







今天有个同事给我打电话问我题目列出的这个问题,在日常开发中,确实它们俩都是与分组有关的,但是需要注意的是一个是分组函数另一个是分析函数,讲解用到的表就以Oracle中schema的scott的EMP表和DEPT表为例做讲解:
结果就不贴出来了,可以看到的是整个EMP表里面的数据分成了三条,每条数据针对一个部门,对于分组函数而言,它不关心每个分组里面到底是由谁构成的,或者是相对于个体,分组函数是站在一个宏观的角度上看待数据的;
说到这,大家估计开始琢磨到底什么区别了,同样,以求部门工资总和为例:
执行结果为:
下面再看一下:
输出结果为:
输出结果:
老总下命令说:需要统计下公司里每个部门的人数以及每个部门的工资发放的工资总和;先分析下统计每个部门的人数和工资总和,指的是将不同部门的人员分别放到不同的地方,然后再将不同部门的人数一个个数出来,以及工资一个个加出来,也就是说表里面的数据是零散的,通过分组函数分组后展示出来的是以组为单位的几个数据块,需要注意的是分组完成之后的数据块是一个整体为单位的,所以对于这个整体不允许使用比如针对块里单个对象做处理
,正式因为如此,很多初学的人都会犯这种类型的错误,好的,上SQL;
SELECT DEPTNO 部门编号,COUNT(*) AS 部门人数,SUM(sal) 部门工资总和 FROM emp GROUP BY deptno ORDER BY SUM(sal) DESC;
好的,那么又一个需求来了,如果需要显示每个部门的员工姓名、工资、该员工在部门里的工资排序,部门的工资总和呢?那么这个时候使用partition by就要方便的多,看代码:
SELECT deptno 部门名称 ,ename 员工姓名, sal 员工工资, ROW_NUMBER() OVER(PARTITION BY deptno ORDER BY sal) 所在部门工资排序 FROM emp;
- -- 使用分组函数GROUP BY方式
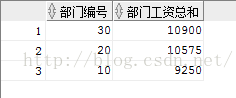
SELECT deptno 部门编号,SUM(sal) 部门工资总和 FROM emp GROUP BY deptno;
下面再看一下:
- -- 使用分析函数 PARTITION BY方式
SELECT deptno 部门编号,SUM(SAL) OVER (partition by sal) 部门工资总和 FROM emp;
对于这个结果大家可能会比较奇怪,其实这也正是这两个函数的区别,如果还是觉得不清晰,再看下面这个更具体的例子:
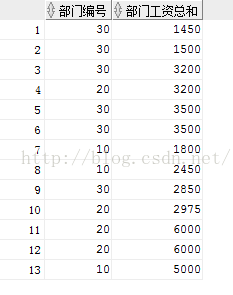
SELECT deptno 部门名称 ,ename 员工姓名, sal 员工工资, SUM(sal) OVER(PARTITION BY deptno ORDER BY sal) 所在部门工资总和 FROM emp;
通过上面三个例子可以得出以下结论:
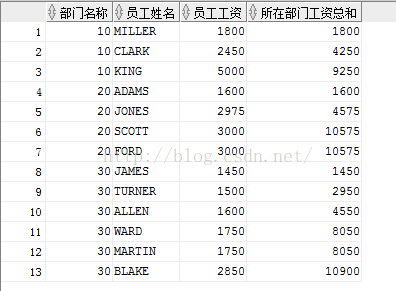
1、字面意思上来看,分组函数是对于整体而言的,分析函数是用来分析个体而言的,呈现的结果也验证了这一点;
2、对于GROUP BY而言,是从整体宏观上把握分组后的数据模块,对于PARTITION BY而言,它虽然也是讲数据分组,但是它是从每个数据模块的个体出发,进行相应操作的,比如上述工资总和,比如每个部门有100个员工,用了它之后会有100条求和累加数据显示出来;
总之一句话,GROUP BY将分组后的块看成一个整体,忽略个体;PARTITION BY也是看成整体,但是重视个体!















 4918
4918

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









