






1.大体框架列出+爬取网页:
| 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 |
|
parse_data函数主要用于爬取以及解析数据
headers可以在网页之中查找
易错点:当使用requests.get获取到网页之后,一般可能使用text方法进行数据获取,但是尝试之后数据产生了乱码,因为requests.get方法获取再用text解码时候默认ISO-8859-1解码,
因此使用content方法并指定decode('utf-8')进行解码
数据解析我使用的是bs4库,也可以用lxml库,但是感觉没有bs4方便,解析方式使用html5lib,对于html数据解析更具有容错性和开放性
2.爬取网页解析:
| 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 |
|
bs4库一般使用方法是find或者find_all方法(详细内容见上一篇博客)
find方法比较使用的是可以查找指定内容的数据,使用attrs={}来定制条件,代码中我用了attrs={'class':'conMidtab'}或者使用class_='conMidtab'
查看网页源代码可知

通过'class':'conMidtab'来定位到所需信息的表

再分析:因为有多个conMidtab,所以测试分析得知多个conMidtab对应的是今天,明天,后天......的天气情况
我们分析的是今天的情况,所以取第一个conMidtab,使用soup.find("div",class_="conMidtab")获取第一个conMidtab的内容
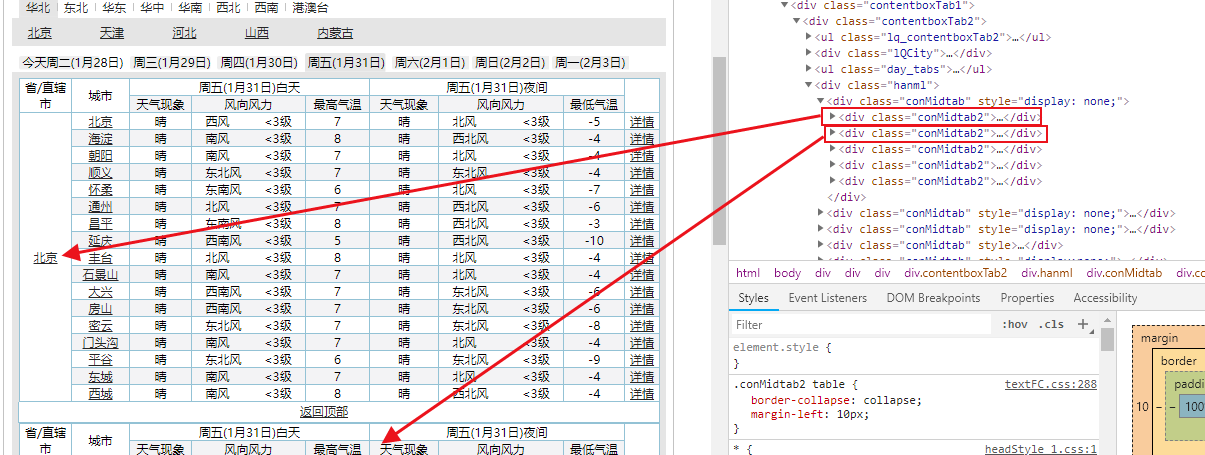
由上知:conMidtab下的多个class="conMidtab2"代表不同的省的天气信息
但是在研究可以发现,所有天气信息都是存储在table里的,因此获取所有tables即可——cons.find_all('table')
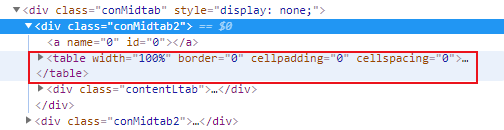
同时对于每一个table而言:第三个tr开始才是对应的城市信息,故对于每一个table获取trs = table.find_all("tr")[2:]

易错点:同时发现对于每个省第一个城市,它隐藏在tr的第二个td里,而除此之外的该省其他城市则在tr的第一个td里,因此使用一个if和else判断
enumerate方法可以产生一个index下标,因此在遍历trs的时候可以知道当index==0的时候是第一行


之后分析:城市名字:对于每个省第一个城市,它隐藏在tr的第二个td里,而除此之外的该省其他城市则在tr的第一个td里
最高气温:对于每个省第一个城市,它隐藏在tr的第五个td里,而除此之外的该省其他城市则在tr的第四个td里
因此使用
| 1 2 3 4 5 6 |
|
| 1 2 3 4 5 6 7 8 9 10 11 12 13 |
|
修改了一下main方法:获取全国数据
4.数据排序找出全国气温最高十大城市:
| 1 2 3 4 5 |
|
其中在排序的时候注意:要转化为int型才可以进行排序,否则是按照string进行排序的。
5.数据可视化:
| 1 2 3 4 5 |
|
使用Bar模块:
Bar方法主要可以给该图标命名
add方法主要是添加(图颜色的名称,横坐标名, 纵坐标名)
render主要是存储在本地之中
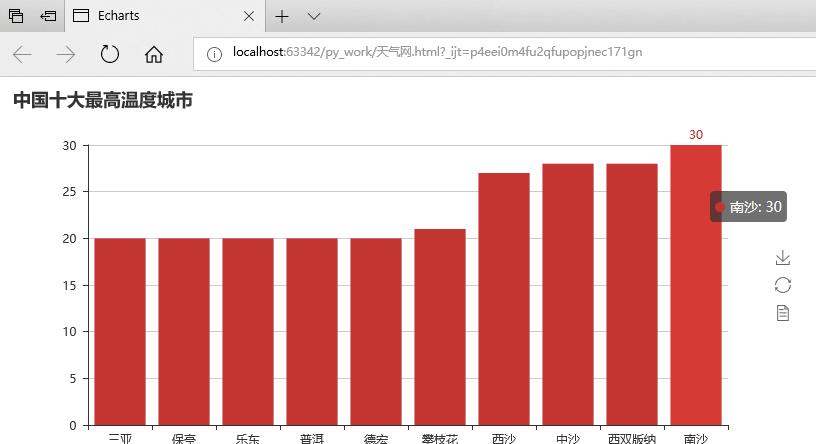
结果展示:
完整代码:
| 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 |
|















 5868
5868

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









