






 本文介绍如何使用Kettle工具进行数据去重、缺失值处理、异常值处理及数据检验的方法,包括完全去重、不完全去重、缺失值填充、异常值修补等流程。
本文介绍如何使用Kettle工具进行数据去重、缺失值处理、异常值处理及数据检验的方法,包括完全去重、不完全去重、缺失值填充、异常值修补等流程。
5.1 数据去重
(1)完全去重
1.数据准备
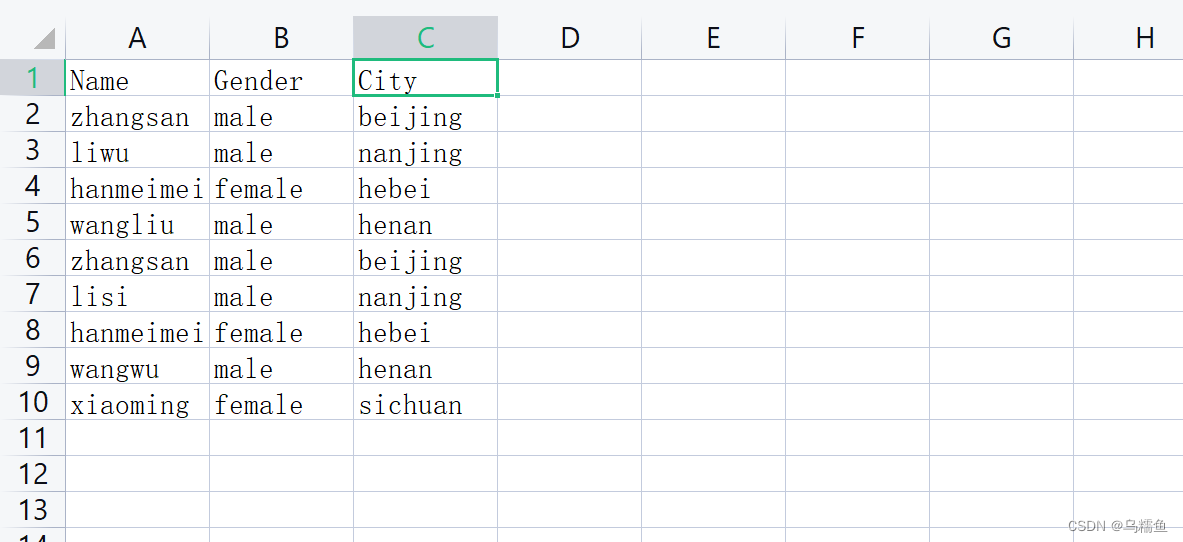
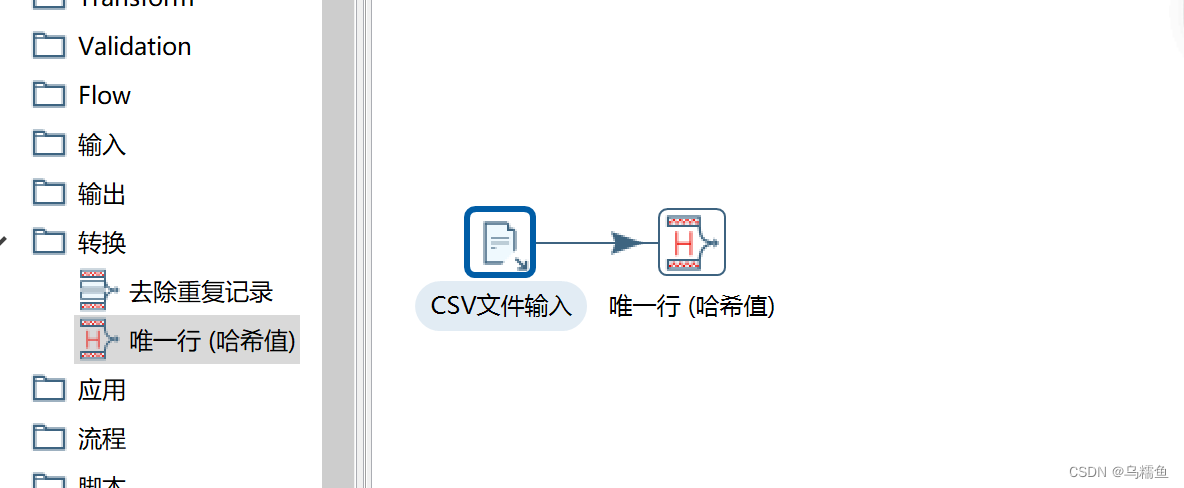
2.通过使用Kettle工具,创建一个转换repeat_transform,并添加“CSV文件输入”控件、“唯一行(哈希值)”控件以及Hop跳连接线,具体如图所示。
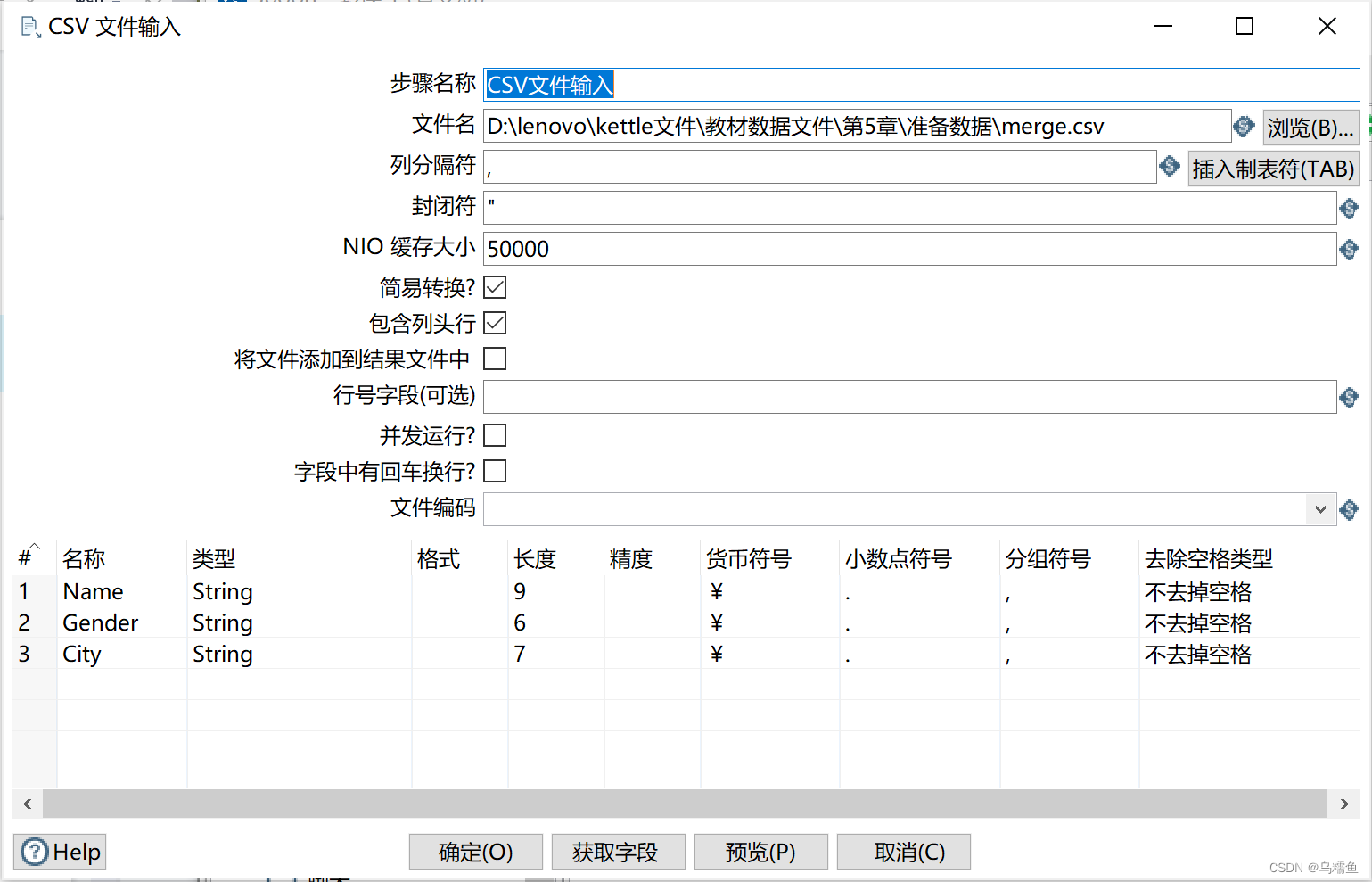
3. 双击“CSV文件输入”控件,进入“CSV文件输入”配置界面,具体如图所示。
单击【浏览】按钮,选择要进行完全去重处理的CSV文件merge.csv;再单击【获取字段】按钮,Kettle会自动检索CSV文件,并对文件中的字段类型、格式、长度、精度等属性进行分析。
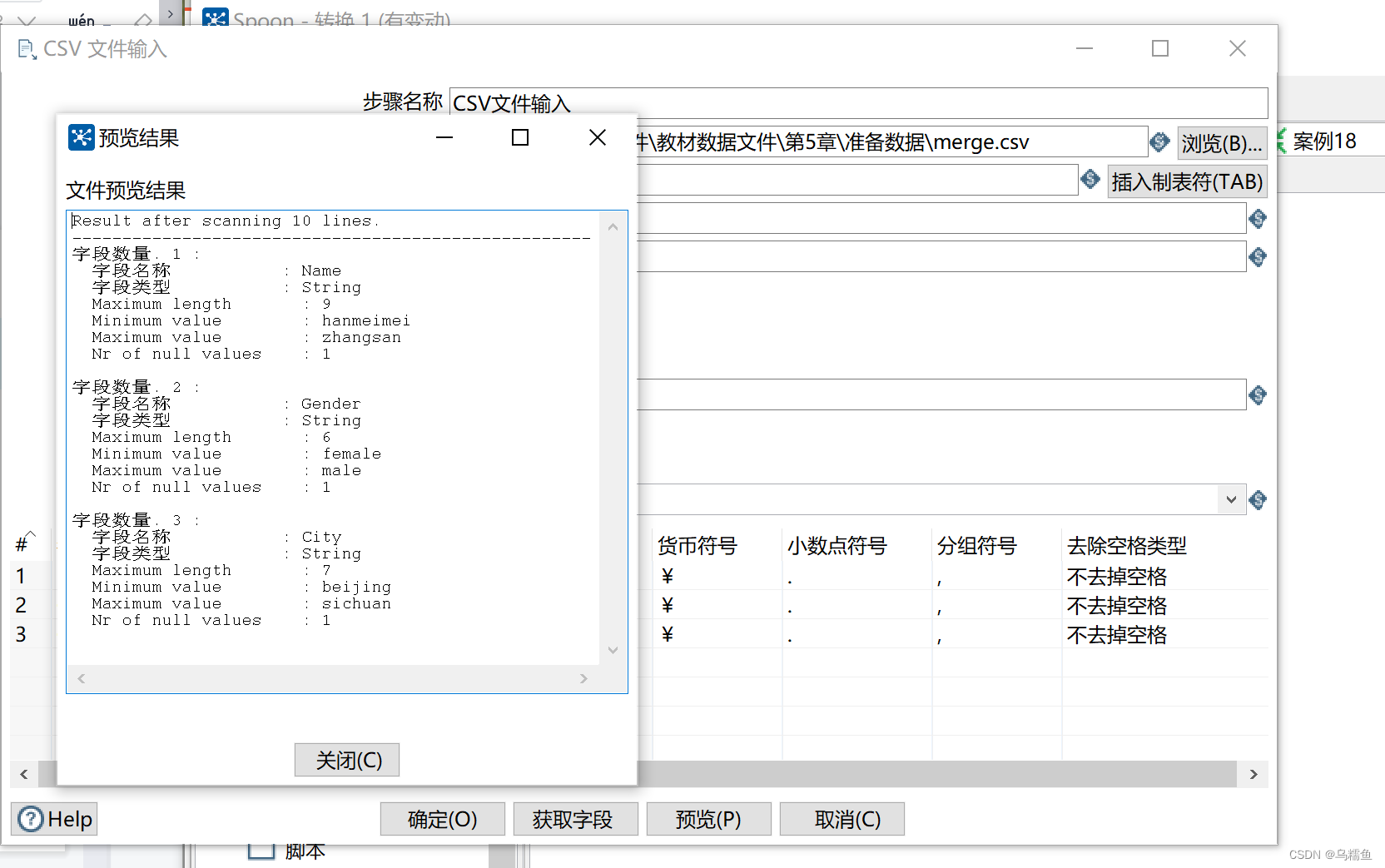
 单击【预览】按钮,查看CSV文件merge.csv的数据是否加载到CSV文件输入流中。
单击【预览】按钮,查看CSV文件merge.csv的数据是否加载到CSV文件输入流中。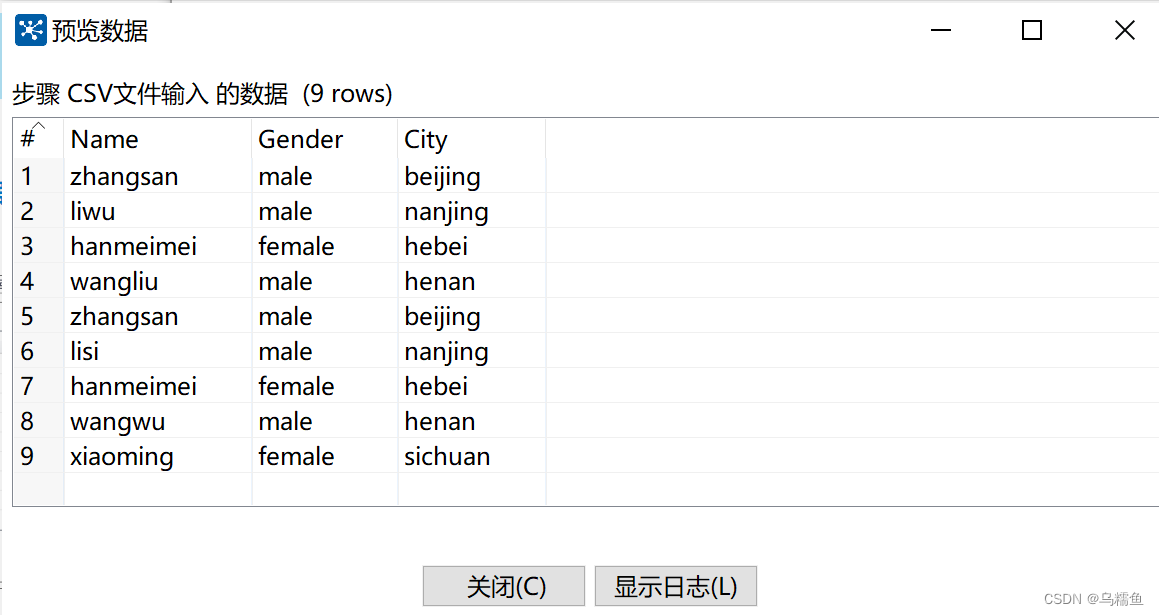 4.配置”唯一行(哈希值)”控件
4.配置”唯一行(哈希值)”控件
双击“唯一行(哈希值)”控件,进入“唯一行(哈希值)”配置界面。
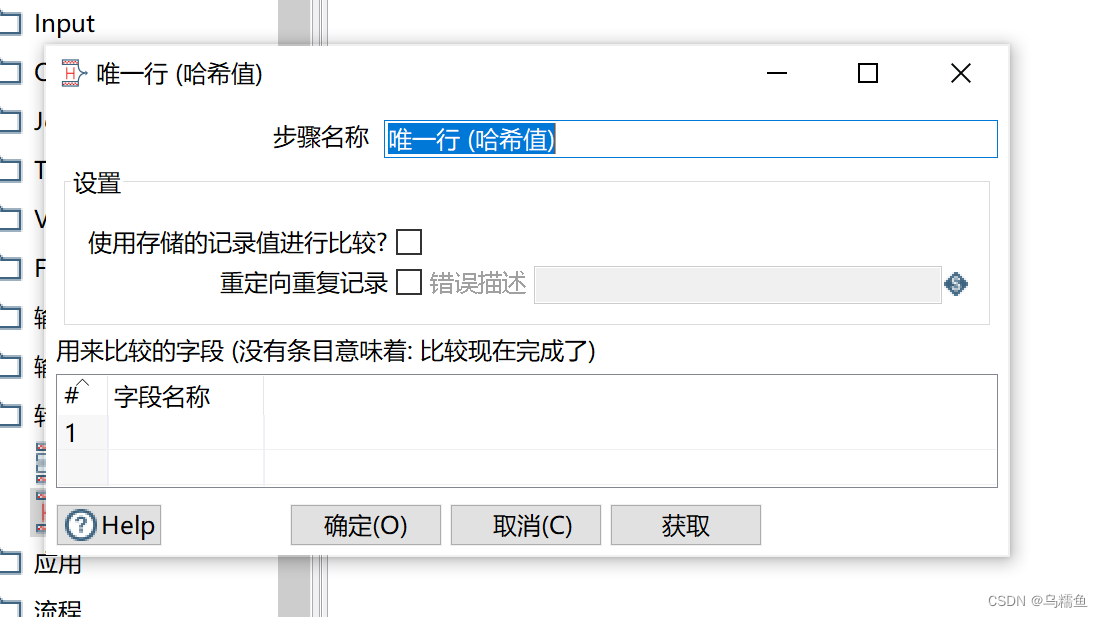
在“用来比较的字段”处,添加要去重的字段,这里可以单击【获取】按钮,获取要去重的字段。
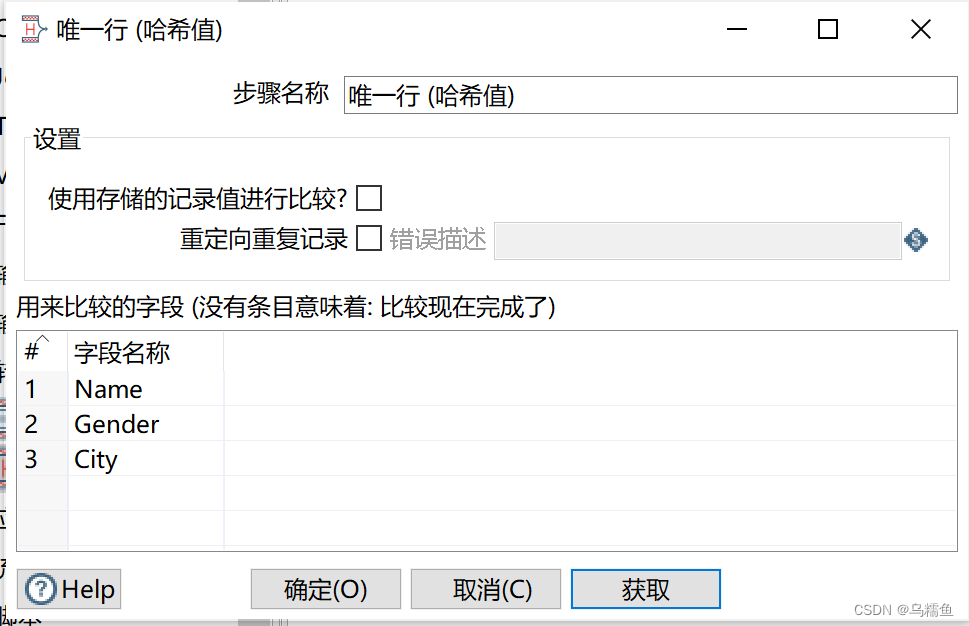
5. 运行转换repeat_transform,单击转换工作区顶部的左上角运行按钮,运行创建的repeat_transform转换。
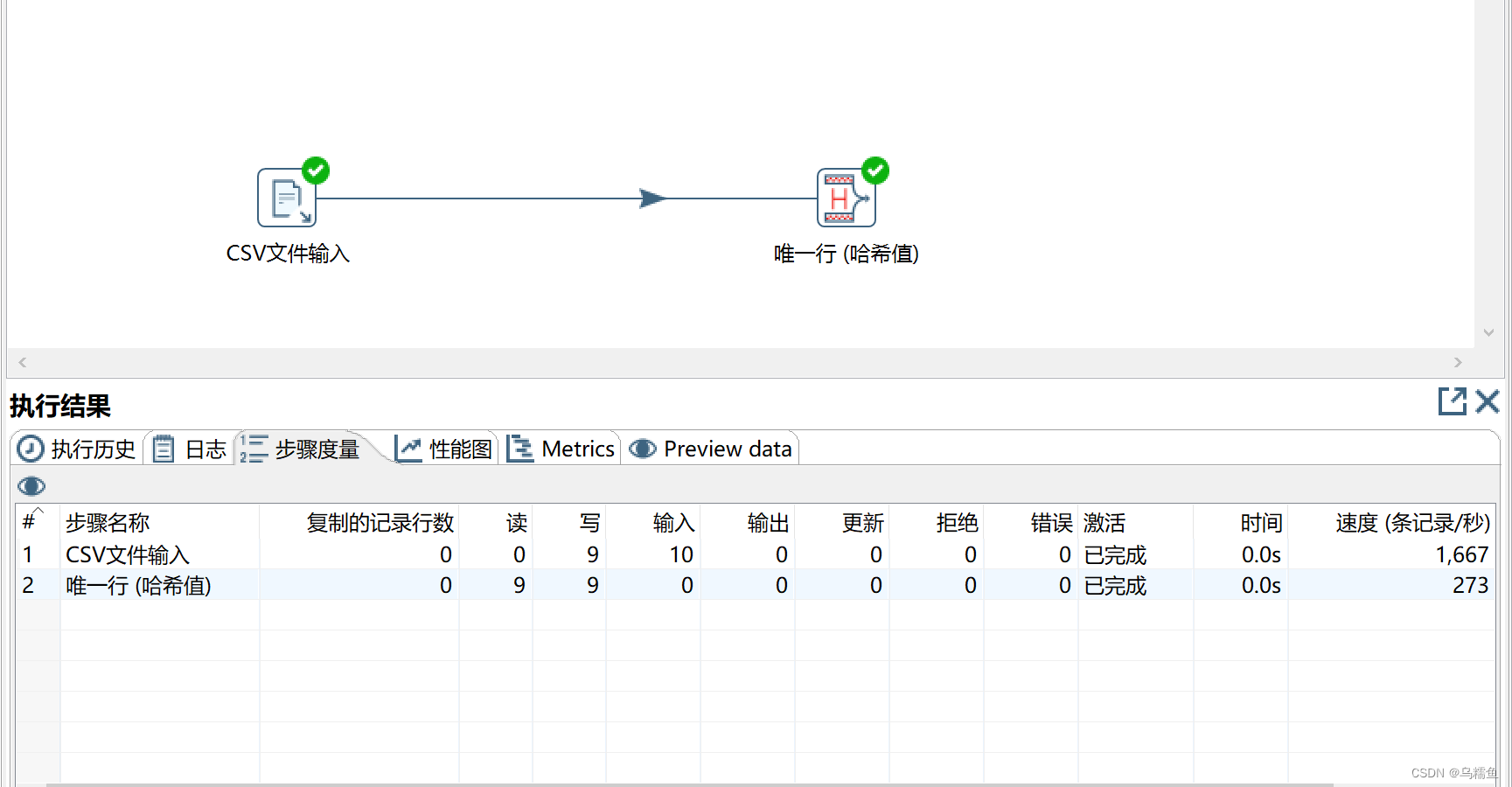
6.查看merge.csv是否消除完全重复的数据,选中“唯一行(哈希值)”控件,单击执行结果窗口的“Preview data”选项卡,查看是否消除CSV文件merge.csv中完全重复的数据。
(2)不完全去重
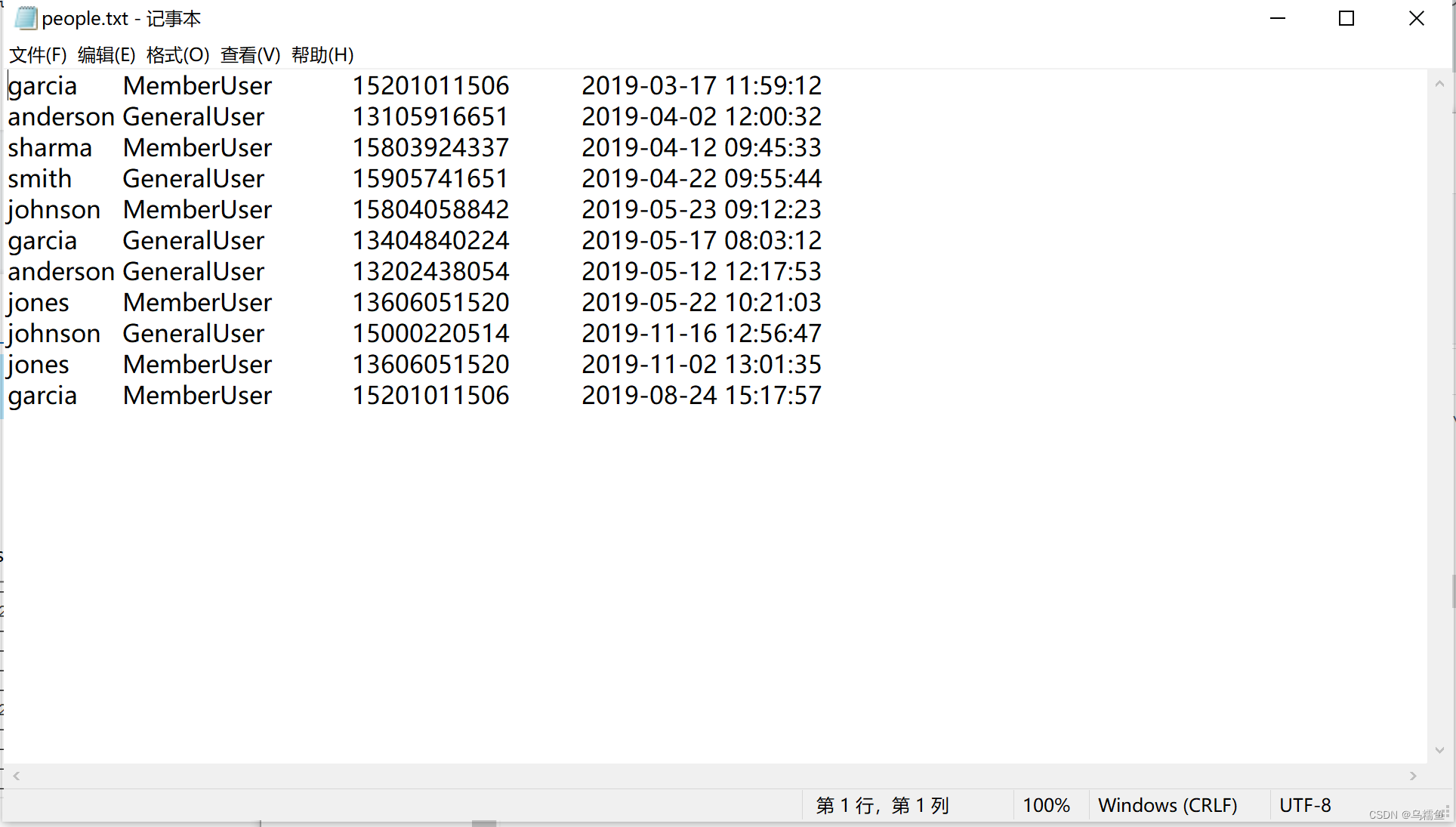
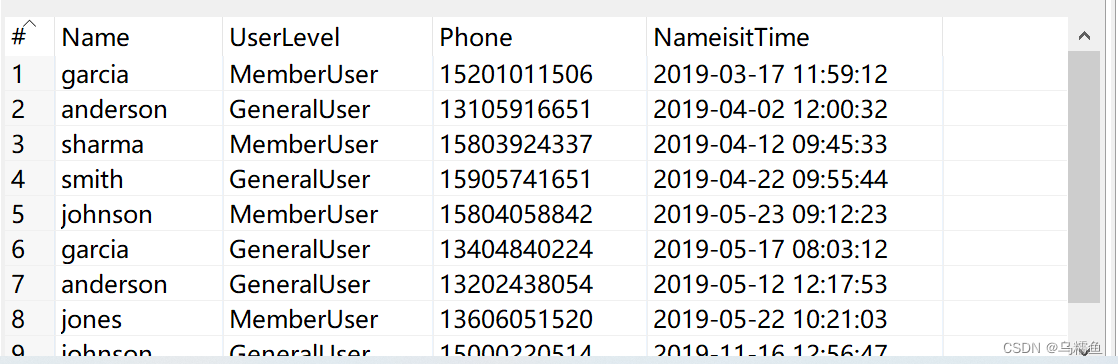
1.数据准备。现在有一份用户访问网站的数据文件people.txt,内容如图所示。
2. 打开Kettle工具,创建转换。
通过使用Kettle工具,创建一个转换repeat_transform,并添加“文本文件文件输入”控件、“唯一行(哈希值)”控件以及Hop跳连接线,具体如图所示。
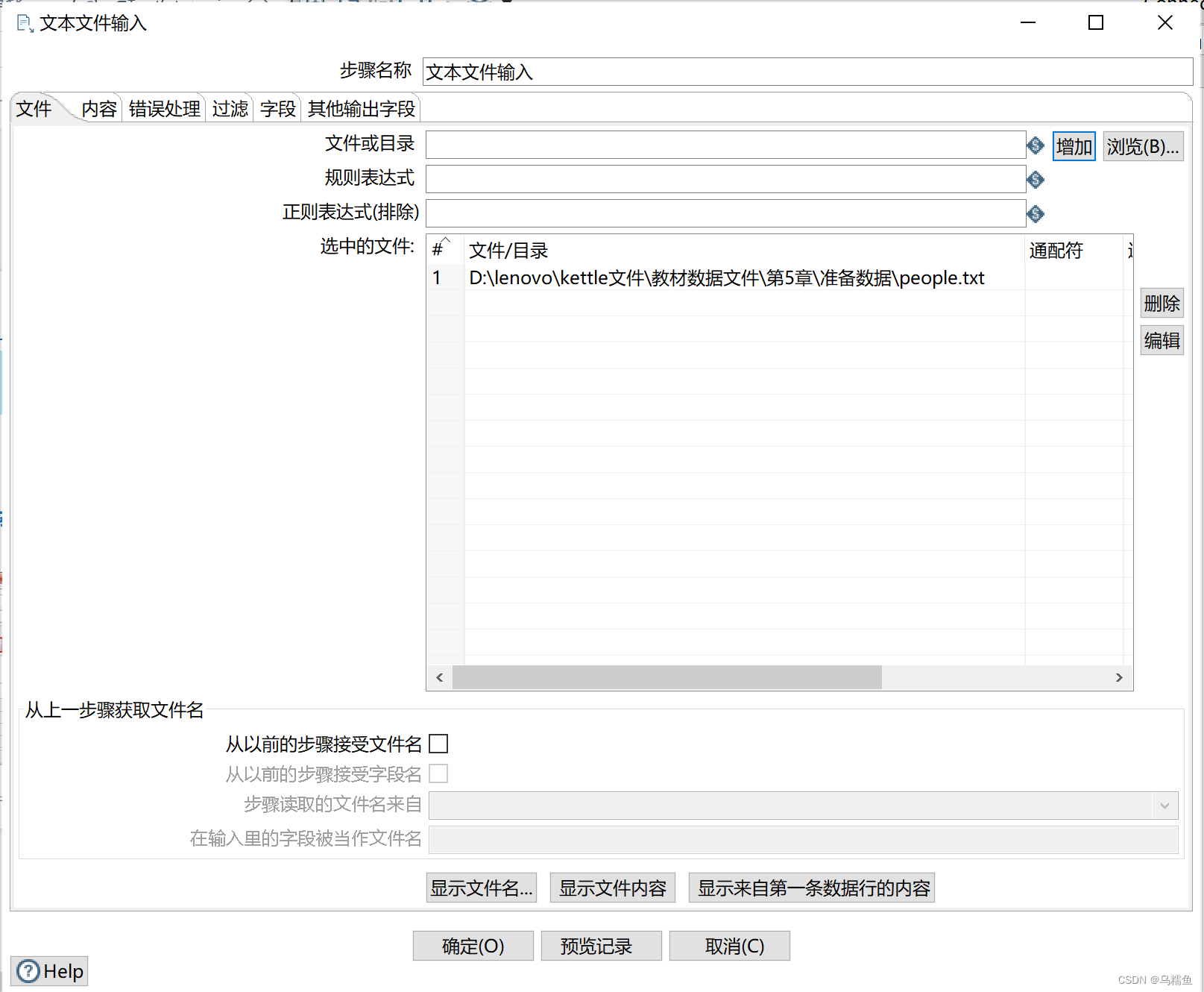
3.双击“文本文件输入”控件,进入“文本文件输入”配置界面。 单击【浏览】按钮,选择要去重的文件people.txt;单击【增加】按钮,将要去重的文件people.txt添加到转换part_repeat_transform中。
单击“内容”选项卡;清除分隔符处的默认分隔符“;”,并单击【Insert TAB】按钮,在分隔符处插入一个制表符;取消勾选“头部”复选框。
单击“字段”选项卡;根据文件people.txt的内容添加对应的字段名称,并指定数据类型。 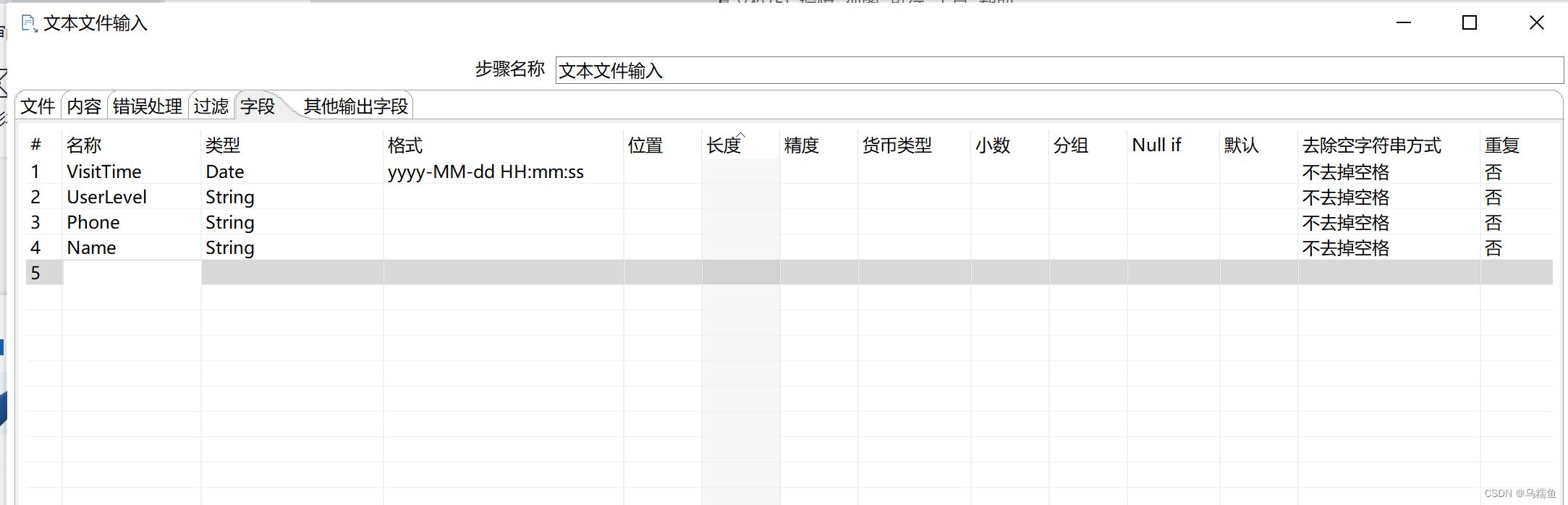
4.配置唯一行(哈希值)控件 。双击“唯一行(哈希值)”控件,进入“唯一行(哈希值)”配置界面。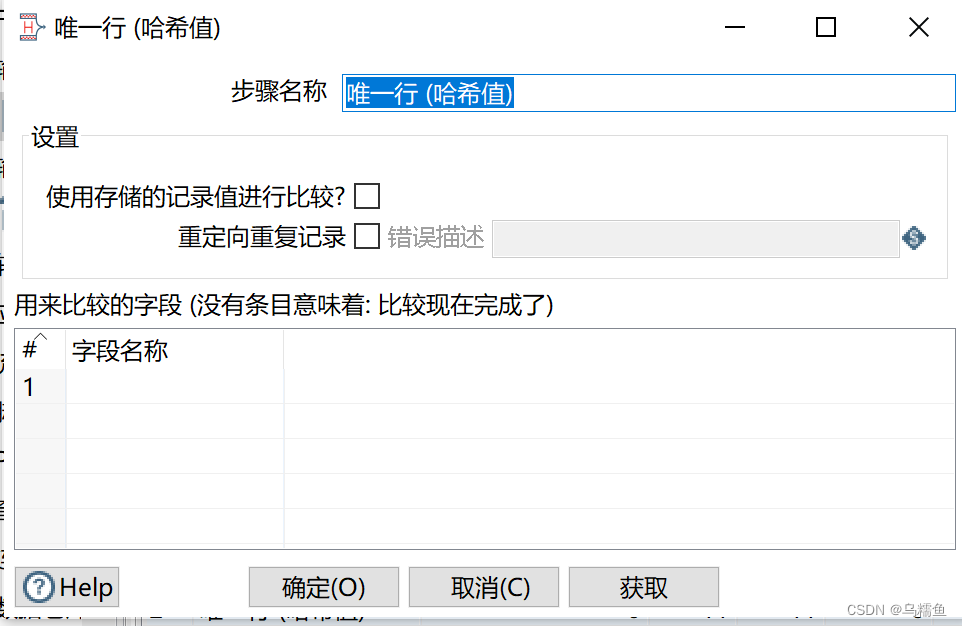
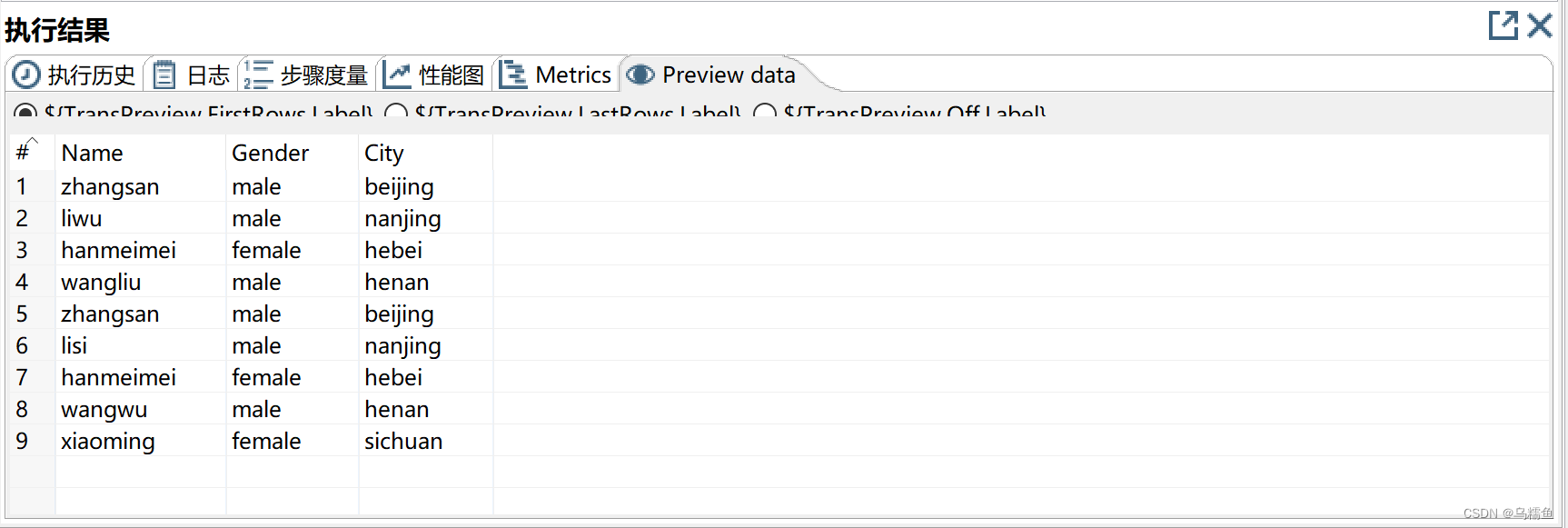
在“用来比较的字段”处,添加要比较去重的字段,即Name、UserLevel、Phone字段。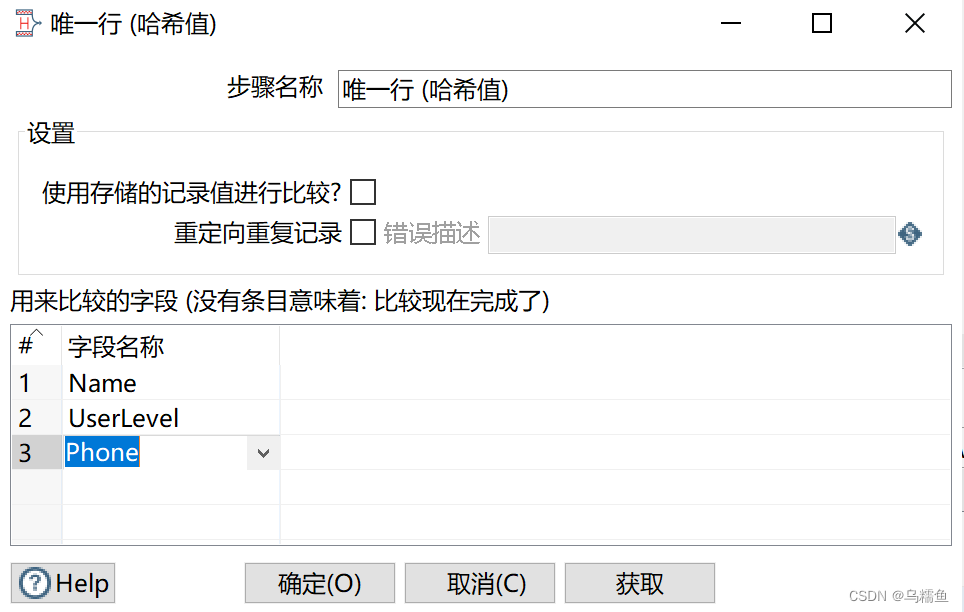
5.单击转换工作区顶部的运行按钮,运行创建的part_repeat_transform转换。
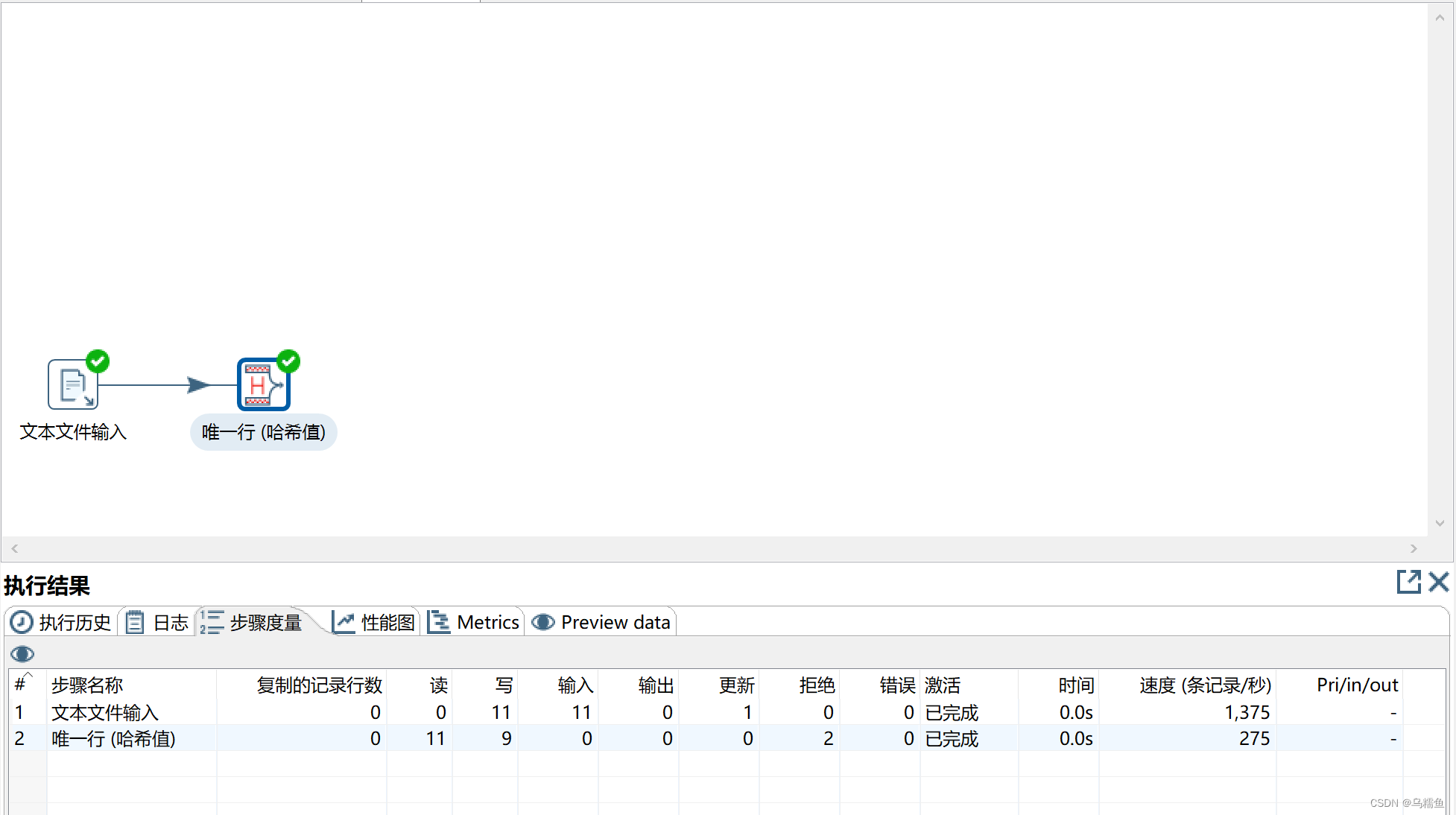
6.选中“唯一行(哈希值)”控件,单击执行结果窗口的“Preview data”选项卡,查看是否消除文件people.txt中不完全重复的数据。
 5.2 缺失值处理
5.2 缺失值处理
(1)去除缺失值 。
1.数据准备。现在有一份就业人员的收入数据文件revenue.txt,由于某种原因,在数据采集的过程中产生了大量的缺失值数据,内容如图所示。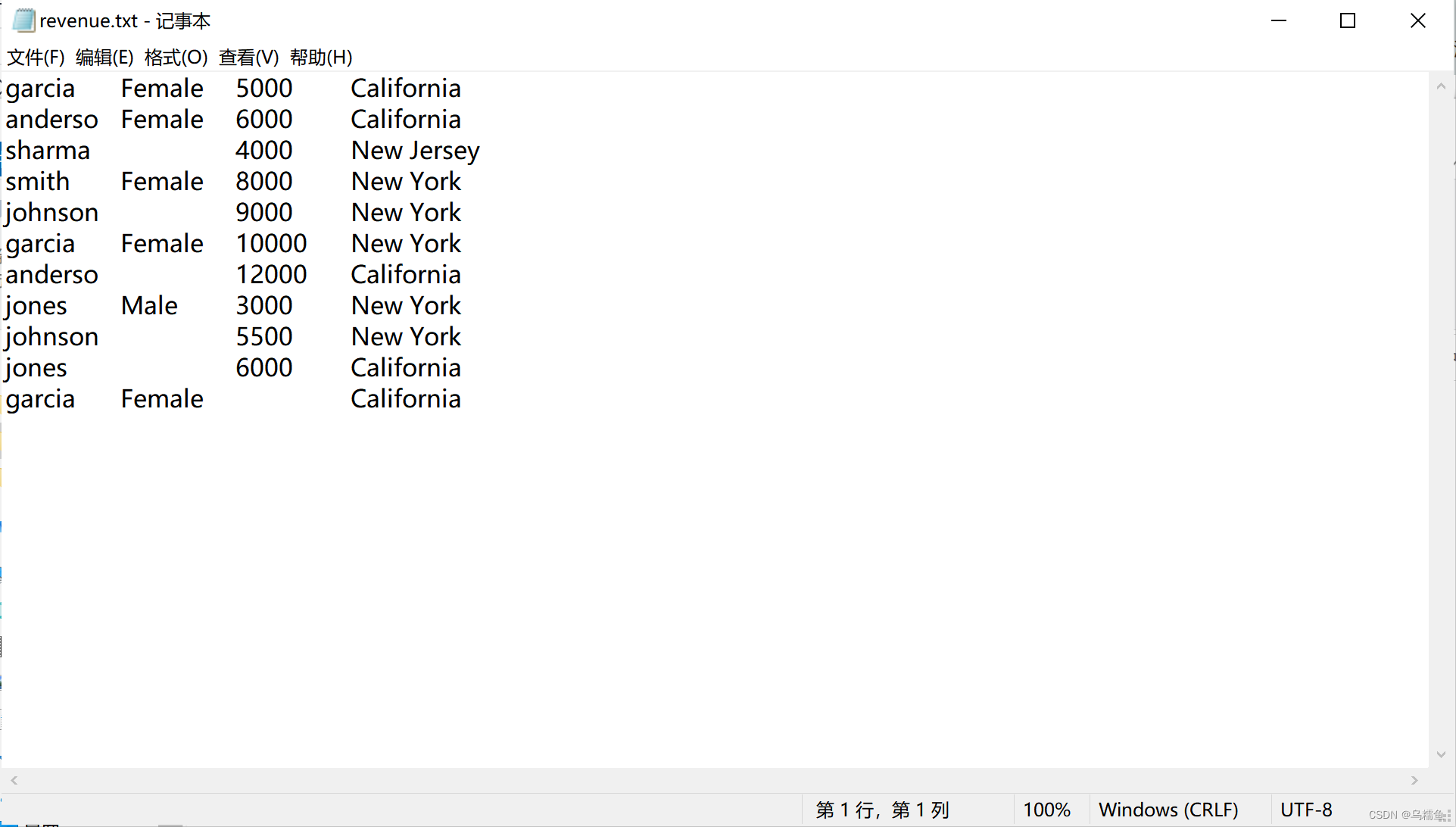
2. 打开Kettle工具,创建转换。通过使用Kettle工具,创建一个转换delete_missing_value,并添加“文本文件输入”控件、“字段选择”控件、“过滤记录”控件、“Excel输出”控件、“空操作(什么也不做)”控件以及Hop跳连接线。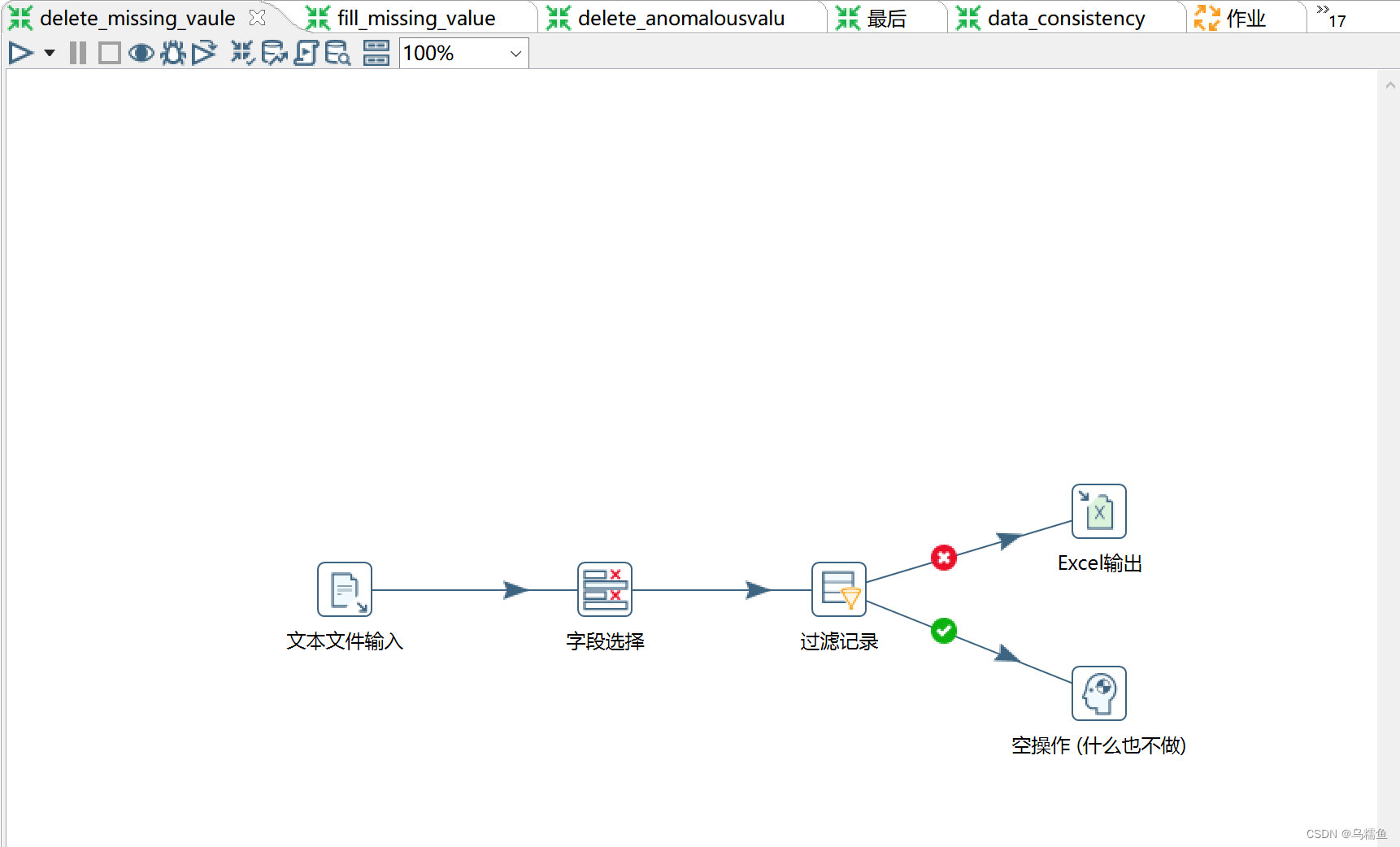
3.配置文本文件输入控件。双击“文本文件输入”控件,进入“文本文件输入”配置界面。单击【浏览】按钮,选择要去除缺失值的文件revenue.txt;单击【增加】按钮,将要去除缺失值的文件revenue.txt添加到“文本文件输入”控件中。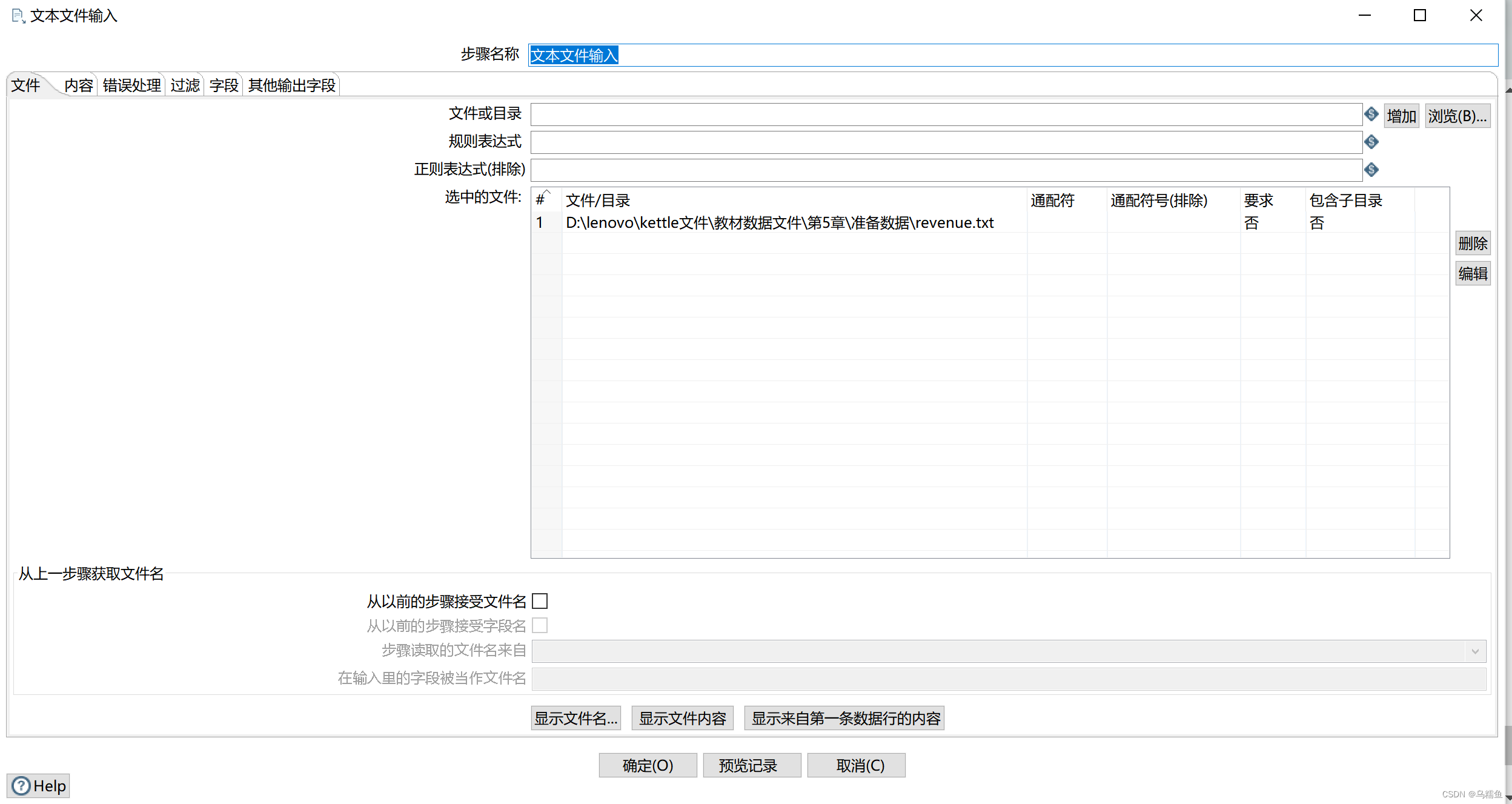
单击“内容”选项卡;在清除分隔符处的默认分隔符“;”,单击【Insert TAB】按钮,在分隔符处插入一个制表符;取消勾选“头部”复选框,若不取消,在进行数据抽取操作时会排除文件第一行的数据。
单击“字段”选项卡;根据文件revenue.txt的内容添加对应的字段名称,并指定数据类型。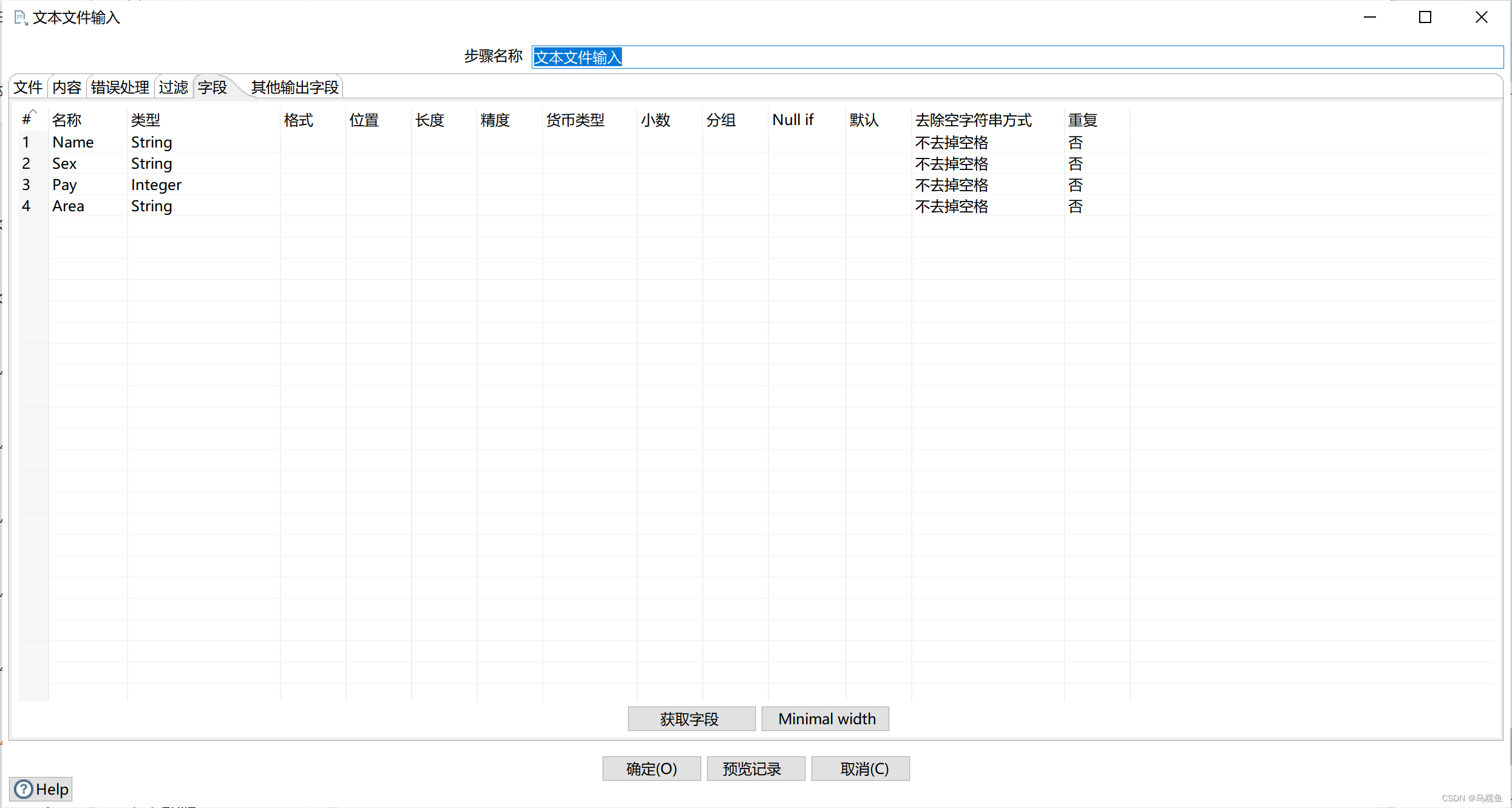
单击【预览记录】按钮,查看文件revenue.txt中的数据是否成功抽取到文本文件输入流中,具体如图所示。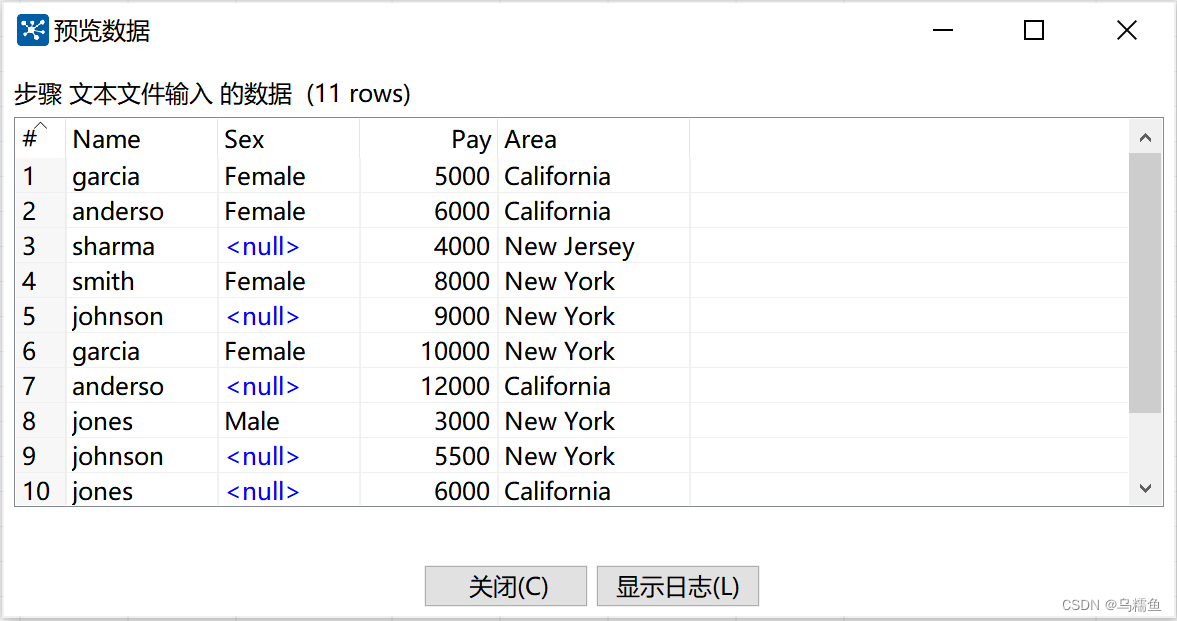
4.配置字段选择控件。双击“字段选择”控件,进入“选择/改名值”界面。在“选择和修改”选项卡的“字段”处手动添加文本文件输入控件输出的所有数据字段,也可以单击【获取选择的字段】按钮,Kettle工具自动检索并添加文本文件输入控件输出的所有数据字段。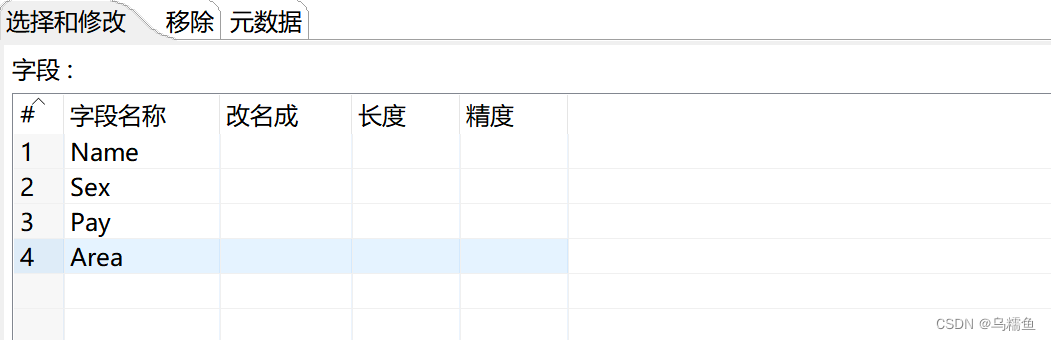
在“移除”选项卡处添加要移除的字段名称,这里移除的是Sex字段。 5.配置5.过滤记录控件。双击“过滤记录”控件,进入“过滤记录”界面。在“条件”处设置过滤的条件,过滤掉有缺失值的数据字段(这里是过滤Name、Pay和Area字段中的缺失值);单击左边“<field>”框,弹出字段对话框,选择要过滤的字段Name;单击 “=”框,弹出函数对话框,选择过滤条件(这里选择IS NULL)。
5.配置5.过滤记录控件。双击“过滤记录”控件,进入“过滤记录”界面。在“条件”处设置过滤的条件,过滤掉有缺失值的数据字段(这里是过滤Name、Pay和Area字段中的缺失值);单击左边“<field>”框,弹出字段对话框,选择要过滤的字段Name;单击 “=”框,弹出函数对话框,选择过滤条件(这里选择IS NULL)。
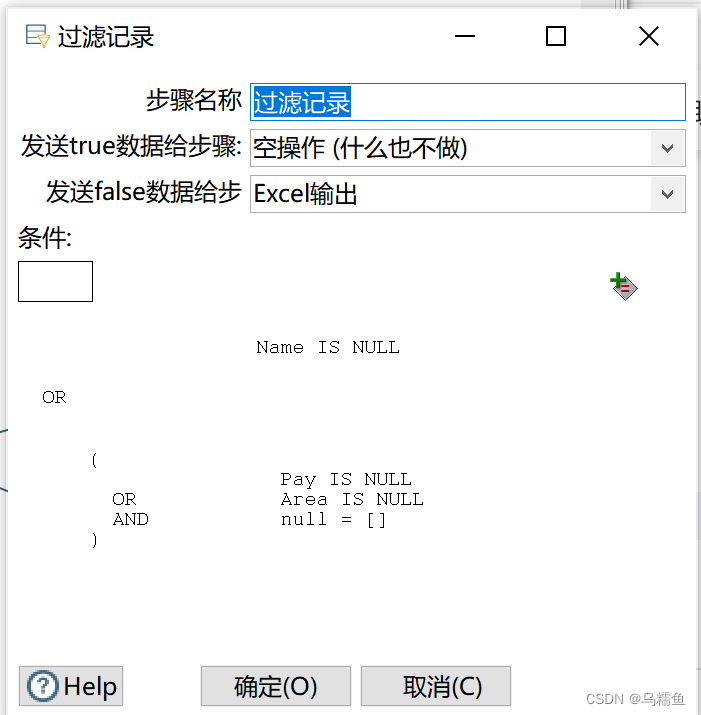
单击符号“+”增加过滤条件;单击“AND”,弹出操作符对话框,选择操作符(这里选择的是OR)。 单击“增加条件”图中的“null = [ ]”,添加过滤字段;单击左边“<field>”框,弹出字段对话框,选择要过滤的字段Pay;单击“=”框,弹出函数对话框,选择过滤条件(这里选择IS NULL)。字段Pay的过滤设置,如图所示。单击“字段Pay的过滤设置”图中的符号“+”增加过滤条件;单击“AND”,弹出操作符对话框,选择操作符(这里选择OR)。单击“增加条件”图中的“null = [ ]”,添加过滤字段;单击左边“<field>”框,弹出字段对话框,选择要过滤的字段Area;单击“=”框,弹出函数对话框,选择过滤条件(这里选择IS NULL);字段Area的过滤设置,具体如图所示。连续单击两次【确定】按钮,查看整体设置的过滤条件。在“发送true数据给步骤:”处的下拉框中选择“空操作”,将包含缺失值的行数据放在空操作控件中;在“发送false数据给步骤:”处的下拉框中选择“Excel输出”,将没有缺失值的行数据输出到Excel文件中。
6.配置Excel输出控件。双击“Excel输出”控件,进入“Excel输出”配置界面。单击【浏览】按钮,选择要输出的文件路径。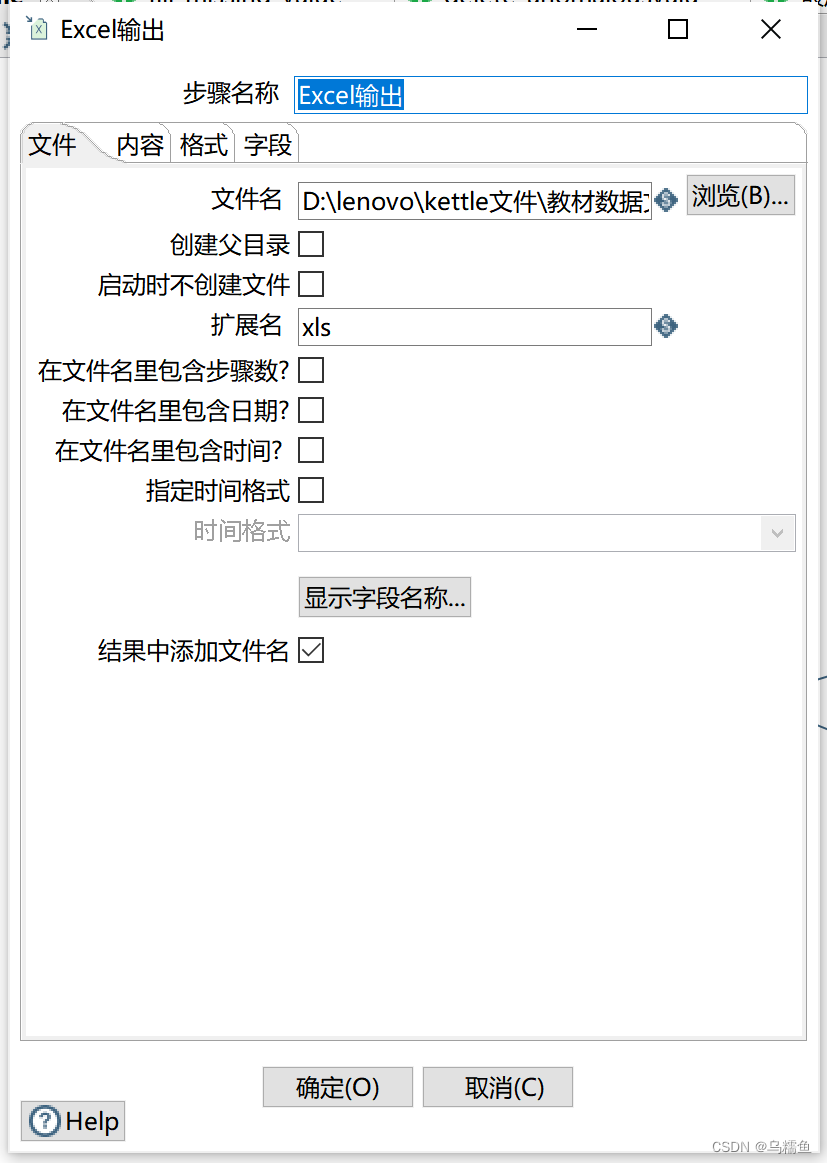
7.运行转换delete_missing_value。单击转换工作区顶部的运行按钮,运行创建的delete_missing_value转换。
8.查看“Excel输出”控件输出的文件file.xls是否还含有缺失值数据,文件file.xls的内容如图所示。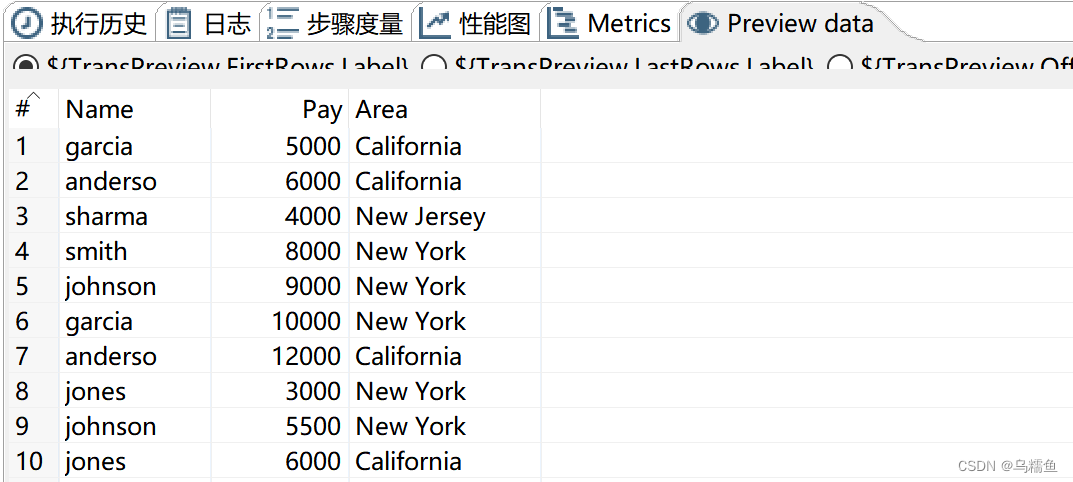
(2) 填充缺失值。
1.数据准备。现在有一份社会人员调查信息的数据文件people_survey.txt,由于某种原因,在数据采集的过程中产生了大量的缺失值,文件people_survey.txt的具体内容如图所示。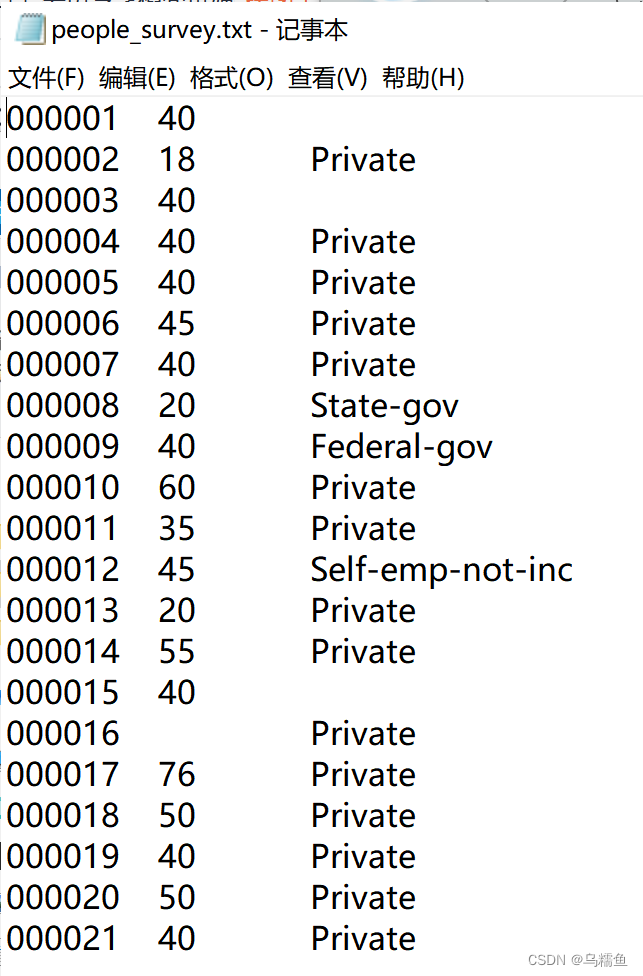
2. 通过使用Kettle工具,创建一个转换fill_missing_value,并添加“文本文件输入”控件、“过滤记录”控件、“空操作(什么也不做)”控件、“替换NULL值”控件、“合并记录”控件、“字段选择”控件以及Hop跳连接线。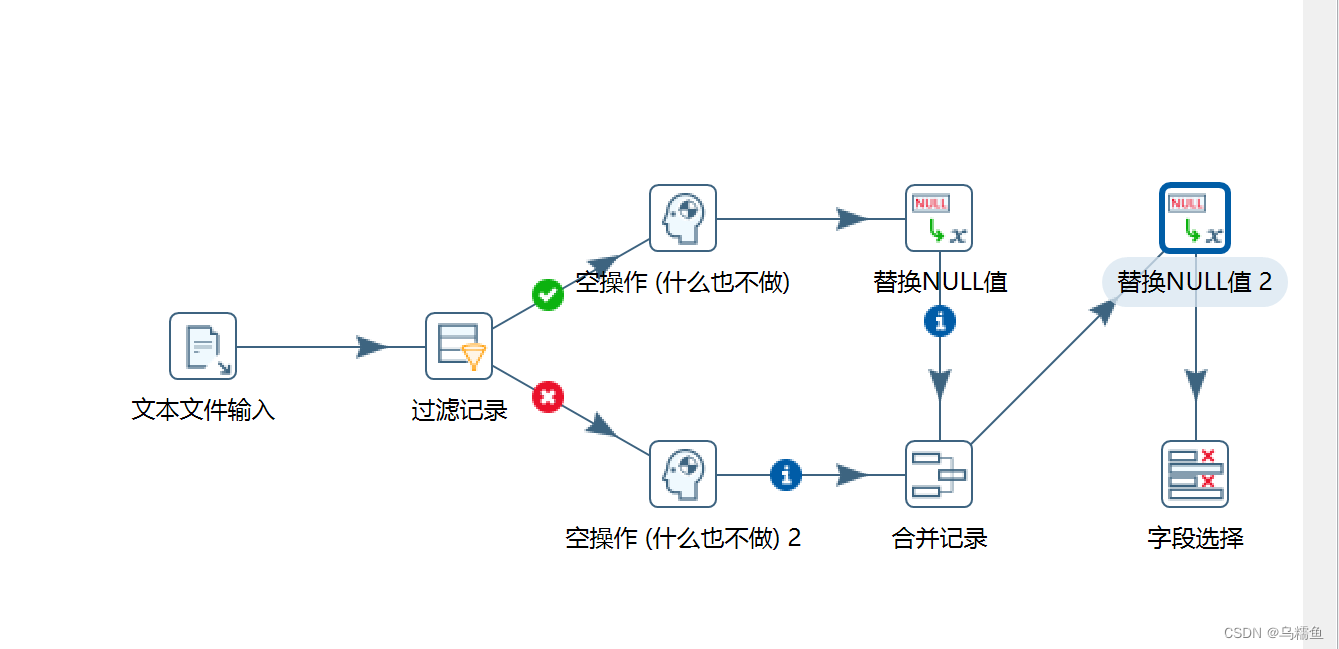
3.配置文本文件输入控件。双击“文本文件输入”控件,进入“文本文件输入”配置界面。单击【浏览】按钮,选择要去除缺失值的文件people_survey.txt;单击【增加】按钮,将要去除缺失值的文件people_survey.txt添加到“文本文件输入”控件中。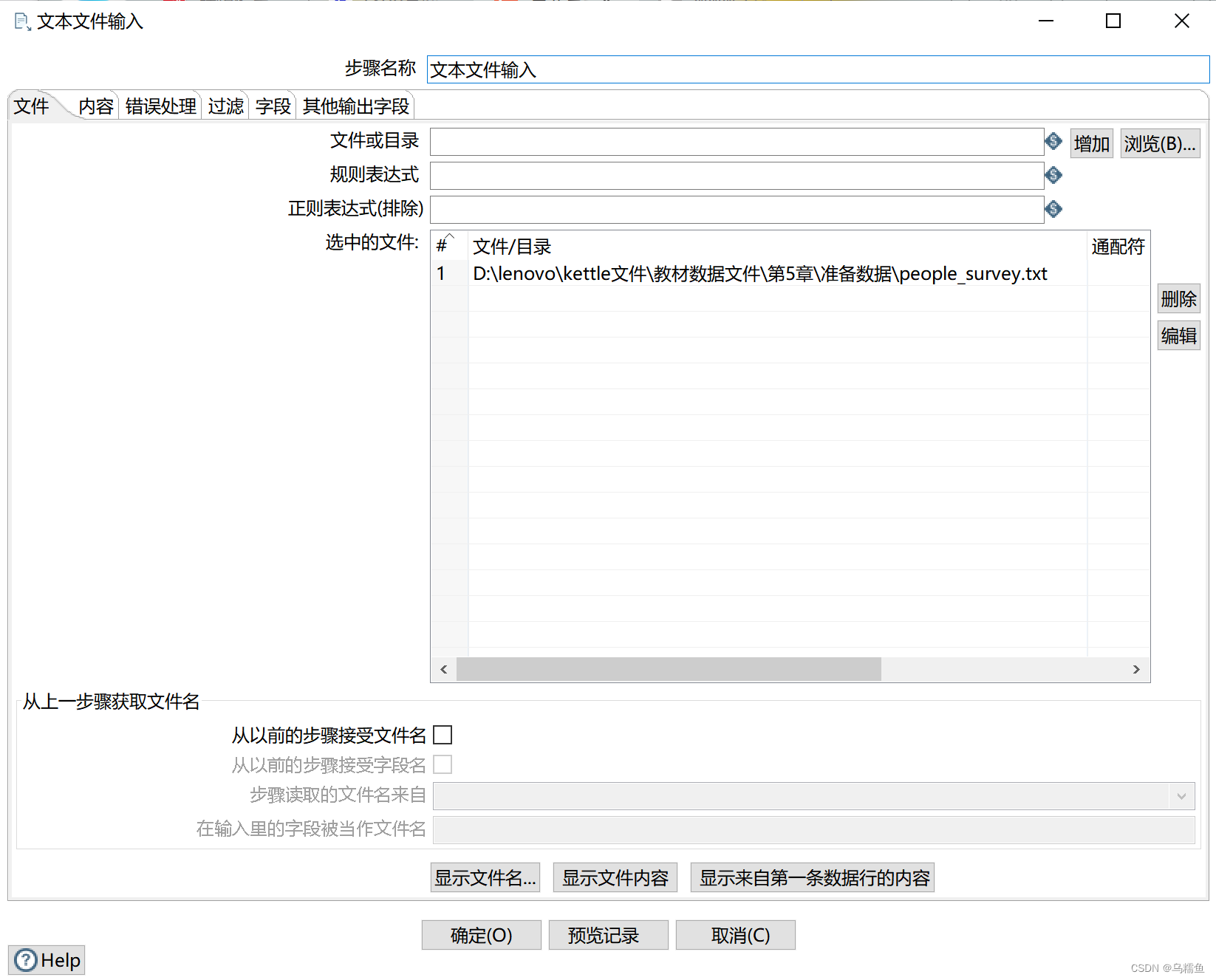
单击“内容”选项卡;在清除分隔符处的默认分隔符“;”,单击【Insert TAB】按钮,在分隔符处插入一个制表符;取消勾选“头部”复选框,若不取消,在进行数据抽取操作时会排除文件第一行的数据。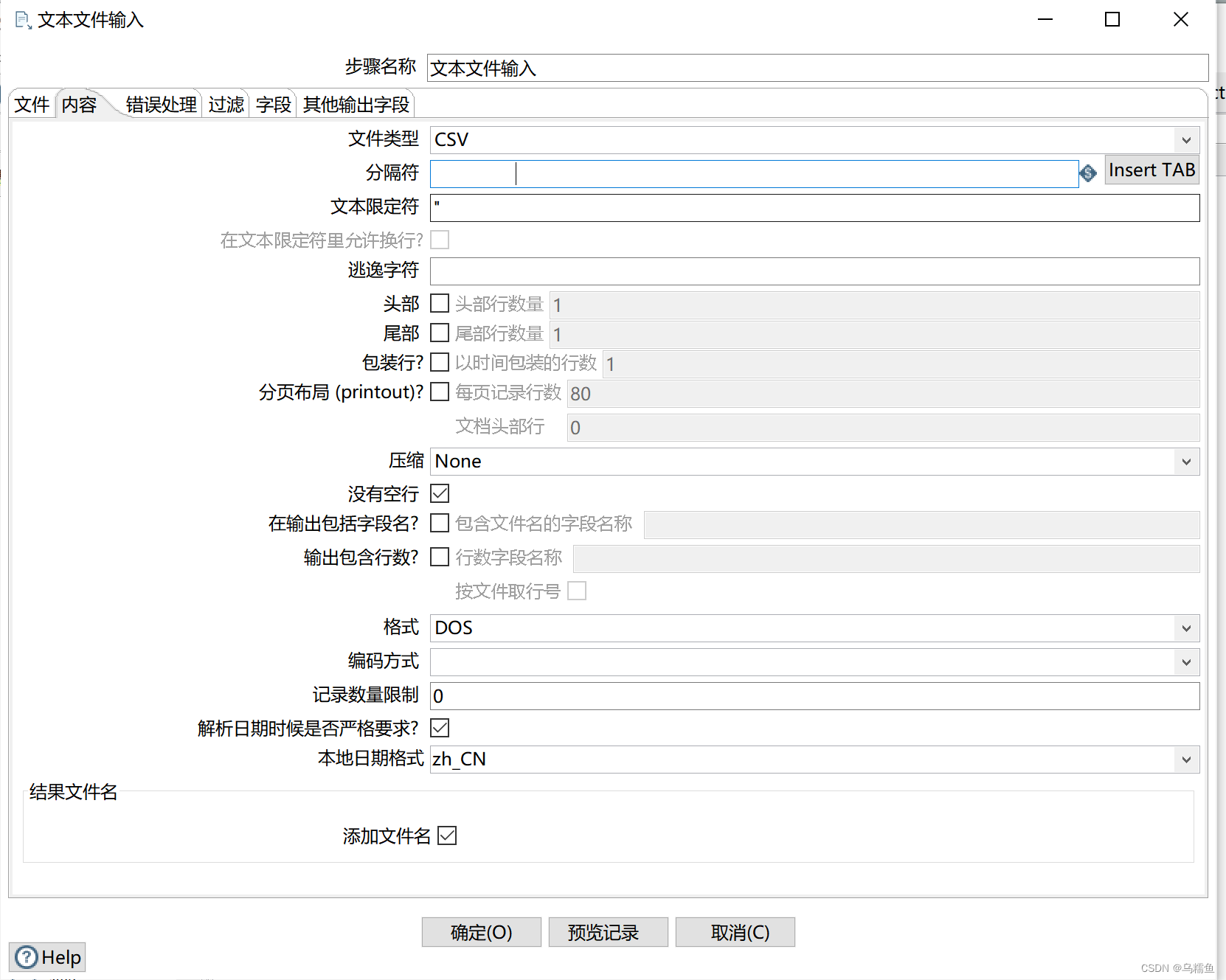
单击“字段”选项卡;根据文件people_survey.txt文件的内容添加对应的字段名称,并指定数据类型。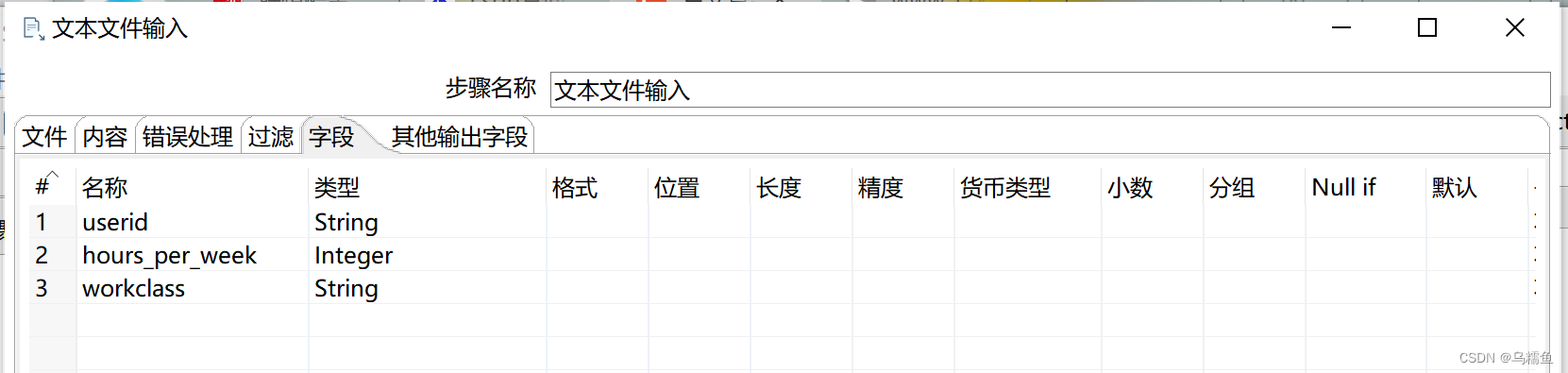
单击【预览记录】按钮,查看文件people_survey.txt的数据是否成功抽取到文本文件输入流中。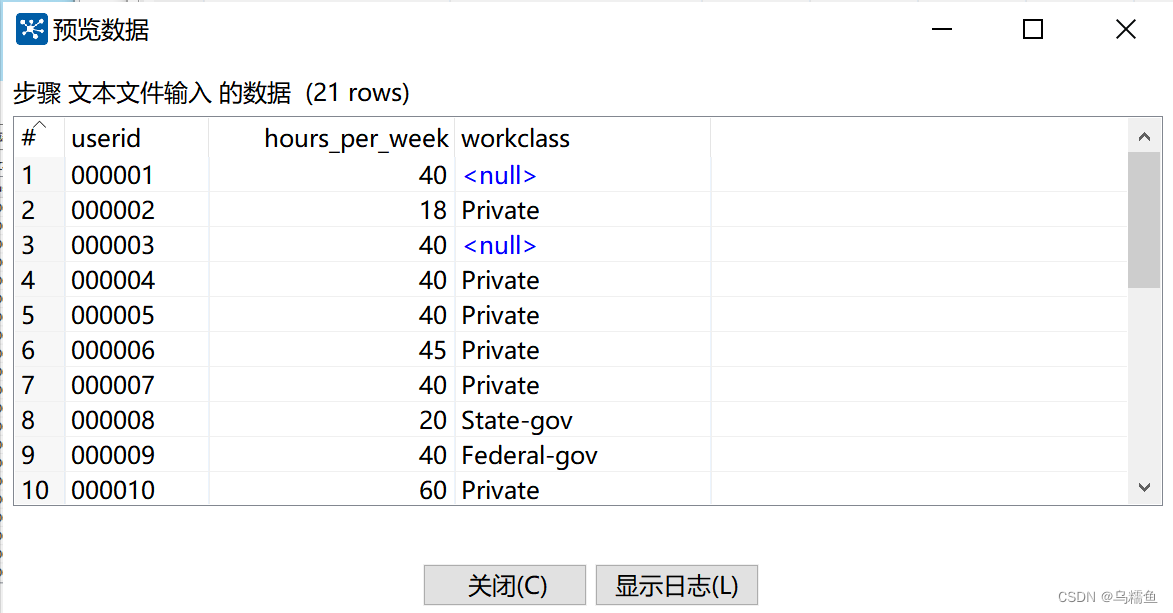
4.配置过滤记录控件。 双击“过滤记录”控件,进入“过滤记录”配置界面。在“条件”处设置过滤的条件,由于从“预览数据”图中可以看出字段userid为000016用户的hours_per_week(即每周工作时间字段)存在缺失值,而它的workclass字段值为Private,因此我们可以将过滤字段设置为workclass、过滤值设置为Private作为过滤条件。在“发送true数据给步骤:”下拉框中选择“空操作”,将workclass字段值为Private的数据放在“空操作”控件中;在“发送false数据给步骤:”下拉框中选择“空操作(什么也不做)2”,将workclass字段值不为Private的数据放在“空操作(什么也不做)2”控件中。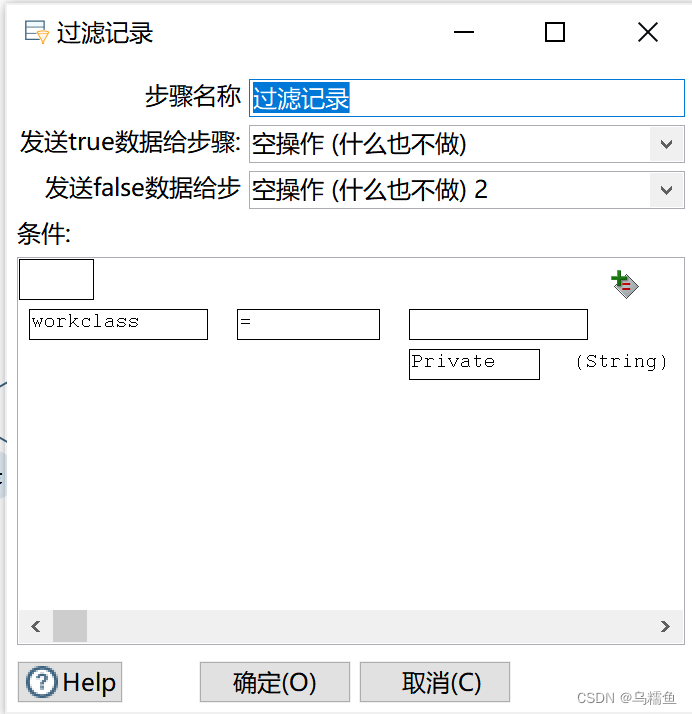
5.配置替换NULL值控件。 双击“替换NULL值”控件,进入“替换NULL值”配置界面。勾选“选择字段”处的复选框,并在“字段”框添加字段为hours_per_week,值替换为44(44是字段为hours_per_week中所有值相加求的均值,这里指用44替换字段hours_per_week中的NULL值)。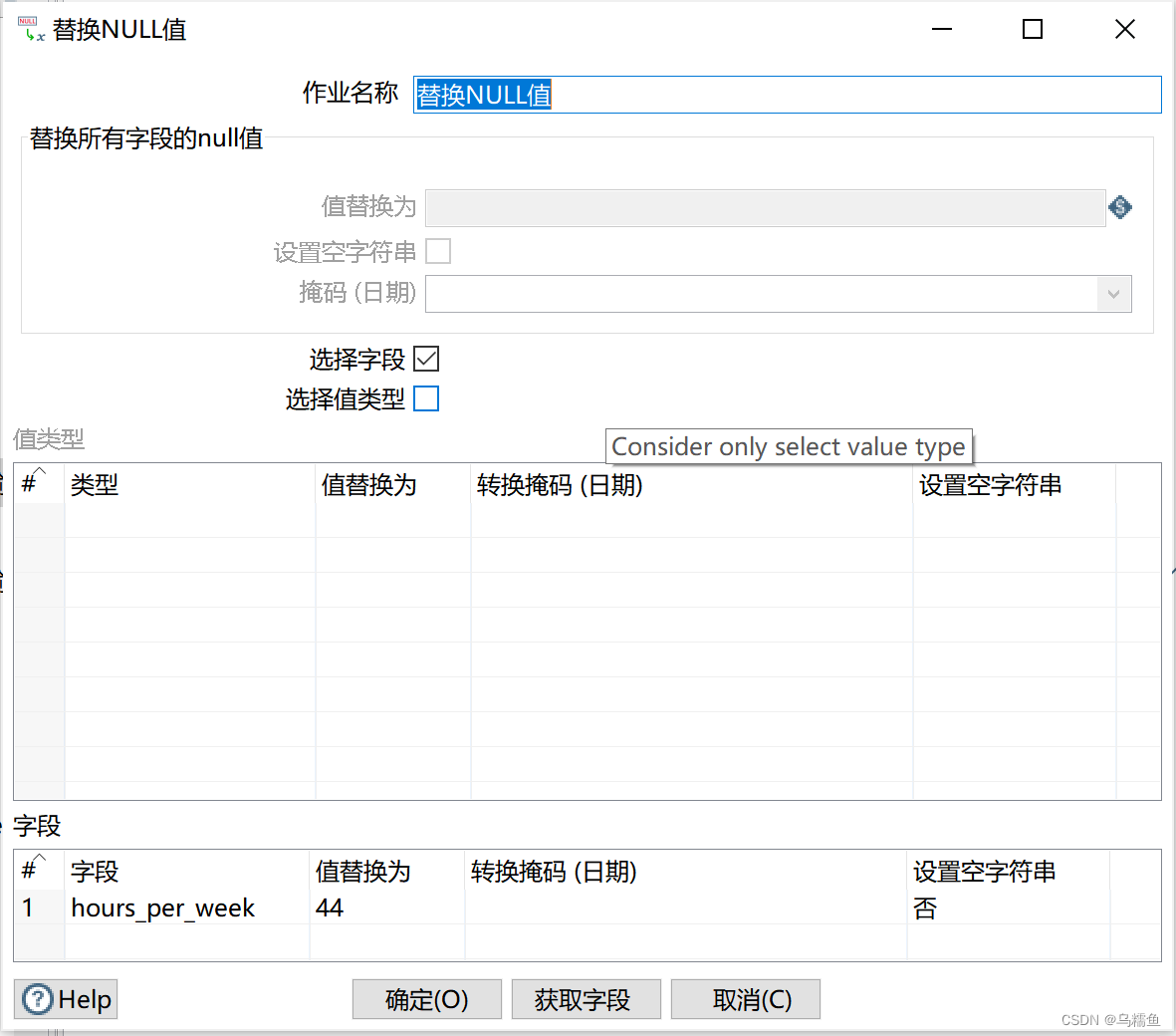
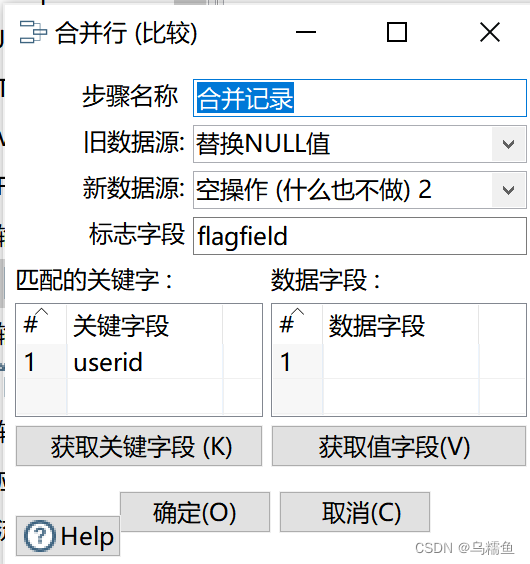
6.双击“合并记录”控件,进入“合并行(比较)”配置界面。 在”旧数据源:”下拉框选择“替换NULL值”,“新数据源:”下拉框选择“空操作(什么也不做)2”;在“匹配的关键字:”部分,添加关键字段,即userid。
7.配置替换NULL值2控件。双击“替换NULL值2”控件,进入“替换NULL值”配置界面。勾选“选择字段”处的复选框,并在“字段”框添加字段为workclass,值替换为Private(这里用Private替换字段workclass中的NULL值)。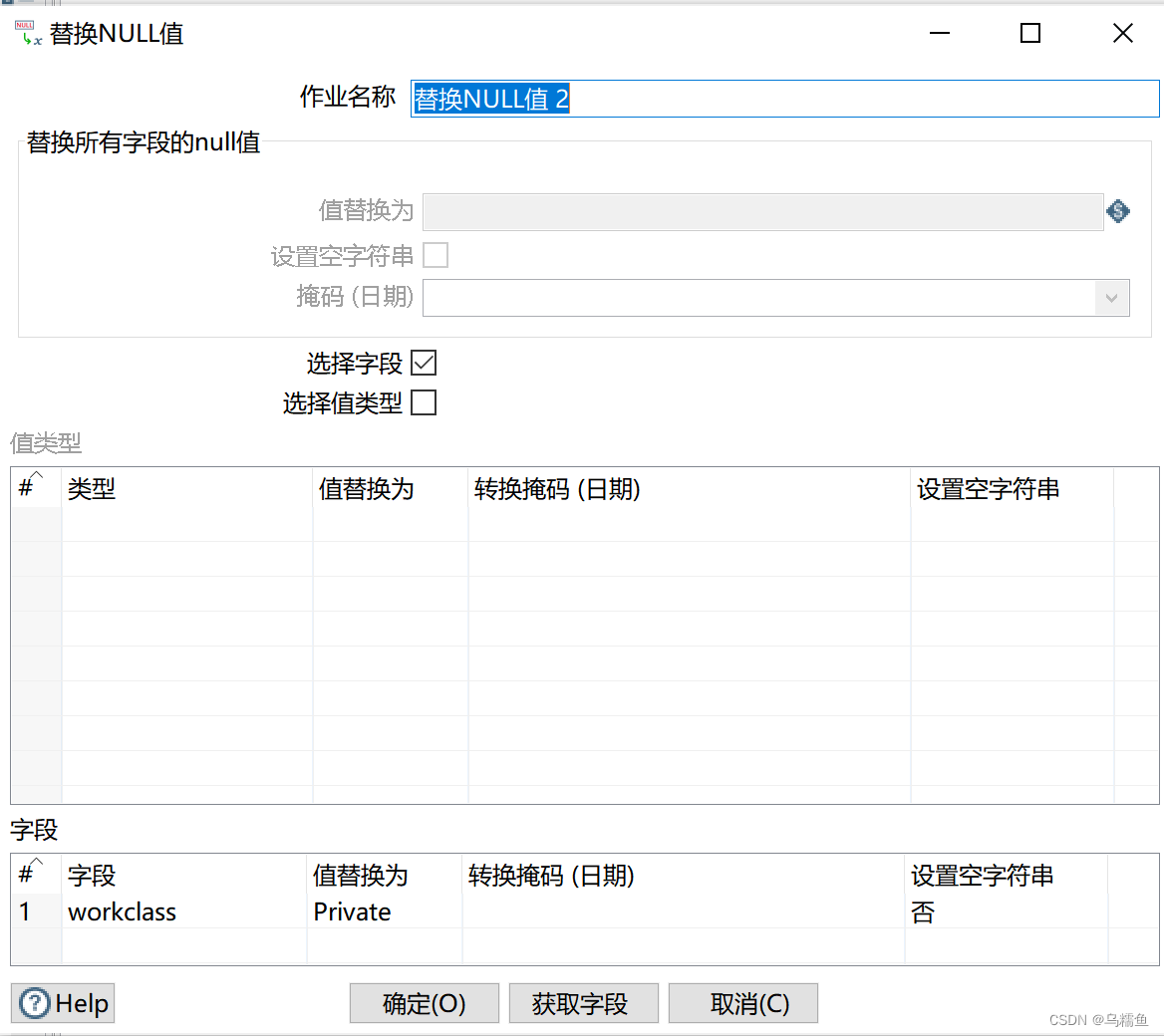
8. 配置字段选择控件。双击“字段选择”控件,进入“选择/改名值”配置界面。在“移除”选项卡处添加要移除的字段名称,这里移除的是字段flagfield。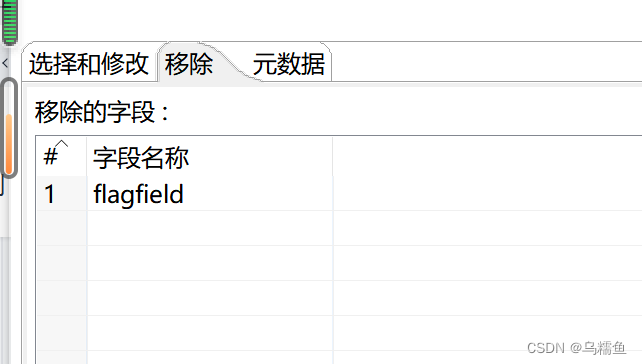
9. 运行转换fill_missing_value。
5.3 异常值处理
(1)删除包含异常值的记录。
1.数据准备。现在有这样一份记录一天中不同时间温度的数据文件temperature.txt,其中包含时间和温度(摄氏度)两个字段,具体内容如图所示(展示部分数据)。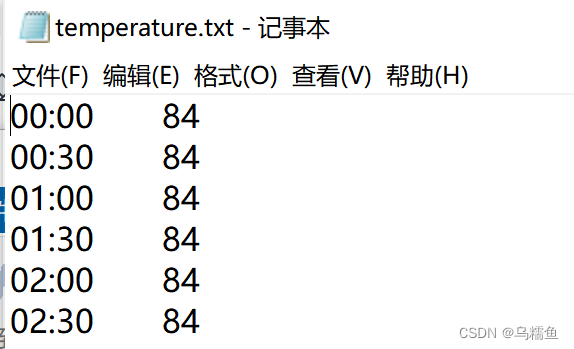
2. 通过使用Kettle工具,创建一个转换delete_anomalous _value,并添加“文本文件输入”控件、“过滤记录”控件、“空操作(什么也不做)”控件以及Hop跳连接线。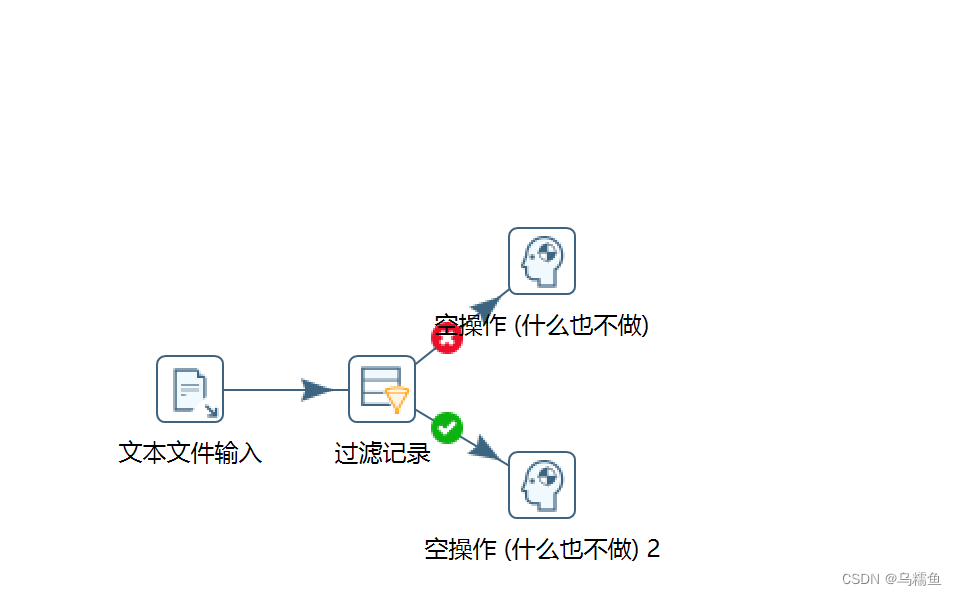
3. 双击“文本文件输入”控件,进入“文本文件输入”配置界面。先单击【浏览】按钮,选择要去除异常值的文件temperature.txt,然后单击【增加】按钮,将要去除异常值的文件temperature.txt添加到“文本文件输入”控件中。
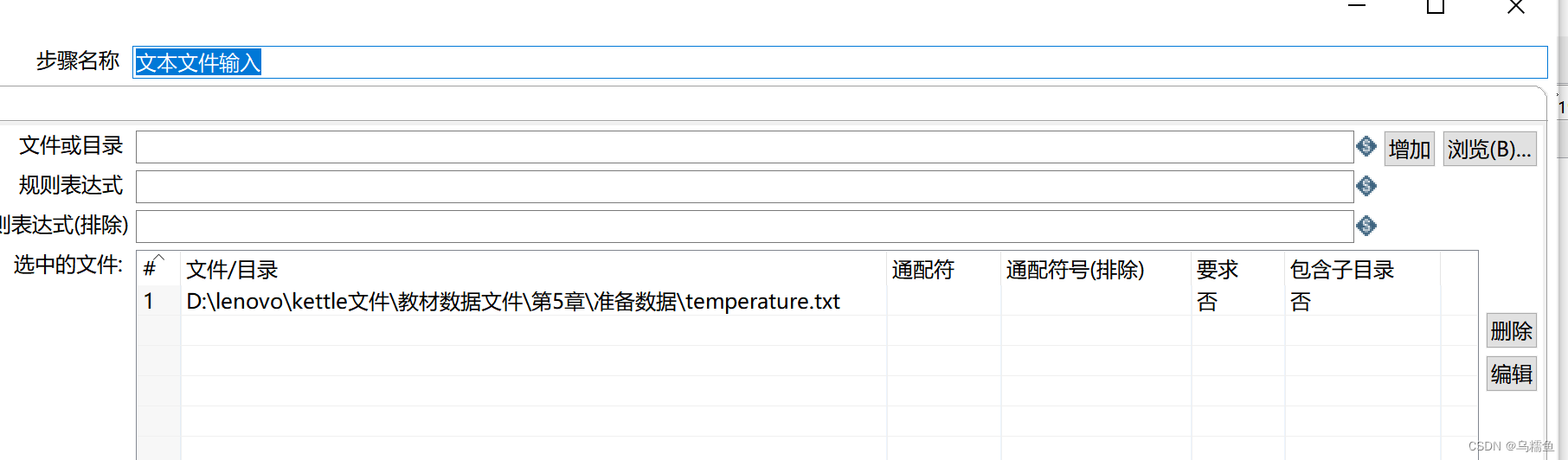
单击“内容”选项卡;清除分隔符处的默认分隔符“;”,单击【Insert TAB】按钮,在分隔符处插入一个制表符;取消勾选“头部”复选框,若不取消,在进行数据抽取操作时会排除文件第一行的数据。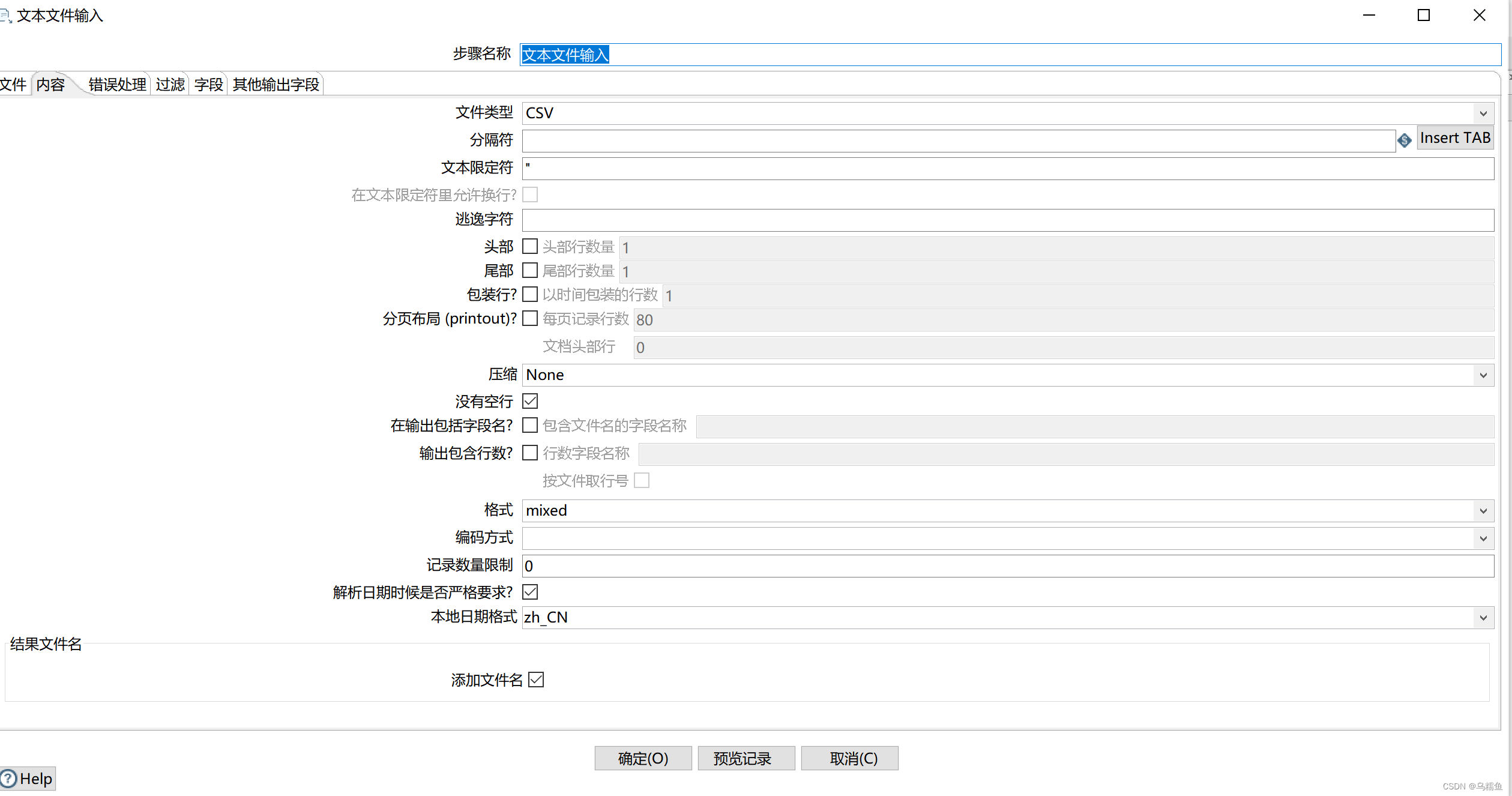
单击“字段”选项卡;根据文件temperature.txt的内容添加对应的字段名称,并指定数据类型。
单击【预览记录】按钮,查看文件temperature.txt的数据是否成功抽取到文本文件输入流中。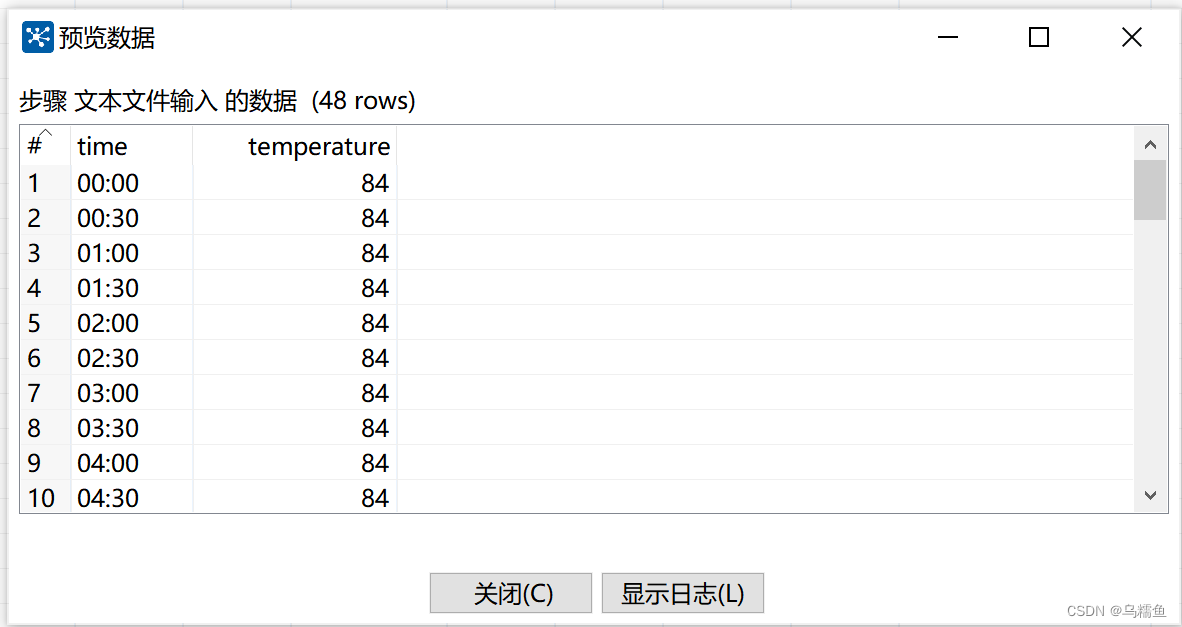
4.配置过滤记录控件。 双击“过滤记录”控件,进入“过滤记录”配置界面。在“条件”处设置过滤的条件,由于文件temperature.txt中time为6:30的温度是137摄氏度,不在非异常值的范围内,因此属于异常值,我们应该将过滤字段设置为temperature、过滤值为137。在“发送true数据给步骤:”处的下拉框中选择“空操作(什么也不做)2”,将异常值放在“空操作(什么也不做)2”控件中;在“发送false数据给步骤:”处的下拉框中选择“空操作(什么也不做)”,将非异常值放在“空操作(什么也不做)”控件中。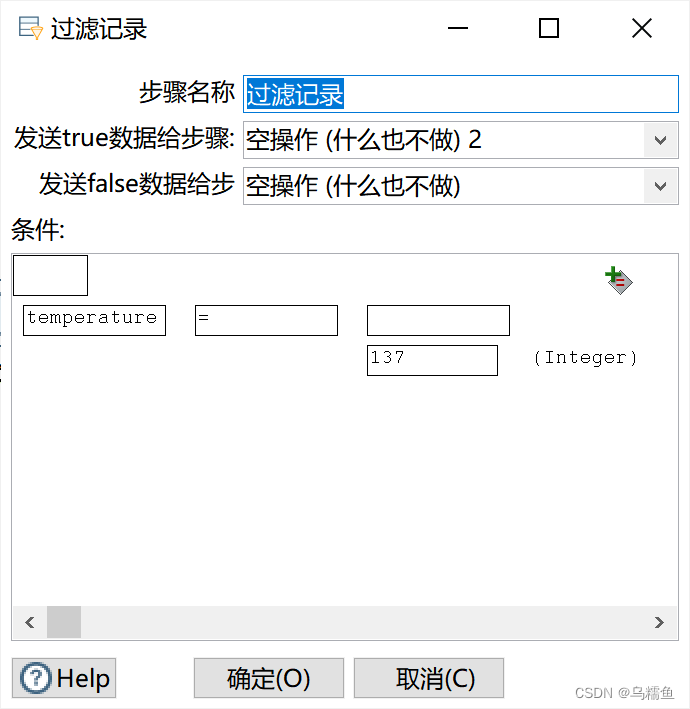
5.运行转换delete_anomalous_value。
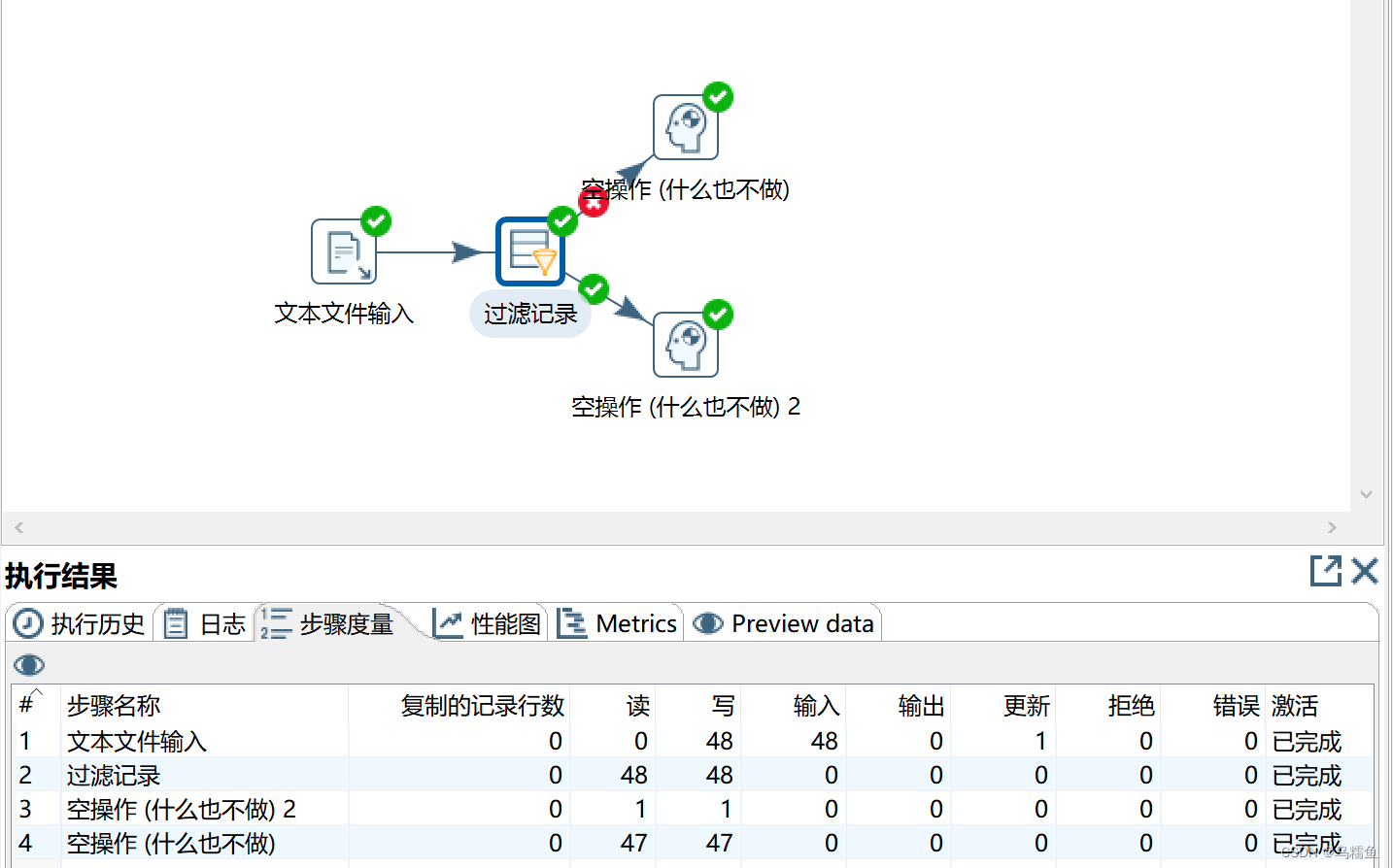
6.查看文件temperature.txt是否去除了异常值。单击“空操作”控件,再单击执行结果的“Preview data”选项卡,查看是否去除了异常值。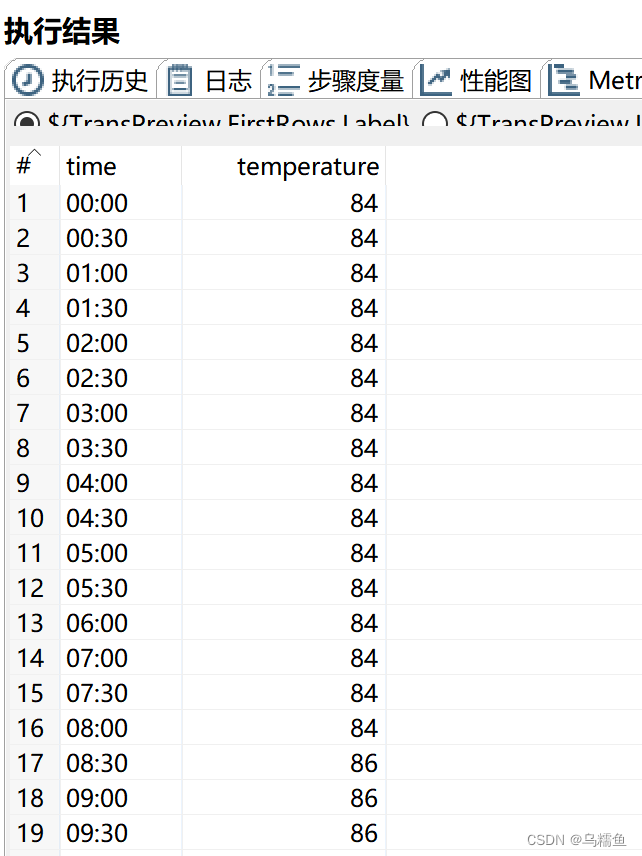
(2)修补异常值。
1.现在有一份500人的身高调查数据表interpolation_data,其中包括id、Gender和Height字段。
2.通过使用Kettle工具,创建一个转换fill_unusual_value,并添加“表输入”控件、“过滤记录”控件、“空操作(什么也不做)”控件、“设置值为NULL”控件、“合并记录”控件、“替换NULL值”控件、字段选择控件以及Hop跳连接线。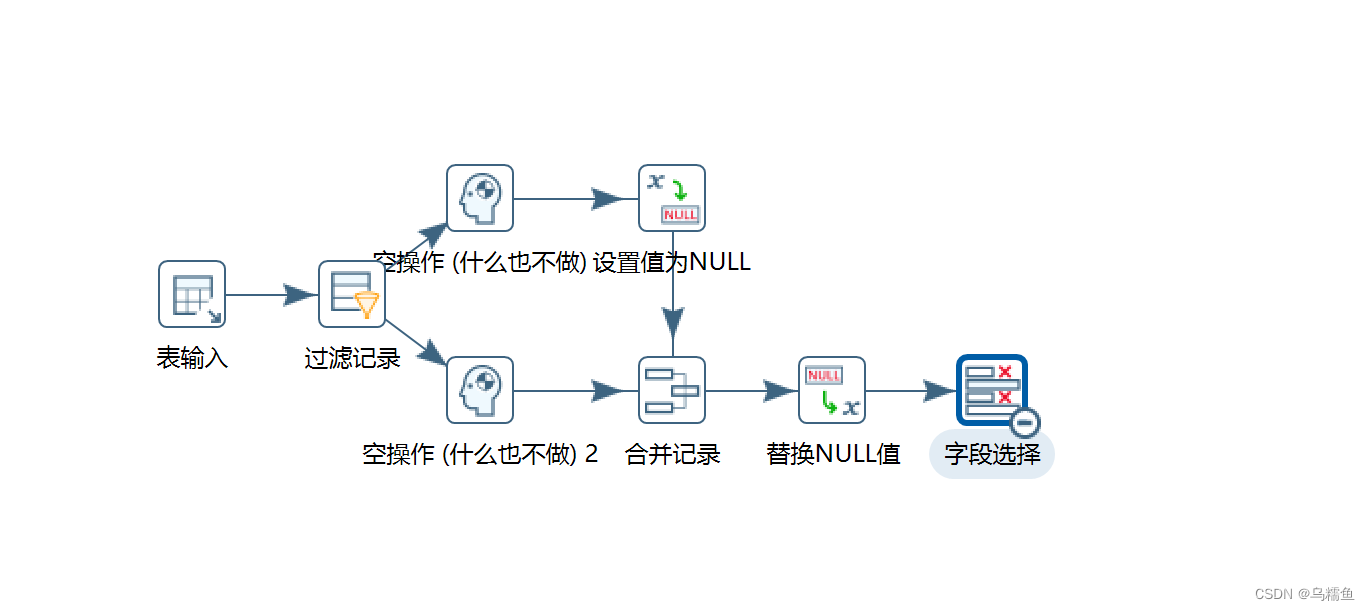
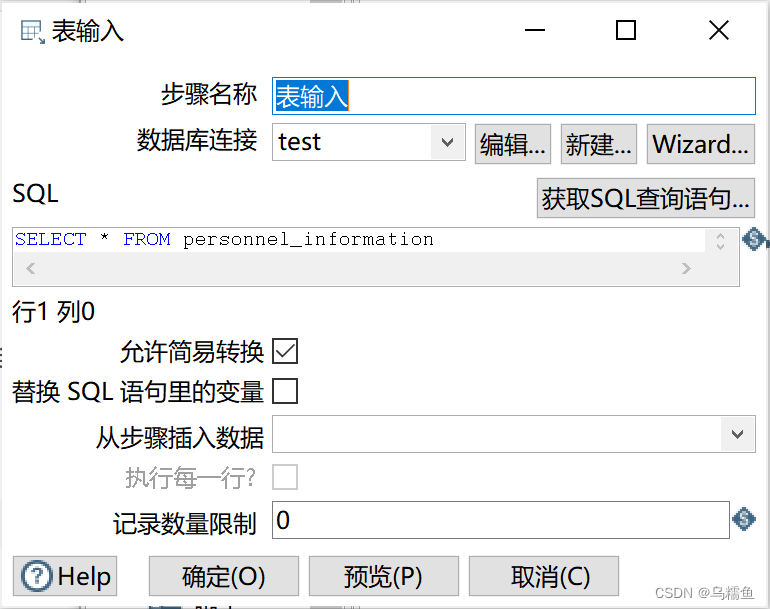
3.双击“表输入”控件,进入“表输入”配置界面。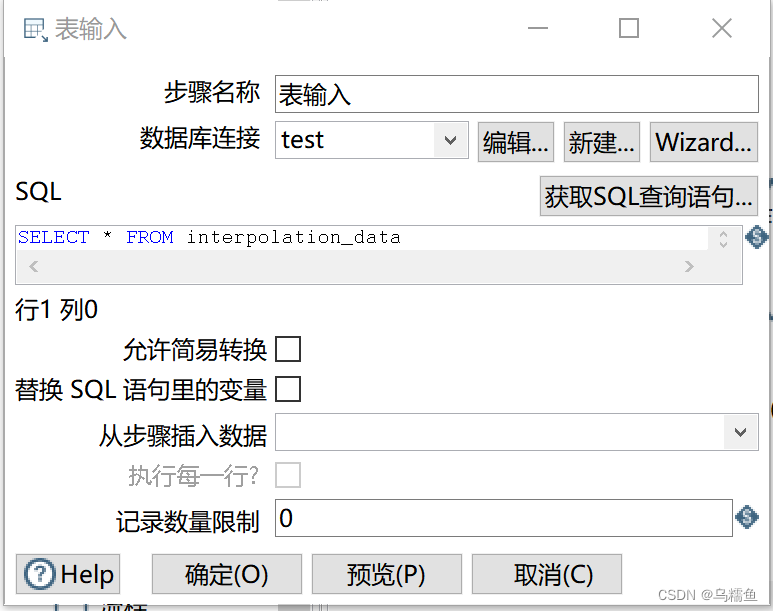 配置数据库连接,配置完成后单击【确认】按钮。
配置数据库连接,配置完成后单击【确认】按钮。
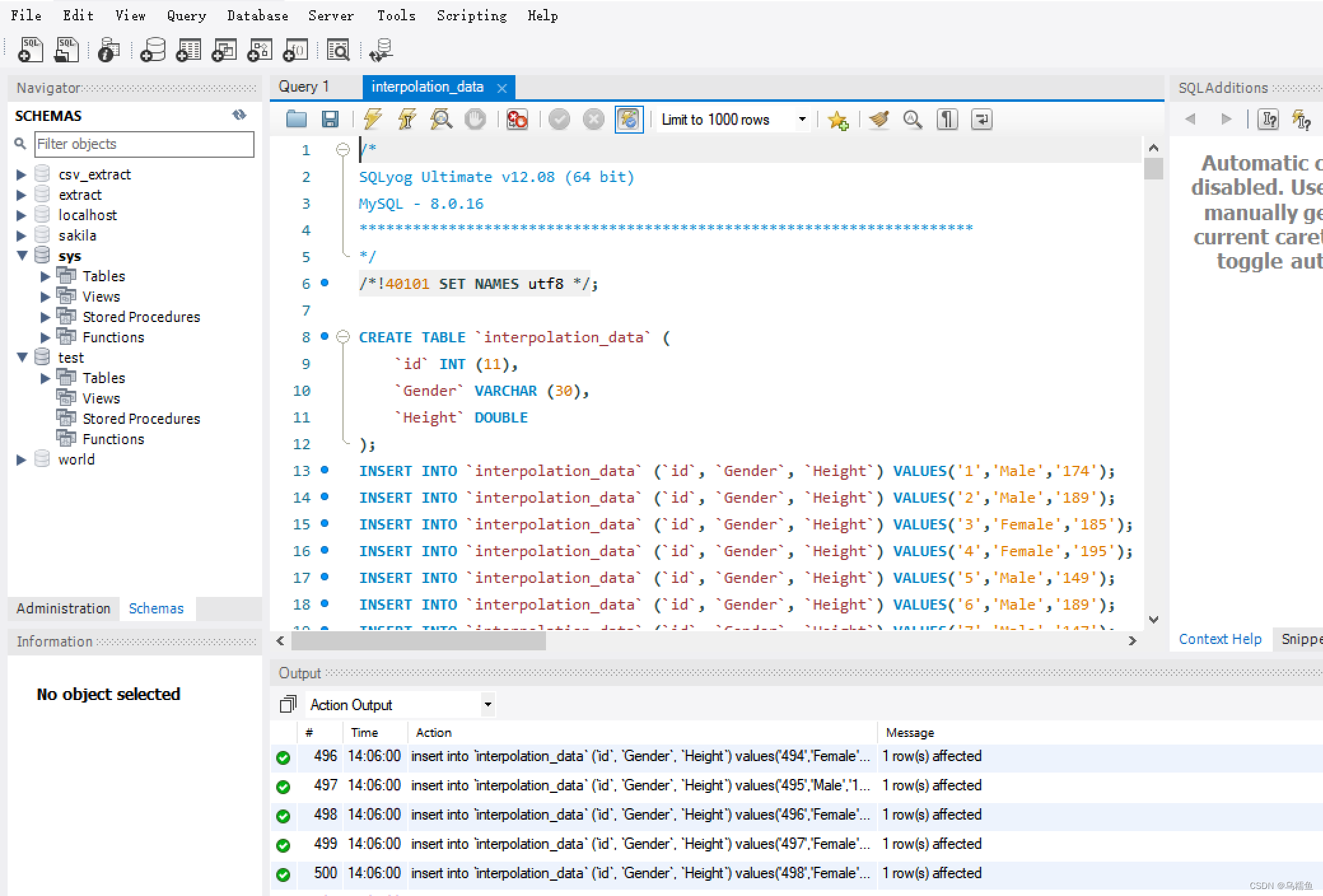
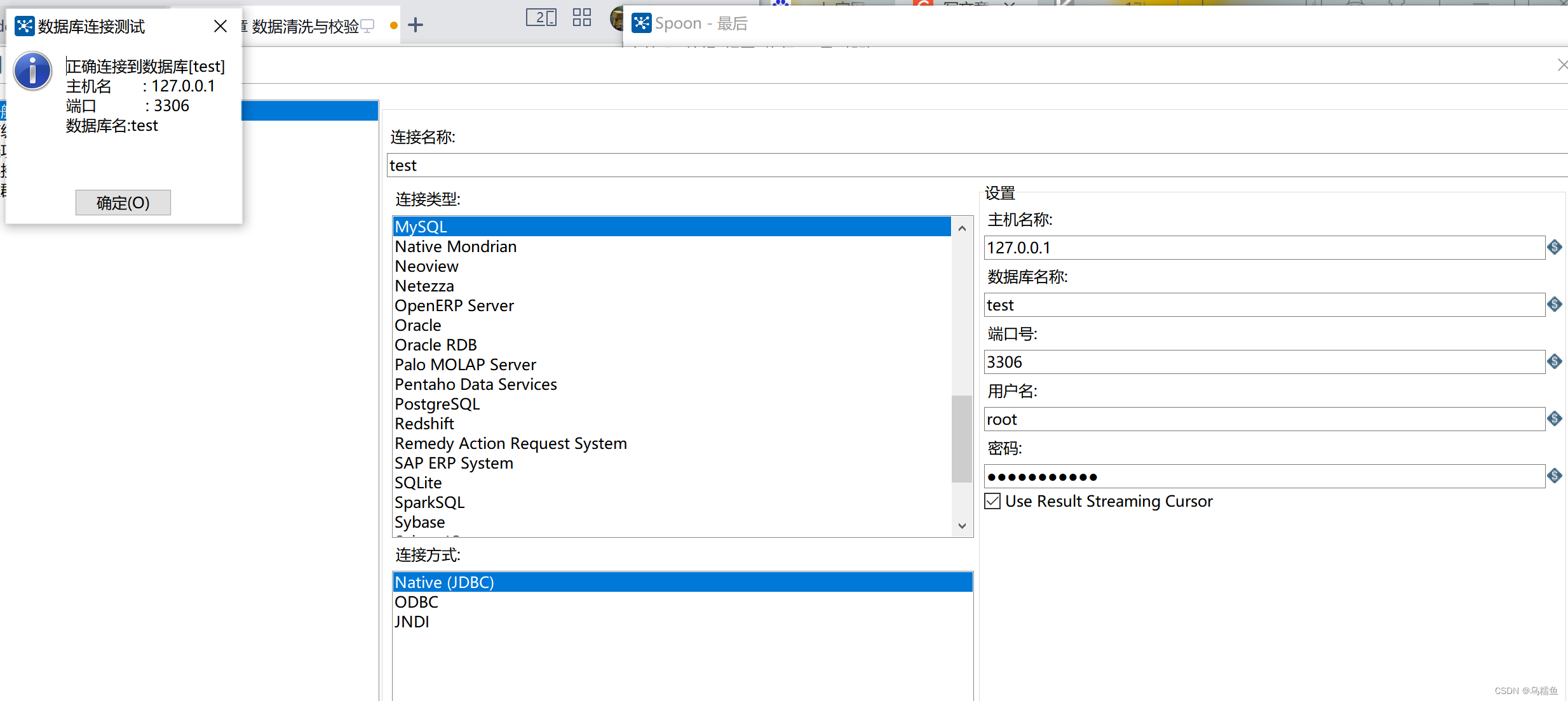
在SQL框中编写查询数据表interpolation_data的SQL语句,然后单击【预览】按钮,查看数据表interpolation_data的数据是否成功从MySQL数据库中抽取到表输入流中。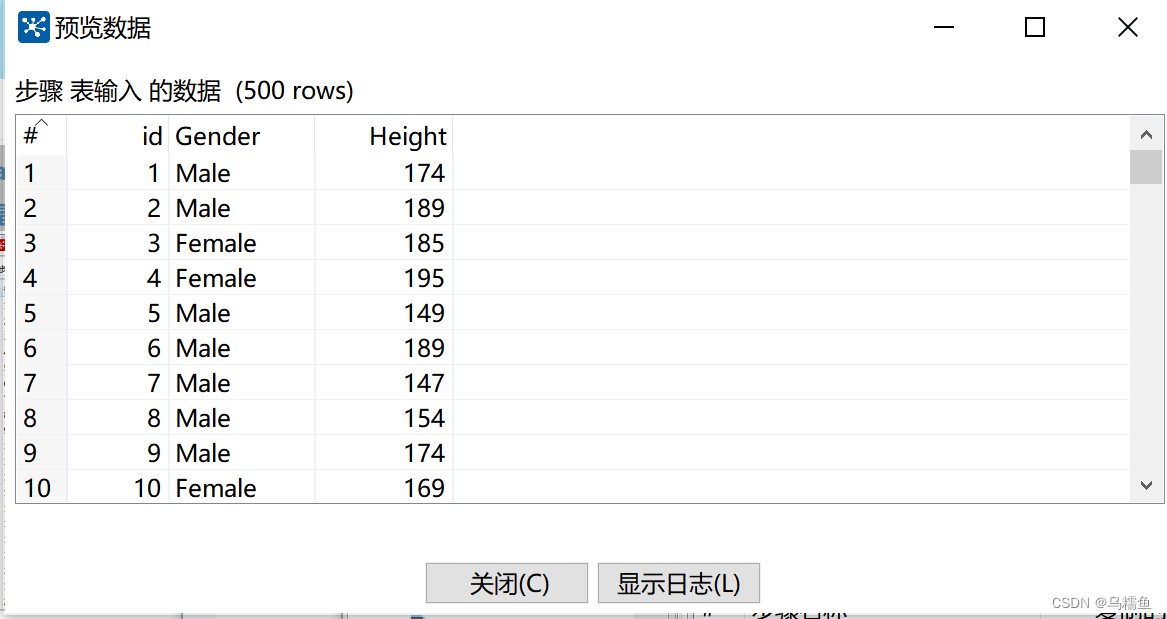
4.双击“过滤记录”控件,进入“过滤记录”配置界面。 在“条件”处设置过滤的条件,即设置Height字段的取值范围([114-226]),从而判断数据表中的每个数据是否为异常值。若是在非异常值的取值范围内,则是非异常值,否则是异常值。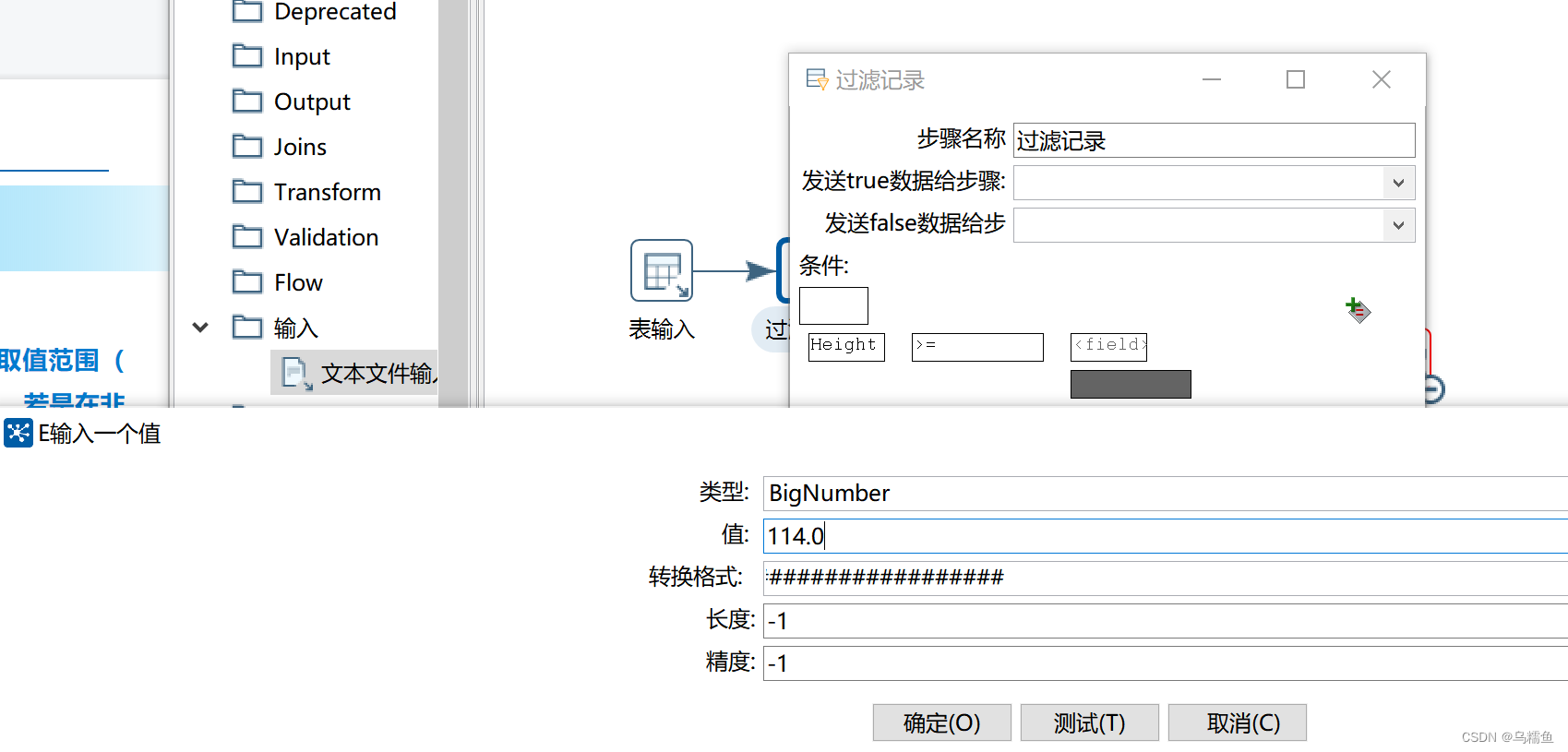
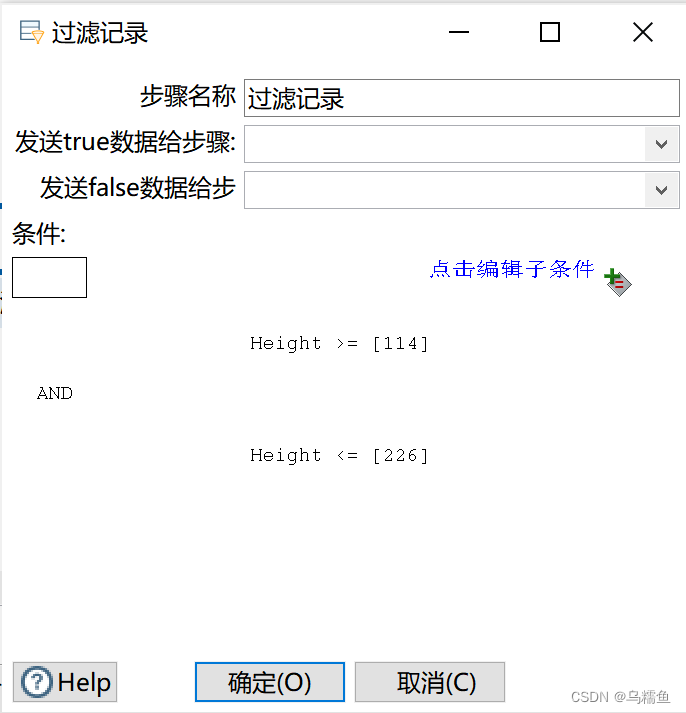 在“发送true数据给步骤:”处的下拉框中选择“空操作(什么也不做)2”,将非异常值放在“空操作(什么也不做)2”控件中;在“发送false数据给步骤:”处的下拉框中选择“空操作(什么也不做)”,将异常值放在“空操作(什么也不做)”控件中。
在“发送true数据给步骤:”处的下拉框中选择“空操作(什么也不做)2”,将非异常值放在“空操作(什么也不做)2”控件中;在“发送false数据给步骤:”处的下拉框中选择“空操作(什么也不做)”,将异常值放在“空操作(什么也不做)”控件中。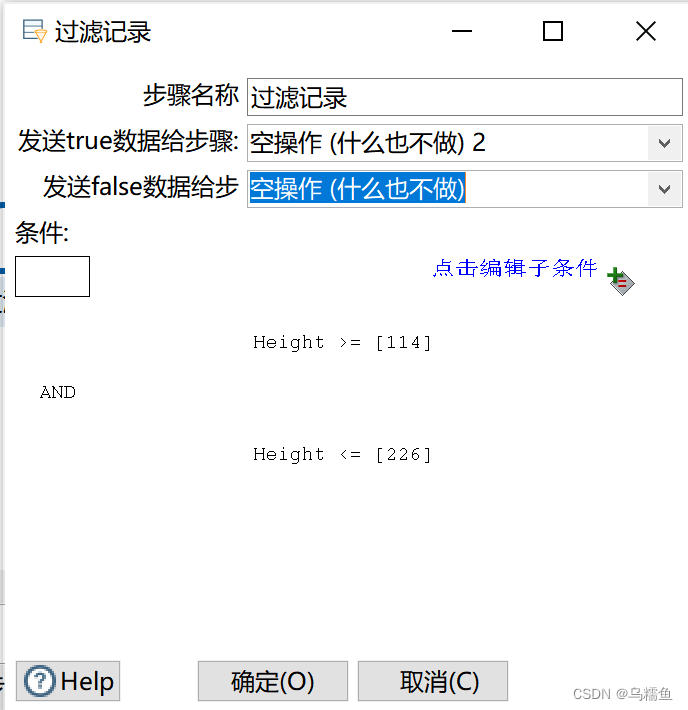
5.选中“空操作(什么也不做)”控件,然后单击转换工作区顶部的预览按钮,预览“空操作(什么也不做)”控件中的数据,id为15的这条数据,Height字段为260,260不在非异常值范围[114,226]内,因此该条数据为异常数据。 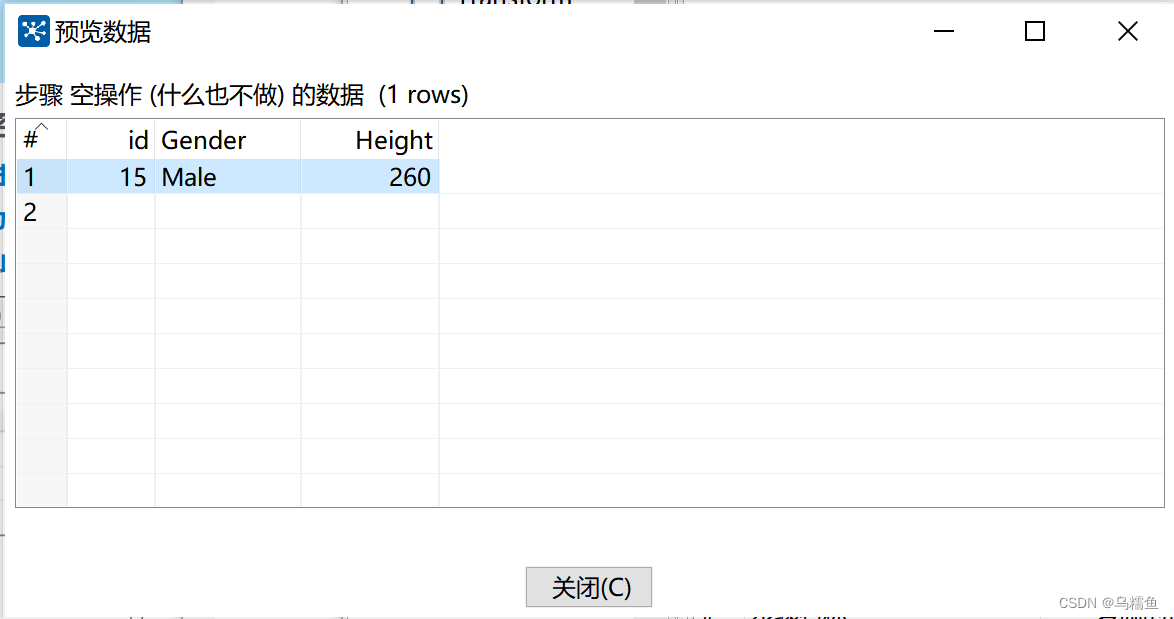
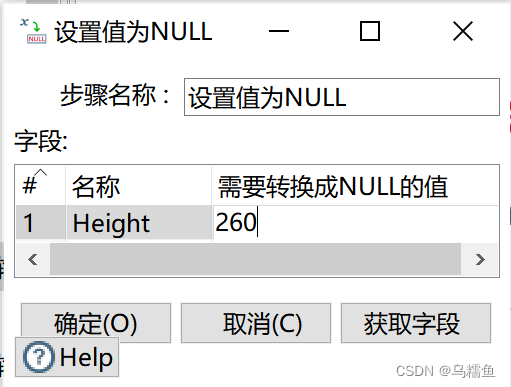
6.双击“设置值为NULL”控件,进入“设置值为NULL”界面;在“字段”处添加要设为NULL值的字段名称和值。
7.双击“合并记录”控件,进入“合并行(比较)”界面。在“旧数据源:”处的下拉框选择“设置为NULL值”,“新数据源:”处的下拉框选择“空操作(什么也不做)2”;在“匹配的关键字:”处,添加关键字段,即id。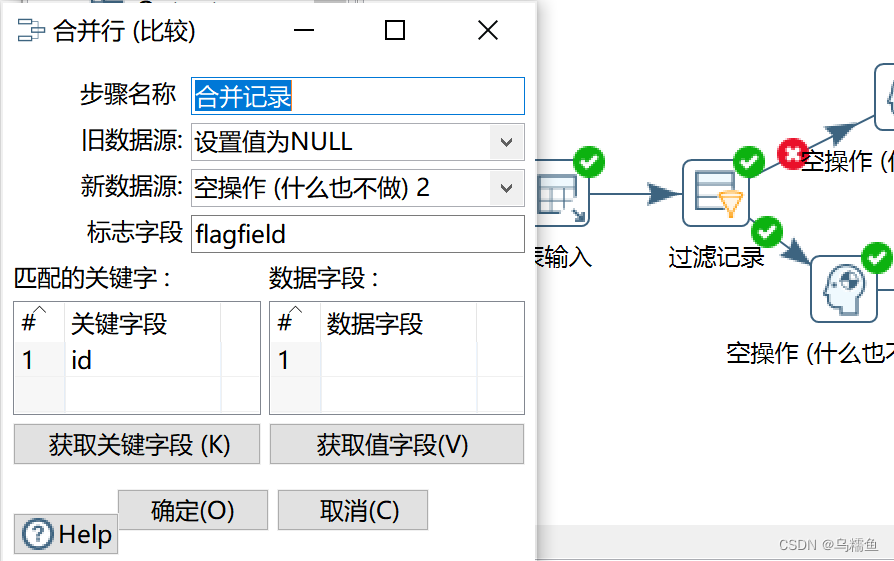
8.双击“替换NULL值”控件,进入“替换NULL值”界面。勾选“选择字段”处的复选框,并在“字段”框添加字段为Hight,值替换为170(通过计算得到499人的平均身高值近似为170,因此用170替换字段Hight中的NULL值)。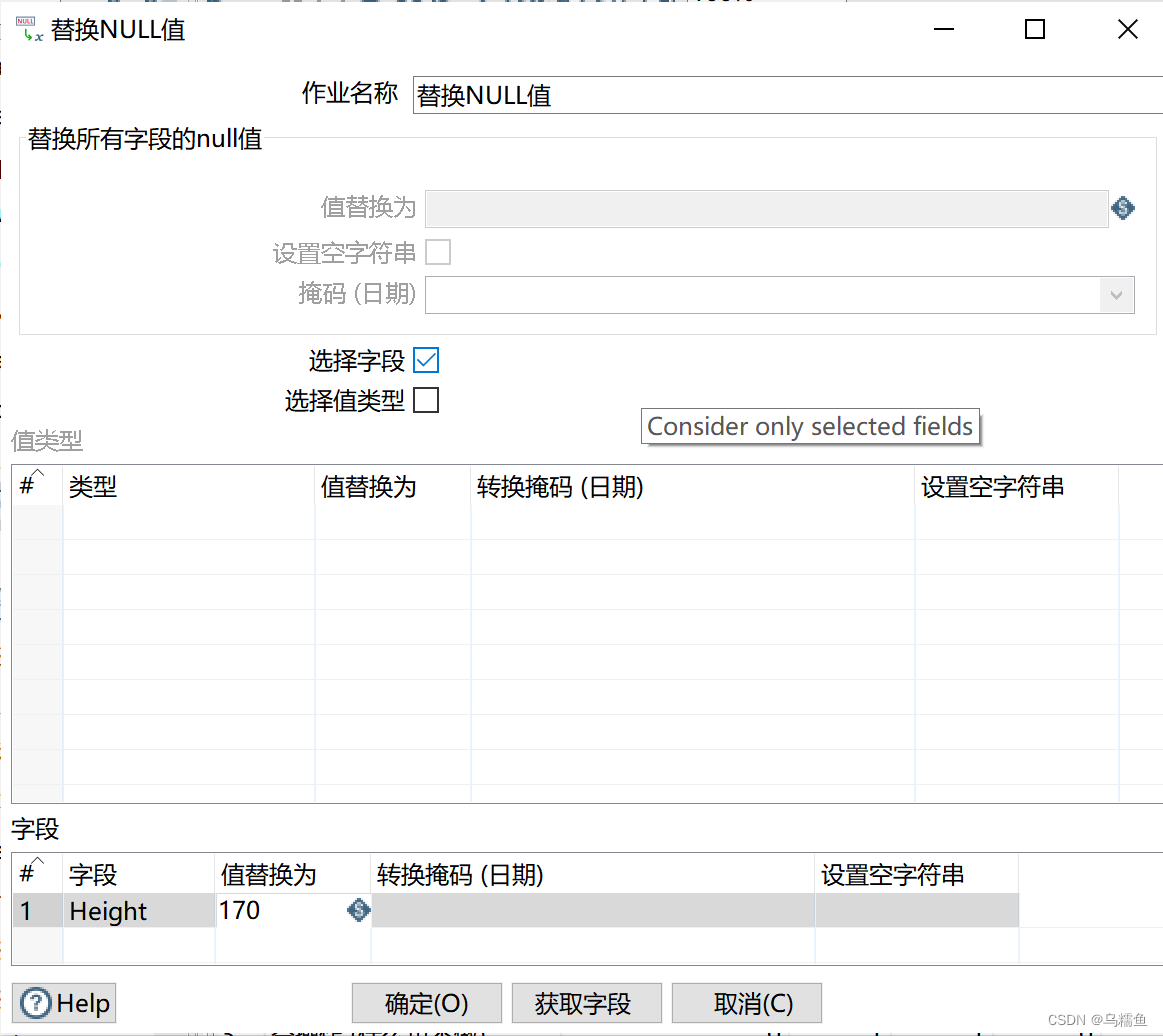
9. 双击“字段选择”控件,进入“选择/改名值”界面。在“移除”选项卡处添加要移除的字段名称,这里移除的是字段flagfield。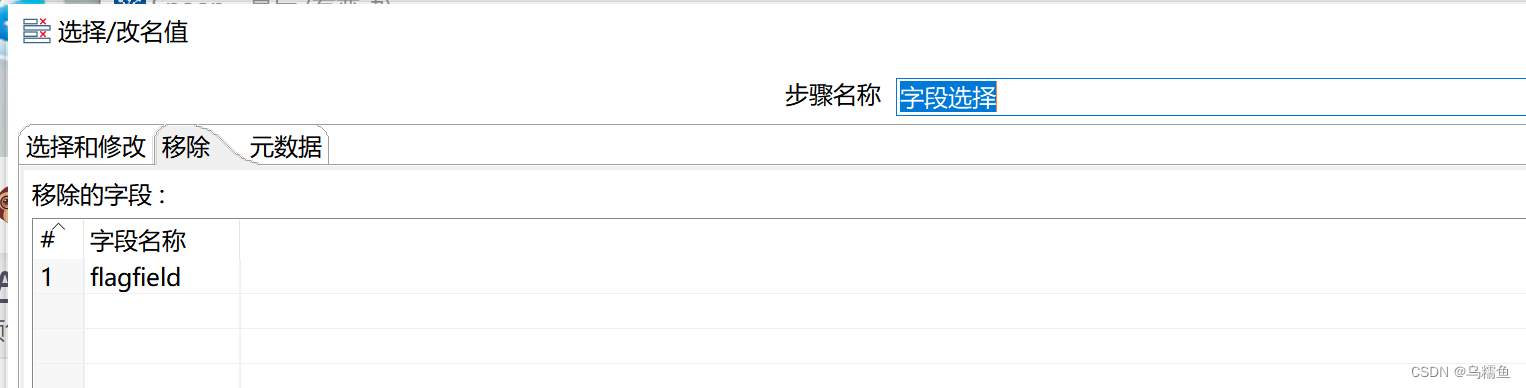
10.运行转换fill_unusual_value。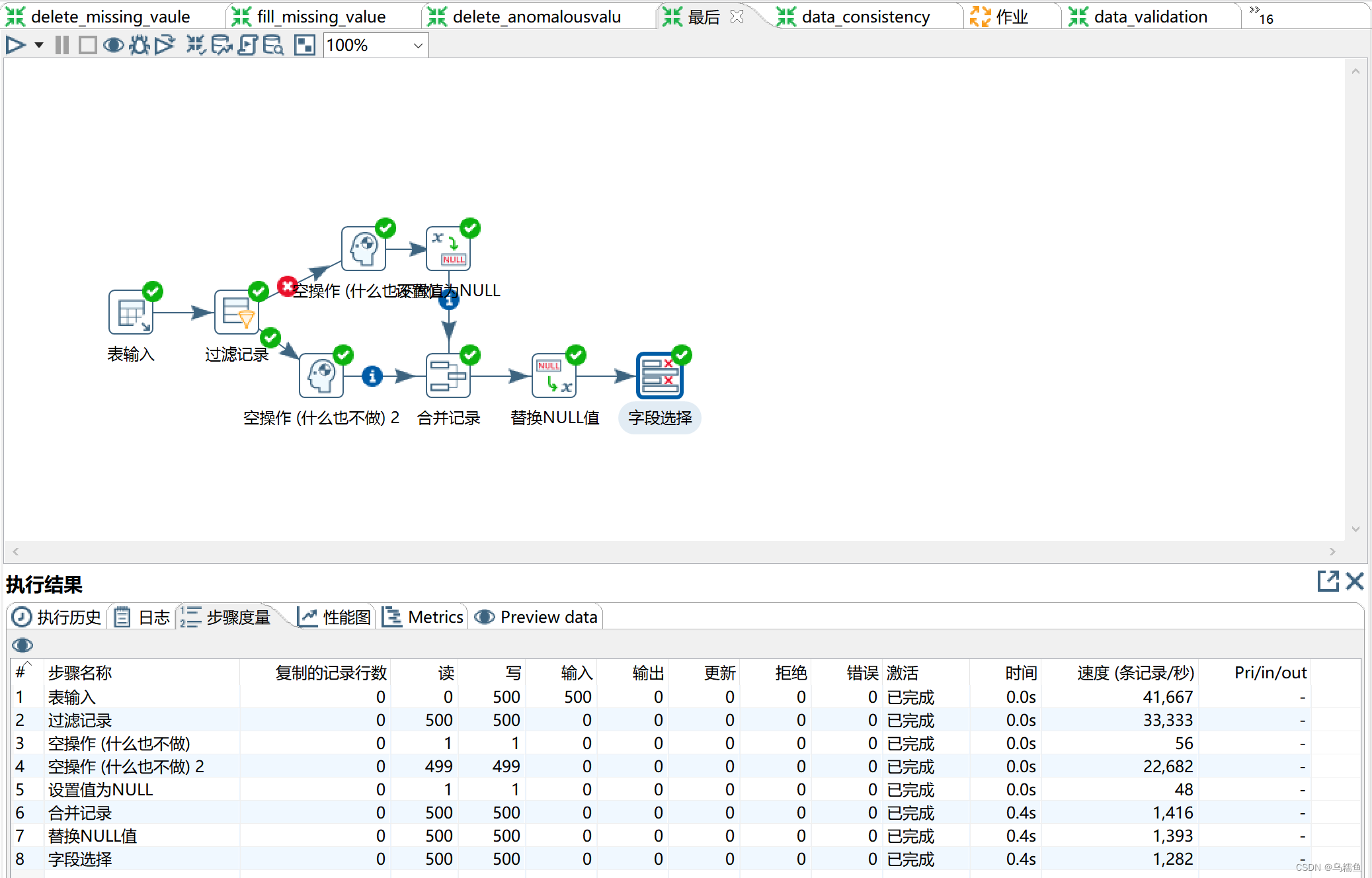
11. 单击“字段选择”控件,再单击执行结果窗口的“Preview data”选项卡,查看是否修改并替换数据表interpolation_data中的异常值。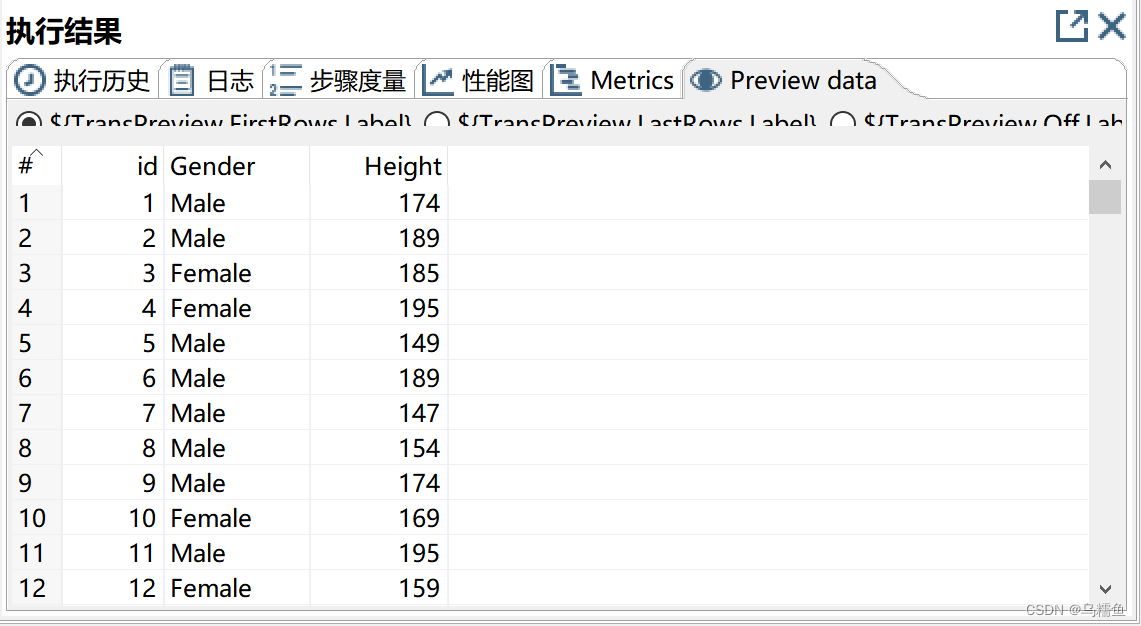
5.4 数据检验
(1)数据一致性处理
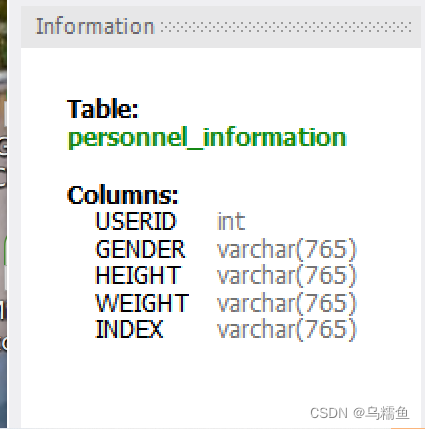
1.现在数据库中有一张名为Personnel_Information的数据表,该表中主要记录了500名职员的性别、身高、体重及健康值。
2.使用Kettle工具,创建一个转换data _consistency,并添加“表输入”控件、“值映射”控件、“插入/更新”控件以及Hop跳连接线。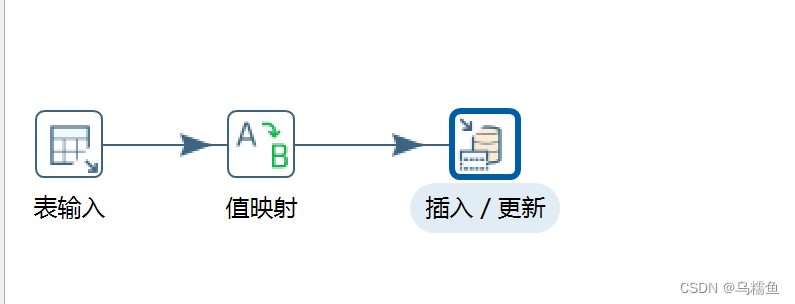
3. 双击“表输入”控件,进入“表输入”配置界面;单击【新建】按钮,配置数据库连接,配置完成后单击【确认】按钮。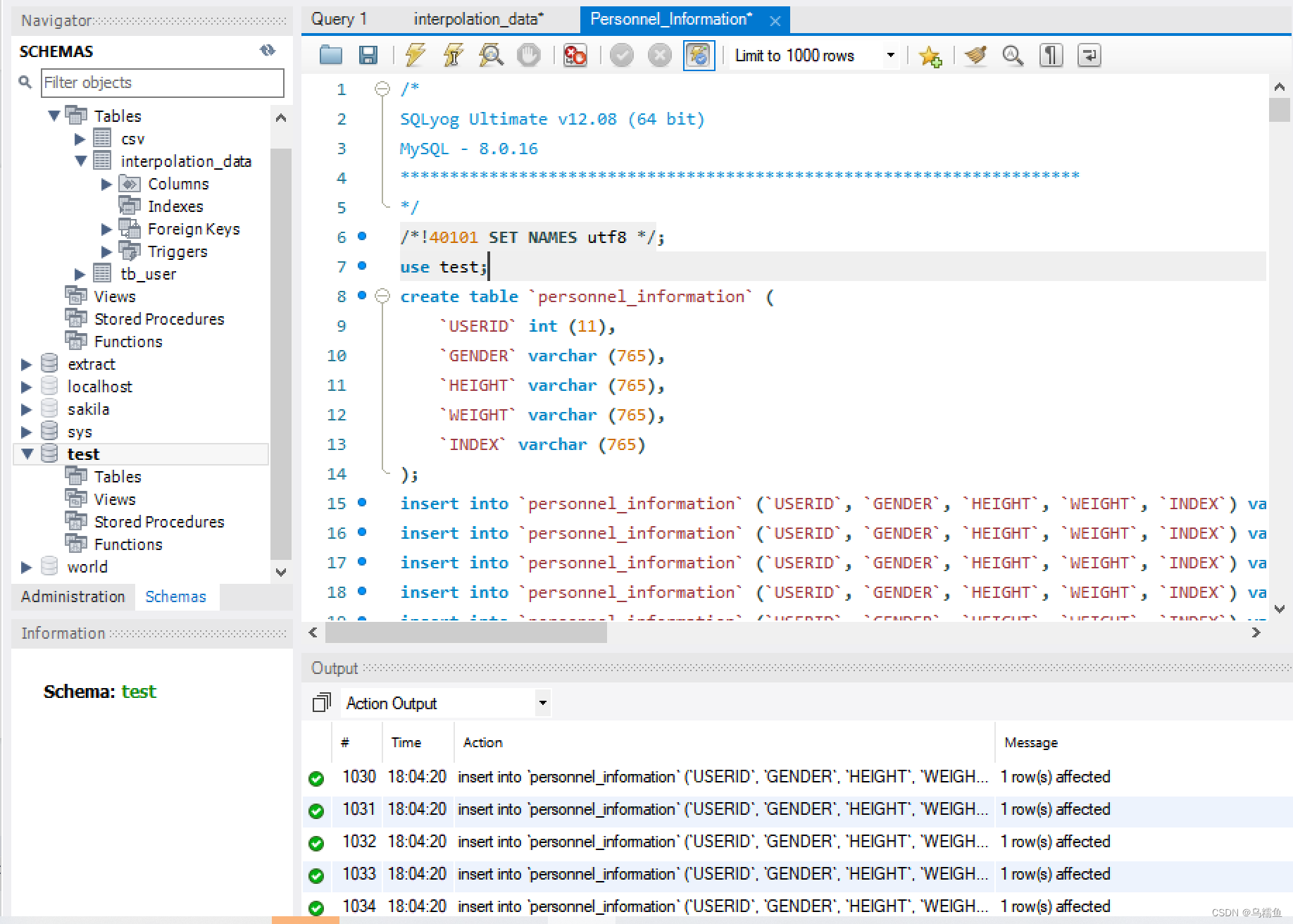
 在SQL框中编写查询数据表interpolation_data的SQL语句,然后单击【预览】按钮,查看数据表Personnel_Information的数据是否成功从MySQL数据库中抽取到表输入流中。
在SQL框中编写查询数据表interpolation_data的SQL语句,然后单击【预览】按钮,查看数据表Personnel_Information的数据是否成功从MySQL数据库中抽取到表输入流中。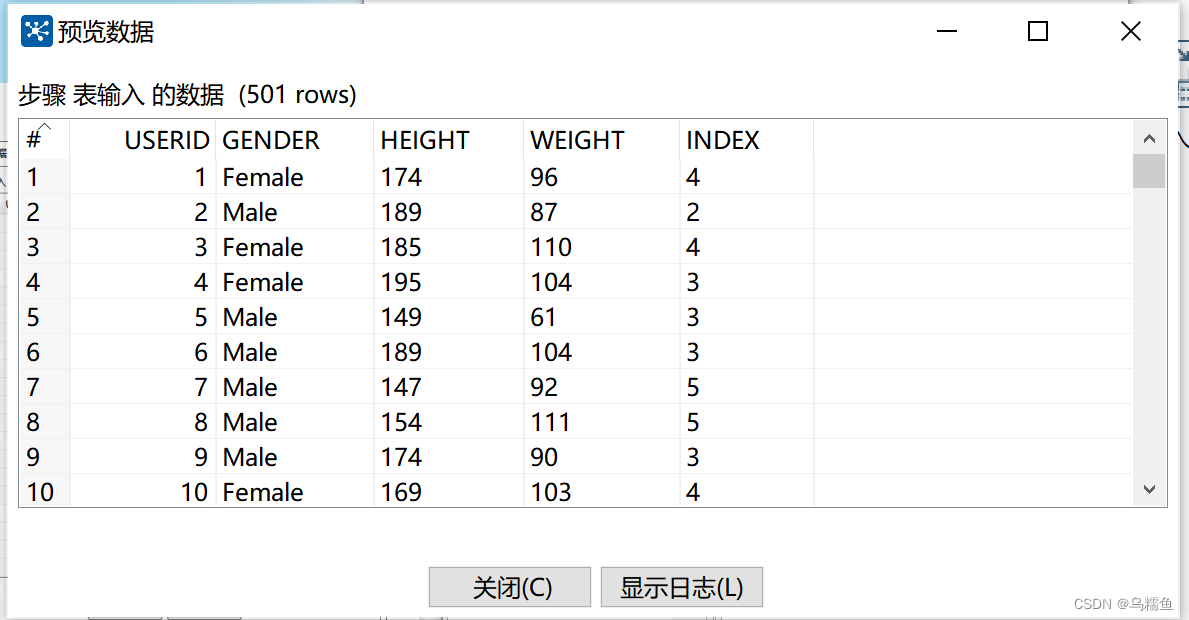
4. 双击“值映射”控件,进入“值映射”配置界面;在“使用的字段名”处的下拉框选择字段GENDER;在“字段值”框中,添加源值和目标值,这里是将Male替换成数字0,将Female替换成数字1。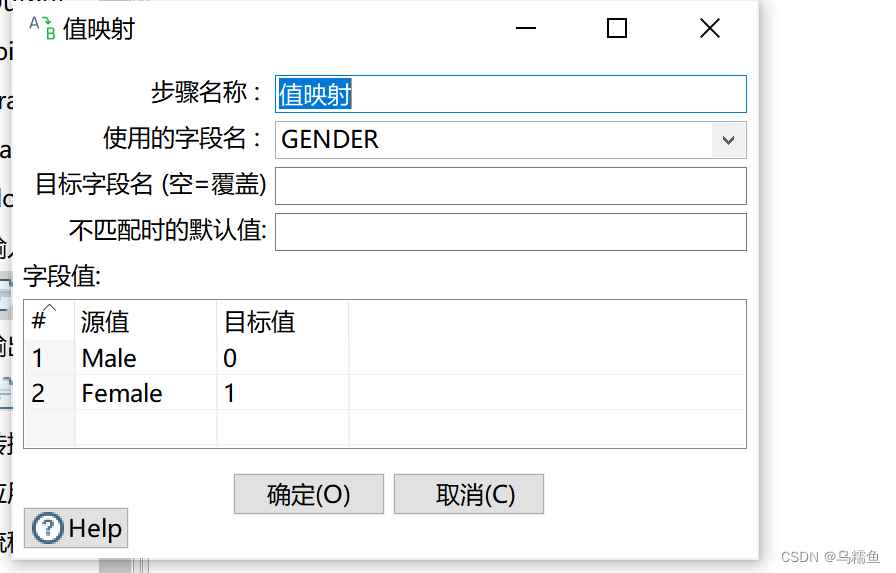
5. 双击“插入/更新”控件,进入“插入/更新”界面;单击【新建】按钮,配置数据库连接,配置完成后单击【确认】按钮。单击目标表右侧的【浏览】按钮,选择目标表Personnel_ Information_New。单击【获取字段】按钮,用来指定查询数据所需要的关键字,这里选择的是Personnel_ Information_New数据表中的USERID字段和输入流里面的USERID字段;单击【获取和更新字段】按钮,用来指定需要更新的字段。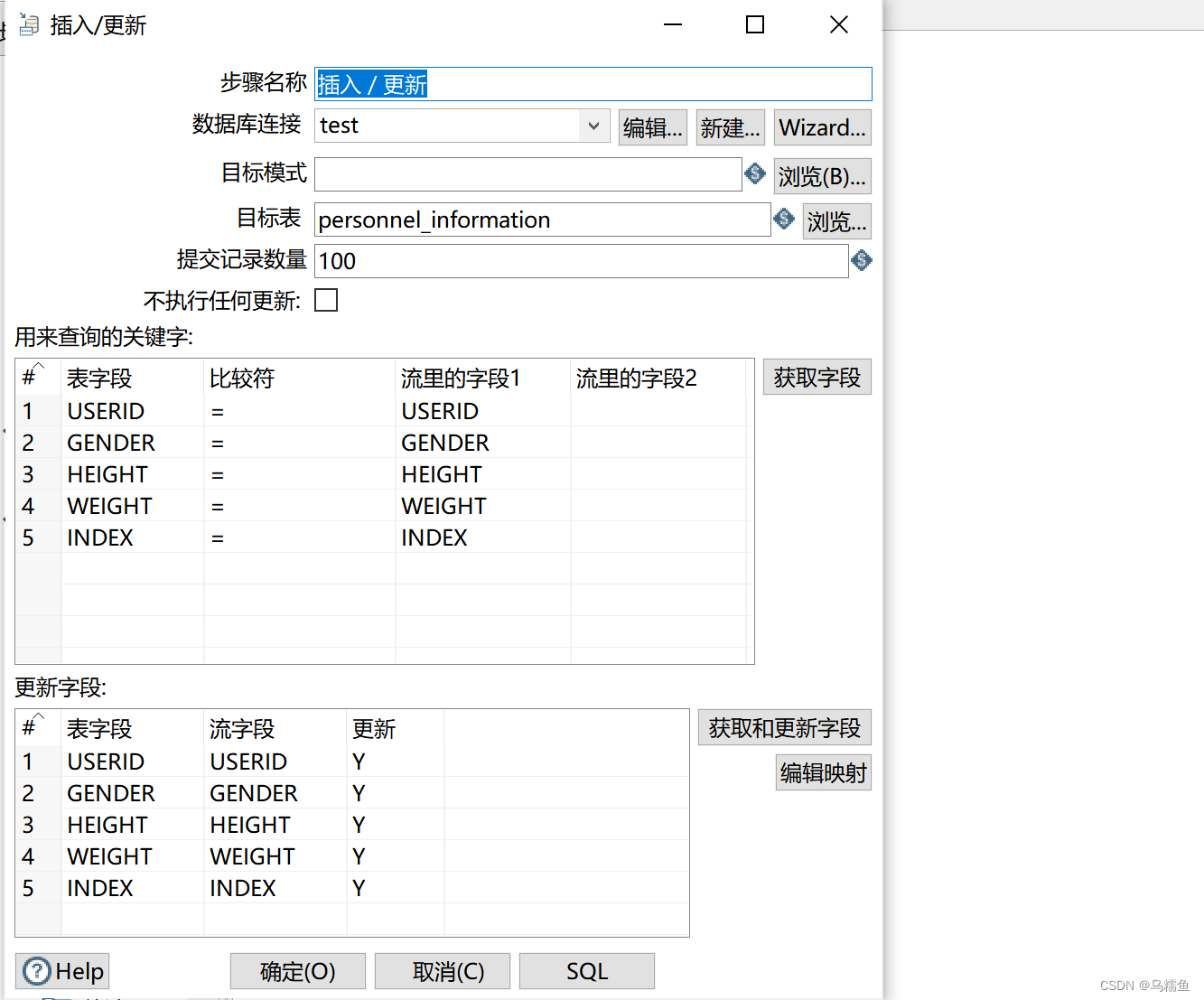
6.运行转换data _consistency。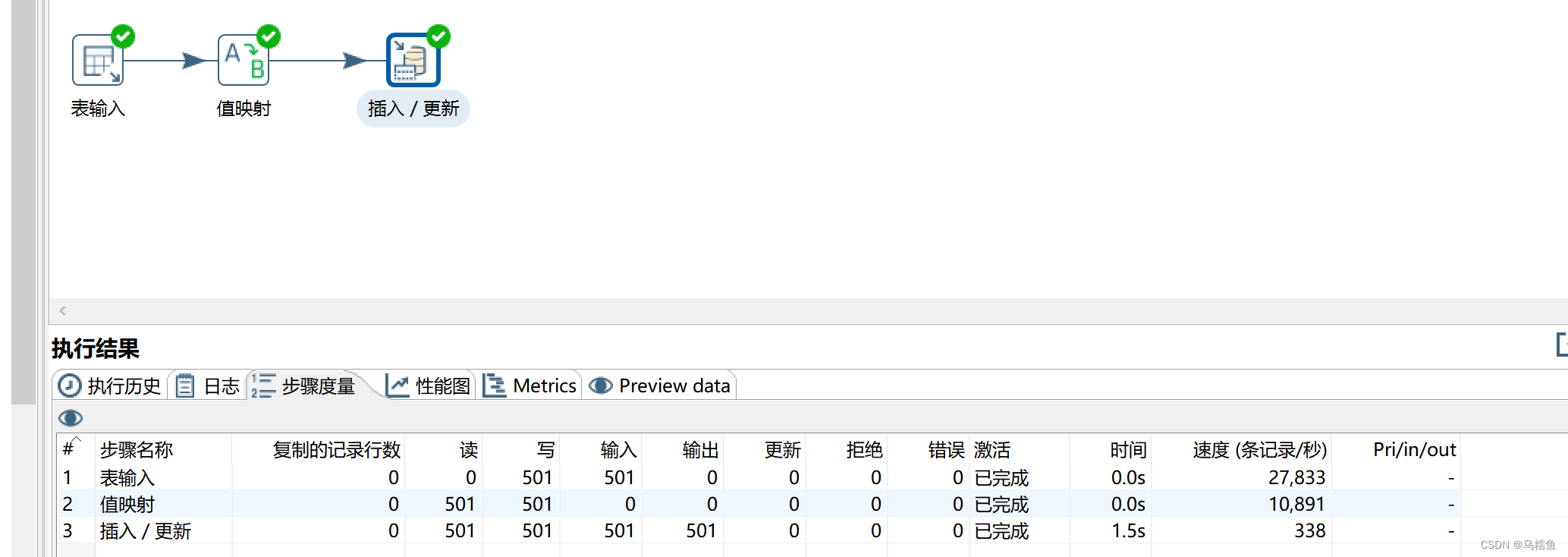
7.通过workbench工具,查看数据表Personnel_ Information_New是否已成功插入501条数据,查看结果如图所示。
8.通过使用Kettle工具,创建一个作业data _consistency_job,并添加“Start”控件、“转换”控件以及作业跳连接线。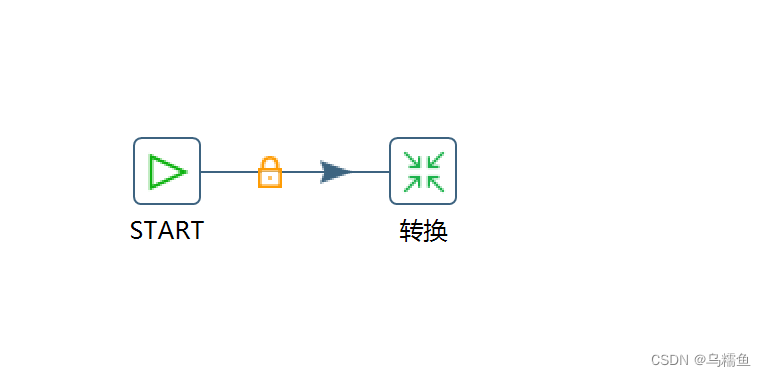
9.双击“Start”控件,进入“作业定时调度”界面;勾选“重复”处的复选框;单击“类型”处的下拉框,选择“时间间隔”定时,并设置以秒计算的间隔是5,以分钟计算的间隔是0。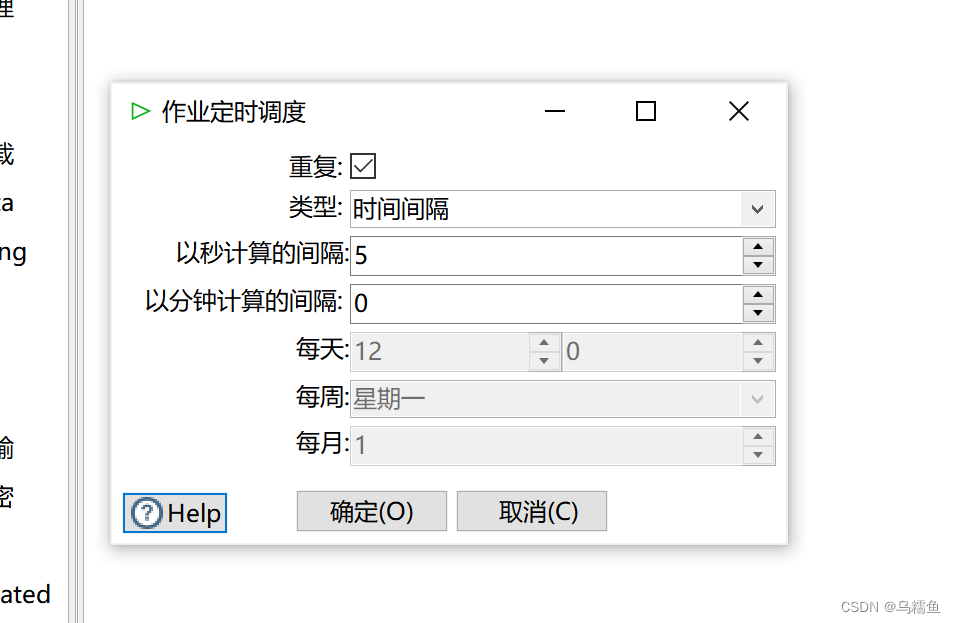
10. 双击“转换”控件,进入“转换”界面;单击【浏览】按钮,选择添加转换data _consistency至作业中。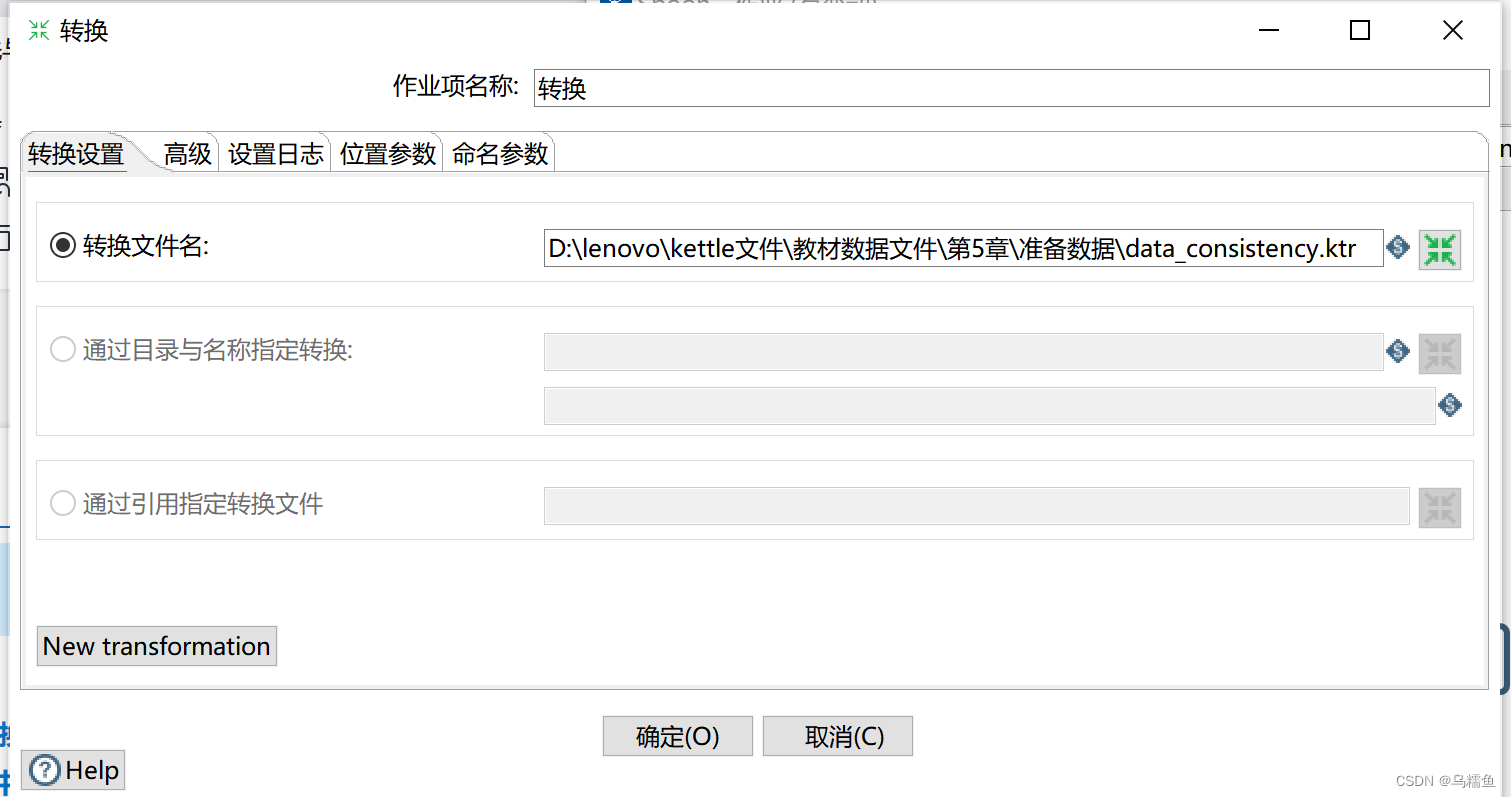
11.运行作业data _consistency_job。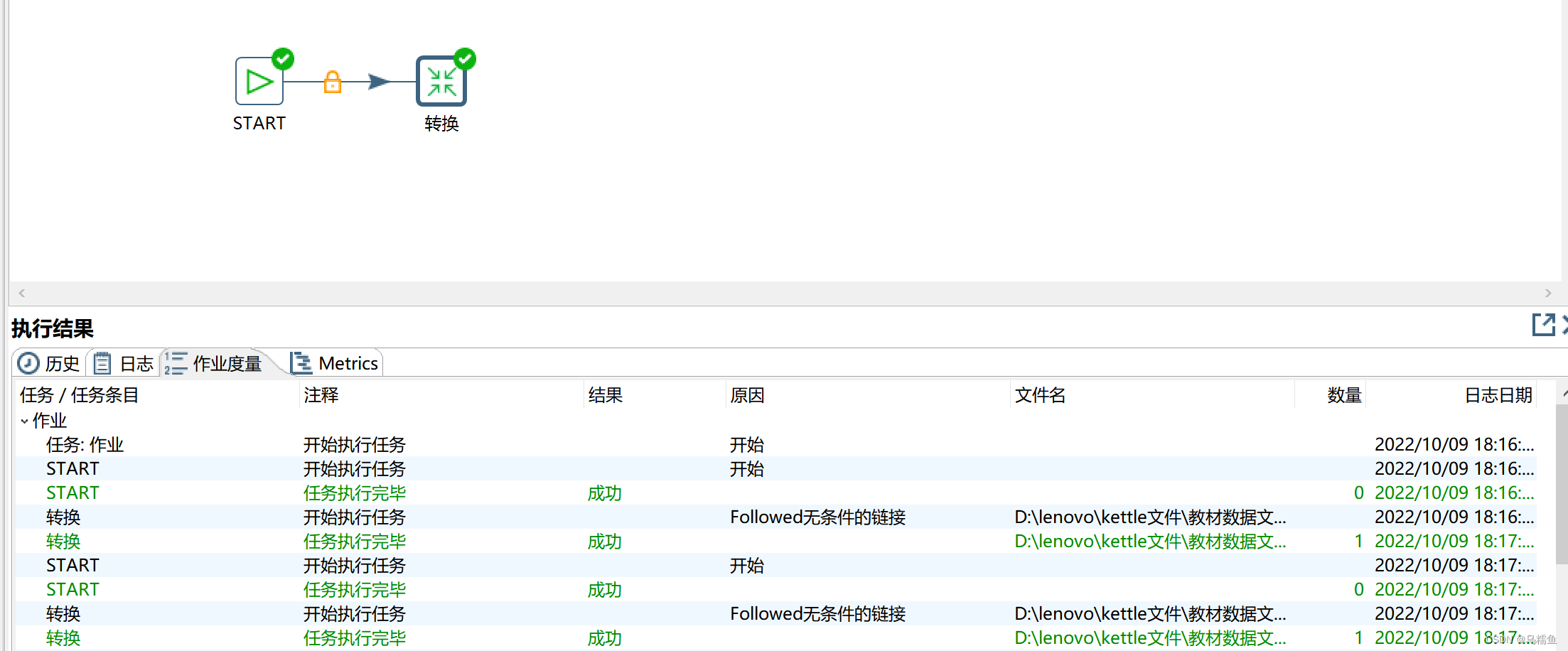
12.从控制台的日志输出可以看出,作业每隔5秒会执行一次转换实现数据同步并且在执行过程中会记录处理的数据量以及当前时间段处理的数据条数。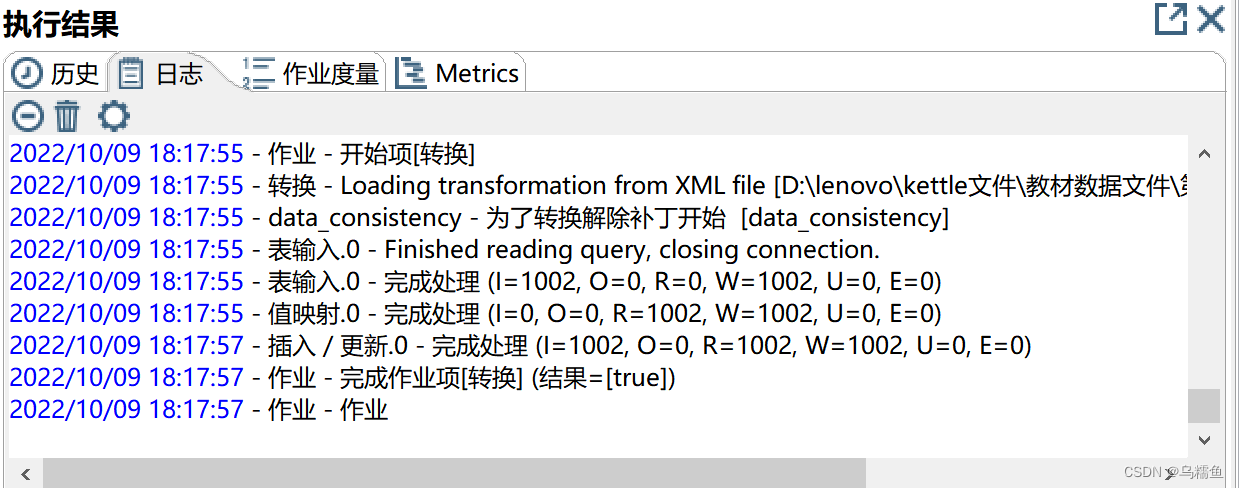
(2)数据规范化处理
1.使用Kettle工具,创建一个转换data_validation,并添加“自定义常量数据”控件、“计算器”控件、“数据检验”控件、“空操作”控件以及Hop跳连接线。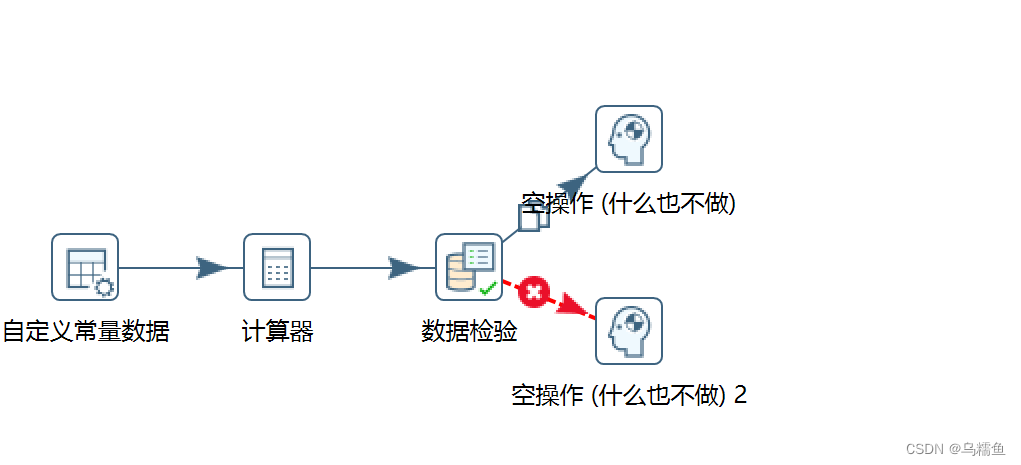
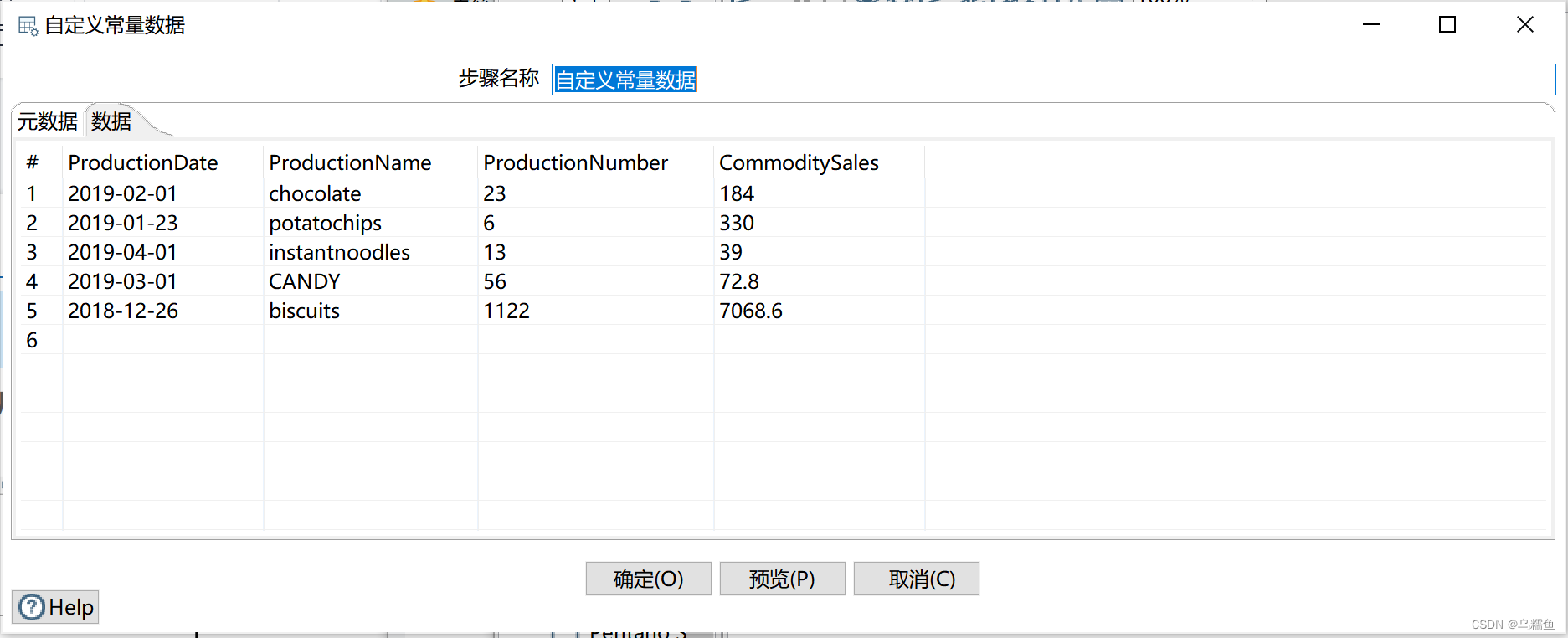
2.双击“自定义常量数据”控件,进入“自定义常量数据”界面配置实验用数据;单击“元数据”选项卡,添加字段常量ProductionDate、ProductionName、ProductionNumber以及CommoditySales并指定其数据类型;单击“数据”选项卡,添加自定义的数据。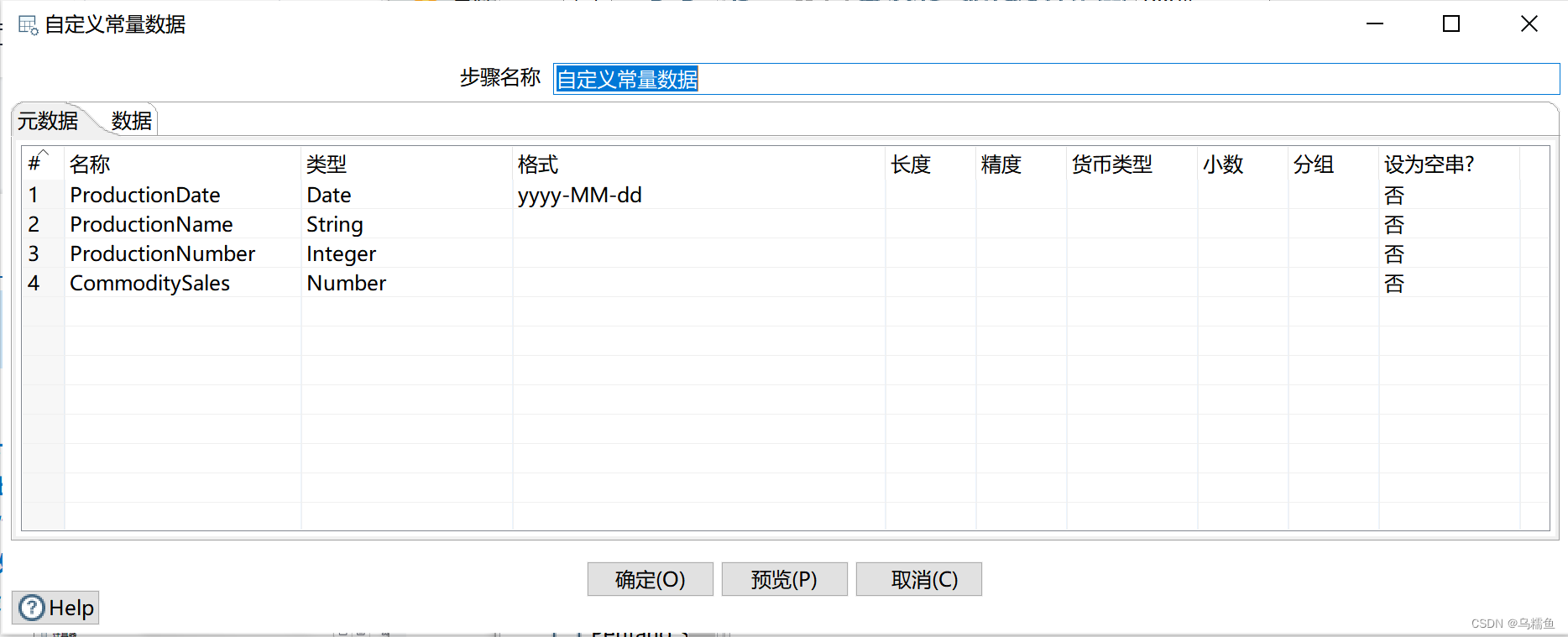
3. 双击“计算器”控件,进入“计算器”界面;在“字段”处,添加一个新字段UnitPrice,用于存储计算出的产品单价数据;在“字段A”和“字段B”处的下拉选项中分别选择“CommoditySales”(销售额)和“ProductionNumber”(销售数量)字段;在“计算”处的下拉框中选择“A/B”,即表示将字段A与字段B进行相除计算。 4.双击“数据检验”控件,进入“数据检验”界面;单击【增加检验】按钮,增加检验条件,这里我们制定的检验条件有三个,即日期(ProductionDate)不能在2019年1月1日之前、产品名称(ProductionNumber)必须都是小写以及单个产品价格(UnitPrice)不能超过10这三个检验条件;单击【增加检验】按钮,弹出“输入检验的名称”窗口,在该窗口中添加检验名称date_verify用于校验如期,添加后单击【确定】按钮关闭“输入检验的名称”窗口。
4.双击“数据检验”控件,进入“数据检验”界面;单击【增加检验】按钮,增加检验条件,这里我们制定的检验条件有三个,即日期(ProductionDate)不能在2019年1月1日之前、产品名称(ProductionNumber)必须都是小写以及单个产品价格(UnitPrice)不能超过10这三个检验条件;单击【增加检验】按钮,弹出“输入检验的名称”窗口,在该窗口中添加检验名称date_verify用于校验如期,添加后单击【确定】按钮关闭“输入检验的名称”窗口。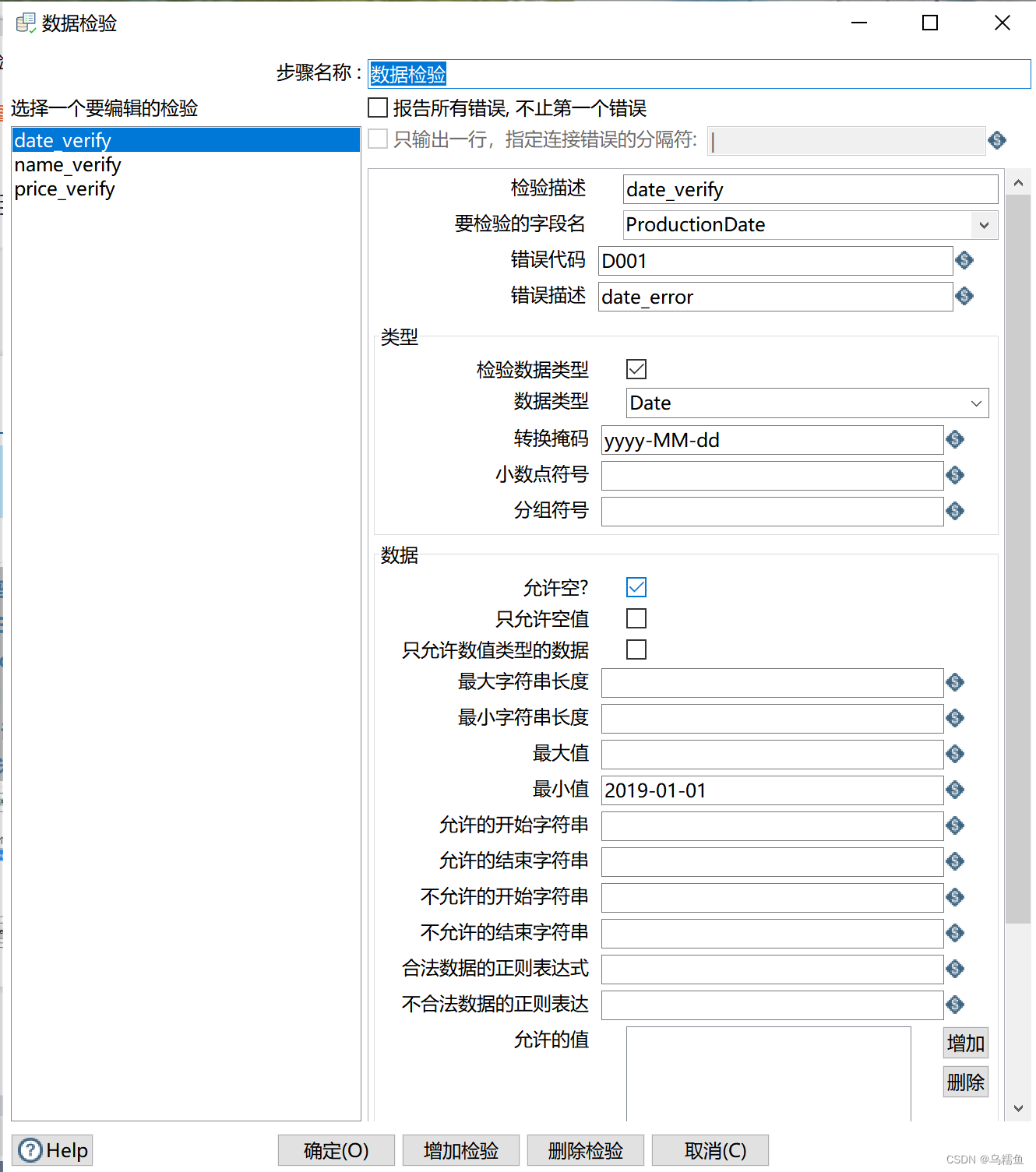
在“要检验的字段名”处,添加要检验的字段;在“错误代码”和“错误描述”处自定义检验到错误数据时日志的输出内容;勾选“检验数据类型”处的复选框;在“数据类型”处指定数据类型;在“转换掩码”处输入与指定检验字段相同的日期格式;在“最小值”处添加检验条件。单击【增加检验】按钮,弹出“输入检验的名称”窗口,在该窗口中添加检验名称name_verify用于校验商品名称,添加后单击【确定】按钮关闭“输入检验的名称”窗口。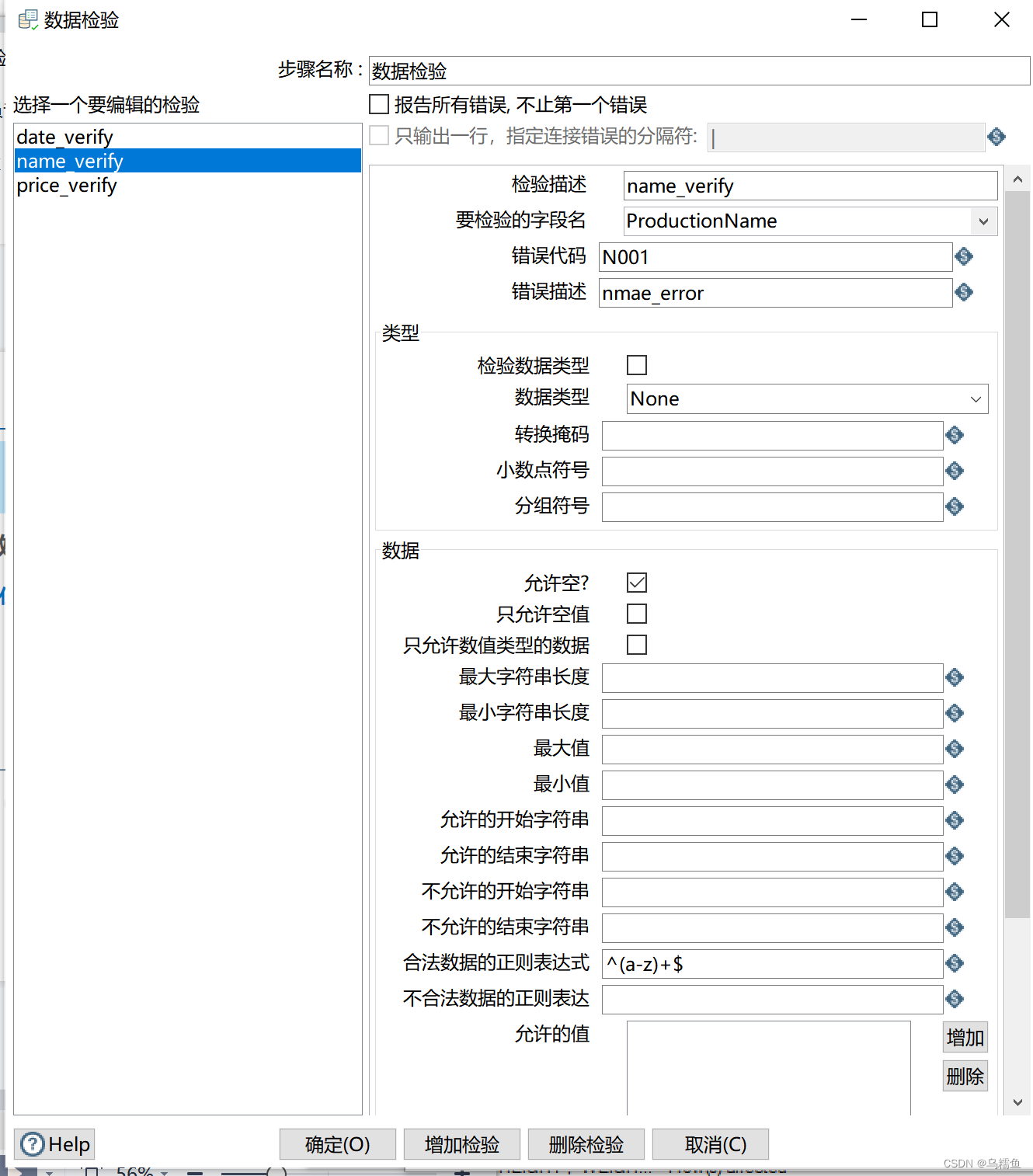
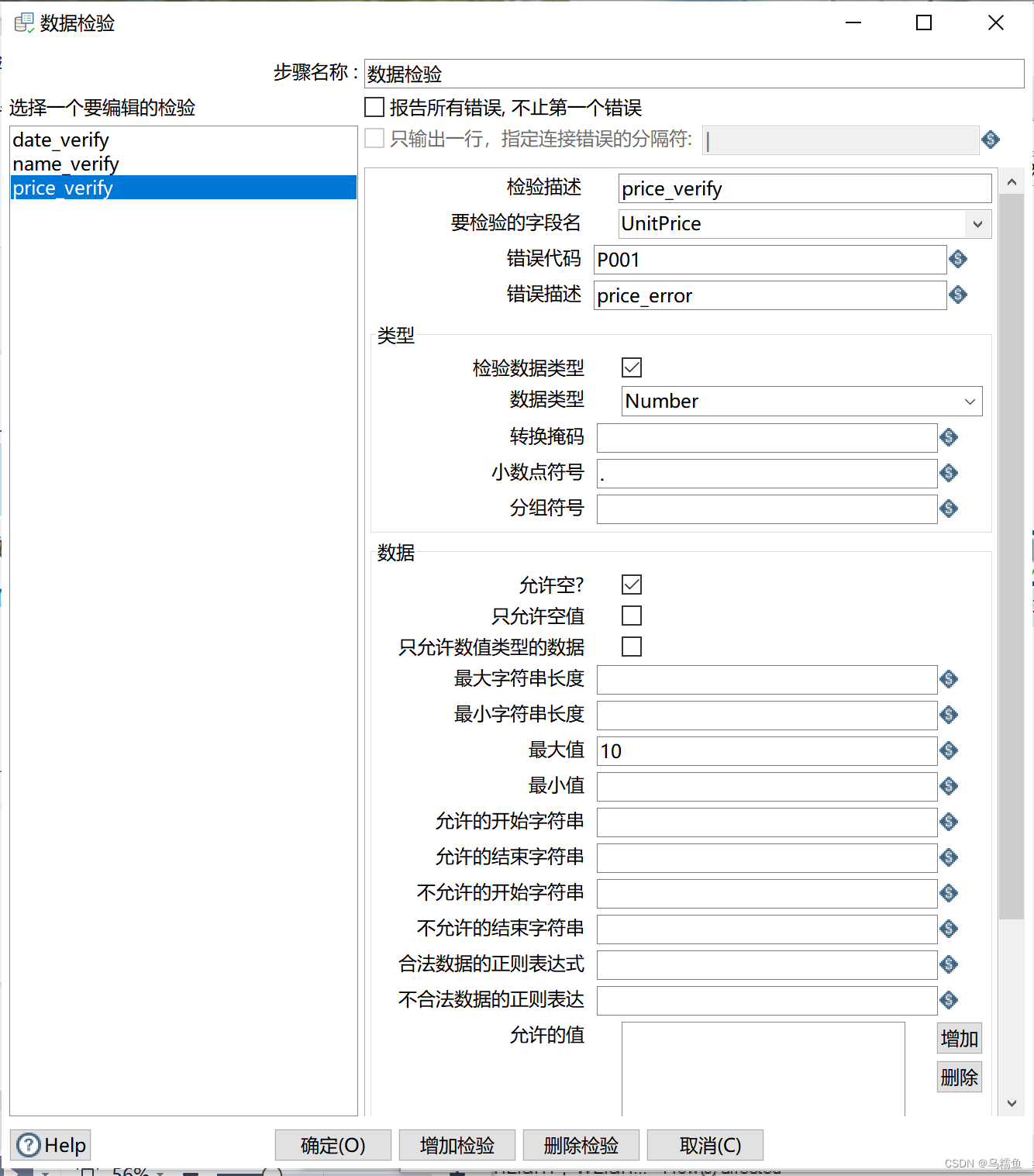 5. 单击选中“数据检验”控件,然后按住Shift键,通过分发方式设置“主输出步骤”连接到“空操作(什么也不做)”控件;设置“错误处理步骤”连接到“空操作(什么也不做)2”控件。
5. 单击选中“数据检验”控件,然后按住Shift键,通过分发方式设置“主输出步骤”连接到“空操作(什么也不做)”控件;设置“错误处理步骤”连接到“空操作(什么也不做)2”控件。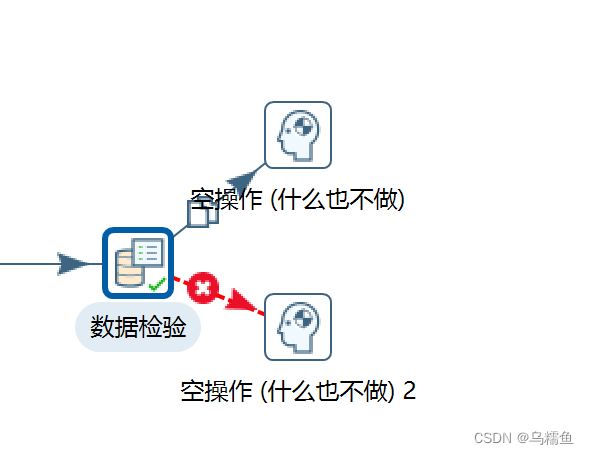
6.运行转换data_validation。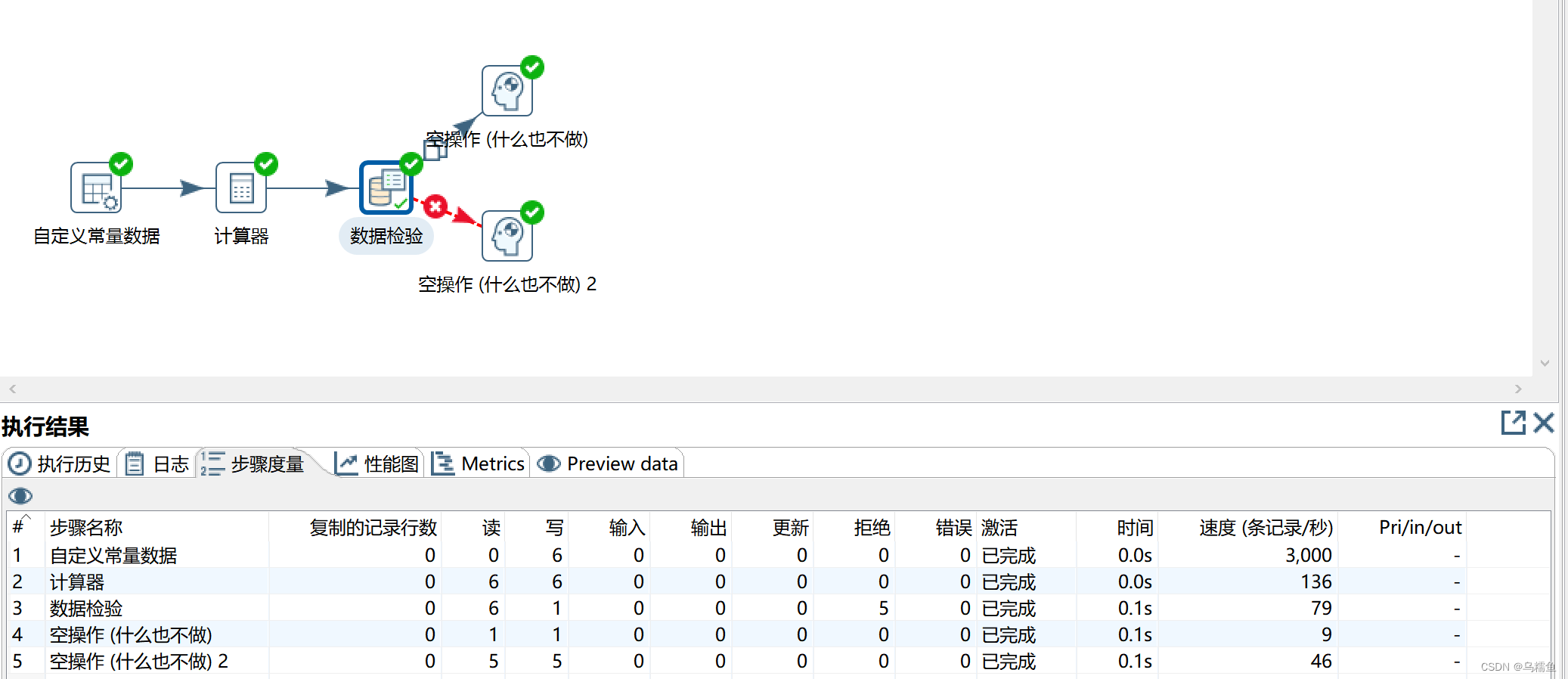
7.选中“空操作(什么也不做)2”控件,单击执行结果窗口的“Preview data”选项卡,查看是否将不符合校验规则的数据检验出来。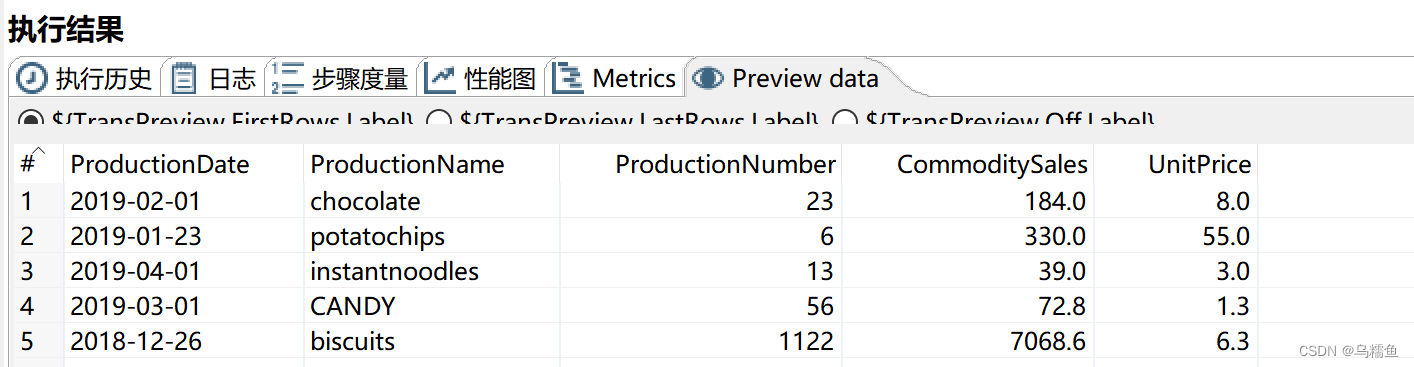

















 458
458

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









