









1、combineByKey使用
<pyspark>
x = sc.parallelize([('B',1),('B',2),('A',3),('A',4),('A',5)])
createCombiner = (lambda el:str(el))
mergeVal = (lambda aggr,el:aggr+";"+el)
mergeComb = (lambda agg1,agg2 : agg1+";"+agg2)
y = x.combineByKey(createCombiner,mergeVal,mergeComb)
print(y.collect())
#结果:[('A', '3;4;5'), ('B', '1;2')]
补一个元胞的例子其中combineByKey(func1,func2,func3)应用如下(下面三段摘自http://blog.csdn.net/sicofield/article/details/50957349):
要理解combineByKey(),要先理解它在处理数据时是如何处理每个元素的。由于combineByKey()会遍历分区中的所有元素,因此每个元素的键要么还没有遇到过,要么就和之前的键相同。combineByKey()的处理流程如下:
如果是一个新的元素,此时使用createCombiner()来创建那个键对应的累加器的初始值。(!注意:这个过程会在每个分区第一次出现各个键时发生,而不是在整个RDD中第一次出现一个键时发生。)
如果这是一个在处理当前分区中之前已经遇到键,此时combineByKey()使用mergeValue()将该键的累加器对应的当前值与这个新值进行合并。
3.由于每个分区都是独立处理的,因此对于同一个键可以有多个累加器。如果有两个或者更多的分区都有对应同一个键的累加器,就需要使用用户提供的mergeCombiners()将各个分区的结果进行合并。
官方文档的API:
combineByKey(createCombiner,mergeValue,mergeCombiners,numPartitions=None, partitionFunc=)
Generic function to combine the elements for each key using a custom set of aggregation functions. Turns an RDD[(K, V)] into a result of type RDD[(K, C)], for a “combined type” C. Users provide three functions:
createCombiner, which turns a V into a C (e.g., creates a one-element list)
mergeValue, to merge a V into a C (e.g., adds it to the end of a list)
mergeCombiners, to combine two C’s into a single one. In addition, users can control the partitioning of the output RDD.
Note V and C can be different – for example, one might group an RDD of type (Int, Int) into an RDD of type (Int, List[Int]).
x = sc.parallelize([(“a”, 1), (“b”, 1), (“a”, 1)])
def add(a, b): return a + str(b)
sorted(x.combineByKey(str, add, add).collect())
结果:[(‘a’, ‘11’), (‘b’, ‘1’)]
怀疑combineByKey有问题
createCombiner = (lambda t:[t])
mergeVal = (lambda aggr,t:aggr.append(t))
mergeComb = (lambda agg1,agg2 : agg1+agg2)
x=sc.parallelize([('a',1),('a',1),('a',1),('a',1)])
y = x.combineByKey(createCombiner,mergeVal,mergeComb)
print y.collect()
结果:[('a', [1, 1, 1, 1])]
x=sc.parallelize([('a',1),('a',1),('a',1),('a',1),('a',1),('a',1),('a',1),('a',1),('a',1),('a',1),('a',1),('a',1),('a',1),('a',1),('a',1),('a',1)])
y = x.combineByKey(createCombiner,mergeVal,mergeComb)
print y.collect()
结果:
File "/Users/bingdada/spark/python/lib/pyspark.zip/pyspark/shuffle.py", line 302, in mergeCombiners
d[k] = comb(d[k], v) if k in d else v
File "<stdin>", line 1, in <lambda>
TypeError: can only concatenate list (not "NoneType") to list
解决:我不用list了 combine的时候拼成字符串,获取的时候再解析成list,可以。。。。。。。原因?2、groupByKey后数据格式
groupByKey()后,value会生成一个python的可迭代对象,通过list()将其变为列表,列表中每个元素为与key对应的value。所以可能groupByKey()后常会跟着mapValues().
groupByKey().mapValues(lambda recommendItemList:getContextList(list(recommendItemList)))3、join后数据格式
跟函数:
mergeRdd = orderPoiRdd.fullOuterJoin(clickPoiRdd).map(lambda uidAndordAndCli:formatRdd(uidAndordAndCli))
#其中uidAndOrdAndCli是join后的tuple(key,(orderPoiRddJoinVal,clickPoijoinVal)),所以join后参数个数可以整体看做为1直接跟map:
#join后不跟函数直接跟map的时候也可以直接把元胞中的每一项写清
join(groupIdRdd).map(lambda (globalid,((T1_TIMESTAMP,T2_TIMESTAMP),d_num)在join时经常会报以下错误:
(1)ValueError: too many values to unpack 好像是返回参数多与自己lamda中写死的参数个数;
(2)need more than two values to unpack 好像是返回参数少与自己lamda中写死的参数个数;
这两个哪个对应哪个有点混了,待我有机会再改。
4、mapValues拼接返回格式
5、测试
本地小数据运行测试:
如果数据来自textfile,直接拉几行数据本地测试;
如果数据来自hql,先查好部分数据,下载;把sql过程换成textFile读+分割过程:
#原代码#:
orderPoiRdd = getOrderPoiRdd(sqlCtx)
clickPoiRdd = getClickPoiRdd(sqlCtx)
mergeRdd = mergeClickAndOrder(orderPoiRdd,clickPoiRdd)
#测试用代码#:
orderPoiRdd = sc.textFile("test_Ord").map(lambda line:line.split('\t'))
clickPoiRdd = sc.textFile("test_Cli").map(lambda line:line.split('\t'))
# print orderPoiRdd.collect()
# print clickPoiRdd.collect()
orderPoiRdd = getOrderPoiRdd(orderPoiRdd)
clickPoiRdd = getClickPoiRdd(clickPoiRdd)
# print orderPoiRdd.collect()
# print clickPoiRdd.collect()
mergeRdd = mergeClickAndOrder(orderPoiRdd,clickPoiRdd)
print mergeRdd.collect()copy一份原代码修改用于测试,测试过程中发现的问题同步到原代码中。
用coalesce(1)算子,这样只有一个线程,看log不会乱
6、避免线上脏数据影响的处理
(1) 分割后数据域个数不对的过滤掉。
(2) textFile后要过滤为None或“”行
(3) 数据倾斜:先用reduceByKey查出/保存条数很多的key,用map广播出去这些key,如果这些key不重要,处理的时候滤掉就可以了;
否则可以考虑把这种key划分成小key.
(4) python使用list时,需要设置index越界的处理方式,因为在数据量大情况下是有可能出这个问题的,要让代码尽可能健壮
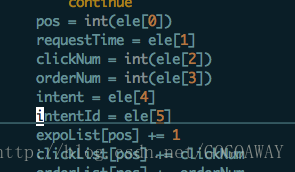
这个问题拿小数据可能看不出来,而且在用小数据收集结果不是collect()而是take(2)的形式也看不出来,所以小数据就直接collect吧。然后这种错误报错位置不一定准,比如下面这个报错在reduceByKey,但是看了很久reduceByKey没有错误,后来发现是上面一行报错。所以在觉得报错语句较肯定没有问题的时候可以考虑数据不合法的问题:

(5)时间 要注意有9999:99:99 这样的脏数据
7、特别容易弄错参数个数的情况
mergedItemRdd = itemUserRdd.filter(lambda line:line is not None and len(line)>0
).map(lambda line:line.strip().split("*")
).combineByKey(createCombiner,mergeVal,mergeComb
).mapValues(lambda timeList:sortTimeList(timeList)
).map(lambda item_userkey,timeStr:strEncode(item_userkey)+"\t"+strEncode(timeStr))
combineByKey之前是一个元胞,处理完后也是一个元胞,所以只有一个参数(如果之前是list也要注意),像上面只写元胞的两个元素就错了!!!
8、spark栈溢出讲的挺好的博客:
http://www.voidcn.com/blog/zy_zhengyang/article/p-6181356.html
9、没有解决的问题:
调用类的静态方法,报错:RuntimeError: uninitialized staticmethod object















 244
244

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









