






目录
1.读取CSV文件
CSV(Comma-Separated Values,逗号分隔值)文件存储的数据以逗号进行分割。
import pandas as pd
df = pd.read_csv('nba.csv') #存放的文件地址
print(df)(1)读取数据的前3行
import pandas as pd
df = pd.read_csv('nba.csv')
print(df.head(3))
(2)读取数据的后3行
import pandas as pd
df = pd.read_csv('nba.csv')
print(df.tail(3))(3)将数据存储为CSV文件
import pandas as pd
nme = ["Google", "Runoob", "Taobao", "Wiki"]
st = ["glad", "book, "grocery", "search"]
ag = [90, 40, 80, 98]
# 字典
dict = {'name': nme, 'site': st, 'age': ag}
df = pd.DataFrame(dict)
# 保存 dataframe
df.to_csv('site.csv') 2.数据清洗常用函数
(1)Pandas清洗空值
1.使用通过 isnull() 判断各个单元格是否为空。
import pandas as pd
#文件地址前面放r的原因是阻止转义
df = pd.read_csv(r'C:\Users\22403\Desktop\property-data.csv')
print (df['ID'])
print (df['ID'].isnull())输出结果如下:
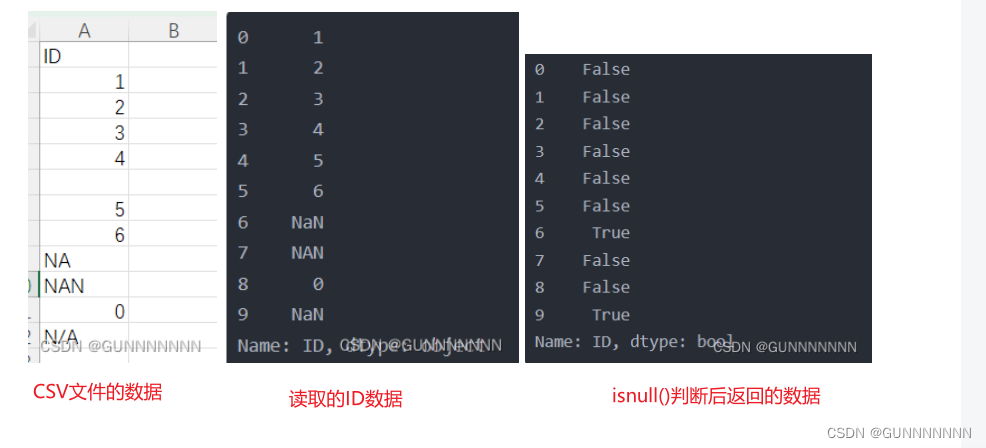
可以看出pd.read_csv读取的文件会把什么都没有的单元格忽略,而写有NA或者N/A的数据读取为空值(NaN也可以,而NAN会被认为是有数据的),通过isnull()判断后会将空值显示为True
如果想使某几个数据也被认定为空值,可以参考如下方法:
import pandas as pd
missing_values = ["1","2"]
df = pd.read_csv(r'C:\Users\22403\Desktop\property-data.csv', na_values = missing_values)
print (df['ID'])
print (df['ID'].isnull())输出结果如下:1和2也为空值了
0 NaN
1 NaN
2 3
3 4
4 5
5 6
6 NaN
7 NAN
8 0
9 NaN
10 NaN
Name: ID, dtype: object
0 True
1 True
2 False
3 False
4 False
5 False
6 True
7 False
8 False
9 True
10 True
Name: ID, dtype: bool2.删除为空值的一行数据:dropna()
删除包含空数据的行,dropna()会找每一列,只要有空值,就会把这一行都删掉
import pandas as pd
df = pd.read_csv(r'C:\Users\22403\Desktop\property-data.csv')
new_df = df.dropna()
print(new_df)输出结果如下:
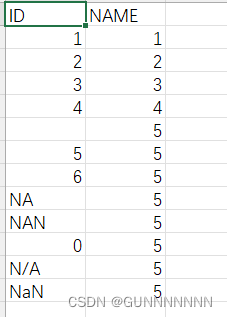
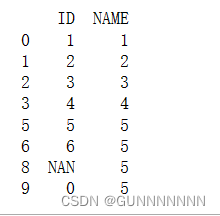
可以看到含有NA,N/A,NaN的一行全部都没有了
也可以移除指定列有空值的行:(这样就只会在这一行中找空值,找到就删掉这一行,其他行不会找了)
import pandas as pd
df = pd.read_csv(r'C:\Users\22403\Desktop\property-data.csv')
new_df = df.dropna(subset=['ID'])
print(new_df)3.替换空字段
import pandas as pd
df = pd.read_csv(r'C:\Users\22403\Desktop\property-data.csv')
df.fillna(12345)
print(df) #没有替换
df.fillna(12345,inplace = True) #替换源数据,把表格中所有空值都替换为12345
print(df)输出结果如下图:
ID NAME
0 1 1
1 2 2
2 3 3
3 4 4
4 NaN 5
5 5 5
6 6 5
7 NaN 5
8 NAN 5
9 0 5
10 NaN 5
11 NaN 5
ID NAME
0 1 1
1 2 2
2 3 3
3 4 4
4 12345 5
5 5 5
6 6 5
7 12345 5
8 NAN 5
9 0 5
10 12345 5
11 12345 5(2)计算均值,中位数,众数
Pandas使用 mean()、median() 和 mode() 方法计算列的均值(所有值加起来的平均值)、中位数值(排序后排在中间的数)和众数(出现频率最高的数)。














 871
871











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









