







卷积神经网络 (Convolutional Neural Network,CNN)
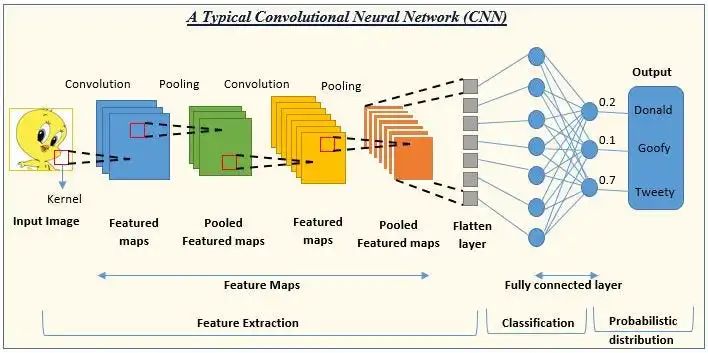
CNN 架构彻底改变了图像处理。借助这种算法,计算机获得了人类水平的视觉。该架构使用过滤器和图层来提取图像中的模式。由于这种工作方式,该架构通常用于图像分类、对象识别、人脸识别和类似应用。
循环神经网络 (Recurrent Neural Network,RNN)
CNN 在图像处理方面表现良好,但在翻译等 NLP 任务方面表现不佳。RNN 架构是针对模式随时间变化的数据而开发的,例如 NLP 和时间序列数据(如:股票走势预测)。RNN 将历史数据存储在内存中,并使用该数据来预测下一个时间点的数据。
生成对抗网络(Generative Adversarial Network,GAN)
另一种突破性的深度学习算法是 GAN,它用于提高产量,特别是在艺术和视频游戏等领域。GAN 经常用于生成图像和 NLP 等领域的数据。例如,使用 GAN,我们可以生成照片或逼真的人类语音。
大家熟知的AI换脸技术就是基于 GAN。
自编码器(Autoencoder)
今天,有大量的数据。从大数据中提取信息非常困难,因为它包含非常多的特征 为了减少大数据的维度,我们可以使用自编码器。
自编码器学习数据的压缩表示并能够处理维度较低的数据。例如,我们可以用几句话来描述一篇博客表达的内容。这就是自编码器发挥作用的地方。
Transformers
Transformers 是一种专为 NLP 应用程序设计的深度学习架构。该架构通过执行数学计算来揭示文本的含义,并使用许多注意力机制处理文本的不同方面。它在翻译任务上非常有效。

Transformers 在翻译句子时,首先将句子分成小部分,然后进行许多数学计算以确定每个部分的含义,然后将这些部分组合在一起形成完整的句子。GPT 和 BERT 等最先进的模型就是使用 Transformers 架构开发的。
决策树算法如何工作
套用西瓜书上的一个图来说明决策树算法是如何工作的:

我们挑选西瓜时,都会考虑西瓜脐部、色泽、根蒂以及敲一敲听声音等因素(特征),决策树就是对这些考虑因素进行逐个拆解,从而判断西瓜(样本)是好瓜还是坏瓜(类别)。
从上面来看,这些特征好像都是离散型的,对于 Iris 数据集中数值特征来说,我们可以设定一个阈值,比如判断萼片宽度(sepal width)是否小于 2.5 厘米。
决策树算法从树根开始,选择能够产生最大信息增益(Information Gain,IG)的特征进行数据集拆分,一直到叶子节点为止,所有叶子节点中的样本都属于同一个类别,这样就可能会产生非常深的树,从而引发过拟合问题,所以就需要对树进行剪枝以限制树的深度(模型复杂度)。
最大化信息增益
信息增益的公式定义如下

f 是要执行拆分的特征,Dp 和 Dj 表示父节点 p 和第 j 个孩子节点中的样本集,Np 和 Nj 分别表示父节点 p 和第 j 个孩子节点中的训练样本数量。I 就表示节点的纯度。
所以信息增益就是衡量父节点纯度和所有孩子节点纯度加权和的差异。
包括 scikit-learn 在内的大多数机器学习库的决策树算法都会将父节点分裂成左右两个孩子节点,所以信息增益公式可以简化为:

三种纯度衡量指标
现在有 Gini 纯度、熵和分类错误三种节点纯度衡量指标。
首先我们看一下熵(entropy):

p(i|t) 表示节点 t 中属于类别 i 的样本占该节点中所有样本的比例。如果节点 t 中所有样本都属于同一个类别,那么熵就是 0,表示这个节点没有不确定性;如果节点 t 中的每个样本都分属于不同的类别,那么此时熵最大,表示这个节点的不确定性最大。
Gini 纯度可以看作是最小化误分类概率的指标:

在实际应用中,Gini 纯度和熵表现很类似,所以不建议花很多精力去比较在选择哪种纯度衡量指标。相反更应集中精力实验不同决策树剪枝技巧。
最后一个就是分类错误:

这个指标适合用来做决策树剪枝,但是由于它对于节点中类别概率分布不敏感,所以它不适合用来生成决策树。
生成决策树
我们现在使用 scikit-learn 提供的 DecisionTreeClassifier 构建一个深度为 4,采样 Gnini 纯度的分类决策树,还是使用 Iris 数据集。
决策树算法不要求特征缩放。

可以看到这些决策边界几乎和坐标轴平行。
我们可以可视化生成的决策树,从而也能对模型的预测结果做出解释。

树分支的左孩子表示满足父节点中的判断条件,右孩子表示不满足条件。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









