







【优化】windows双网叠加 多网叠加 网速叠加 教程
1 连接两个以上的网络, 网络不能是同一个
例如 网线-A + wifi-B
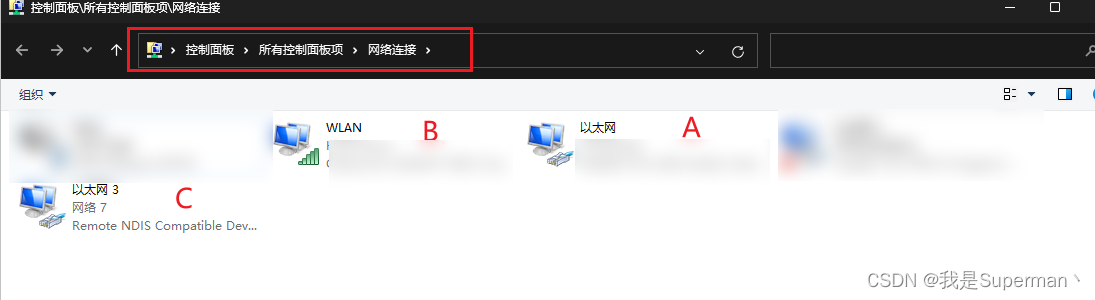
2 控制面板\所有控制面板项\网络连接
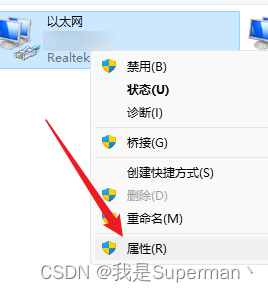
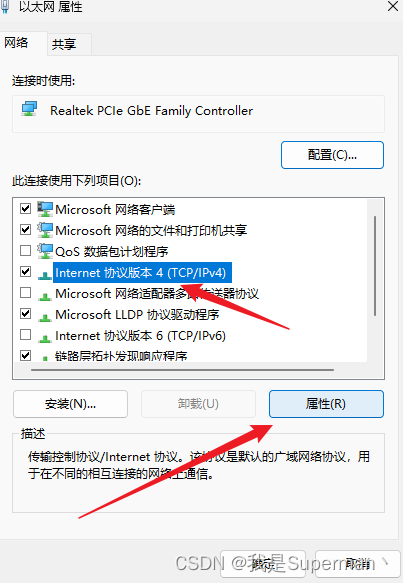
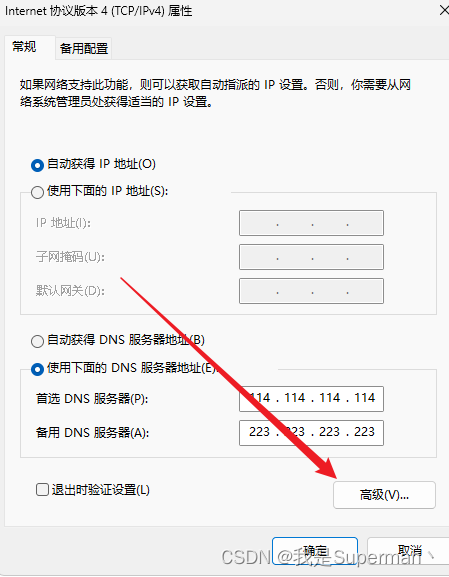
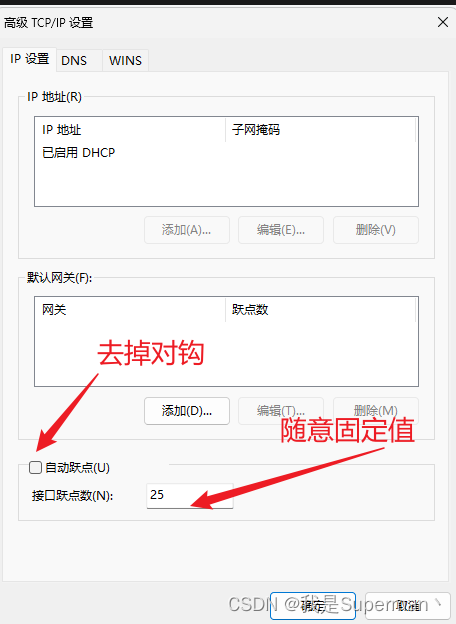
最后 确定保存
同理 修改wifi-B的接口活跃点数为 25 并保存
如果没有生效 可以将两个网络连接禁用 再启用
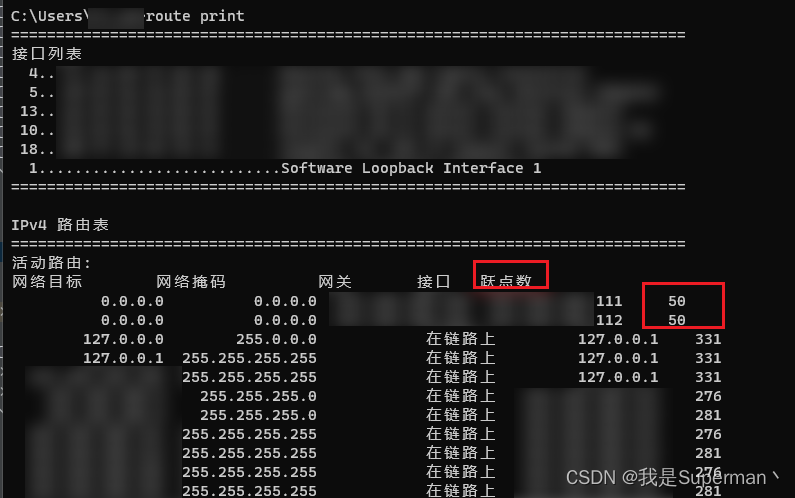
通过命令行 route print 查询当前两个路由的跃点数, 如果不一样的话 根据上述教程调整成一样的跃点数, 可能会不一致, 每调整一次可以执行一下命令 route print 看看还差多少, 最终调整成一致即可
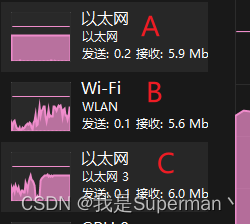
可以通过任务管理器-性能 对应的网卡判断网速是否叠加
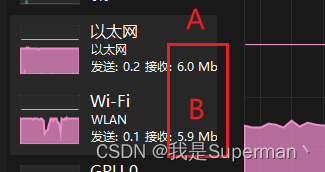
补充三网叠加 PS通过手机USB网络共享了一个网卡C
保持跃点数一直就行 route print
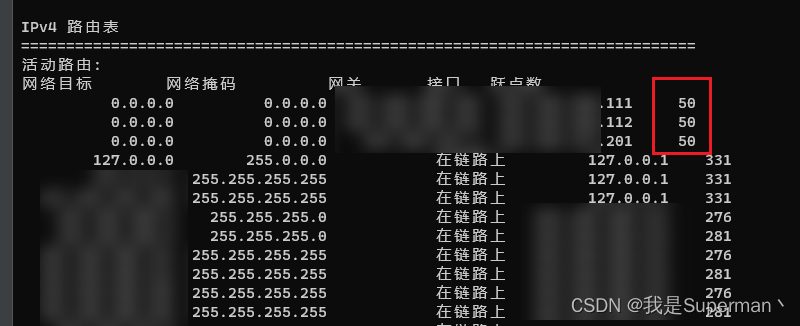
在控制面板里调整跃点数 , 一定要点保存, 然后陆续点确定回来
注意:
如果哪个网卡网速掉了的话 可以调整跃点数优先级 跃点数越小 优先级越高


















 6851
6851

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











