import pymysql
mydb = pymysql.connect(host="localhost",# ①
user='root',
password='1q2w3e4r5t',
db="books",)
cursor = mydb.cursor()# ②
sql ="select * from mybooks"# ③
cursor.execute(sql)# ④
datas = cursor.fetchall()# ⑤for data in datas:print(data)
sql_count ="SELECT COUNT(1) FROM city"
cursor.execute(sql_count)
n = cursor.fetchone()# 获得一个返回值
n
1.4 读取来着API的数据
import requests
response = requests.get("https://api.github.com/users/qiwsir")# ①
response.json()
import pandas as pd
data = response.json()# ②
login = data['login']# ③
name = data['name']
blog = data['blog']
public_repos = data['public_repos']
followers = data['followers']
html_url = data['html_url']
df = pd.DataFrame([[login, name, blog, public_repos, followers, html_url]],
columns=['login','name','blog','public_repos','followers','html_url'])# ④
df
二、数据清理
2.1 数据查看
import pandas as pd
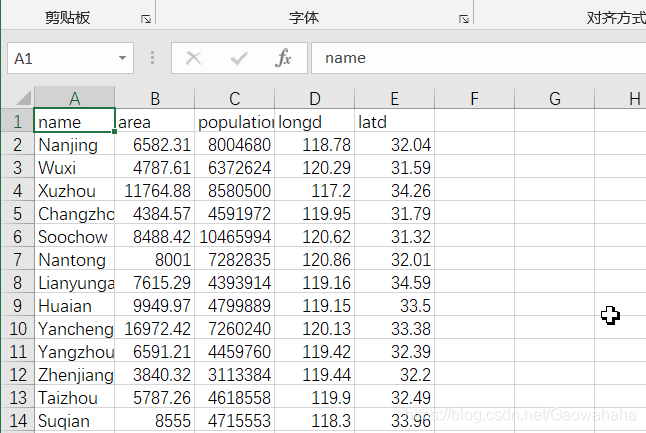
df = pd.read_csv("/home/aistudio/data/data20505/pm2.csv")
df.sample(10)
df.shape # (264, 4)
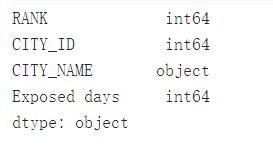
df.info()#查看信息
df.dtypes
2.2 转换数据类型
import pandas as pd
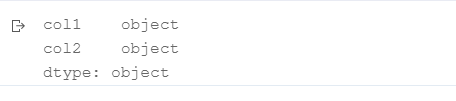
df = pd.DataFrame([{'col1':'a','col2':'1'},{'col1':'b','col2':'2'}])
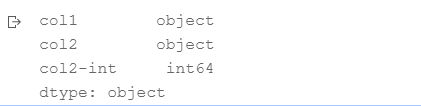
df.dtypes
df['col2-int']= df['col2'].astype(int)# ①
df.dtypes
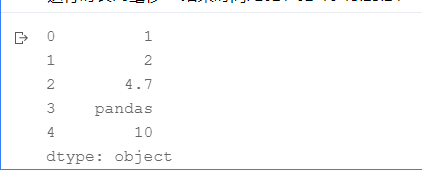
s = pd.Series(['1','2','4.7','pandas','10'])
s.astype(float, errors='ignore')
pd.to_numeric(s, errors='coerce')
import pandas as pd
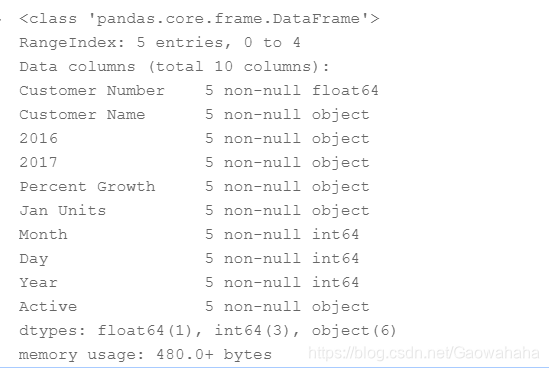
df = pd.read_csv('/home/aistudio/data/data20506/sales_types.csv')
df.info()
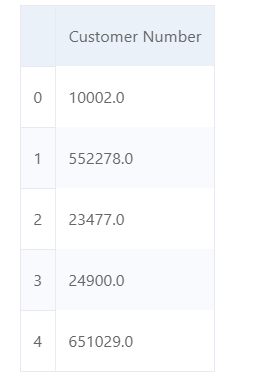
df[['Customer Number']]
df['Customer Number'].astype(int).astype(str)
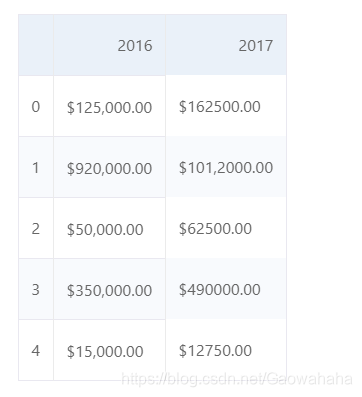
df[['2016','2017']]
defconvert_money(value):
new_value = value.replace("$","").replace(",","")# ②returnfloat(new_value)
df['2016'].apply(convert_money)# ③
import numpy as np
np.where(df['Active']=='Y',1,0)
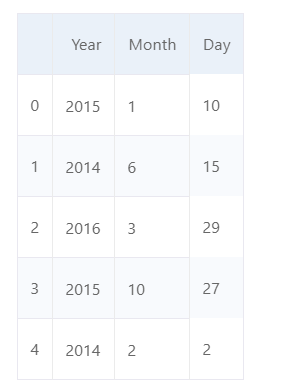
df[['Year','Month','Day']]
pd.to_datetime(df[['Month','Day','Year']])
2.3 处理重复数据
import pandas as pd
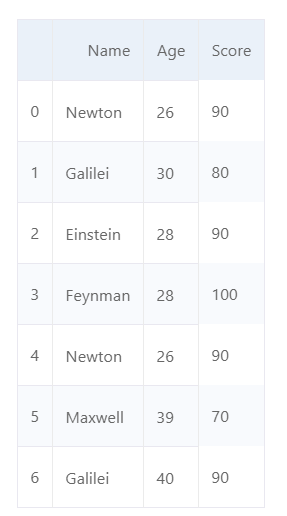
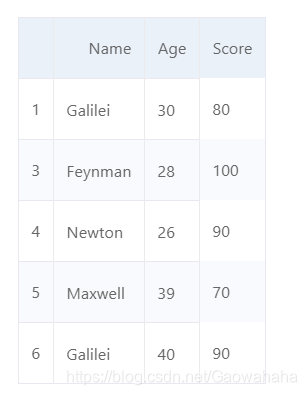
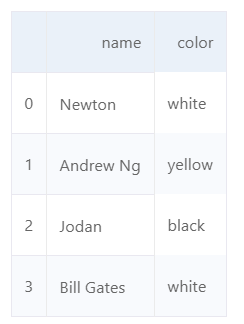
d ={'Name':['Newton','Galilei','Einstein','Feynman','Newton','Maxwell','Galilei'],'Age':[26,30,28,28,26,39,40],'Score':[90,80,90,100,90,70,90]}
df = pd.DataFrame(d,columns=['Name','Age','Score'])
df
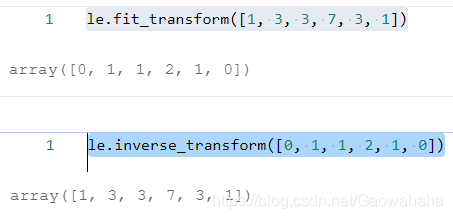
from sklearn.preprocessing import LabelEncoder
le = LabelEncoder()# ①
le.fit(['white','green','red','green','white'])# ②
le.classes_ # ③#out : array(['green', 'red', 'white'], dtype='<U5')
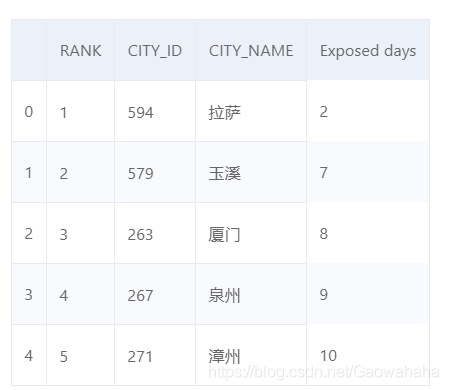
import pandas as pd
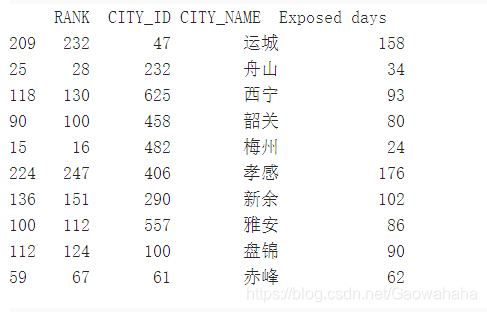
pm25 = pd.read_csv("/home/aistudio/data/data20505/pm2.csv")
pm25.head()
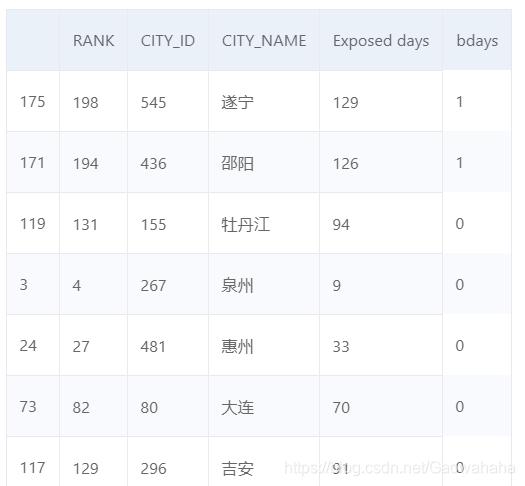
import numpy as np
pm25['bdays']= np.where(pm25["Exposed days"]> pm25["Exposed days"].mean(),1,0)
pm25.sample(10)
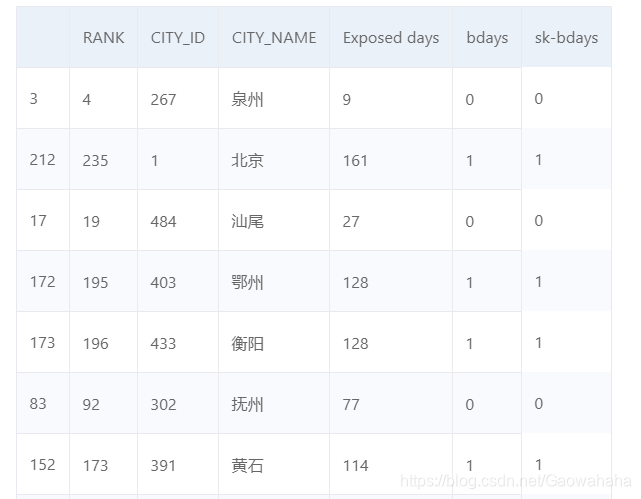
from sklearn.preprocessing import Binarizer
bn = Binarizer(threshold=pm25["Exposed days"].mean())# ①
result = bn.fit_transform(pm25[["Exposed days"]])# ②
pm25['sk-bdays']= result
pm25.sample(10)
from sklearn.preprocessing import OneHotEncoder
ohe = OneHotEncoder()
features = ohe.fit_transform(persons[['color']])
features.toarray()
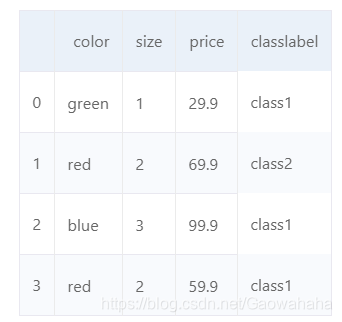
size_mapping ={'XL':3,'L':2,'M':1}
df['size']= df['size'].map(size_mapping)# ②
df
3.4 数据变换
import numpy as np
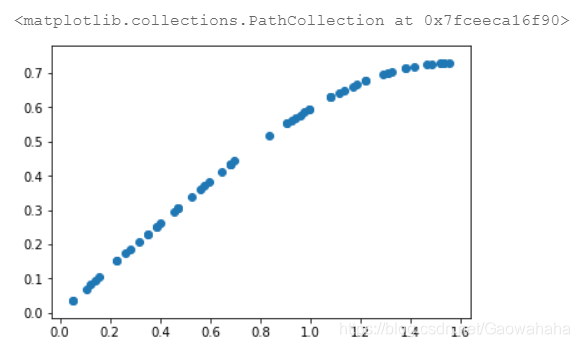
data.drop([0], inplace=True)# 去掉0,不计算log0
data['logtime']= np.log10(data['time'])# ①
data['logloc']= np.log10(data['location'])# ②
data.head()



































 2万+
2万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









