







Cross-Domain Robustness of Transformer-based Keyphrase Generation
基于Transformer的关键词生成的跨域鲁棒性
使用生成式摘要模型来生成关键词列表,这样可以生成文本中不存在的关键词,优于抽取式的方式,本文并没有什么创新之处,
只是验证了生成式的优势,使用的bart模型。
paper: https://arxiv.org/abs/2312.10700
github:https://huggingface.co/beogradjanka/bart_finetuned_keyphrase_extraction
文章目录~
1.背景动机
介绍关键词抽取的现有研究:
大多数用于关键词选择的无监督方法都以提取关键词为目的,也就是对文本中出现的短语进行排序和选择**。**最新的生成式方法既能生成文本中出现的关键词,也能生成文本中没有的关键词。
由于关键词列表是科学文本的某种摘要,因此预训练的抽象摘要模型能有效地生成关键词序列。结果表明,BART经过微调后可以在目标领域的文本上生成关键词列表。不过,它在其他语料库和领域的文本上表现较差。本文的目标是评估能否将 BART 模型中的知识转移到其他领域,该模型经过微调,可为一个领域生成关键词。本文试图回答以下研究问题:
- RQ1.在一个语料库或一个域中微调过的摘要模型,在zero-shot设置下从其他语料库或域的文本中生成关键词的效果如何?
- RQ2.能否通过添加来自其他语料库和领域的训练示例来提高模型性能?
- RQ3.通过少量的训练示例,模型能否像在较大语料库中微调的模型一样有效?
- RQ4.transfer learning能否利用不同规模的训练数据提高模型性能?
2.Model
1.数据集的选择(计算机/生物医学/新闻):
- Krapivin 和 Inspec包含计算机科学领域的科学文本;
- PubMed 和 NamedKeys,包含生物医学领域的科学文本;
- DUC-2001和 KPTimes 包含新闻文本。
在这项工作中,分别利用论文的摘要和正文来选择关键词(分别为 Krapivin-A 和 Krapivin-T)。
2.BART模型训练构造:
为了生成关键词,本文使用了 BART-base。该模型有 12 层,每层有 768 个隐藏单元。BART 的预训练方法是破坏文档,然后优化重建损失-解码器输出与原始文档之间的交叉熵。
本文对 BART-base 进行了六次微调,最大序列长度为 256 个 token。使用了标准的交叉熵损失和 AdamW 优化器。将源文本作为模型的输入,将字符串格式的关键词列表作为输出**。**关键词列表中的关键词用逗号分隔。
3.通过实验结果,对问题RQ1和RQ2的解析:
为了回答 RQ1 和 RQ2,本文在混合数据上对 BART 进行了微调。为此,评估了四种策略:
- Domaineq,在一个领域的所有语料库文本上对模型进行微调,然后在每个语料库上分别进行测试。在这一策略中,对每个语料库使用相同数量的文本。
- Domainall,策略与前者类似,但使用每个语料库的所有文本。
- Mixeq,在所有语料库的文本上对模型进行微调,每个语料库的文本数量相等。
- Mixall,策略与 Mixeq 类似,但使用每个语料库的所有文本。
问题RQ1:在目标语料库上进行微调的 BART 在许多情况下都优于基线方法。在同一语料库中,对摘要进行微调的得分高于对论文正文进行微调的得分。由于输入序列的长度和资源限制,摘要和文本的长度仅限于前 256 个词组。
问题RQ2:使用额外数据的效果因语料库的特点而异。对于训练示例较少的 DUC-2001 来说,使用其他语料库和领域的训练示例提高了所有策略的结果。相反,对于 KPTimes(实验中最大的语料库),使用唯一的目标训练集获得的结果最高。使用_Domain e q {}_{eq} eq_和_Mix e q {}_{eq} eq_策略会导致训练集的大小和目标示例的数量急剧下降,并对模型性能产生负面影响。一般来说,Mix e q {}_{eq} eq 策略会降低除 DUC-2001 以外的所有语料库的得分,原因是目标语料库的训练数据量大幅减少。_Mix a l l {}_{all} all_通常会提高性能,或者至少不会导致结果的大幅下降。
4.通过实验结果,对问题RQ3和RQ4的解析:
问题RQ3:本文在较少的训练实例上对 BART 进行了微调,并通过增加训练数据的规模来评估其性能。本文从目标训练集中随机抽取 50 个文本,在这个子集中对预训练模型进行微调,然后在目标测试集中进行测试。接下来,我们在目标训练集中增加 50 个文本样本,并重复上述过程,直到 1,000 个文本或训练集结束。将结果与使用完整目标语料库和等比例混合的域外语料库获得的分数进行了比较
问题RQ4:本文评估了两阶段微调的两种方案**。**在第一种情况下,在一半的epochs期间在域外数据上对模型进行微调,然后在剩余的三个epochs期间继续在目标数据上进行微调。在第二种情况下,将epochs次数增加了一倍,并在六个epochs内同时在域外数据和目标数据上对模型进行微调。
在目标样本量较小(≈ 最多 300 个文本)的情况下,进行两阶段微调的模型优于仅在目标语料库上进行微调的模型。因此,使用域外语料库可以减少目标数据的使用量。
3.原文阅读
Abstract
用于文本生成的现代模型在许多自然语言处理任务中都取得了最先进的成果。在这项工作中,我们探讨了抽象文本摘要模型在关键词选择方面的有效性。关键词列表是数据库和电子文档库中文本的重要元素。在我们的实验中,针对关键词生成进行微调的抽象文本摘要模型在目标文本语料库中显示出相当高的结果。然而,在大多数情况下,在其他语料库和领域中的zero-shot性能要低得多。我们研究了抽象文本摘要模型在关键词生成方面的跨领域局限性。我们介绍了针对关键词选择任务的微调 BART 模型在六个基准语料库中的评估结果,这些语料库包括来自两个领域的科学文本和新闻文本。我们探讨了不同领域之间的迁移学习对提高 BART 模型在小型文本语料库中的性能所起的作用。我们的实验表明,在样本数量有限的情况下,在域外语料库上进行初步微调是有效的。
1 Introduction
介绍关键词的应用背景:
关键词生成任务旨在预测一组概括源文本内容的关键词。关键词通常被编入数据库索引,以提高信息检索工具的性能。研究人员为自己的论文选择关键词,以提高论文在科学界的知名度。为学术文档自动选择关键词有助于分析当前的研究趋势、推荐论文和确定潜在的同行评审人。
介绍关键词抽取的现有研究:

图 1 展示了一个源文本及其关键词的例子。源文本中存在一些关键词,而另一些则不存在。大多数用于关键词选择的无监督方法都以提取关键词为目的,换句话说,就是对文本中出现的短语进行排序和选择。最新的生成式方法既能生成文本中出现的关键词,也能生成文本中没有的关键词。这些方法利用编码器-解码器架构(encoder-decoder architecture)[8,32,48]和各种训练技术,如结合复制机制(copying mechanism)[44]、强化学习(reinforcement learning)[10]、分层解码(hi-erarchical decoding)[11]和多任务学习(multitask learning)[26]等深度学习方法。目前,自动文本生成模型在各种自然语言处理任务中取得了很高的成绩。由于关键词列表是科学文本的某种摘要,因此预先训练的抽象摘要模型似乎能有效地生成关键词序列。在我们之前的工作中[18,19],我们对其中一些用于生成关键词的模型进行了性能测试。结果表明,BART[27]经过微调后可以在目标领域的文本上生成关键词列表,与几种基线相比,它的结果很有竞争力。不过,与其他微调模型类似,**它在其他语料库和领域的文本上表现较差。我们的目标是评估我们能否将 BART 模型中的知识转移到其他领域,该模型经过微调,可为一个领域生成关键词。**我们试图回答以下研究问题:
RQ1. 在一个语料库或一个域中微调过的文本摘要模型,在zero-shot设置下从其他语料库或域的文本中生成关键词的效果如何?
RQ2. 我们能否通过添加来自其他语料库和领域的训练示例来提高模型性能?
**RQ3.**通过少量的训练示例,模型能否像在较大语料库中微调的模型一样有效?
RQ4. transfer learning能否利用不同规模的训练数据提高模型性能?
本文的结构如下。第 2 节介绍了该领域的相关工作。第 3 节介绍了语料库。第 4 节简要介绍了我们使用的模型。第 5 节介绍了实验设置。第 6 节报告并讨论了实验结果。第 7 节是本文的结论。
2 Related Work
2.1.Abstractive Text Summarization using Pre-trained Transformers
在许多自然语言处理(NLP)任务中,预训练语言模型都显示出令人印象深刻的效果。预训练模型是指之前在大型数据集上训练过的保存网络。这是在小型数据集上进行深度学习的一种常见且高效的方法。自动文本摘要是 NLP 的一个相关趋势。摘要可以通过提取法和抽象法生成。抽象方法很难实现,因为它们需要大量的自然语言处理。然而,抽象模型,如 BART [27]、PEGASUS [49] 等,允许我们通过重新措辞或使用新词来生成新样本,而不是简单地提取重要句子 [21, 41]。
许多研究人员已经对基于预训练语言模型的神经抽象摘要进行了研究,并在大型文本语料库的帮助下显示出很高的性能。特别是,抽象摘要模型被应用于生成新闻[5,13,20,52]、科学[6,35,45]、体育[31]和金融领域[42,51]的摘要。神经抽象摘要法面临的主要挑战之一是,如果目标语料库的样本数量较少,可能会出现领域偏移问题和过度拟合问题[12]。由于不同的语料库包含不同写作风格和形式的文本,因此使用其他语料库的附加文本并不总是成功的。抽象总结的注释成本很高。因此,探索低资源抽象总结的方法非常有意义,并引起了科学家们的关注。
2.2.Keyword Selection
关键词选择方法大致可分为三类:i) 实际关键词提取;ii) 关键词分配;iii) 关键词生成。实际关键词提取包括提取文本中直接出现的词语。在关键词分配中,关键词是从一组预定义的术语中选择的,而文档则根据其主题分类。关键词生成旨在利用神经网络序列到序列应用的最新进展,生成一组或一串关键词。在这项工作中,我们专注于关键词生成,但也使用一些关键词提取方法作为基线。关键词生成允许我们生成源文本中未以明确形式呈现的宽泛术语和关键词。
迄今为止,一些学者已经研究了以序列形式生成多个关键词的神经模型[8, 39]。Chowdhury 等人[14]的研究表明,与现有的抽取式神经模型相比,经过微调的 BART 在关键词生成方面显示出了有竞争力的结果。在文献[23, 46]中,作者尝试用可控文本生成技术生成关键词。文献[26]的作者提出了 KeyBART,这是 BART 模型的一种新的预训练设置,可学习按照源文件中的原始顺序生成关键词。Shen 和Le[37]研究了标题关注和序列代码代表关键词序列中短语顺序在改进基于transformer的关键词生成方面的优势。
文献[38]的作者全面考察了从预训练语言模型中选择关键词的最新进展。他们强调,大多数现有的关键词提取数据集和研究都是基于一些最常见的主题,缺乏与其他领域相关的数据集和研究。因此,将知识从一个领域转移到另一个领域,以建立特定领域的关键词提取模型,是关键词生成的主要挑战之一。
3 Data
实验在六个语料库中进行关键词选择:
- Krapivin [25] 和 Inspec [22] 包含计算机科学领域的科学文本;
- PubMed [36] 和 NamedKeys [17],包含生物医学领域的科学文本;
- DUC-2001 [43] 和 KPTimes [16] 包含新闻文本。
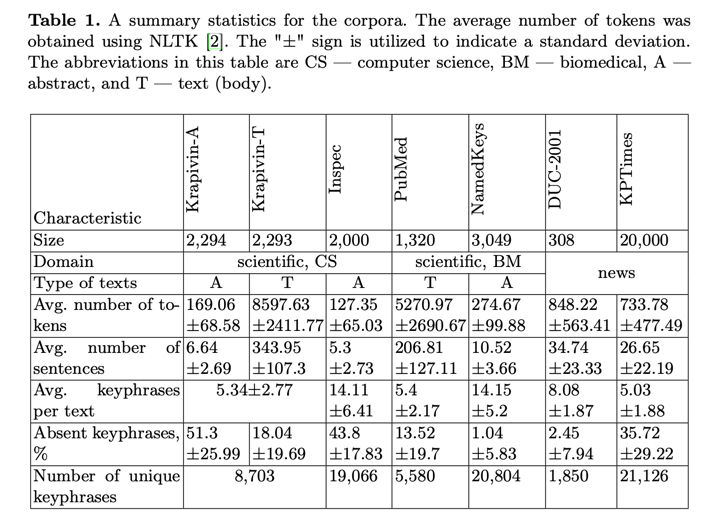
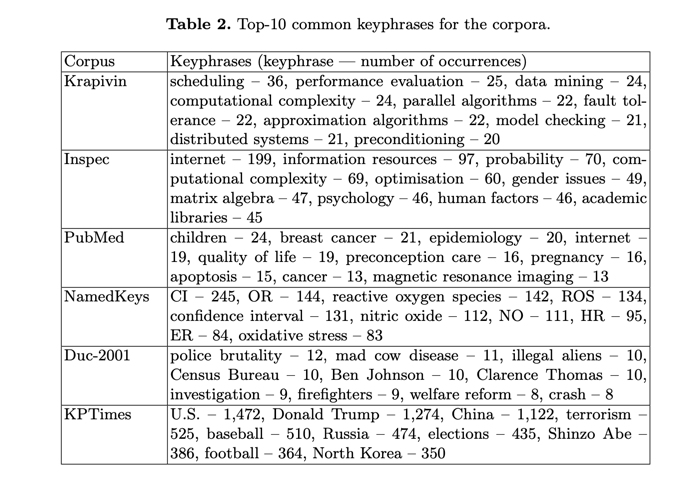
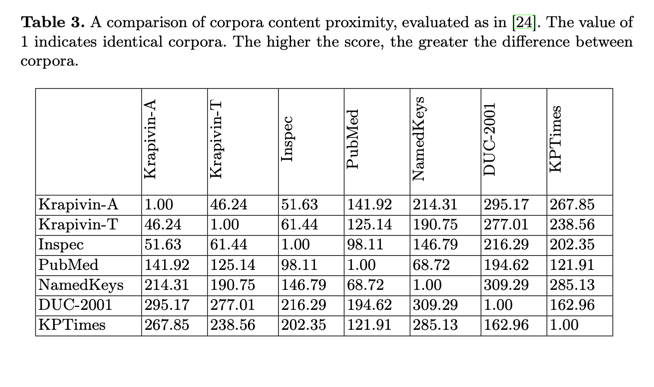
Krapivin 语料库包含分为标题、摘要和正文的论文全文。在这项工作中,我们分别利用论文的摘要和正文来选择关键词(分别为 Krapivin-A 和 Krapivin-T)。KPTi- mes 原始语料库由 279,923 个文章-关键词对组成。在此,我们只使用了原始语料库的测试集,其中包含 20,000 个样本。表 1 列出了语料库的简要统计数据。最流行的关键词见表 2。表 3 对语料库的内容进行了比较。
4 Models
模型的选择构造:
为了生成关键词,我们使用了 BART-base [27],这是一种基于transformer的去噪自动编码器,用于预训练 seq2seq 模型。该模型有 12 层,每层有 768 个隐藏单元,共有 1.39 亿个参数。BART 的预训练方法是破坏文档,然后优化重建损失–解码器输出与原始文档之间的交叉熵。我们对 BART-base 进行了六次微调,最大序列长度为 256 个 token。我们使用了标准的交叉熵损失和 AdamW 优化器 [30]。我们将源文本作为模型的输入,将字符串格式的关键词列表作为输出。关键词列表中的关键词用逗号分隔。
作为基准,我们使用了 PKE 库[3]中的 TopicRank [4] 和 YAKE![7]和 KeyBART [26],后者代表了基于 BART 架构的预训练,可在 OAGKX 数据集[9]上生成预训练的关键词序列。
5 Experimental Setup
我们将每个语料库随机分成 70% 的训练集和 30% 的测试集。对于 BART,我们对每个模型运行三次,然后计算平均结果。由于 TopicRank 和 YAKE! 都是无监督方法,需要预先设定关键词的数量,因此我们为每个语料提取了 5、10 和 15 个关键词,并为每个指标选择了最佳值。KeyBART 是在零拍摄设置下使用的。我们根据全匹配 F1 分数(F1)、ROUGE-1(R1)、ROUGE-L(RL)[28] 和 BERTScore(BS)[50] 对模型进行了评估。
全匹配 F1 分数评估的是原始关键词集和生成关键词集之间完全匹配的数量。其计算方法是精确度和召回率的调和平均值。
ROUGE-1 分数计算模型生成的文本与参考文献之间匹配的单字符数。ROUGE-L 分数的计算方法类似,但测量的是最长的共同子序列。为了测量 ROUGE-1 和 ROUGE-L,我们将每个文本的关键词合并成一个字符串,并用逗号作为分隔符。
BERTScore 利用基于 BERT 模型的预训练上下文嵌入,使用余弦相似度匹配源文本和生成文本中的词语。研究表明,在句子级和系统级评估中,人类判断与这一指标相关。为了计算 BERTScore,我们使用了 RoBERTa-large [29]的上下文嵌入,它是对 BERT 的一种修改,使用动态屏蔽进行了预训练。
6 Results and Discussion
为了回答 RQ1 和 RQ2,我们在一个语料库上对 BART 进行了微调,并在zero-shot设置下将其应用于其他语料库。然后,我们在混合数据上对 BART 进行了微调。为此,我们评估了四种策略:
- 我们使用 Domaineq,在一个领域(例如,CS 领域包括 Krapivin-a、Krapivin-T 和 Inspec)的所有语料库文本上对模型进行微调,然后在每个语料库上分别进行测试。在这一策略中,我们对每个语料库使用相同数量的文本。例如,如果 Krapivin-A、Krapivin-T 和 Inspec 的训练集大小分别为 1,606、1,605 和 1,400,我们就从 Krapivin-A 和 Krapivin-T 中随机使用 1,400 个文本,从 Inspec 中使用所有文本。训练数据的总体规模为 4,200 个。来自不同语料库的文本以随机顺序混合。
- 全域,策略与前者类似,但我们使用每个语料库的所有文本。在这种情况下,上述示例的总训练数据量为 4,611 个,即 1,606+1,605+1,400 个。
- Mixeq:在所有语料库的文本上对模型进行微调,每个语料库的文本数量相等,然后分别在每个语料库上进行测试。不同语料库的文本以随机顺序混合。
- Mixall,策略与 Mixeq 类似,但我们使用每个语料库的所有文本。
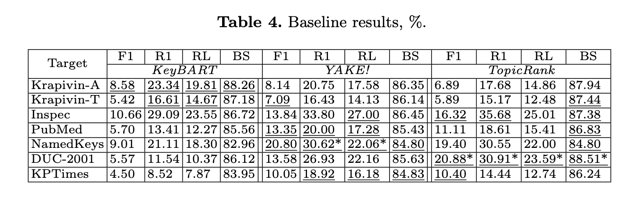
表 4 显示了基线在测试集上的性能。最佳基线结果以下划线表示。不同方法的性能因语料库而异。例如,KeyBART 在新闻领域的表现较差,因为该模型是在科学文本上预先训练过的。
表 5 列出了 BART 的结果。根据包含目标语料库的数据对模型进行微调后得到的结果以灰色标出。训练数据以斜体显示。优于基线的分数用下划线标出。对于混合训练数据,我们在括号中标出了训练示例的总数,并用粗体标出了超过仅在目标语料库上进行微调的 BART 结果的分数。所有模型中的最佳结果(表 4 和表 5)用星号(*)标出。附录 A 中的表 6 显示了 BART 三次运行的标准偏差。
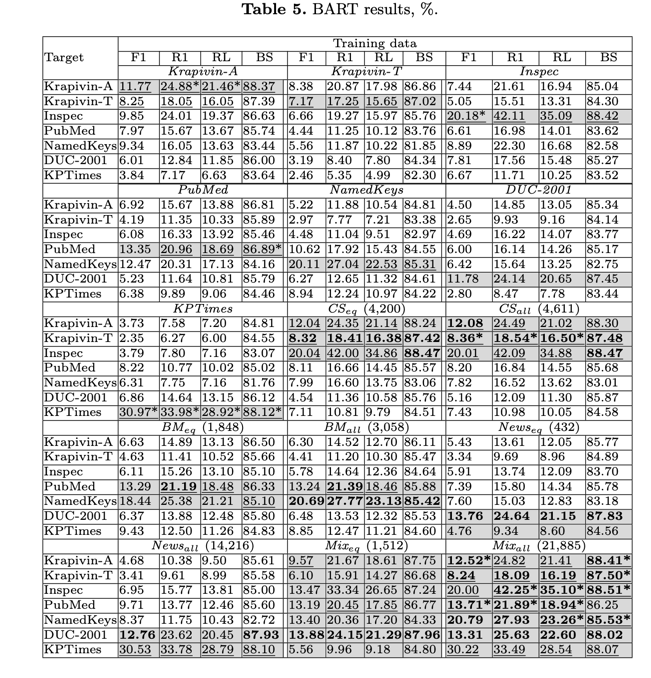
在目标语料库上进行微调的 BART 在许多情况下都优于基线方法(Krapivin-A、Inspec 和 KPTimes - 所有指标;Krapivin-T - F1、R1 和 RL;PubMed - R1、RL 和 BS;NamedKeys - RL 和 BS)。在 DUC-2001 中,BART 的结果低于无监督方法的结果,这可能是由于该语料库的规模较小。语料库外的结果普遍低于语料库内的结果。例如,在 Inspec(CS 领域)上进行微调时,Krapivin-A 和 Krapivin-T(均为 CS 领域)的 F1 性能分别降低了 37% 和 30%,PubMed 和 NamedKeys(BM 领域)分别降低了 51% 和 56%,DUC-2001 和 KPTimes(新闻领域)分别降低了 34% 和 78%。唯一的例外是 Krapivin-A 的微调模型。对于 Krapivin-T,其结果高于语料库中的得分。因此,在同一语料库中,对摘要进行微调的得分高于对论文正文进行微调的得分。由于输入序列的长度和资源限制,摘要和文本的长度仅限于前 256 个词组。
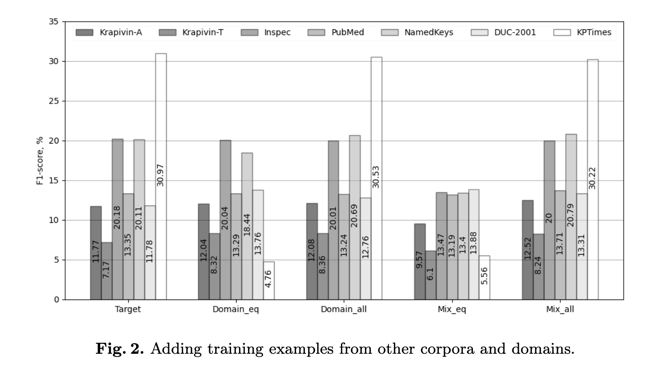
图 2 展示了添加其他语料库和领域的训练示例对 F1 的影响。在我们的实验中,使用额外数据的效果因语料库的特点而异。对于训练示例较少的 DUC-2001 来说,使用其他语料库和领域的训练示例提高了所有策略的结果。相反,对于 KPTimes(我们实验中最大的语料库),使用唯一的目标训练集获得的结果最高。使用_Domain e q {}_{eq} eq_和_Mix e q {}_{eq} eq_策略会导致训练集的大小和目标示例的数量急剧下降,并对模型性能产生负面影响。一般来说,Mix e q {}_{eq} eq 策略会降低除 DUC-2001 以外的所有语料库的得分,原因是目标语料库的训练数据量大幅减少。_Mix a l l {}_{all} all_通常会提高性能,或者至少不会导致结果的大幅下降1。在 Krapivin-A(就 F1 和 BS 而言)、Krapivin-T(BS)、Inspec(R1、RL 和 BS)、PubMed(F1、R1、RL)和 NamedKeys(RL、BS)的所有模型中,该策略都显示出最佳结果。数据集规模的缩小自然会导致训练时间的减少。例如,Mix a l l {}_{all} all(21 885 个训练示例)的训练时间为 53 分 59 秒,Mix e q {}_{eq} eq(1 512 个训练示例)的训练时间为 3 分 59 秒。在这种情况下,使用英伟达™(NVIDIA®)Tesla T4 GPU 的训练时间缩短了约 20 倍。
为了回答问题 3,我们在较少的训练实例上对 BART 进行了微调,并通过增加训练数据的规模来评估其性能。与 [33] 类似,我们采用了以下少量转移程序。我们从目标训练集中随机抽取 50 个文本,在这个子集中对预训练模型进行微调,然后在目标测试集中进行测试。接下来,我们在目标训练集中增加 50 个文本样本,并重复上述过程,直到 1,000 个文本或训练集结束。我们将结果与使用完整目标语料库和等比例混合的域外语料库获得的分数进行了比较。例如,对于 Krapivin-A,混合使用的域外语料包括 PubMed、NamedKeys、DUC-2001 和 KPTimes。为了回答问题 4,我们首先在混合的域外语料库上对 BART 进行了微调,然后使用上述策略在目标语料库的文本上对同一模型进行了微调。我们评估了两阶段微调的两种方案。**在第一种情况下,我们在一半的epochs(六个epochs中的三个)期间在域外数据上对模型进行微调,然后在剩余的三个epochs期间继续在目标数据上进行微调。在第二种情况下,我们将历时次数增加了一倍,并在六个历时内同时在域外数据和目标数据上对模型进行微调。
以 F1 表示的结果见图 3。图中使用了以下约定。最佳基线 - 数据集的最佳基线结果。
Full target (6 ep) - 在完整目标语料库上进行微调。Not target_eq (6 ep) - 在域外数据上进行微调。目标(6 ep)–对部分目标语料进行微调。Not target_eq (3 ep) → Target (3 ep) - 对域外数据进行三次微调,然后对目标语料库的一部分进行三次微调。Not target_eq (6 ep) → Target (6 ep) - 对混合域外数据进行六次微调,然后对目标语料库的一部分进行六次微调。就 PubMed 而言,最佳基线结果与 Full target (6 ep) 的线条相吻合。
在目标样本量较小(≈ 最多 300 个文本)的情况下,进行两阶段微调的模型优于仅在目标语料库上进行微调的模型。因此,使用域外语料库可以减少目标数据的使用量。对于某些语料库(Krapivin-A、PubMed 和 DUC-2001),以两阶段方式微调的模型优于在完整目标语料库上微调的模型。对于 Krapivin-A,使用 59% 的目标训练集获得的 F1 分数超过了全部目标分数。对于 PubMed 和 DUC-2001,我们分别用了 43% 和 46%。对于其他具有较大完整目标语料库规模的语料库,我们在本实验中没有观察到超过完整目标语料库 F1 的结果。
7.Conclusion
我们探索了针对关键词生成任务进行微调的抽象文本摘要模型的鲁棒性。我们的实验基于 BART,这是一种基于变压器的去噪自动编码器,用于预训练 seq2seq 模型。我们在三个不同领域的六个语料库中研究了 BART 微调后在关键字生成方面的跨领域局限性。我们还研究了在少量训练数据的条件下,初步域外微调对提高模型性能的影响。
我们发现,对域外数据进行初步微调可以提高关键字生成的性能,并允许使用更少的目标数据。我们的研究结果补充了有关两阶段微调程序有效性的一系列结果,即首先在源域数据集上对基于转换器的模型进行微调,然后再使用焦油域数据集进行微调。例如,针对文本分类[34,47] 和命名实体识别[33,40] 所做的类似研究表明,两步训练程序的效果优于仅在目标语料库上进行微调的基线模型。我们未来的研究将侧重于从高资源语言(例如英语)到其他语言(尤其是俄语)的迁移学习。



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









