







大家好,今天来介绍一下细致的概念部分。
Softmax是一种数学函数,通常用于将一组任意实数转换为表示概率分布的实数。比如说,一组实数24.5,164,0.18我们就可以把他们转化成0.13,0.87和0.
交叉熵(Cross Entropy)主要用于度量两个概率分布间的差异性信息。 H(p, q) = -Σ(p(x) * log(q(x)))
交叉熵损失函数(Cross Entropy Loss)是机器学习中常用的损失函数,它能够用来衡量两个分布之间的距离。交叉熵损失函数的意义是,它能够帮助机器学习模型从训练样本中估计出最接近目标分布的预测概率密度函数。
经验风险(Empirical Risk): 经验风险是指模型在训练数据上的平均损失或误差。
正则化作用 正则化技术广泛应用在机器学习和深度学习算法中,其本质作用是防止过拟合、提高模型泛化能力。
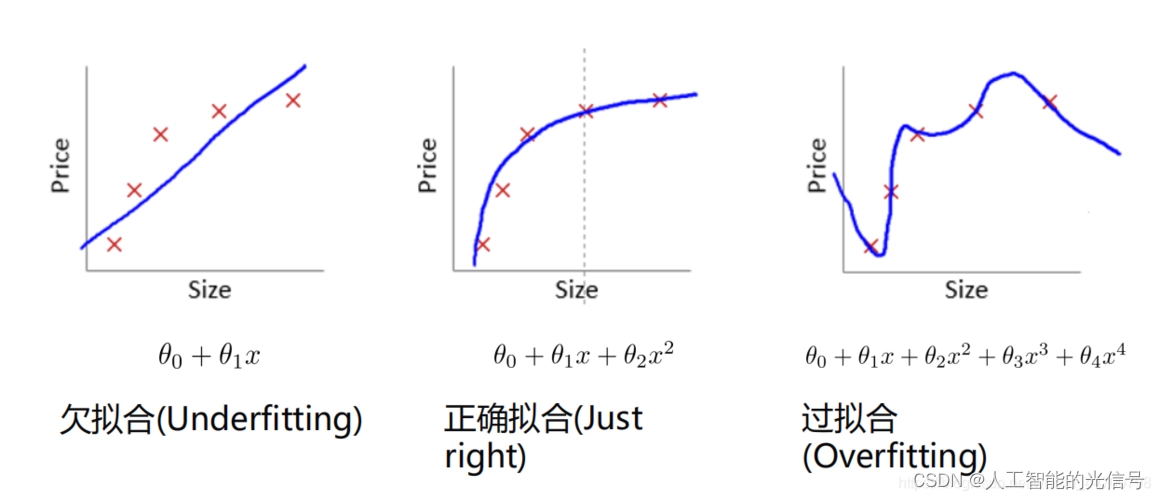
拟合是一个数理科学术语,形象的说,拟合就是把平面上一系列的点,用一条光滑的曲线连接起来。因为这条曲线有无数种可能,从而有各种拟合方法。
过拟合是指学习时选择的模型所包含的参数过多,以至于出现这一模型对已知的数据预测的很好,但对未知数据预测得很差的现象。如果过拟合怎么办?这时候我们就要提到一个概念——权重衰减。权重衰减(Weight Decay)作用是抑制模型的过拟合,以此来提高模型的泛化性。
欠拟合模型描述能力太弱,以至于不能很好地学习到数据中的规律。
过拟合和欠拟合之间就是一个模型的承载力。
过拟合和欠拟合都是我们不希望得到的。















 350
350











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









