







 本文介绍如何利用Python的Scrapy框架爬取起点小说网站上的信息,并详细讲解了爬取过程及数据存储到数据库的方法,为后续的数据分析和处理打下基础。
本文介绍如何利用Python的Scrapy框架爬取起点小说网站上的信息,并详细讲解了爬取过程及数据存储到数据库的方法,为后续的数据分析和处理打下基础。
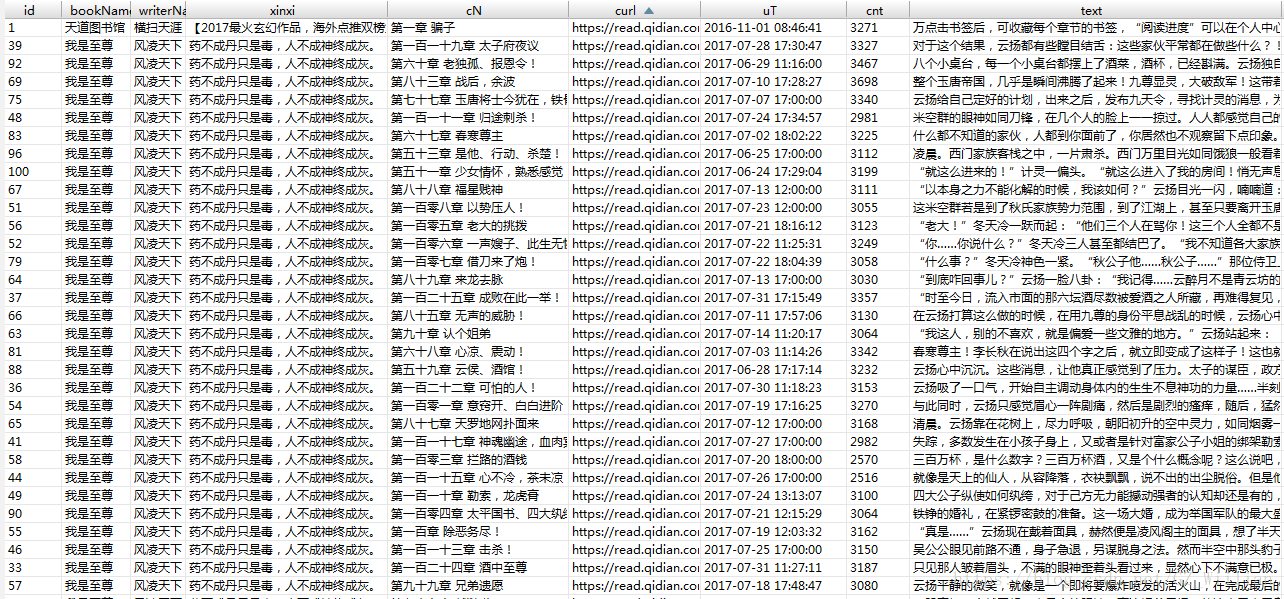
最终效果如下:
······················主程序:·······································
# -*- coding: utf-8 -*-
import scrapy
import requests
import json
from qidian.items import QidianItem
class MyqidianSpider(scrapy.Spider):
name = 'myqidian'
allowed_domains = ['qidian.com']
start_urls = ['http://www.qidian.com/all?chanId=21&orderId=&page=1&style=1&pageSize=20&siteid=1&pubflag=0&hiddenField=0']
def parse(self, response):
# print(response.text)
bookList = response.xpath('//ul[@class="all-img-list cf"]/li')
for i in bookList:
bookId = i.xpath('./div[@class="book-img-box"]/a/@data-bid').extract()[0]
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 3538
3538

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









