







星型模型(Star Schema)
由一个事实表和多个维度表组成,事实表与维表通过主键外键相关联,维表之间不存在关联关系,当所有维表都关联到事实表时,整个图形非常像一种星星的结构。
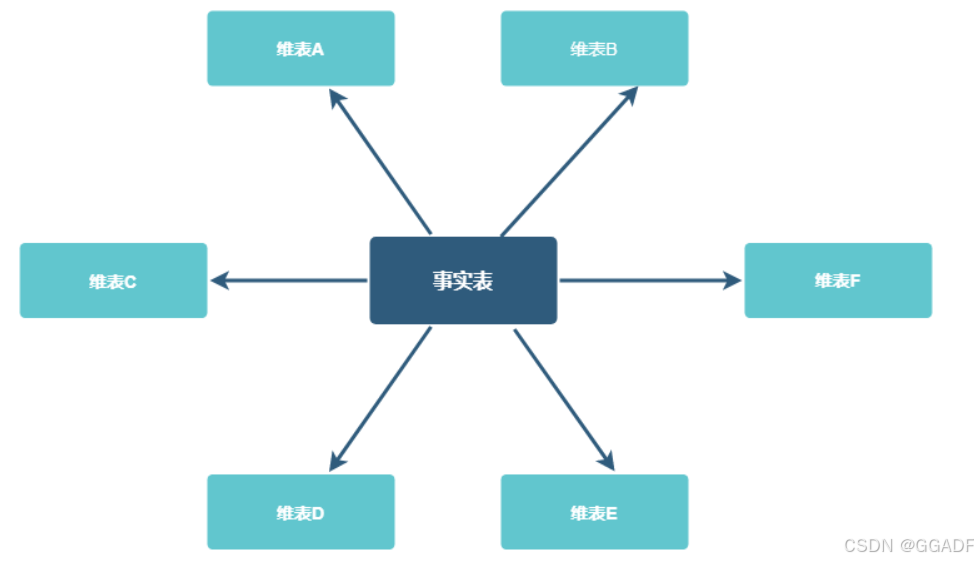
优点:
- 结构简单:易于理解和维护。
- 查询性能高:结构简单且非规范化,查询速度快。
缺点:
- 数据冗余:存在数据冗余。因为其维表只有一个层级,有些信息被存储了多次。
适用场景:用于大多数数据仓库场景,特别是需要高查询性能和简单结构的场景。
雪花模型(Snowflake Schema)
在星型模型的基础上,将维度表进一步规范化,分解为多个相关的表。一个或多个维表没有直接连接到事实表上,而是通过其他维表连接到事实表上。
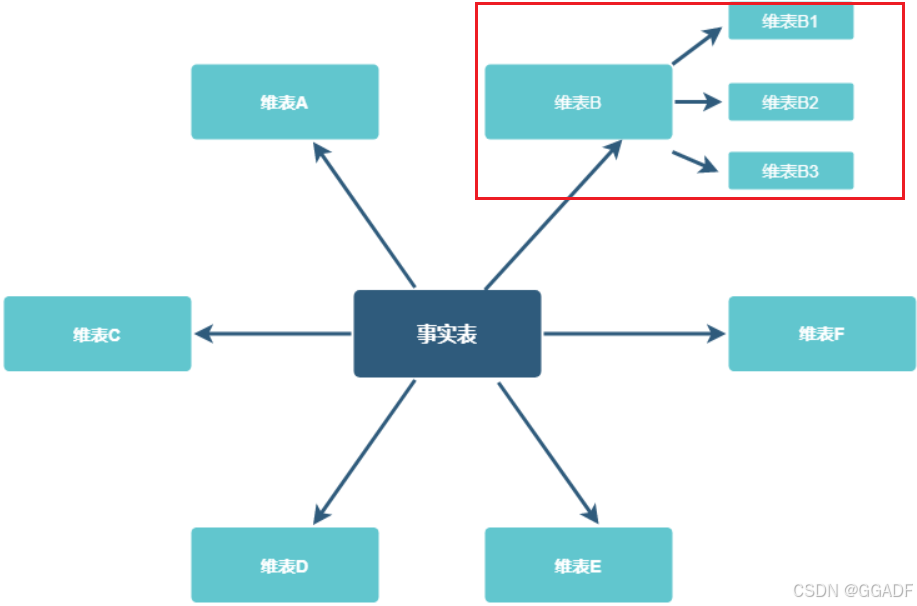
优点:
- 减少数据冗余:规范化设计减少了数据冗余,节省存储空间。
- 数据一致性:规范化设计有助于维护数据一致性。
缺点:
-
查询性能较低:由于查询需要连接多个表,查询速度可能较慢。
-
复杂性高:结构复杂,不易理解和维护。
适用场景:适用于需要高度规范化和数据一致性的场景,但对查询性能要求不高的场景。
星座模型(Galaxy Schema)
在星型模型和雪花模型的基础上进一步发展,适用于处理多个业务过程(多个事实表)的场景。多个事实表共享某些维度表。
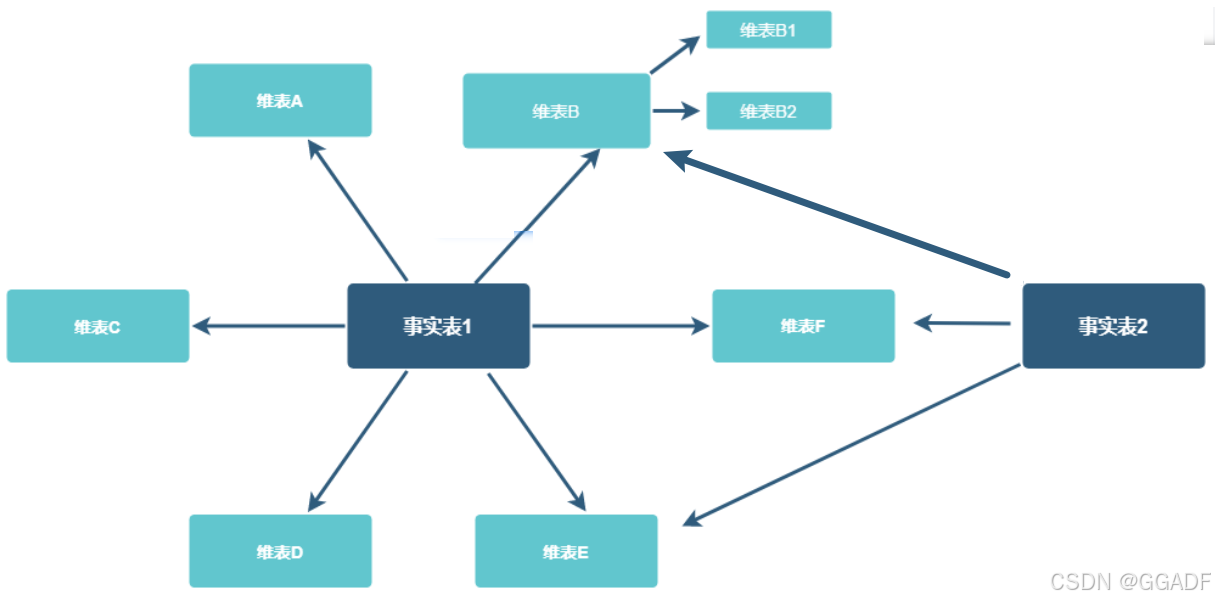
优点:
- 减少冗余:共享维度表减少了数据冗余,节省存储空间。
- 支持复杂分析:可以跨多个事实表进行复杂的分析和查询。
缺点:
- 复杂性高:结构复杂,设计和维护难度相对较大,需仔细规划维度表和事实表之间的关系。
- 查询性能较低:由于查询可能涉及多个事实表,复杂的连接操作,查询性能可能受到影响。
适用场景:适用于复杂的,需要处理多个业务过程且需要共享维度的场景。

















 8669
8669

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









