






SGD,Momentum,Adagard,Adam原理-面试哥
https://blog.csdn.net/qq_23236081/article/details/115444628
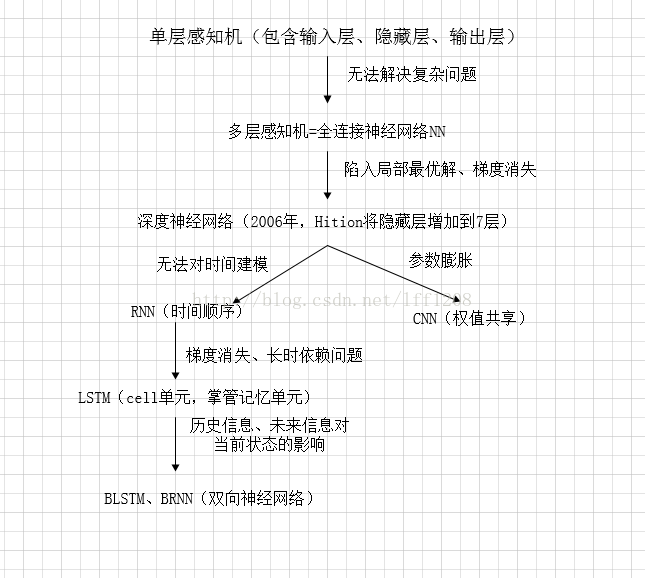
一、神经网络的来源
神经网络技术起源于上世纪五、六十年代,当时叫感知机(perceptron),包含有输入层、输出层和一个隐藏层。输入的特征向量通过隐藏层变换到达输出层,由输出层得到分类结果。但早期的单层感知机存在一个严重的问题——它对稍微复杂一些的函数都无能为力(如异或操作)。直到上世纪八十年代才被Hition、Rumelhart等人发明的多层感知机克服,就是具有多层隐藏层的感知机。
多层感知机可以摆脱早期离散传输函数的束缚,使用sigmoid或tanh等连续函数模拟神经元对激励的响应,在训练算法上则使用Werbos发明的反向传播BP算法。这就是现在所说的神经网络NN。
神经网络的层数直接决定了它对现实的刻画能力——利用每层更少的神经元拟合更加复杂的函数。但问题出现了——随着神经网络层数的加深,优化函数越来越容易陷入局部最优解,并且这个“陷阱”越来越偏离真正的全局最优。利用有限数据训练的深层网络,性能还不如较浅层网络。同时,另一个不可忽略的问题是随着网络层数增加,“梯度消失”现象更加严重。(具体来说,我们常常使用sigmoid作为神经元的输入输出函数。对于幅度为1的信号,在BP反向传播梯度时,每传递一层,梯度衰减为原来的0.25。层数一多,梯度指数衰减后低层基本上接受不到有效的训练信号。)
2006年,Hition提出了深度学习的概念,引发了深度学习的热潮。具体是利用预训练的方式缓解了局部最优解的问题,将隐藏层增加到了7层,实现了真正意义上的“深度”。
DNN形成

为了克服梯度消失,ReLU、maxout等传输函数代替了sigmoid,形成了如今DNN的基本形式。结构跟多层感知机一样,如下图所示:
我们看到全连接DNN的结构里下层神经元和所有上层神经元都能够形成连接,从而导致参数数量膨胀。假设输入的是一幅像素为1K*1K的图像,隐含层有1M个节点,光这一层就有10^12个权重需要训练,这不仅容易过拟合,而且极容易陷入局部最优。
CNN形成
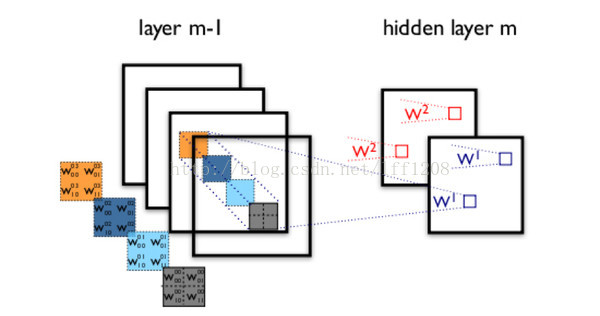

由于图像中存在固有的局部模式(如人脸中的眼睛、鼻子、嘴巴等),所以将图像处理和神将网络结合引出卷积神经网络CNN。CNN是通过卷积核将上下层进行链接,同一个卷积核在所有图像中是共享的,图像通过卷积操作后仍然保留原先的位置关系。
通过一个例子简单说明卷积神经网络的结构。假设我们需要识别一幅彩色图像,这幅图像具有四个通道ARGB(透明度和红绿蓝,对应了四幅相同大小的图像),假设卷积核大小为100*100,共使用100个卷积核w1到w100(从直觉来看,每个卷积核应该学习到不同的结构特征)。
用w1在ARGB图像上进行卷积操作,可以得到隐含层的第一幅图像;这幅隐含层图像左上角第一个像素是四幅输入图像左上角100*100区域内像素的加权求和,以此类推。
同理,算上其他卷积核,隐含层对应100幅“图像”。每幅图像对是对原始图像中不同特征的响应。按照这样的结构继续传递下去。CNN中还有max-pooling等操作进一步提高鲁棒性。
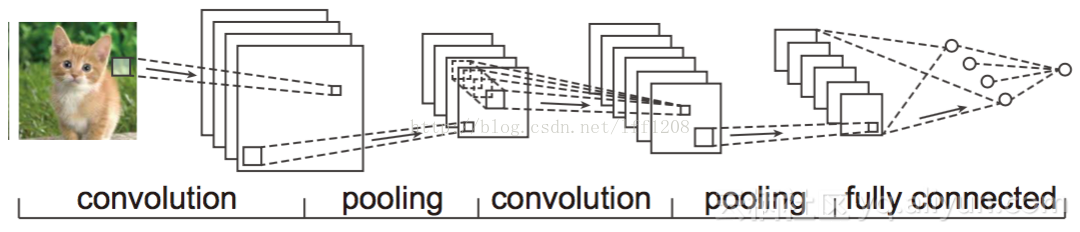
注意到最后一层实际上是一个全连接层,在这个例子里,我们注意到输入层到隐藏层的参数瞬间降低到了100*100*100=10^6个!这使得我们能够用已有的训练数据得到良好的模型。题主所说的适用于图像识别,正是由于CNN模型限制参数了个数并挖掘了局部结构的这个特点。顺着同样的思路,利用语音语谱结构中的局部信息,CNN照样能应用在语音识别中。
RNN形成
DNN无法对时间序列上的变化进行建模。然而,样本出现的时间顺序对于自然语言处理、语音识别、手写体识别等应用非常重要。为了适应这种需求,就出现了大家所说的另一种神经网络结构——循环神经网络RNN。雷锋网
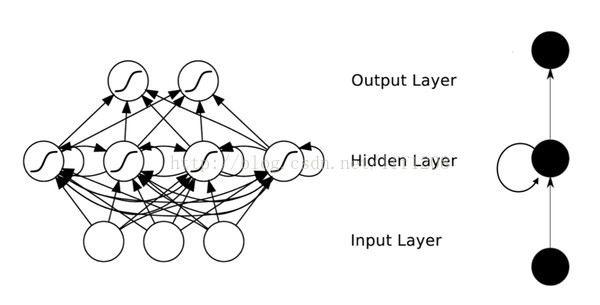
在普通的全连接网络或CNN中,每层神经元的信号只能向上一层传播,样本的处理在各个时刻独立,因此又被成为前向神经网络(Feed-forward Neural Networks)。而在RNN中,神经元的输出可以在下一个时间段直接作用到自身,即第i层神经元在m时刻的输入,除了(i-1)层神经元在该时刻的输出外,还包括其自身在(m-1)时刻的输出!表示成图就是这样的:
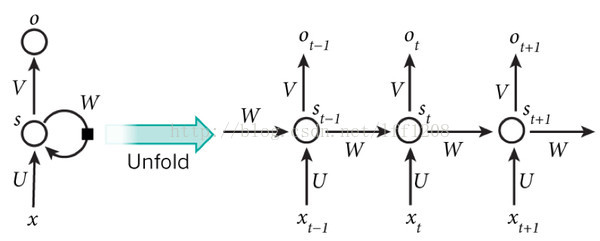
为方便分析,按照时间段展开如下图所示:
(t+1)时刻网络的最终结果O(t+1)是该时刻输入和所有历史共同作用的结果!这就达到了对时间序列建模的目的。RNN可以看成一个在时间上传递的神经网络,它的深度是时间的长度!正如我们上面所说,“梯度消失”现象又要出现了,只不过这次发生在时间轴上。
所以RNN存在无法解决长时依赖的问题。为解决上述问题,提出了LSTM(长短时记忆单元),通过cell门开关实现时间上的记忆功能,并防止梯度消失,LSTM单元结构如下图所示:
除了DNN、CNN、RNN、ResNet(深度残差)、LSTM之外,还有很多其他结构的神经网络。如因为在序列信号分析中,如果我能预知未来,对识别一定也是有所帮助的。因此就有了双向RNN、双向LSTM,同时利用历史和未来的信息。
事实上,不论是哪种网络,他们在实际应用中常常都混合着使用,比如CNN和RNN在上层输出之前往往会接上全连接层,很难说某个网络到底属于哪个类别。不难想象随着深度学习热度的延续,更灵活的组合方式、更多的网络结构将被发展出来。
二、BP算法
作为深度学习领域的破冰之作,BP神经网络重新燃起了人们对深度学习的热情.它解决了DNN中的隐层传递中的权重值的计算问题.那么,BP算法思想是什么?它又是如何实现的呢?这就是本节的研究内容.
一.BP算法的提出及其算法思想
神经网络主要是由三个部分组成的,分别是:1) 网络架构 2) 激活函数 3) 找出最优权重值的参数学习算法.
BP算法就是目前使用较为广泛的一种参数学习算法.
BP(back propagation)神经网络是1986年由Rumelhart和McClelland为首的科学家提出的概念,是一种按照误差逆向传播算法训练的多层前馈神经网络。
既然我们无法直接得到隐层的权值,能否先通过输出层得到输出结果和期望输出的误差来间接调整隐层的权值呢?BP算法就是采用这样的思想设计出来的算法,它的基本思想:学习过程由信号的正向传播(求损失)与误差的反向传播(误差回传)两个过程组成。如图1所示为BP算法模型示意图.

二.BP算法、前向传播和反向传播
2.1 BP算法的一般流程
根据BP算法的基本思想,可以得到BP算法的一般过程:
1) 正向传播FP(求损失).在这个过程中,我们根据输入的样本,给定的初始化权重值W和偏置项的值b, 计算最终输出值以及输出值与实际值之间的损失值.如果损失值不在给定的范围内则进行反向传播的过程; 否则停止W,b的更新.
2) 反向传播BP(回传误差).将输出以某种形式通过隐层向输入层逐层反传,并将误差分摊给各层的所有单元,从而获得各层单元的误差信号,此误差信号即作为修正各单元权值的依据。
由于BP算法是通过传递误差值δ进行更新求解权重值W和偏置项的值b, 所以BP算法也常常被叫做δ算法.
下面我们将以三层感知器结构为例,来说明BP算法的一般计算方法(假设个隐层和输出层的激活函数为f).
图2 三层感知器结构

BP算法网络结构的示意图如图3所示.

BP和梯度下降法的关系 和CNN的关系
不同。BP算法是用来计算损失函数相对于神经网络参数的梯度。而梯度下降法是一种优化算法,用于寻找最小化损失函数的参数。 梯度下降法及其它优化算法(如 Adam 或 Adagrad等)都依赖BP来得到梯度。
CNN和BP
一个维度的BP神经网络就相当于CNN中的全连接了,无非是多几个全连接,CNN是二维,二维如果搞成全连接就导致运算量巨大,所以有了权重共享,大大减少了运算量,CNN卷积的思想肯定也源于BP神经网络就,在图像上做二维卷积的CNN发出炫目的光芒下,BP神经网络就已经快被人们遗忘了,但是不管CNN再怎么发展,不要忘了它的思想的根源依然是BP,
至于二维卷积问题,其实图像处理里边早都有了各种微分和积分的卷积模板这样做过的,或许是受这些思想的启发,卷积的形式可以这样搞,不熟的话复习下刚萨雷斯的图像处理,拉普拉斯微分卷积、高斯模糊卷积等
广义的BP就是反向传播,它是一种思想,贯穿于整个深度学习,不管是RNN、LSTM还是当前最火的CNN,这个BP的算法也源于BP神经网络的发明
三、sigmoid、softmax、relu、tanh
激活函数使用原因
如果不用激励函数,每一层输出都是上层输入的线性函数,无论神经网络有多少层,输出都是输入的线性组合。
如果使用的话,激活函数给神经元引入了非线性因素,使得神经网络可以任意逼近任何非线性函数,这样神经网络就可以应用到众多的非线性模型中。
比如,在单层感知机中,分类的结果大于某个值为一类,小于某个值为一类,这样的话就会使得输出结果在这个点发生阶跃,logistic函数解决了阶跃函数的突然阶跃问题,使得输出的为0-1的概率,使得结果变得更平滑,他是一个单调上升的函数,具有良好的连续性,不存在不连续点。
1. softmax函数
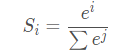
映射区间[0,1]
主要用于:离散化概率分布
2. sigmoid函数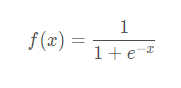
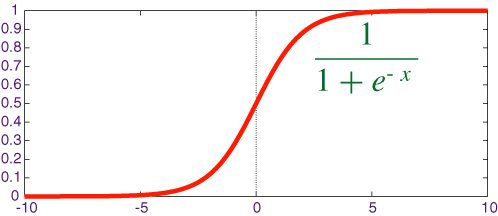
映射区间(0, 1)
也称logistic函数
在神经网络中的反向传播
sigmoid函数求导
sigmoid就是极端情况(类别数为2)下的softmax
所以sigmoid的最大值取值为1 / 4 1/41/4
所以sigmoid在多层神经网络中不常用到,因为会产生梯度消失,为什么呢?我们在反向传播的时候,求梯度都是链式法则,也就是说多个导数式子连乘的形式,因为sigmoid的最大值也就是1 / 4 1/41/4,所以整个梯度就会变得非常的小。
3. tanh函数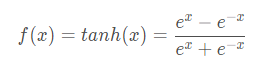
映射区间 (-1,1)
也称双切正切函数
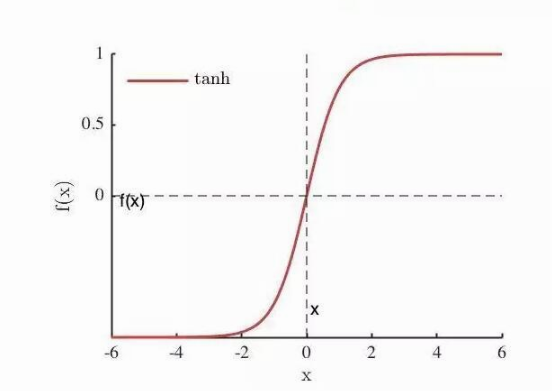
sigmoid函数和tanh函数都存在一个问题:当神经网络的层数增多的时候,由于在进行反向传播的时候,链式求导,多项相乘,函数进入饱和区(导数接近于零的地方)就会逐层传递,这种现象被称为梯度消失。
比如:sigmoid函数与其导数的函数如下,可以看出梯度消失的问题
解决办法:可以采用批标准化(batch normalization)来解决
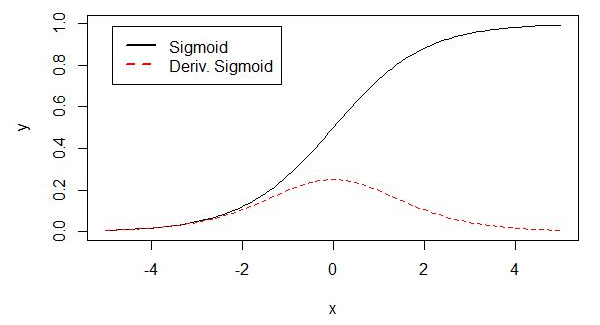
4. ReLU函数
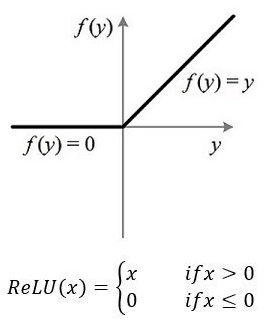
映射区间:[0,+∞)
RELU函数的优点:
相关大脑方面的研究表明生物神经元的信息编码通常是比较分散及稀疏的。通常情况下,大脑中在同一时间大概只有1%-4%的神经元处于活跃状态。使用线性修正以及正则化(regularization)可以对机器神经网络中神经元的活跃度(即输出为正值)进行调试;相比之下,逻辑函数在输入为0时达到1/2 , 即已经是半饱和的稳定状态,不够符合实际生物学对模拟神经网络的期望。不过需要指出的是,一般情况下,在一个使用修正线性单元(即线性整流)的神经网络中大概有50%的神经元处于激活态;
更加有效率的梯度下降以及反向传播:避免了梯度爆炸和梯度消失问题;
简化计算过程:没有了其他复杂激活函数中诸如指数函数的影响;同时活跃度的分散性使得神经网络整体计算成本下降。
RELU总结
虽然ReLU函数大于零的部分和小于零的部分分别都是线性函数,但是整体并不是线性函数,所以仍然可以做为激活函数,ReLU函数其实是分段线性函数,把所有的负值都变为0,而正值不变,这种操作被成为单侧抑制。
在训练数据的时候,由于对于不同的任务,可能某些神经元的输出影响就比较大,有些则小,甚至有些则无,类似于人的大脑,左脑和右脑分别管理逻辑能力与想象力,当使用右脑的时候,就抑制左脑,当使用左脑的时候,抑制右脑,RELU函数正好可以实现小于0的数直接受到抑制,这就使得神经网络的激活更接近于生物学上的处理过程,给神经网络增加了生命。
总结
因为线性模型的表达能力不够,引入激活函数是为了添加非线性因素;
然后发展出了很多的激活函数适用于各种模型的训练;
RELU函数的引入给神经网络增加了生物学特性,可以称为灵魂激活函数。
yolov3&yolov4&yolov5比较_程序猿的视界-CSDN博客
一步一步教你反向传播,求梯度(A Step by Step Backpropagation Example)_wawaku的博客-CSDN博客_反向传播求梯度
Pytorch 疑案之:优化器和损失函数是如何关联起来的?_JintuZheng的博客-CSDN博客_损失函数和优化器的关系















 477
477











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









