










开始之前,总体梳理一下项目流程,大致了解一下我们是怎么一步一步得到最终结果的

1、创建训练数据集
- 下载数据(链接:https://pan.baidu.com/s/1tM4ZXplEP2MC787OKSgt6A 提取码:achj)
- 克隆python环境(关于克隆环境和安装包上一篇有详细步骤)
- 添加Python包:scikit-learn和seaborn
1)-程序包管理器中“添加程序包”
2)-Conda或pip安装
4.打开工程文件
分析之前需要了解诸如海洋温度,盐度和营养物浓度之类的变量,以预测海草生长地点的适宜性。由于字段数据并不完美,并且通常缺少值,因此您需要填写值以完成原始数据,然后才能在分析中使用它们。
共有四个要素类:
- EMU_Global_90m:生态海洋单位点数据,其中包含高达90米水深的海洋测量值。
- Seagrass_USA:海草发生的面数据。Seagrass_USA中的每个多边形都是确定的海草栖息地。
- US_coastline_shallow:美国海岸的多边形数据,其覆盖的测深范围一直到在Seagrass_USA中观察到海草栖息地的深度。
- bathymetry_shallow:全局浅测深多边形,用于全局预测海草。
打开EMU_Global_90m属性表,变量包括盐度,海洋温度和硝酸盐含量等。但包含许多缺失值。这些属性将作为预测变量用于随机森林模型中。

4.1 使用【填充缺失值】工具,设置如下参数后运行。要填充的字段分别为:氧气、硝酸盐、磷酸盐、盐度、硅酸盐、srtm30和温度。

(注:警告消息是由于盐度、SRTM30和温度属性没有缺失值,但稍后需要用它们分析)
填充后的属性表如下

_STD字段显示用于估计缺失值的相邻数据点的标准偏差。
_ESTIMATED字段:若使用工具填充了属性,则为1,若数据已存在,则为0。
现在,我们已获得所需海洋变量的空间完整数据。
此时,蓝圈表示添加了新数据值,空白圆圈表示仅包含原始数据。

4.2 图层符号化
对EMU_Global_90m_Filled图层在符号系统中选择“单一符号”,选择“Circle1”样式,大小设置为6pt

4.3 创建训练数据
接下来,将创建随机森林预测模型需要的训练数据,探究海草密度与海洋状况之间的关系。训练数据集将由7个预测变量(海洋测量值)和1个结果变量(位置是否合适的海草栖息地)组成。
为了便于稍后使用的Python脚本访问,这些预测变量必须位于单个要素类中。所以需要创建一个新的随机点要素类,将海洋测量数据添加到每个点。
4.3.1 将视图导航至“弗洛里达”书签的位置
4.3.2 打开【创建随机点】工具,设置如下参数后运行,生成10000个随机点

4.3.3 打开【经验贝叶斯克里金法】,输入EMU_Global_90m_Filled图层。对于Z值字段分别输出下列每一个属性的栅格结果:
| Z 值字段 | Output raster |
| TEMP(备注:TEMP_UNFILLED) | temp |
| DISSO2 (备注: DISSO2_FILLED) | dissO2 |
| NITRATE (备注: NITRATE_FILLED) | nitrate |
| PHOSPHATE (备注: PHOSPHATE_FILLED) | phosphate |
| SILICATE (备注: SILICATE_FILLED) | silicate |
| SRTM30 (备注: SRTM30_UNFILLED) | srtm30 |
| SALINITY (备注: SALINITY_UNFILLED) | salinity |
得到7幅栅格数据,类似下图

4.3.4 使用【提取多值到点】工具,设置如下参数运行,将上述7个属性的值提取到我们刚才生成的随机点中。

4.4 创建训练标签
为了让深度学习的模型了解什么样的海洋环境适合海草的生长,我们需要做一个简单的查询来区分在Seagrass_USA图层内(赋值1)或外(赋值0)的属性。
4.4.1 使用【添加字段】工具为USA_Train图层添加“Present”字段,设置为双精度类型

4.4.2 使用【计算字段】工具设置“Present”值为0
4.4.3 【按位置选择】“USA_Train”图层和“Seagrass_USA”图层【相交】的部分

4.4.4 再次使用【计算字段】工具,将选中要素赋值为1.
4.4.5 清空选择要素
流程

2、执行随机森林
之前,我们创建了具有8变量的训练数据集,这些数据有助于确定海草栖息地的适用性。现在,用准备好的数据和机器学习库来创建预测模型。
首先,检查变量的相关性,以确保随机森林分类是最佳选择。
随机森林是一种需要训练的有监督的机器学习方法,或者使用已知预测模型的数据集。
将数据分为两部分,一部分训练随机森林分类器,另一部分测试结果。根据结果的准确性,可以将模型应用于所拥有的全局数据,并将其保存为要素类。
2.1 将空间数据加入Python
导入所需要的模型库

2.2 选择分类


2.3 分割数据



2.4 训练随机森林分类器



最后将生成的“GlobalPrediction”图层添加到显示界面

3、评估预测结果
3.1使用【Kernel Density】,在环境选项卡中设置mask为Bathymetry_shallow。工具设置参数如下运行。

3.2 对结果图层【SeagrassHabitats】进行符号渲染,分类类型选择“拉伸”,配色方案选择Heat Map1
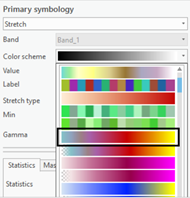
将图层属性的坐标系统中勾选“Enable wrapping around the date line ”,渲染结果如图所示

3.3 插入图框-激活-调整位置
3.4 插入文本框-设置标题
3.5 插入图例、比例尺……

















 951
951











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









