Jared D Kaplan,Prafulla Dhariwal,Arvind Neelakantan,Pranav Shyam,Girish Sastry,Amanda Askell等。语言模型是少样本学习者。NeurIPS,2020年。
【4】Hui Bu,Jiayu Du,Xingyu Na,Bengu Wu和Hao Zheng。Aishell-1:一个开源的普通话语音语料库和语音识别基线。在O-COCOSDA中。IEEE,2017年。
【5】Soravit Changpinyo,Piyush Sharma,Nan Ding和Radu Soricut。概念12m:将网络规模的图像文本预训练推向识别长尾视觉概念。在CVPR上发表于2021年。
【6】Guiming Hardy Chen,Shunian Chen,Ruifei Zhang,Junying Chen,Xiangbo Wu,Zhiyi Zhang,Zhihong Chen,Jianquan Li,Xiang Wan和Benyou Wang。Allava:利用gpt4v合成的数据为一个轻量级的视觉语言模型提供动力,2024年。
[7] 国国陈,柴树舟,王冠波,杜嘉宇,张伟强,翁超,苏丹,Daniel Povey,Jan Trmal,张俊博等。Gigaspeech:一个不断发展的多领域语音识别语料库,包含10,000小时的转录音频。arXiv预印本arXiv:2106.06909,2021年。
【8】林晨,李金松,董晓艺,张盼,臧宇航,陈泽辉,段浩东,王佳琦,乔宇,林大华等。我们正在评估大型视觉语言模型的正确方式吗?arXiv预印本 arXiv:2403.20330,2024年。
【9】林晨,李吉松,董晓艺,张盼,何丛辉,王佳琦,赵锋和林达华。ShareGPT4V:通过更好的标题改进大型多模态模型。arXiv预印本arXiv:2311.12793,2023年。
[10] 陈哲云,王卫云,浩天,叶盛龙,高张伟,崔二飞,文文文,胡孔志,罗家鹏,郑麻等。我们要gpt-4v多远?使用开源套件缩小与商业多模式模型的差距。arXiv预印本arXiv:2404.16821,2024。 [11] 陈喆,吴建南,王文海,苏伟杰,陈郭,邢森,钟穆燕,张清龙,朱西洲,陆磊威,李斌,罗平,陆同,乔宇,戴济锋。Internvl:扩展视觉基础模型并为通用的视觉语言任务对齐。arXiv预印本arXiv:2312.14238,2023年。
[12] 蒋未林,李卓翰,林子,应生,吴张浩,张连敏,郑四源,庄永浩,约瑟夫·冈萨雷斯,等。vicuna: 一个开源的聊天机器人,以90% * 的聊天质量给gpt-4带来深刻的印象。请参阅https:// 小羊驼。lmsys。org (2023年4月14日访问),2023年。 [13] Dai Wenliang,Li Junnan,Li Dongxu,Huat Tiong Anthony Meng,Zhao Junqi,Wang Weisheng,Li Boyang,Pascale N Fung 和 Steven Hoi。Instructblip:通过指令调整实现通用视觉语言模型。NeurIPS,2024年。
【14】傅超友,陈佩贤,沈云航,秦玉蕾,张梦丹,林旭,杨金瑞,郑晓武,李科,孙兴,吴云生,吉荣荣。Mme:一种用于多模态大型语言模型的综合评估基准。arXiv预印本arXiv:2306.13394,2023年。
【15】傅超友,戴宇涵,罗永东,李磊,任树怀,张仁瑞,王梓晗,周晨煜,沈云航,张梦丹等。Video-MME:视频分析中多模态语言模型的首个全面评估基准。arXiv预印本 arXiv:2405.21075,2024年。
[16]傅超友,林浩佳,龙祖伟,沈云航,赵梦,张一帆,董少奇,王雄,尹迪,马龙等。Vita:迈向开源交互式全模态大语言模型。arXiv预印本 arXiv:2408.05211,2024年。
[17] 董晓东,孙兴,刘子伟,王亮等。Mme-survey:一个关于多模态语言模型评估的综合调查。arXiv预印本 arXiv:2411.15296,2024年。
[18]亚历克斯·格雷夫斯,圣地亚哥·费尔南德斯,法乌斯蒂诺·戈麦斯和尤根·施密特胡贝尔。连接主义时间分类:用递归神经网络对未分段序列数据进行标记。在ICML上发表于2006年。
【19】顾佳锡,孟晓君,卢观松,侯鲁,牛民哲,梁小丹,姚磊伟,黄润辉,张威,姜欣等。Wukong:一个大规模中文跨模态预训练基准数据集。NeurIPS,2022。
[20] 桂天瑞,刘福晓,吴西洋,鲜睿琪,李宗霞,刘小宇,王习军,陈立昌,黄芙蓉,亚瑟·雅库布等。Hallusionbench:一种用于大型视觉语言模型中纠缠的语言幻觉和视觉错觉的高级诊断套件。在 CVPR 上发表,2024 年。
[21] Tuomo Hiippala,Malihe Alikhani,Jonas Haverinen,Timo Kalliokoski,Evanfiya Logacheva,Serafina Orekhova,Aino Tuomainen,Matthew Stone和John A Bateman。Ai2d-rst:一个包含1000个小学科学图表的多模态语料库。语言资源与评估,2021年。
[22]Hong Wenyi,Wang Weihan,Ding Ming,Yu Wenmeng,Lv Qingsong,Wang Yan,Cheng Yean,Huang Shiyu,Ji Junhui,Xue Zhao等。Cogvlm2:用于图像和视频理解的视觉语言模型。arXiv预印本arXiv:2408.16500,2024年。
[23] 胡圣鼎,屠宇格,韩旭,何超群,崔甘泉,龙翔,郑志,方悦伟,黄玉祥,赵维林等。Minicpm:通过可扩展的训练策略揭示小型语言模型的潜力。arXiv预印本 arXiv:2404.06395,2024年。
[24]Albert Q Jiang,Alexandre Sablayrolles,Arthur Mensch,Chris Bamford,Devendra Singh Chaplot,Diego de las Casas,Florian Bressand,Gianna Lengyel,Guillaume Lample,Lucile Saulnier等。Mistral 7b。arXiv预印本arXiv:2310.06825,2023年。
[25] 鲍丽,张可晨,张浩,郭东,张仁瑞,李锋,张远翰,刘子伟和李春源。Llava-next:更强的llm在野外增强多模态能力,2024年5月。
[26] 鲍丽, 张远翰, 郭东, 张仁瑞, 李锋, 张浩, 张可晨, 张培源, 李延伟, 刘子威等。Llava-onevision:一种简单的视觉任务转移方法。arXiv预印本 arXiv:2408.03326,2024年。
[27] 李坤昌, 王亚丽, 何一楠, 李逸卓, 王艺, 刘怡, 王尊, 徐吉兰, 陈郭, 罗平等。Mvbench:一个全面的多模态视频理解基准。在 CVPR,2024 年。
[28] 李艳伟, 张越辰, 王成尧, 钟志胜, 陈艺欣, 褚睿航, 刘少腾, 和 姜家亚。Mini-Gemini:挖掘多模态视觉语言模型的潜力。arXiv预印本 arXiv:2403.18814,2024年。
【29】 林斌,叶阳,朱彬,崔佳溪,宁慕楠,金鹏,袁利。 视频-LLaVA:通过投影前对齐学习统一视觉表示。arXiv预印本 arXiv:2311.10122,2023年。
【30】 Ji Lin,Hongxu Yin,Wei Ping,Yao Lu,Pavlo Molchanov,Andrew Tao,Huizi Mao,Jan Kautz,Mohammad Shoeybi和Song Han。Vila:视觉语言模型的预训练,2023年。
刘浩天,李春元,吴青阳和Lee Yong Jae。视觉指令调整。arXiv预印本arXiv:2304.08485,2023年。
【32】刘源,段浩东,张远翰,李博,张松阳,赵望波,袁一科,王佳琦,何丛辉,刘梓威等。Mmbench:你的多模态模型是全能选手吗?arXiv预印本arXiv:2307.06281,2023年。
【33】刘远欣,李世成,刘艺,王玉翔,任树怀,李磊,陈思硕,孙旭和侯路。Tempcompass:视频LLMs真的理解视频吗?arXiv预印本arXiv:2403.00476,2024年。
刘玉良,张丽,杨彪,李春源,尹旭成,刘承林,金连文和白翔。在大型多模态模型中隐藏的OCR神秘面纱。arXiv预印本arXiv:2305.07895,2023年。
[35] 刘子涵,平伟,罗拉吉什,徐鹏,李灿宇,穆罕默德·肖伊比和布莱恩·卡坦扎罗。ChatQA:在对话式问答和RAG上超越GPT-4。arXiv预印本arXiv:2401.10225,2024年。
[36] 露皓宇,刘文,张博,王冰轩,董凯,刘波,孙景祥,任同征,李卓舒,孙耀峰等。Deepseek-vl:迈向现实世界的视觉语言理解。arXiv预印本 arXiv:2403.05525,2024年。
[37] Pan Lu,Hritik Bansal,Tony Xia,Jiacheng Liu,Chunyuan Li,Hannaneh Hajishirzi,Hao Cheng,Kai-Wei Chang,Michel Galley,and Jianfeng Gao.Mathvista:Evaluating mathematical reasoning of foundation models in visual contexts.arXiv预印本arXiv:2310.02255,2023。
[38] Pan Lu,Swaroop Mishra,Tanglin Xia,Liang Qiu,Kai-Wei Chang,Song-Chun Zhu,Oyvind Tafjord,Peter Clark和Ashwin Kalyan。学会解释:通过科学问题回答中的思维链进行多模态推理。NeurIPS,2022年。
[39]Lu Shiyin,Li Yang,Chen Qing-Guo,Xu Zhao,Luo Weihua,Zhang Kaifu,Ye Han-Jia.Ovis:Structural embedding alignment for multimodal large language model.arXiv预印本arXiv:2405.20797,2024。
[40]Dan Oneat,a˘和Horia Cucu。通过数据增强和语音表示来改善多模态语音识别。在CVPR上发表于2022年。
【41】OpenAI。GPT-4技术报告。2023年。
【42】OpenAI。你好,gpt-4o。2023年。
[43] Vassil Panayotov,Guoguo Chen,Daniel Povey和Sanjeev Khudanpur。Librispeech:基于公共领域音频书籍的ASR语料库。在ICASSP上发表于2015年。
[44] V Madhusudhana Reddy,T Vaishnavi和K Pavan Kumar。使用深度学习的语音到文本和文本到语音识别。在ICECAA上发表。IEEE,2023年。
[45] 永仁,王涛,易江燕,徐乐,陶建华,张元楚和周俊卓。具有时间不变码的少令牌神经语音编解码器。在ICASSP上发表。IEEE,2024年。
[46] Christoph Schuhmann,Romain Beaumont,Richard Vencu,Cade Gordon,Ross Wightman,Mehdi Cherti,Theo Coombes,Aarush Katta,Clayton Mullis,Mitchell Wortsman 等人。Laion-5b:用于训练下一代图像文本模型的开放大型数据集。NeurIPS,2022年。
[47] 分享。分享双子座:为多模态大型语言模型扩展视频字幕数据,2024年6月。https://github.com/Share14/ShareGemini。
【48】Rohan Taori,Ishaan Gulrajani,Tianyi Zhang,Yann Dubois,Xuechen Li,Carlos Guestrin,Percy Liang和Tatsunori B Hashimoto。斯坦福骆驼:一种遵循指令的美洲驼模型,2023年。
【49】Chameleon团队。变色龙:混合模态早期融合基础模型。arXiv预印本arXiv:2405.09818,2024年。
[50] 双子座团队、罗汉·阿尼尔、塞巴斯蒂安·博格奥德、永辉吴、让-巴蒂斯特·阿莱拉克、于家辉、拉杜·索里库特、约汉·施卡尔威克、安德鲁·米·戴、安雅·豪特等人。gemini: 一系列高效的多模式模型。arXiv预印本arXiv:2312.11805,2023。 [51] 生邦通,艾利斯布朗,彭昊吴,Sanghyun Woo,Manoj Middepogu,Sai chartha Akula,jihang,Shusheng Yang,Adithya Iyer,Xichen Pan,等。寒武纪-1: 对多模态llms的完全开放、以愿景为中心的探索。arXiv预印本arXiv:2406.16860,2024。 [52] 雨果Touvron,Thibaut Lavril,gauier Izacard,Xavier Martinet,Marie-Anne Lachaux,timo-thee Lacroix,Baptiste roere,Naman Goyal,Eric Hambro,Faisal Azhar等。美洲驼: 开放高效的基础语言模型。arXiv预印本arXiv:2302.13971,2023。 [53] 乌戈图瓦龙、路易·马丁、凯文·斯通、彼得·阿尔伯特、阿姆贾德·阿尔马海里、Yasmine Babaei、Nikolay Bashlykov、Soumya Batra、prajwal Bhargava、Shruti Bhosale等人。llama 2: 开放基础和微调的聊天模型。arXiv预印本arXiv:2307.09288,2023。 【54】Yuxiang Tuo,Wangmeng Xiang,Jun-Yan He,Yifeng Geng和Xuansong Xie。Anytext:多语言视觉文本生成与编辑。arXiv预印本arXiv:2311.03054,2023年。
[55] 王俊克,孟凌琛,翁泽佳,何博,吴祖轩和姜玉刚。看到就是相信:提示GPT-4V以获得更好的视觉指令调整。arXiv预印本arXiv:2311.07574,2023年。
【56】熊王,李洋泽,付超友,谢磊,李科,孙兴和马龙。冻结万能:一种具有冻结语言模型的智能低延迟语音到语音对话模型。arXiv预印本arXiv:2411.00774,2024年。
[57]谢之飞,吴长桥。Mini-omni2:迈向具有视觉、语音和双工能力的开源gpt-4o。arXiv预印本arXiv:2410.11190,2024年。
【58】叶佳博,胡安文,徐海阳,叶清豪,严明,许国海,李晨亮,田俊峰,钱奇,张吉等。Ureader:基于多模态大语言模型的无OCR视觉情景化语言理解。arXiv预印本 arXiv:2310.05126,2023年。
【59】Yu Weihao,Yang Zhengyuan,Li Linjie,Wang Jianfeng,Lin Kevin,Liu Zicheng,Wang Xinchao,and Wang Lijuan.Mm-vet:评估大型多模态模型的综合能力。arXiv预印本arXiv:2308.02490,2023年。
【60】Xiang Yue,Yuansheng Ni,Kai Zhang,Tianyu Zheng,Ruoqi Liu,Ge Zhang,Samuel Stevens,Dongfu Jiang,Weiming Ren,Yuxuan Sun等。Mmmu:一个面向专家agi的海量多学科多模态理解和推理基准。在IEEE/CVF计算机视觉与模式识别会议论文集上发表,页码9556-9567,2024年。
[61] Jun Zhan,Junqi Dai,Jiasheng Ye,Yunhua Zhou,Dong Zhang,Zhigeng Liu,Xin Zhang,Ruibin Yuan,Ge Zhang,Linyang Li等。AnyGPT:具有离散序列建模的统一多模式LLM。arXiv预印本arXiv:2402.12226,2024年。
[62] 张彬彬,吕航,郭鹏程,邵启杰,杨超,谢磊,徐欣,步慧,陈晓宇,曾晨辰等。Wenetspeech:面向语音识别的多域中文语料库(超过10000小时)。在ICASSP上发表,2022年。
[63] 张东,李世民,张新,詹军,王鹏宇,周雅倩和邱夕朋。SpeechGPT:通过内在跨模态对话能力增强大型语言模型。arXiv预印本 arXiv:2305.11000,2023年。
【64】 张盼,董晓怡,王斌,曹宇航,徐超,欧阳林科,赵志远,丁双瑞,张松阳,段浩东,严杭等。Internlm-xcomposer:一种用于高级文本-图像理解和合成的视觉语言大型模型。arXiv预印本 arXiv:2309.15112,2023年。
【65】 张培源,张可晨,李博,曾广涛,杨京康,张远翰,王梓越,谭浩然,李春元,刘子伟。从语言到视觉的长上下文转移。arXiv预印本 arXiv:2406.16852,2024年。
[66] 张一帆,文清松,付超友,王雪,张章,王亮,金荣。超越llava-hd:深入高分辨率大型多模态模型。arXiv预印本arXiv:2406.08487,2024年。
[67] 张一帆,张焕宇,田浩辰,付超友,张双庆,吴俊飞,李锋,王坤,文清松,张章等。Mme-realworld:您的多模态llm是否能够挑战人类难以应对的高分辨率现实世界场景?arXiv预印本arXiv:2408.13257,2024年。



















 526
526

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











