 视频相似度自动分割代码
视频相似度自动分割代码




作者最近在收集车祸视频的数据,网上的视频大多都是由视频博主们收集一段段的视频进行合并成的一个大视频,如果我一个个的进行剪辑的话会浪费掉大量的时间于是就打算弄一些视频根据相似度自动进行分割的代码。
代码如下:
import cv2
import numpy as np
import torch
from datetime import datetime
import torchvision.models as models
from torchvision import transforms
from scipy.spatial.distance import cosine
from collections import deque
import os
from moviepy.editor import VideoFileClip
import argparse
# 配置参数
SIMILARITY_THRESHOLD = 0.8 # 分割阈值(余弦相似度)
MIN_EVENT_LENGTH = 20 # 最小事件长度(帧数)
DEVICE = "cuda" if torch.cuda.is_available() else "cpu"
def get_video_paths(input_dir):
"""获取目录下所有视频文件路径(支持多格式)"""
video_extensions = ('.mp4', '.avi', '.mov', '.mkv', '.flv')
return [os.path.join(input_dir, f) for f in os.listdir(input_dir)
if f.lower().endswith(video_extensions)]
def setup_model():
"""初始化特征提取模型(带错误重试)"""
print("正在加载ResNet模型...")
for _ in range(3): # 最多重试3次
try:
model = models.resnet18(pretrained=True)
model = torch.nn.Sequential(*(list(model.children())[:-1]))
model.eval().to(DEVICE)
print(f"模型已加载到设备:{DEVICE}")
return model
except Exception as e:
print(f"模型加载失败: {str(e)},正在重试...")
raise RuntimeError("模型加载失败,请检查网络连接")
# 图像预处理管道
preprocess = transforms.Compose([
transforms.ToPILImage(),
transforms.Resize(256),
transforms.CenterCrop(224),
transforms.ToTensor(),
transforms.Normalize(mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225])
])
class VideoProcessor:
def __init__(self, model):
self.model = model
self.frame_buffer = deque(maxlen=2)
def extract_feature(self, frame):
"""优化后的特征提取(带显存管理)"""
try:
input_tensor = preprocess(frame).unsqueeze(0).to(DEVICE)
with torch.no_grad(), torch.cuda.amp.autocast():
feature = self.model(input_tensor)
return feature.flatten().cpu().numpy()
except Exception as e:
print(f"特征提取失败: {str(e)}")
return None
finally:
if DEVICE == "cuda":
torch.cuda.empty_cache()
def process_video(self, video_path, output_dir):
"""处理单个视频的核心逻辑"""
cap = cv2.VideoCapture(video_path)
if not cap.isOpened():
print(f"错误:无法打开视频文件 {video_path}")
return
fps = cap.get(cv2.CAP_PROP_FPS)
total_frames = int(cap.get(cv2.CAP_PROP_FRAME_COUNT))
print(f"处理视频:{os.path.basename(video_path)} ({total_frames}帧 | FPS: {fps:.2f})")
current_event = []
events = []
for frame_idx in range(total_frames):
ret, frame = cap.read()
if not ret: break
# 每50帧打印进度
if frame_idx % 50 == 0:
print(f"进度:{frame_idx}/{total_frames} ({frame_idx / total_frames:.1%})")
feature = self.extract_feature(frame)
if feature is None: continue
self.frame_buffer.append(feature)
if len(self.frame_buffer) == 2:
sim = 1 - cosine(self.frame_buffer[0], self.frame_buffer[1])
# 事件分割逻辑
if sim < SIMILARITY_THRESHOLD:
if len(current_event) >= MIN_EVENT_LENGTH:
events.append((current_event[0], current_event[-1]))
current_event = [frame_idx]
else:
current_event.append(frame_idx) if current_event else current_event.append(frame_idx - 1)
cap.release()
print(f"检测到 {len(events)} 个事件")
self.save_events(video_path, events, output_dir, fps)
def save_events(self, video_path, events, output_dir, fps):
"""保存所有事件片段(带音频保留)"""
video_name = os.path.splitext(os.path.basename(video_path))[0]
output_folder = os.path.join(output_dir, video_name)
os.makedirs(output_folder, exist_ok=True)
for event_id, (start, end) in enumerate(events):
start_time = start / fps
end_time = (end + 1) / fps
timestamp = datetime.now().strftime("%Y%m%d%H%M%S")
output_path = os.path.join(output_folder, f"{timestamp}_event_{event_id}.mp4")
try:
with VideoFileClip(video_path) as video:
subclip = video.subclip(start_time, end_time)
subclip.write_videofile(
output_path,
codec="libx264",
audio_codec="aac",
preset="fast",
threads=4,
logger=None
)
print(f"保存事件 {event_id}: {start_time:.2f}s-{end_time:.2f}s")
except Exception as e:
print(f"保存失败: {str(e)}")
if __name__ == "__main__":
parser = argparse.ArgumentParser()
parser.add_argument("--input", default="data", help="输入目录路径")
parser.add_argument("--output", default="output", help="输出根目录路径")
args = parser.parse_args()
model = setup_model()
processor = VideoProcessor(model)
video_paths = get_video_paths(args.input)
print(f"发现 {len(video_paths)} 个待处理视频")
for idx, path in enumerate(video_paths, 1):
print(f"\n{'=' * 40}")
print(f"正在处理视频 ({idx}/{len(video_paths)}): {os.path.basename(path)}")
try:
processor.process_video(path, args.output)
except Exception as e:
print(f"处理失败: {str(e)}")
finally:
if DEVICE == "cuda":
torch.cuda.empty_cache()
使用方法:
将视频放入到程序同目录下的date目录下

date目录下:
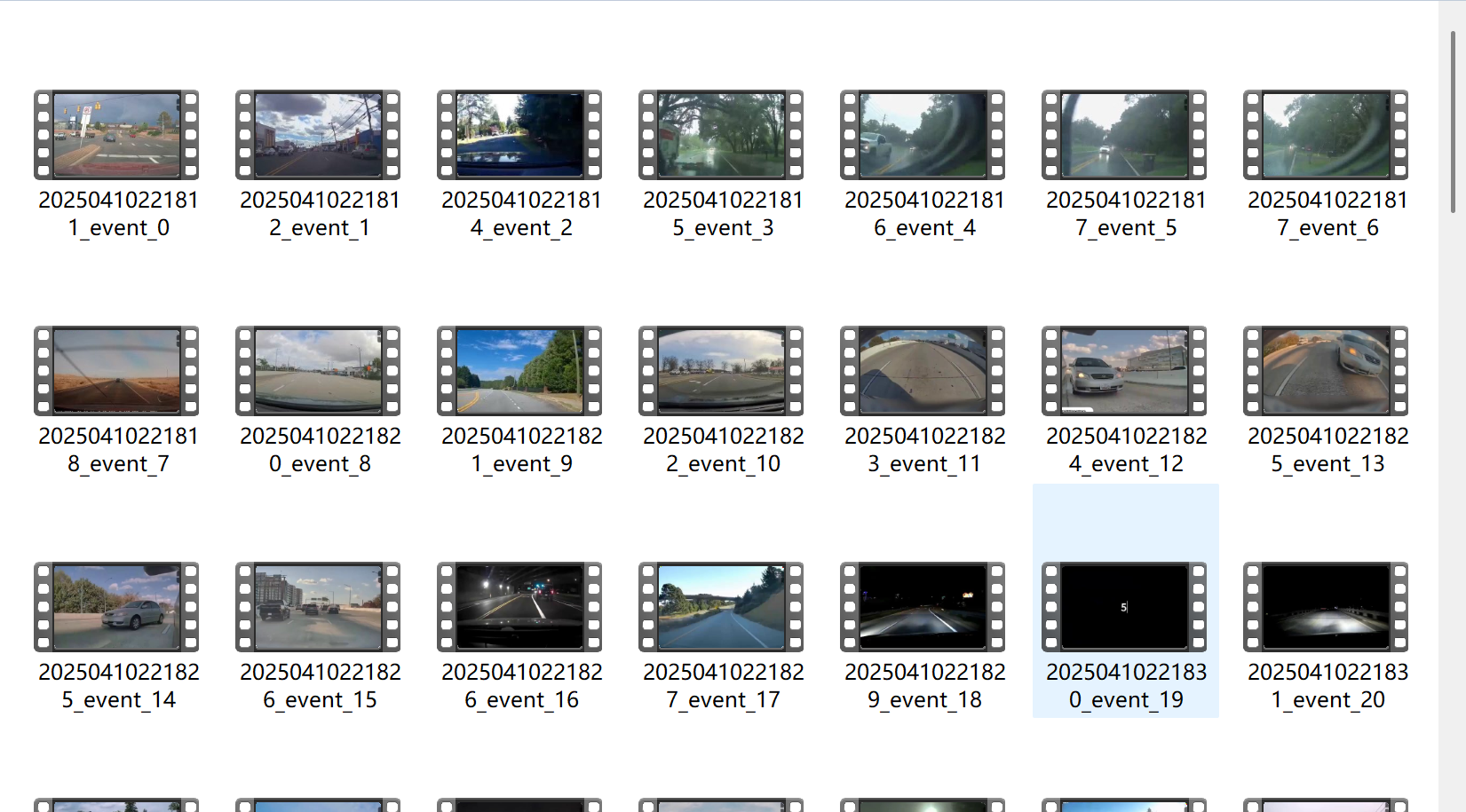
程序处理完之后会在ouput目录下生成分割好的视频。
分割好后的视频如下:

















 247
247

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









