









应该是有一小部分数据 需要特殊处理
尝试90天,反复重试3个task:
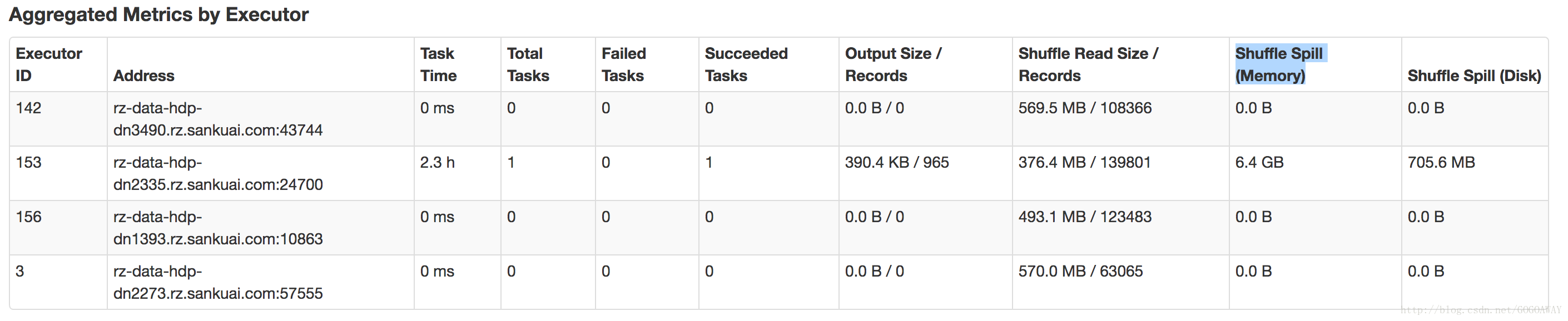
其实处理很快,就是shuffle read时间很久

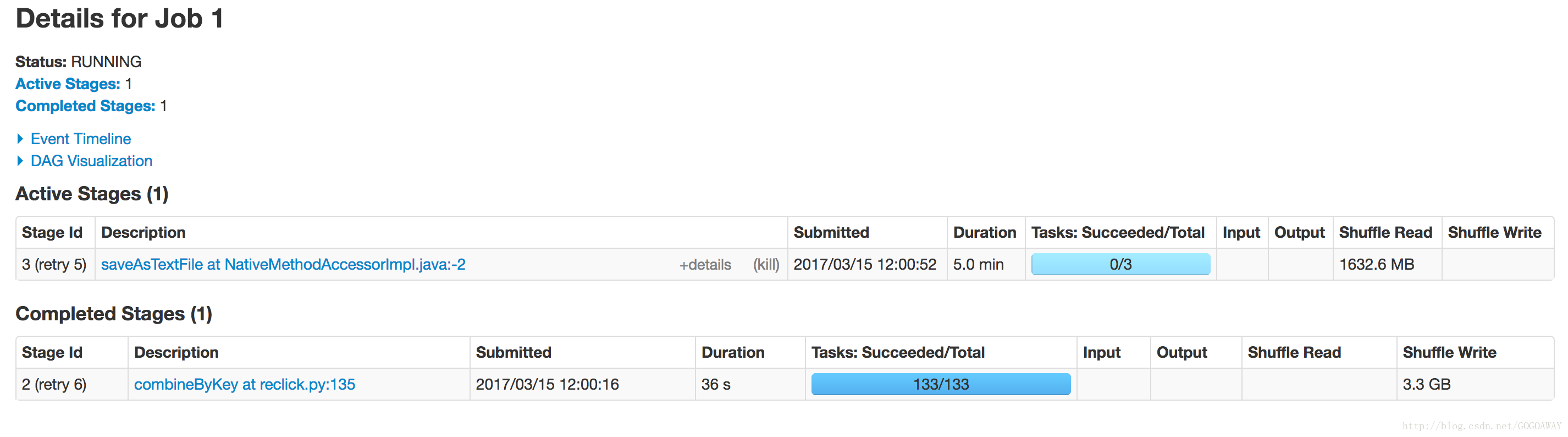
第一次150天数据量尝试后期效果:

怎么知道为什么会超出内存太多?
combine Persist 4096 后的结果:
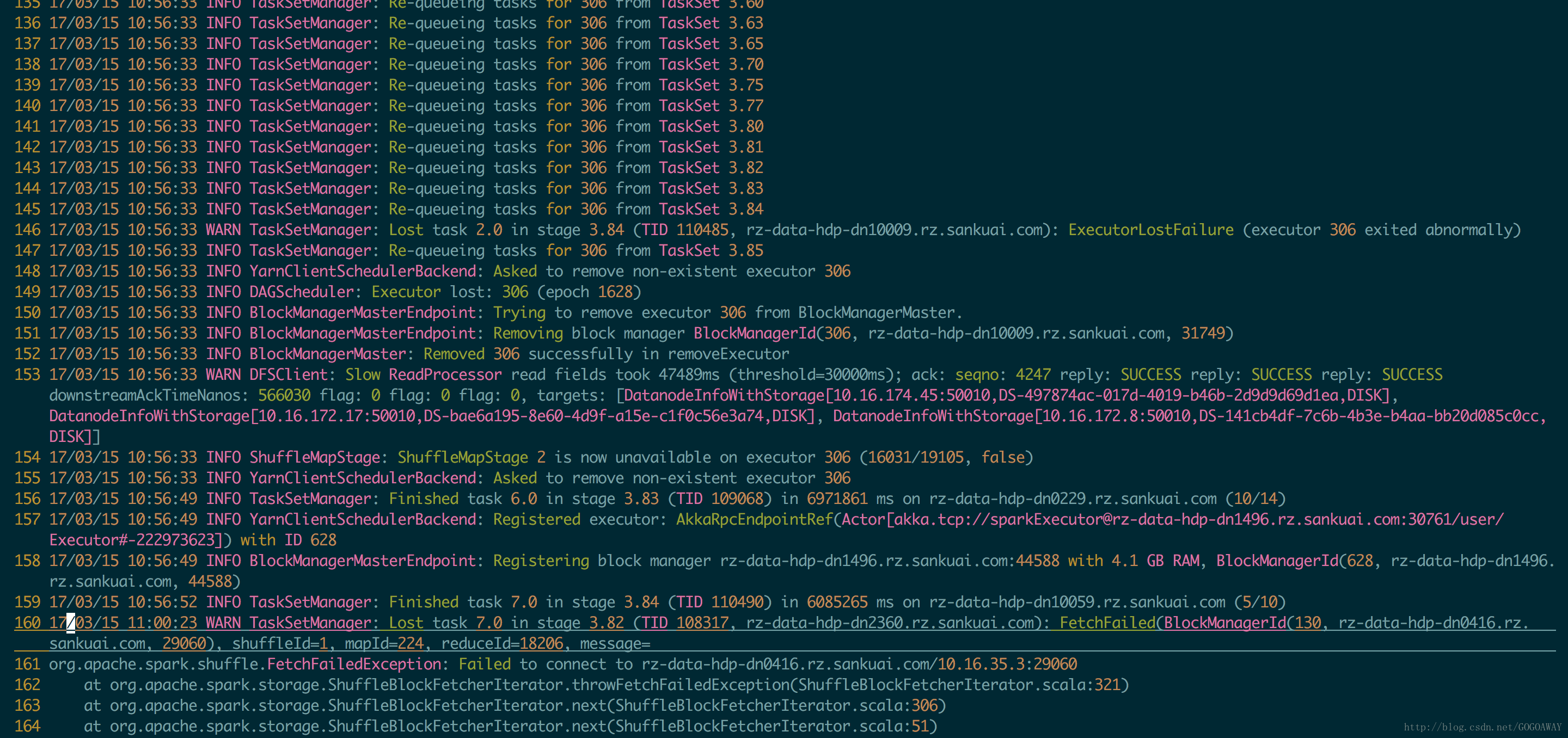
另外task数本来只有4096个 但是后来变成两万多个?
变成两万多个后也是大量不成功,一直在重复尝试,看样子依然是shuffle内存不够。
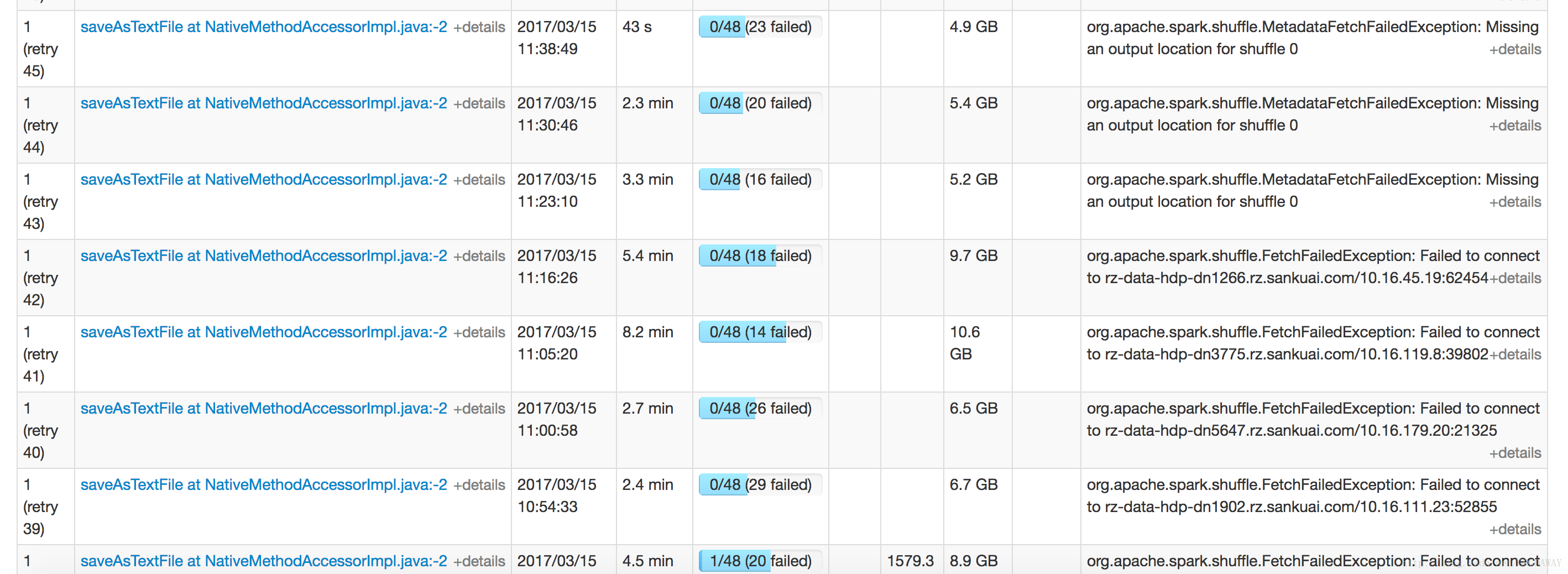
stage失败和task失败的区别是?

1.1.2 spark.shuffle.spill
这个参数的默认值是true,用于指定Shuffle过程中如果内存中的数据超过阈值(参考spark.shuffle.memoryFraction的设置),那么是否需要将部分数据临时写入外部存储。如果设置为false,那么这个过程就会一直使用内存,会有Out Of Memory的风险。因此只有在确定内存足够使用时,才可以将这个选项设置为false。
对于Hash BasedShuffle的Shuffle Write过程中使用的org.apache.spark.util.collection.AppendOnlyMap就是全内存的方式,而org.apache.spark.util.collection.ExternalAppendOnlyMap对org.apache.spark.util.collection.AppendOnlyMap有了进一步的封装,在内存使用超过阈值时会将它spill到外部存储,在最后的时候会对这些临时文件进行Merge。
而Sort BasedShuffle Write使用到的org.apache.spark.util.collection.ExternalSorter也会有类似的spill。
而对于ShuffleRead,如果需要做aggregate,也可能在aggregate的过程中将数据spill的外部存储。
1.1.3 spark.shuffle.memoryFraction和spark.shuffle.safetyFraction
在启用spark.shuffle.spill的情况下,spark.shuffle.memoryFraction决定了当Shuffle过程中使用的内存达到总内存多少比例的时候开始Spill。在Spark 1.2.0里,这个值是0.2。通过这个参数可以设置Shuffle过程占用内存的大小,它直接影响了Spill的频率和GC。
如果Spill的频率太高,那么可以适当的增加spark.shuffle.memoryFraction来增加Shuffle过程的可用内存数,进而减少Spill的频率。当然为了避免OOM(内存溢出),可能就需要减少RDD cache所用的内存,即需要减少spark.storage.memoryFraction的值;但是减少RDD cache所用的内存有可能会带来其他的影响,因此需要综合考量。
在Shuffle过程中,Shuffle占用的内存数是估计出来的,并不是每次新增的数据项都会计算一次占用的内存大小,这样做是为了降低时间开销。但是估计也会有误差,因此存在实际使用的内存数比估算值要大的情况,因此参数 spark.shuffle.safetyFraction作为一个保险系数降低实际Shuffle过程所需要的内存值,降低实际内存超出用户配置值的风险。















 343
343

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









