






前言
你有没有发现,DeepSeek 最近没啥动静,这很奇怪。
打从过年的时候 DeepSeek R1 火爆 X 平台后,梁文锋出席了几个活动,就没啥动静了。
反观阿里呼哧呼哧在两个月内接连上新 QwQ 和 Qwen 3。
字节传出即梦 3.0 灰度测试后,近几天又正式发布了 Seed-1.5 VL。
除了五一劳动节前,给了我们一个文献浅浅品尝,好像真的潜水去了。。。
在它凭着首个 MoE 模型火出圈后,忙碌的只有被它圈粉的网友了吧。
我稍微扒了一下 X 平台上的时间线,发现从 3 月 25 日深度求索在 X 上发布了 DeepSeek-V3-0324 后就再也没说过什么话了。
反倒是网友一直在千呼万唤,非常活跃。
有个很有意思的事儿,有个网友发了很长一段话,大概讲的是「我昨天在一个实验室看到DeepSeek R2正在跑的新架构,看完脑子里只剩下牛逼两个字了,完全颠覆了整个世界了」。
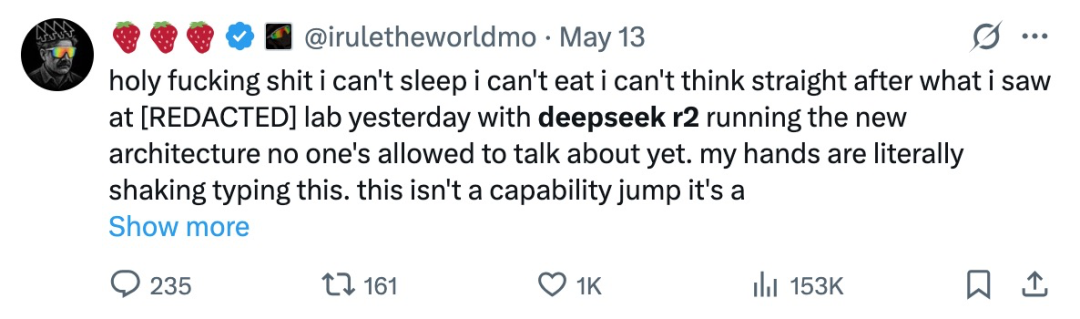
大家可以通过这个链接去看看,这个网友足足敲了 3000 多个词儿。
https://x.com/iruletheworldmo/status/1922035201527411118
其实早在 2 月底就有人说起 DeepSeek R2 要发布的事了,到了 5 月好像更多了。

瓜保熟吗?
来,让我们先简单捋一捋近半年深度求索的时间线。
2024 年 12 月 27 日,也就是元旦前一天发布 DeepSeek V3,这是全球首个全开源 MoE 模型。
2025 年 1 月 13 日,推出 App,使用 V3 大模型。
2025 年 1 月 20 日,发布开源大模型 R1。
2025 年 1 月 28 日,除夕夜推出 Janus-Pro-7B。
2025 年 4 月 4 日,提出了一个新的学习方法,自我原则点评调优。
2025 年 4 月 30 日,劳动节前一天开源了 DeepSeek-Prover-V2。
不知道大家有没有发现,深度求索更新的时间绝不含糊,国际节日前会给大家发点糖,尝尝配方正不正宗,到中国传统节日前就给国际一个重磅消息。 DeepSeek R1 是这样一点点深入人心的,我盲猜 R2 也极有可能是一样的出牌方式。
「许多个凑巧,同时间来到,就未必是凑巧」。
我有个预感,DeepSeek R2 应该很快就会来了,不会远,可能就在端午节前。
其实我对 DeepSeek R2 的感觉有点微妙,既希望它来,但又怕它胡来。我承认我是有点期待在它身上的。我看了一圈,发现很多网友也是和我一样的。
大家都对 DeepSeek R2 寄予厚望,这是一个好现象。
求上得中,求中得下。逼它一把,说不定就愿望成真了。。。
有关于 DeepSeek R2 的新特性,大家都提了很多自己的想法。
但总体上大差不差。

我也尝试收集了好些线索,这次,我也来凑个热闹,大胆预测下 DeepSeek R2 的新突破。
首先,DeepSeek R2 将不再是单打独斗,而是会和国内算力巨头强强联手。
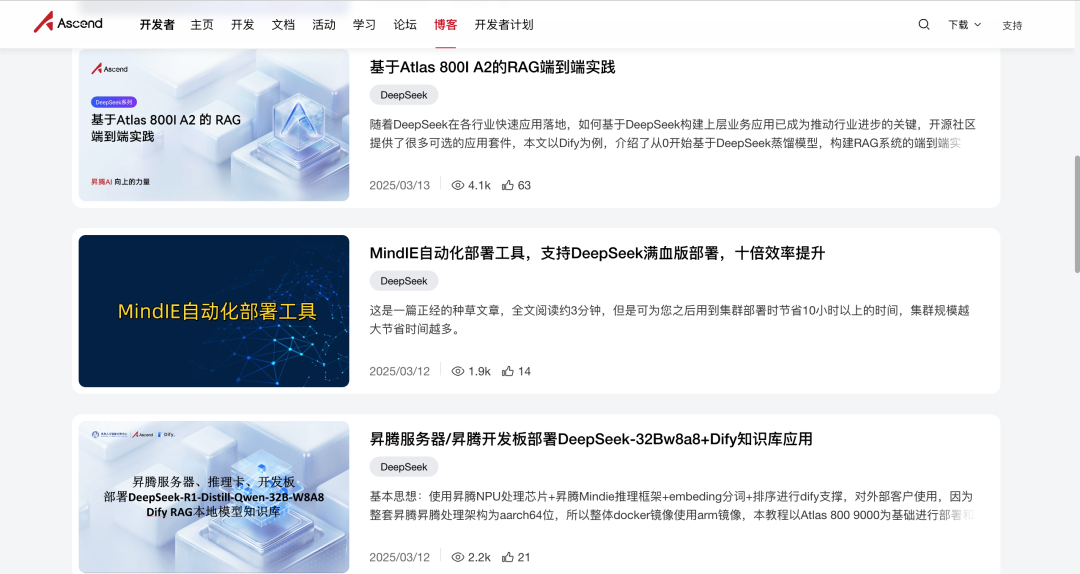
不难发现,在华为昇腾开发者社区,近三个月分享的方案里出现「DeepSeek」的频次非常高。
再顺藤摸瓜下,我还看到一个线索,早在 2 月 6 日,华为和 DeepSeek 深度合作了!
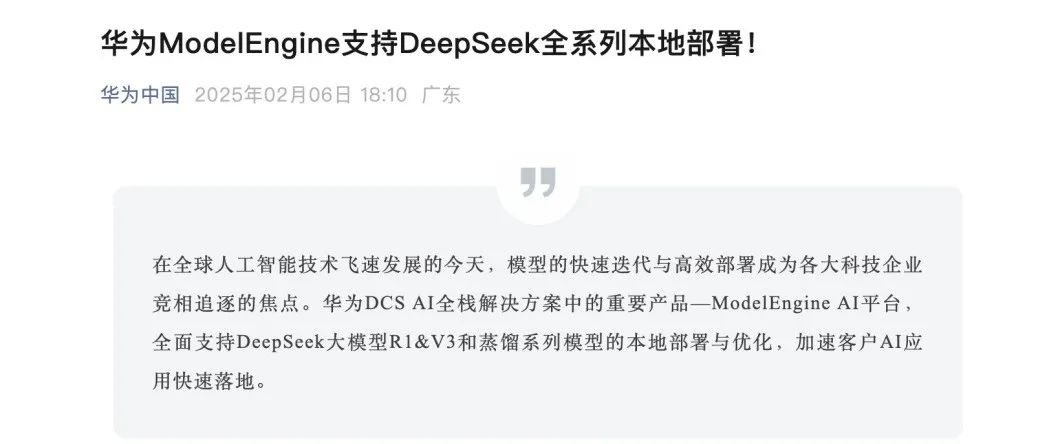
国产算力 x 国产 AI 大模型,从某种程度上意味着中国 AI 发展有希望不会被卡脖子,受制于人了。
虽然说,中美谈判后,英伟达算力短期内因关税豁免和特供芯片放行得到喘息。
但这也难说得好,特朗普永远不变的点就是他永远在变。

再者, DeepSeek R2 在技术创新上会带来更大的惊喜。而这个创新点不是以往的哪个方法的优化,而是一次从无到有的变革。这个极有可能就是「自我原则批评调整」新的学习方法。
以往的模型多少有点独裁专断在里面,不管来的什么客,也不管这客喜欢吃啥,都请他吃一顿西红柿炒鸡蛋。
大家都知道一刀切一定是有问题的,前不久的 DeepSeek-Prover-V2 论文也指出这个问题了。
文章里讲了一种好方法,就是「自我原则批评调整」。这是啥呢?通俗点讲,就是因地制宜,招待不同的客人,厨师不再听命于东家,而是问客人想吃啥。
我认为 DeepSeek-Prover-V2 的这个学习方法应用在 DeepSeek R2 上会大有用处。
甚至,它会是我们未来能否走向 AGI 的关键。毕竟真正的 AGI 一定是有自主选择的能力的。
另外。
DeepSeek 有一个缺点,不知道大家有没有发现。它只能读得懂文字,没有语音输入。


身边有好些朋友老是跟我吐槽,「 DeepSeek 回答质量是挺高,但是用起来好不方便啊」。
这个不方便体现在很多方面,现在的 DeepSeek 就好像一个特长生,除了理解文本比较出色,看图说话的能力基本上是没有的。
我们从小就被要求德智体美劳全面发展,DeepSeek 当然不例外。多模态 AI 一定是 DeepSeek R2 的宿命。
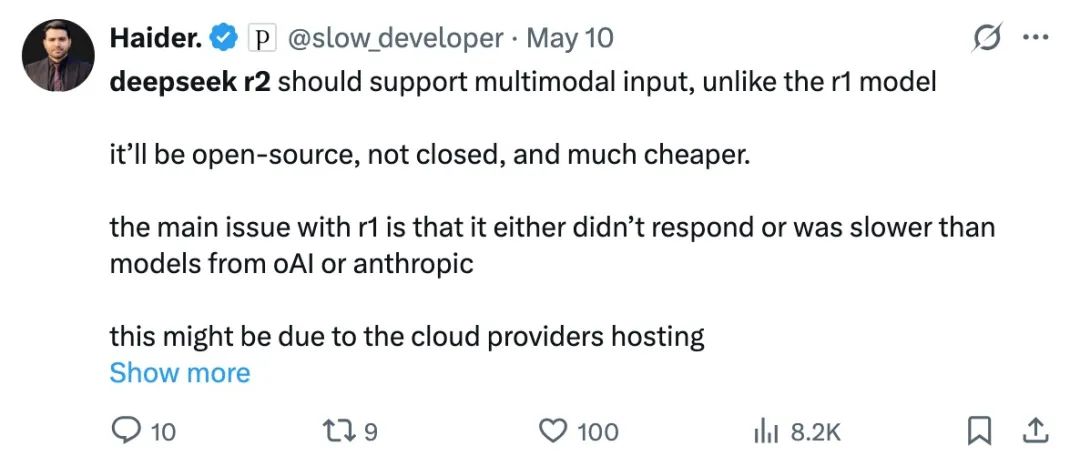
所以,「支持多模态」很有可能会是 DeepSeek R2 又一特性。
至于有多强,这玩意儿真没办法算出来。
但有点是可以确定的,DeepSeek R2 一定会把多模态价格打下来的。「鲶鱼效应」将会在未来AI发展中发挥的淋漓尽致,在我看来,DeepSeek 就是那条鲶鱼。
即使不是 DeepSeek R2,也可能是 DeepSeek R3、Qwen 3 Pro、即梦4.0、可灵 3.0、Seed。
说实话,基于这点,我挺希望 DeepSeek R2 快点上线的。现在表现稍微好点的多模态 AI,确实有点贵。。。
总的来说,DeepSeek R2 一定是「便宜大碗」「更大更强」的。
至于跳的对不对,那就期待下吧。
有一说一,现在的深度求索有点 AI 界雷布斯那味儿了。
妥妥价格战带盐人。
哪里价高,打哪里。
我发现,对于个人,似乎更重要的就是低价了。
我需要一个工具,帮我做一些事儿。
写写文案,搞搞 PPT。
但是,这样未免也太单一。
我认为本质并不在这里。
我们也许得学会「透过现象看本质」。
要做成一件事情,往往需要很多个步骤,需要很多人的参与。
要做好一件事情,更是需要综合水平更高的人或团队。
一定程度上短板无限放大,就成了致命点了。
然而,大模型的出现,就是为了扭转局面,扬长避短。
好比我是一个产品经理,我有个不错的想法,但我不会写代码,我需要一个开发替我去实现。但不巧的是,我的开发手上还有别的活儿。
以往,我们只能等,等协作者空闲。
而现在,我清楚表达需求,并给到会写代码的 AI,让它替我完成就可以了。
换而言之,DeepSeek 的火爆带来的不仅仅是低价的大模型使用,更是各种各样想法落地的机会。
对个人、家庭,对员工、企业,都是这样的。
我期待 DeepSeek R2。
我期待真正的「AI应用元年」的到来。
最后的最后
感谢你们的阅读和喜欢,作为一位在一线互联网行业奋斗多年的老兵,我深知在这个瞬息万变的技术领域中,持续学习和进步的重要性。
为了帮助更多热爱技术、渴望成长的朋友,我特别整理了一份涵盖大模型领域的宝贵资料集。
这些资料不仅是我多年积累的心血结晶,也是我在行业一线实战经验的总结。
这些学习资料不仅深入浅出,而且非常实用,让大家系统而高效地掌握AI大模型的各个知识点。如果你愿意花时间沉下心来学习,相信它们一定能为你提供实质性的帮助。
这份完整版的大模型 AI 学习资料已经上传CSDN,朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】

DeepSeek全套安装部署资料

大模型知识脑图
为了成为更好的 AI大模型 开发者,这里为大家提供了总的路线图。它的用处就在于,你可以按照上面的知识点去找对应的学习资源,保证自己学得较为全面。

经典书籍阅读
阅读AI大模型经典书籍可以帮助读者提高技术水平,开拓视野,掌握核心技术,提高解决问题的能力,同时也可以借鉴他人的经验。对于想要深入学习AI大模型开发的读者来说,阅读经典书籍是非常有必要的。

实战案例
光学理论是没用的,要学会跟着一起敲,要动手实操,才能将自己的所学运用到实际当中去,这时候可以搞点实战案例来学习。

面试资料
我们学习AI大模型必然是想找到高薪的工作,下面这些面试题都是总结当前最新、最热、最高频的面试题,并且每道题都有详细的答案,面试前刷完这套面试题资料,小小offer,不在话下

640套AI大模型报告合集
这套包含640份报告的合集,涵盖了AI大模型的理论研究、技术实现、行业应用等多个方面。无论您是科研人员、工程师,还是对AI大模型感兴趣的爱好者,这套报告合集都将为您提供宝贵的信息和启示。

这份完整版的大模型 AI 学习资料已经上传CSDN,朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









