







嗨,大家好,我是心海!今天我们来实现一个程序,可以爬取“起点小说”vip内容,但是要先说明一点,我们这篇是入门教程,而起点的反爬机制非常强大,所以我们并不是直接去其官网爬取,而是通过一些别人已经构建好的网站,来爬取内容
这样做的优点,是这些网站反爬机制会比较弱,甚至没有反爬,所以可以作为我们入门练习非常好的一个项目,带你快速体验一遍爬虫的便捷性
在这篇文章中,我们将带你一步步实现一个简单的 Python 爬虫,用于爬取网页小说内容。我们会详细讲解核心原理、代码实现细节,并用图示帮助大家理解整个流程。并通过一个案例带你完整爬取一遍
文章仅供练习参考,有能力的朋友还请多多支持正版
目录
(3) 多线程爬取:process_page 与线程池的应用
一、 什么是网络爬虫
还记得小时候,你可能喜欢翻箱倒柜地寻找自己喜欢的玩具或者零食吧?网络爬虫就像一个非常勤劳且聪明的“小机器人”,它按照你给定的“指令”(告诉它想找什么),自动地在互联网这个巨大的“箱子”里,一个网页一个网页地去“翻找”,找到你想要的信息,然后整齐地搬运回来。
你可以把它想象成一只不知疲倦的小蜜蜂,在互联网的花园里穿梭,采集花蜜(网页上的信息)。而我们程序员,就是训练这只小蜜蜂的“饲养员”。
简单而言,爬虫就是让计算机帮你将一大堆网页内容找到你要的,再给提取过来!
二、 为什么我们要学习Python爬虫?(实际应用场景)
你可能会好奇,学会这个“小机器人”有什么用呢?它的用途可广泛啦!
-
数据分析和研究: 比如,抓取商品价格变化、分析用户评论、收集行业数据等等,为决策提供有力支持。
-
信息聚合和整理: 自动抓取多个新闻网站的头条,汇总成你需要的资讯摘要。
-
自动化测试: 模拟用户行为,对网站或应用进行自动化测试。
-
内容采集和整理: 像我们今天要做的——爬取喜欢的小说、漫画等内容,方便离线阅读。
-
搜索引擎的基础: 像Google、百度这样的搜索引擎,也依赖于庞大的爬虫系统来发现和索引网页。
而Python语言,因其简洁易懂的语法和丰富的第三方库,成为了编写网络爬虫的首选语言。
三、准备工作
安装必要的库
在开始之前,我们需要安装几个 Python 库,它们分别是 requests 和 beautifulsoup4。requests 库用于发送 HTTP 请求,获取网页内容;beautifulsoup4 库用于解析 HTML 内容,方便我们提取所需的信息。
你可以使用以下命令来安装这两个库:
pip install requests beautifulsoup4四、实战案例:爬取在线小说
我们以某小说网站为例(注意:下面需要先选择没有反爬的网站,仅用于学习入门,后续会更新更实用,反反爬的方法)。
第一步:分析网页结构
我们在爬取小说内容时,很重要的一点就是找出完整URL的规律,第二点就是找出我们爬取内容的位置
首先是小说目录,一般小说都会有一个目录,特别是这些小的网站,他们的URL本身可能不太规律,那么我们就需要把目录先爬下来,然后根据目录去爬取内容
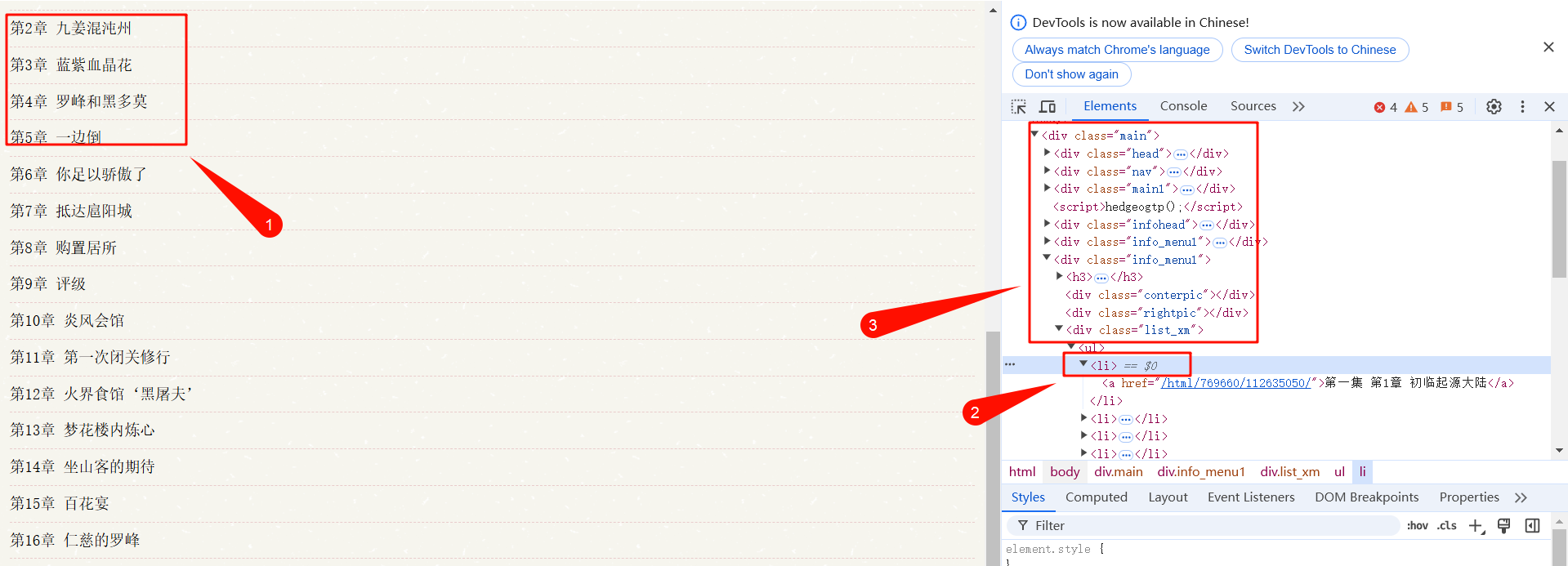
打开小说目录,我们可以通过开发者工具(F12)查看内容被包裹在什么标签内。
然后我们通过标签可以定位到这些地址“href”和小说名称,可以提取出来
我们再看正文
我们发现正文内容通常在一个 <div id="novelcontent"> 内,这就是我们提取文本的关键目标。
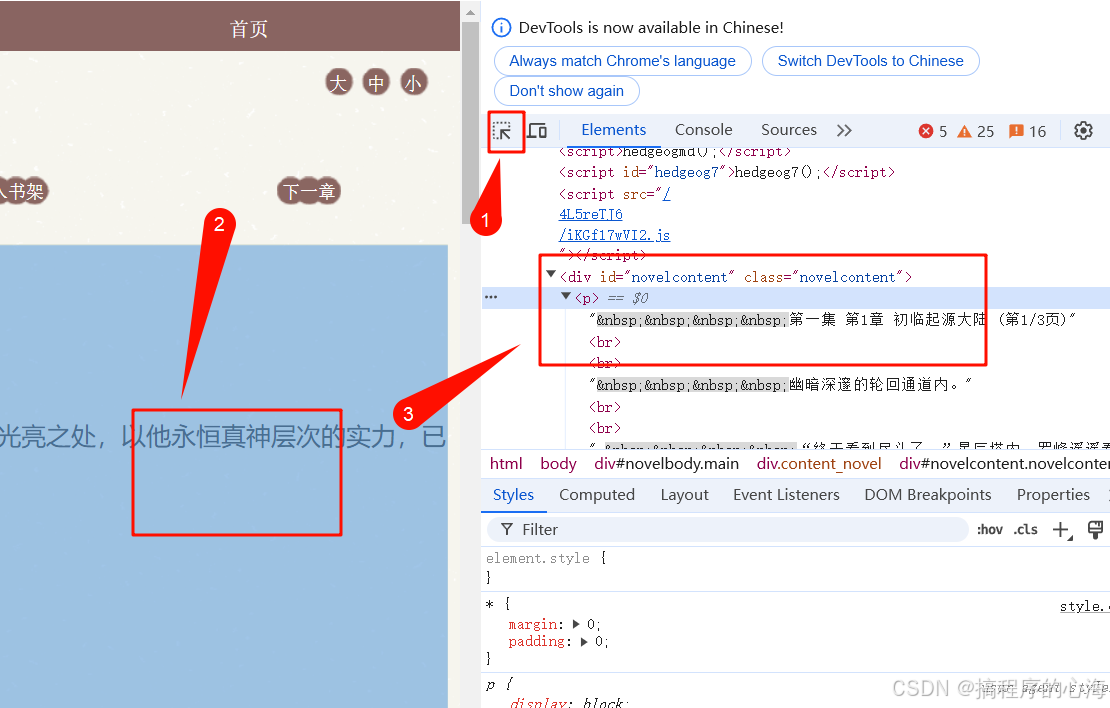
像我们现在这个页面这种结构就特别简单,对应id下的第一个p标签就是我们的目标文本,我们将他们全部爬出来,然后按照URL的规律进行遍历循环,就可以完成一个简单的爬虫。
<div id="novelcontent">
<p>小说正文在这里...</p>
</div>
通过上面的分析,我们可以确定流程
爬取目录→保存URL及标题→根据URL爬取每一页的文本→合并导出
第二步:爬取目录并保存
首先我们要爬取的目录是这个列表中的所有项

那么如何定位?
我们这里为更可靠地定位到目标内容,可先通过
find_all获取所有class="info_menu1"的div(有两个且我们要的在第二个),所以我们再取第二个并查找内部的list_xm。
然后我们提取里面的 ul 下 li 下 a 标签下的内容,最后保存到一个csv文件
import requests
from bs4 import BeautifulSoup
import csv
base_url = "http://m.kk169.org/html/769660/asc-" # 替换为实际基础URL
with open('output.csv', 'w', newline='', encoding='utf-8') as csvfile:
writer = csv.writer(csvfile)
writer.writerow(['href', 'text'])
for page in range(1, 19):
current_url = base_url + str(page)
response = requests.get(current_url)
if response.status_code == 200:
soup = BeautifulSoup(response.text, 'html.parser')
info_menu1_divs = soup.find_all('div', class_='info_menu1')
if len(info_menu1_divs) >= 2:
second_info_menu1 = info_menu1_divs[1]
list_xm_div = second_info_menu1.find('div', class_='list_xm')
if list_xm_div:
a_tags = list_xm_div.select('ul li a')
for a in a_tags:
href = a.get('href')
text = a.get_text(strip=True)
writer.writerow([href, text])
else:
print(f"页面 {page} 中未找到 list_xm 的 div")
else:
print(f"页面 {page} 中未找到足够的 info_menu1 的 div")
else:
print(f"请求页面 {page} 失败,状态码:{response.status_code}")什么,你说你看不懂前端代码?不知道怎么定位?没关系,现在 AI 工具已经足够聪明,只要你描述清楚需求,它就可以给你正确编写出代码
所以说,现在编程的门槛越来越低,即使是小白也可以轻松完成爬虫程序
最后我们爬下来的数据形如
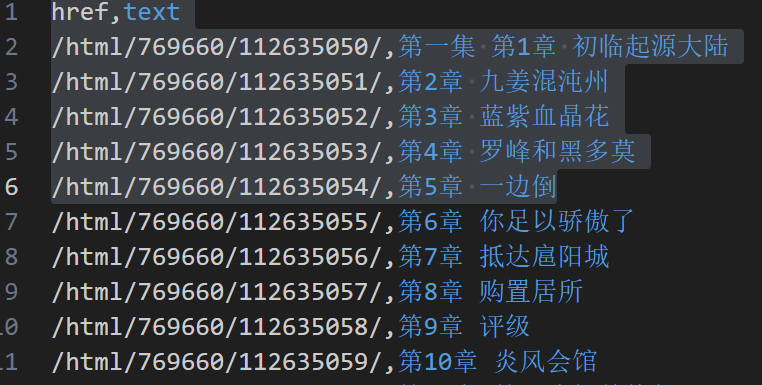
第三步 批量爬取正文内容
接下来进入正文部分, 我们再一次明确需求

正文的结构甚至比目录更加简单,只要我们通过 id 定位,再将第一个 p 标签内容全部提取出来即可
看起来很简单,那么我们就只需要优化好细节即可
(1)导入库与初始化全局变量
首先,我们导入所需库,设置 CSV 文件的读取以及初始化一些全局变量:
import requests
from bs4 import BeautifulSoup
import time
import re
import random
from concurrent.futures import ThreadPoolExecutor
from queue import Queue
import csv
# 从 CSV 文件中读取章节编号与标题映射
chapter_titles = {}
with open('output.csv', 'r', encoding='utf-8') as csvfile:
reader = csv.DictReader(csvfile)
for row in reader:
# 利用正则表达式提取章节ID(例如:/112635050/... 中的112635050)
chapter_id = re.search(r'/(\d+)/(\d+)/', row['href']).group(2)
chapter_titles[chapter_id] = row['text']
# 保存所有章节内容及错误处理相关变量
all_content = []
consecutive_failures = 0
stop_flag = False
result_queue = Queue()
error_log = []
用
csv.DictReader遍历 CSV 文件中的行,采用正则表达式提取章节编号;此处正则r'/(\d+)/(\d+)/'用于匹配 URL 中的第二个数字块。初始化
result_queue用于存放爬取结果,error_log用于记录连续爬取失败的信息,方便最后排查问题。
(2) 爬取单页面函数:crawl_page
该函数负责获取单个页面的 HTML 内容,并利用 BeautifulSoup 进行解析,同时实现重试机制:
def crawl_page(url, chapter_id, page_num):
global consecutive_failures
max_retries = 5
retries = 0
while retries < max_retries:
try:
response = requests.get(url)
response.raise_for_status()
response.encoding = response.apparent_encoding
soup = BeautifulSoup(response.text, 'html.parser')
novel_content = soup.find('div', id='novelcontent')
if novel_content:
text = novel_content.get_text(strip=False)
# 清理文本:过滤掉包含“第...章”的标题行,及其他无用提示信息
text = re.sub(r'第\d+章.*?\n', '', text, flags=re.DOTALL)
text = re.sub(r'(本章未完,请点击下一页继续阅读)', '', text)
text = re.sub(r'上一章\s*返回目录\s*加入书签\s*下一章', '', text)
consecutive_failures = 0
return (chapter_id, page_num, text.strip())
except Exception as e:
print(f"爬取 {url} 失败,第 {retries + 1} 次尝试: {e}")
retries += 1
time.sleep(1 + random.random())
consecutive_failures += 1
error_log.append(f"连续 {max_retries} 次尝试爬取 {url} 失败: {e}")
return None
函数通过
try...except结构捕获请求异常,最多重试 5 次,保证网络不稳定时程序的健壮性。页面解析后提取 id 为
novelcontent的<div>,之后利用正则表达式去除部分冗余文本,如章节标题重复、提示信息等。成功获取文本后返回包含章节号、页码与文本内容的元组,否则记录错误并返回
None。
(3) 多线程爬取:process_page 与线程池的应用
为了提高爬取效率,我们采用多线程并发,通过 ThreadPoolExecutor 对每个章节的多个分页同时发起请求。
def process_page(chapter_id, page_num):
global stop_flag
if stop_flag:
return
base_url = 'http://m.kk169.org/html/769660/'
url = f"{base_url}{chapter_id}_{page_num}"
start_time = time.time()
result = crawl_page(url, chapter_id, page_num)
if not stop_flag and result:
result_queue.put(result)
time.sleep(1 + random.random())
end_time = time.time()
print(f"{chapter_id} 完成章节{chapter_titles[chapter_id]} \t\t分页{page_num},用时{end_time-start_time:.2f}秒")
if consecutive_failures >= 20:
stop_flag = True
print("连续20次失败,停止爬取")
save_progress()
每个线程调用
process_page请求对应分页的小说页面,并记录请求耗时。成功爬取后将结果放入共享的
result_queue中。如果连续失败次数达到阈值(20 次),则设置停止标志并及时保存已获取的内容,保障数据不丢失。
(4) 数据整合及保存函数:save_progress
所有线程结束后(或在异常情况下触发),统一对结果数据进行整合,生成最终小说内容文本,并写入文件:
def save_progress():
global all_content
chapter_data = {}
while not result_queue.empty():
chapter_id, page_num, content = result_queue.get()
if chapter_id not in chapter_data:
chapter_data[chapter_id] = [''] * 3
chapter_data[chapter_id][page_num - 1] = content
sorted_chapters = sorted(chapter_data.keys(), key=lambda x: int(x))
for chapter_id in sorted_chapters:
if chapter_id in chapter_data:
pages = chapter_data[chapter_id]
merged_content = '\n'.join([p for p in pages if p])
if merged_content:
title = chapter_titles[chapter_id]
chapter_content = f"\n\n{title}\n\n{merged_content}"
all_content.append(chapter_content)
# 将完整小说内容写入文件
with open('novel_content200.txt', 'w', encoding='utf-8') as f:
f.write('\n'.join(all_content))
# 写入错误日志文件
with open('error_log.txt', 'w', encoding='utf-8') as f:
f.write('\n'.join(error_log))
从队列中读取所有页面的内容后,按照章节编号对内容进行排序并合并各分页内容。
最后分别将小说内容和错误日志写入文件,便于后续查看及调试。
(5) 程序主入口
最后,程序统一启动线程池,并对所有章节分页依次发起请求:
if __name__ == "__main__":
start_time = time.time()
print("开始处理章节...")
# 按章节编号排序,确保爬取顺序
sorted_chapters = sorted(chapter_titles.keys(), key=lambda x: int(x))
with ThreadPoolExecutor(max_workers=5) as executor:
for chapter_id in sorted_chapters:
for page_num in range(1, 4):
executor.submit(process_page, chapter_id, page_num)
# 当爬取正常结束时,保存所有内容
save_progress()
end_time = time.time()
print(f"爬取完成,总用时{end_time - start_time:.2f}秒,处理章节数{len(all_content)}")
利用
with ThreadPoolExecutor(max_workers=5)创建最多 5 个线程执行爬取任务。遍历所有章节和分页,提交任务给线程池,利用多线程提高速度。
爬取结束后统一调用
save_progress保存所有内容。
程序流程
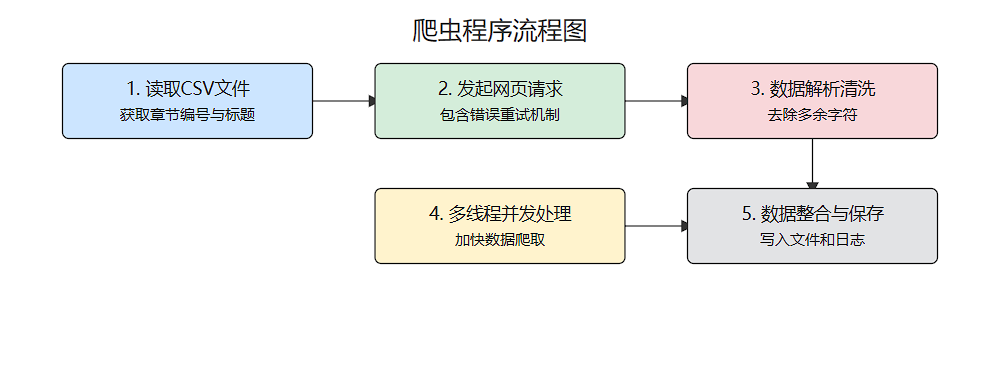
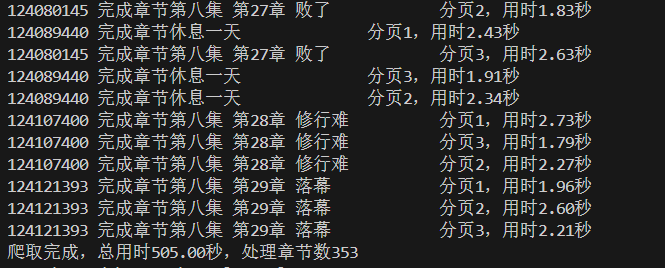
将执行上面的程序,我们就可以得到一个完整的txt文件
🛡️ 注意事项:做个友好的爬虫
在进行网络爬虫时,我们需要遵守一些基本的道德和法律规范,做一个“友好”的爬虫:
尊重 robots.txt 协议: 大部分网站都会在其根目录下放置一个名为 robots.txt 的文件,用于告诉爬虫哪些页面可以爬取,哪些不可以。在爬取网站之前,最好先查看一下这个文件,并遵守其规定。
控制爬取频率: 不要过于频繁地访问同一个网站,以免给服务器带来过大的负担,甚至被网站封禁 IP 地址。我们在代码中添加 time.sleep() 就是为了放慢爬取速度。
遵守网站的使用条款: 某些网站可能会有明确禁止爬虫的行为,我们需要尊重这些条款。
仅用于学习和个人使用: 爬取的内容应仅用于个人学习和研究,不得用于商业用途或侵犯他人的版权。
总结
本文通过一个完整的实例讲解了如何利用 Python 实现一个基本的网页小说爬虫。在实际项目中,爬虫除了技术实现,还需要注意以下几点:
反爬机制:网站可能存在反爬措施,可通过增加代理、调整请求间隔等方式规避。
数据存储与处理:爬取数据后需要及时清洗和存储,保障信息的完整与准确。
异常处理:完善的错误重试和日志记录机制能够大大提升程序健壮性。
希望通过本文的详细讲解,能帮助你深入理解爬虫开发的基本流程,也可以根据此实例进一步扩展其他爬虫功能。对于初学者来说,实践是最好的老师,多尝试、多调试,将理论与实践结合,一步步提升技能。
当然,现在我们完全可以使用 AI 辅助我们完成这些程序,但是仍然需要我们去一步步引导、优化它,所以我们学习这个,更多的是学习一个思路,并将它应用到更加广阔的领域。
我是心海,如果这篇文章对你有所启发,期待你的点赞关注!



















 2161
2161

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









