









改善深层网络之深度学习使用层面
1- 训练集、验证集、测试集的数据分配问题(Train/Dev/Test sets):
(1)数据较少时,可以按照7/3划分(没有验证集),或者是6/2/2划分,机器学习领域内普遍认可这种划分。
(2)如果数据很多,达到十万百万级,可以按照98/1/1,或者验证集和测试集更小也是可以的。
2- 偏差与方差(Bias/Variance):
(1)偏差(bias):偏差衡量了模型的预测值与实际值之间的偏离关系。通常在深度学习中,我们每一次训练迭代出来的新模型,都会拿训练数据进行预测,偏差就反应在预测值与实际值匹配度上,比如通常在keras运行中看到的准确度为96%,则说明是低偏差;反之,如果准确度只有70%,则说明是高偏差。偏差较大为欠拟合。
(2)方差(variance):方差描述的是训练数据在不同迭代阶段的训练模型中,预测值的变化波动情况(或称之为离散情况)。从数学角度看,可以理解为每个预测值与预测均值差的平方和的再求平均数。通常在深度学习训练中,初始阶段模型复杂度不高,为低方差;随着训练量加大,模型逐步拟合训练数据,复杂度开始变高,此时方差会逐渐变高。方差较大为过拟合。
减少神经网络过拟合的方法有:1,数据扩增。2,提前终止训练。3,正则化。4,Dropout。
参考链接:https://www.cnblogs.com/hutao722/p/9921788.html
3- 正则化(Regularization):
深度学习可能存在过拟合问题——高方差,有两个解决方法,一个是正则化,另一个是准备更多的数据,这是非常可靠的方法,但你可能无法时时刻刻准备足够多的训练数据或者获取更多数据的成本很高,但正则化通常有助于避免过拟合或减少你的网络误差。
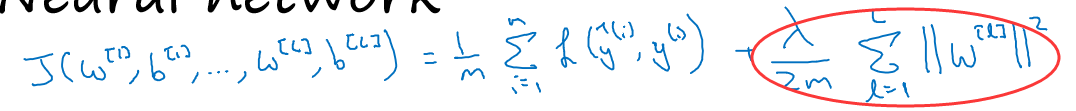
圆圈里的就是正则项(L2正则,L2范数正则化也被称为“权重衰减”),其中λ是权重衰减(weight decay)的超参数。
为什么正则化可以有效的改善过拟合?直观理解就是λ增加到足够大,w会接近于0,这相当于消除了一些神经元,使得网络变得简单,不容易发生过拟合。
4- Dropout正则化(Dropout Regularization):
除了正则化,还有一个非常实用的正则化方法–“Dropout(随机失活)”,工作原理在训练网络的时候,按比例的让一部分的神经元失活,降低隐藏层结构的复杂度,使其退化成相对简单的网络来降低高方差。
如何实施Dropout,最常用的方法是inverted dropout(反向随机失活):

为了不影响下一层z的期望值,我们需要a3/keepProb,他会修正或弥补我们所需的那20%
5- 归一化输入(Normalizing inputs):
步骤:1,零均值。2,归一化方差。
作用:1,消除量纲。2,加快模型收敛。
6- 梯度消失于梯度弥散(Vanishing/Exploding gradients):
参考这篇博客:https://blog.csdn.net/junjun150013652/article/details/81274958
7- 神经网络的权重初始化(Weight Initialization for Deep Networks):
降低了梯度消失和爆炸问题,因为它给权重矩阵设置了合理值,你也知道,它不能比1大很多,也不能比1小很多,所以梯度没有爆炸或消失过快。

8- 梯度检验:
在实施神经网络时,我经常需要执行foreprop和backprop,然后我可能发现这个梯度检验有一个相对较大的值,我会怀疑存在bug,然后开始调试,调试,调试,调试一段时间后,我得到一个很小的梯度检验值,现在我可以很自信的说,神经网络实施是正确的。不要在训练中使用梯度检验,它只用于调试。
(1),双边误差公式的结果更准确
(2),梯度检验帮我们节省了很多时间,也多次帮我发现backprop实施过程中的bug















 377
377











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









