







Experimental CBIR Systems
- Classification of CBIR Systems
- IBM's Query by Image and Video Content System "QBIC"
- Internet CBIR Systems "WebSEEk" and "VisualSEEk"
- Photobook: Tools for Content-Based Manipulation of Image DataBases
- References
Classification of CBIR Systems
The rich collection of visual information on the Web is integrated with a vast variety of nonvisual information, is highly distributed, minimally indexed, and schemaless. Although there exist many popular search engines for nonvisual information, visual information search engines are mostly under development and experimental investigation and typically are still text-oriented, i.e. with indexing based on texts associated with images: see e.g. a comprehensive review of image search engines prepared recently by British Technical Advisory Service for Images. Additional surveys and a number of links to experimental and commercial CBIR systems can be found on the web page on CBIR developed in the University of Bonn, Germany. At present, only a few experimental CBIR systems have been used in application multimedia domains such as libraries, museums, scientific data archives, photo stock houses, and Web search engines.
Because only colours, textures, shapes, motions, and other low-level features combined with text and other related information are used to query multimedia databases, the search is approximate and requires a visual assessment of computed similarity. The items returned at the top of the list of query results have the greatest similarity with the query input. But these items rarely make an "exact" match to the attributes specified in the query (Chang e.a., 1997).
Today's CBIR systems use also direct input from users and supporting text data to refine indexing visual information. In particular, video icons can be manually generated to annotate specific objects or events in videos, or a text index can be derived from captions and transcripts of broadcast video for retrieving news video. Through learning from user interaction, visual features can be mapped to semantic classes, as it organised in the FourEyes system (MIT Media Lab., USA).
The systems can be classified using the following criteria (Chang e.a., 1997):
- Level of automation of feature extraction and index generation
- Level of integration of multimedia modalities
- Level of adaptability to the needs of users and applications
- Level of abstraction in which content is indexed
- Level of generality of visual information domain
- Level of automation of the database collection
- Abilities to semantically categorise visual information
- Abilities to process compressed visual information
Level of Automation
Interactive content-based visual querying is based on the quantitative features of images and videos extracted and indexed by the system. The CBIR systems differ in degree of automation of feature extraction and index generation. While the low-level features, such as colours, textures, shapes, and motions, are typically extracted by automatic methods, generation of higher-level semantic indexes usually requires human input and/or system training.
In a semiautomatic system the user selects manually image objects and features which are then used by the system for generating the feature indexes.
Level of Integration
Multimedia content involves many information modalities, including images, video, graphics, text, and audio. The CBIR systems differ in how the multiple modalities are treated. Typically, they are indexed independently. Although integration of multiple modalities is under investigation in a few experimental systems, it is not yet fully exploited.
Level of Adaptability
Most systems use a static set of previously extracted features included into image metadata and indexes. The features are selected by the system designer on the basis of trade-offs in indexing costs and search functionalities. However, abilities to dynamically extract and index features are needed to adapt the system to the subjective nature of visual search and to the changing needs of users and applications.Level of Abstraction
The systems differ in the level of abstraction in which content is indexed. Images may be indexed at the low-level feature level (colour, texture, shape), object level (moving foreground item), syntactic level (video shot), and high-level semantic level (image subject). Automatic indexing exploits mostly low-level features, while higher-level indexes are generated manually. Interaction among different levels is still the unsolved problem.
Level of Generality
The CBIR systems differ as to generality of the domain of visual information. Special feature sets can be used to incorporate specific domain knowledge, such as for medical and remote-sensing applications. General systems have the goal of indexing unconstrained visual information, such as that on the Web.
Automation of Data Collection
The systems differ in how new visual information is added to the system's database. A dynamic CBIR system may collect information by software robots, such that automatically traverse the Web. In other systems, e.g. online news archives and photo stock houses, visual information is added manually.
Data Categorisation
The systems differ in how easily visual information is categorised into semantic classes. As visual information repositories have grown, interfaces allowing to navigate through semantic classes of visual information become very useful. However, effective image or video categorisation schemes are not yet developed.
Compressed Data Processing
If feature extraction is performed directly on compressed images and videos, then expensive decompression of the data can be avoided. For compression standards, such as JPEG or MPEG, computation of features can be developed in the compressed domain.
IBM's Query by Image Content System "QBIC(TM)"
| A picture is worth a thousand words -- or in this case, a thousand keywords -- especially when searching the Web for a display of men's shirts, bathroom wallpaper or Japanese prints. When keywords alone cannot locate that special "something" to fit a specific taste, users can turn to IBM's patented Query By Image Content or QBIC, a new search engine that sorts through database images according to colors, textures, shapes, sizes and their positions. [http://www.research.ibm.com/topics/popups/deep/manage/html/qbic.html] |
The QBIC system developed in IBM Almaden Research Center (USA) was the first CBIR system explored feature-based image and video retrieval (Flickner e.a., 1995). Today it is commercially distributed by IBM Corporation and used in several international projects involving very large multimedia databases, in particular, the digital collection of the Russian State Hermitage Museum. The Hermitage website uses the QBIC engine for searching digital archives of world-famous art that constitute the Digital Collection, a new virtual gallery of high-resolution artwork images created in collaboration with IBM Corporation. The QBIC engine locates artwork using visual tools, e.g. by selecting colours from a palette or by sketching shapes on a canvas.

Artwork representation in the QBIC engine for the Hermitage Museum.
The search may also use a simple browsing of specific art categories such as paintings, prints and drawings, sculptures, ceramics and porcelain, arms and armor, and so on. The Advanced Search allows find artwork by artist, title, or subject, or by certain attributes such as style, genre, theme, or date. The QBIC helps to refine results of browsing or advanced search by requesting all artwork with comparable visual attributes.

Colour search inteface in QBIC.
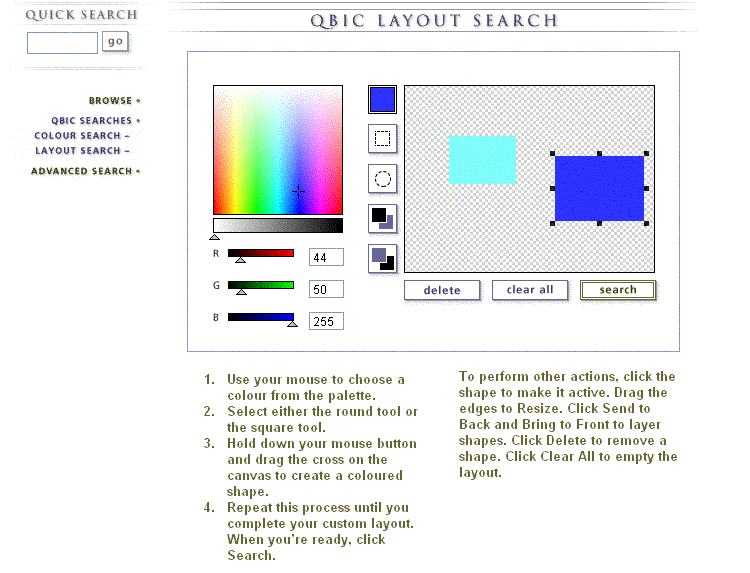
Layouth inteface in QBIC.
The QBIC prototype system (Lee, Barber, & Niblack, 1994; Flickner e.a., 1995) considers two main data types: scenes and objects. A scene is a colour image or single video frame, and an object is a part of a scene (each scene has zero or more objects). Objects are outlined in the image manually, by the user, and each image and object are characterised by colour and texture features. Image or object colour is described with a vector of average colour coordinates and a colour histogram with 64 or 256 elements of the quantised colour space. Texture is described with the three modified Tamura's features (the coarseness, contrast, and directionality). In addition to these features, the prototype exploits the shape descriptor combining moments, heuristic shape features, parametric curves represented by spline control points, first and second derivatives of these curves, and specific distance between the curves (Hausdorff dostance).
For a given database, all objects in the images have to be outlined and features of all images and objects have to be computed at the stage of preparing the database to the search. Then queries can be processed. Each query can be based on objects, entire scenes, or a combination of both.
- An object-based query requests images containing objects with certain features such as colour percentage, colour layout, or/and texture.
- A scene-based query retrieves full scenes with certain features. Because the objects need not be outlined, the query interface is simpler.
To match colour histograms X and Y, a quadratic distance (X - Y)TS(X - Y) is used. Here, S is a symmetric colour dissimilarity matrix with the components S(i,j) indicating the dissimilarity of the colours i and j in the histogram. The distance accounts for both the perceptual differences between the colours and the different amounts of each particular colour.
For data retrieval, the precomputed stored features are compared to a given query in order to determine which images match it. To effectively querying a large database, both filtering and R-trees are used to index the feature vectors in the database in such a way as to allow the 64-element colour histogram to be efficiently accessed by a filtering step using the 3D average colour indexed by an R-tree, and allow the 20-dimensional moment-based shape vector to be transformed to a low (e.g., 3D) space where an R-tree index can be applied. The transformation is based on the principal component analysis.
Internet CBIR Systems "WebSEEk" and "VisualSEEk"
A semiautomatic engine WebSEEk developed in the Columbia University (New York, USA) had the goals of collecting, analysing, indexing, and searching for the Web's visual information (Chang e.a., 1997). WebSEEk collects the Web's distributed visual information using autonomous software Web robots (called "spiders"). The system aggregates and analyses content of collected information, and stores the image metadata, visual summaries, and pointers to the visual information. This allows WebSEEk to act as a server for Web querying and retrieving of indexed visual information.
Web spiders detect images and videos by mapping the file name extensions to the object types in accord to the MIME Multipurpose Internet Mail Extensions labels (such as .gif, .jpg, .qt, .mpg, and .avi). Experiments during three months in 1996 showed that about 85% of the collected visual information consists of colour images, 13.5% contains grey-scale or black-and-white images, and 1.5% contains video sequences. In 1996 - 1997 the system has indexed about 650,000 images and 10,000 videos.
For retrieving visual information, WebSEEk combines multimedia metadata with feature extraction and indexing. Because most online visual information is accompanied by related text information, WebSEEk extracts key words for direct indexing and classification of visual content from Web URL addresses and HTML tags associated with the images and videos. Due to a very large indexed database and the need of achieving a fast content-based query response (in less than two seconds), WebSEEk uses only very simple colour features for indexing (namely, binary colour sets and colour histograms). The search is based on a single colour specified by the user.

Front page of WebSEEk with the list of image categories to search for.
Because visual query is a repetitive interactive process, small-size reduced versions of images or video are used at all intermediate steps, except from the final one. The reduced image versions are built in advance or during the search. Automatic segmentation of shots and selection of key frames is applied to the videos.
To facilitate user-friendly information retrieval, WebSEEk exploits semantic navigation within a clearly defined hierarchical semantic space of more than 2,000 classes.This multilevel hierarchy is constructed semiautomatically. Initially, the basic classes and their hierarchy is built with human assistance. Then, periodically, additional candidate classes are suggested automatically and verified with human assistance. Due to ambiguity of many textual terms, automatic subject classification based on keywords cannot be perfect. However, experiments with WebSEEk have shown that more than 90% of images and videos are correctly assigned to semantic classes.
In 1996 - 1997, the system served thousands of queries daily. It is worthy to note that subject-based queries were the most popular (53.4% of all queries for images and videos), while basic content-based queries by colour distribution and more advanced VisualSEEk's content-based queries constituted only 9.2% and 0.4% of all queries, respectively. Partly this is influences by very limited content-based retrieval functions in this system.
The content-based image/video retrieval system "VisualSEEk", developed in the Columbia University upon the previous WebSEEk having only limited functionality, retrieves visual information that best matches colour contents and the spatial layout of colour regions specified by the query (Smith & Chang, 1995). The interface allows also to assign in future texture, shape, motion, and embedded text to query elements.
The elementary unit of query is a spatial region called "point of denotation" (POD). PODs refer to areas within the images that may possess specific colour, texture, and shape features. For video, the PODs may also possess a motion property. The conceptual query image includes up to three PODs. Each POD can have some or all of the properties of colour, texture, shape, and motion.
The PODs can be positioned by the user in a perticular spatial layout, the positions functioning as grounds for obtaining matches to other images in the database. The spatial or colour match can be exact, best, or none. The user can also assign for each POD a spatial region over which the POD is valid (e.g., to search for only the matches in a certain area of the database images).
Photobook: Tools for Content-Based Manipulation of Image Data Bases
Photobook developed in the MIT Media Laboratory Pentland, Picard, & Sclaroff, 1994; Minka, 1995) performs queries based on features associated with images. The features relate to particular models fitted to each image. Commonly the models involve colour, texture, and shape, although features from any model may be used (e.g., results of face recognition). Features are compared using one out of the library of matching algorithms such as Euclidean or Mahalanobis distance, Kullback-Leibler divergence, vector space angle (correlation), histogram distance, peaks in Fourier space, wavelet tree distance, or user-defined algorithms, as well as any linear combination of these.
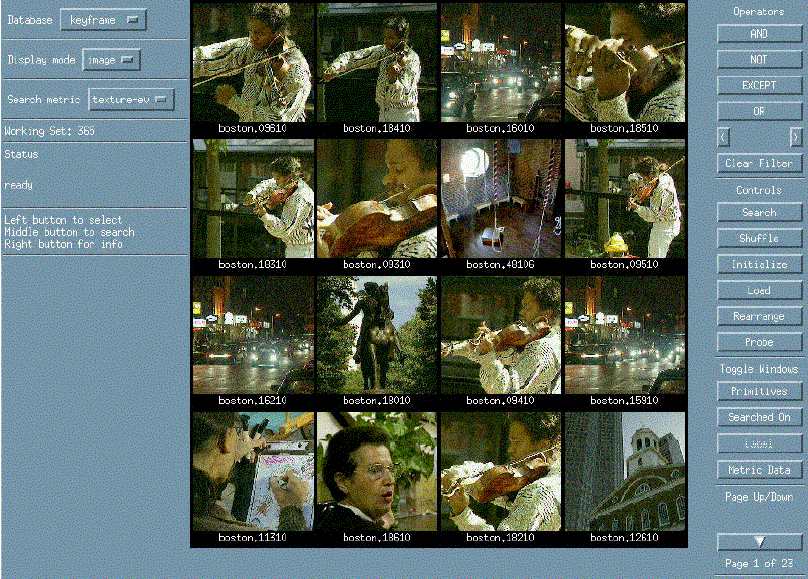
Example of a search in Photobook (Minka, 1995): the user queried for images similar to the one in the upper left, using an eigenpicture space (the 1D ordering is displayed in 2D raster scans).
No image model can be optimal for all tasks, and it is rarely clear which models are appropriate for a task. Photobook includes FourEyes, an interactive learning subsystem that selects and combines models based on positive and negative examples from the user. This makes Photobook different from other CBIR systems such as QBIC, VisualSEEk, or Virage, which all assist little in suggesting a proper model for a particular search. Due to using machine learning abilities of FourEyes subsystem, Photobook learns to select and combine features to satisfy a query. This learning is continuous, and each retrieval session adds to improvement of the system's performance. The main goal of FourEyes is to learn how to select and combine similarity measures, rather than design and understand them (Minka, 1995). The data is first organised by grouping. The grouping provides a means to involve different similarity measures and can be produced manually, with due account of colour /texture models, optical flow information and so on:

Hierarchical clustering with a Markovian simultaneous autoregressive model of textures (Minka, 1995).
FourEyes uses both intra-image (or within-image) groupings and inter-image (or across-image) groupings composed of these. In the example below, let grouping "a" in a single image contain "b", which in turn contains "c". In the feature space these groupings are considered individually, so that the resulting clustering may specify that "a" looks more similar to "b" rather than to "c":
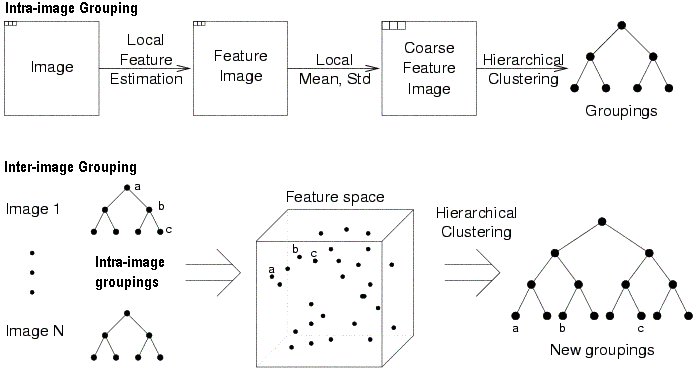
Intra - and inter-image groupings (Minka, 1995).
This approach allows the user to specify the queries by corresponding examples and relate most appropriate similarity measures to different parts of the query. In the example below the user has selected (by mouse-clicking) several patches of sky in the two right images and assigned them the label "sky".

The FourEyes computer-assisted annotation tool(Minka, 1995).
Intra-image grouping by similarity allows FourEyes to grow these labeled patches into larger "sky" regions indicated by cross-hatching. Inter-image grouping allowes FourEyes to also place tentative labels on the two left images. The right-hand menu buttons permit the user to control which sets of groupings are available to the learner, e.g. building, grass, leaves, person, etc. By pointing out the false labels, the user provides the negative examples to refine the decision rule.

Natural scenes with their groundtruth labelling (Minka, 1995).

Natural scenes with their groundtruth labelling (Minka, 1995).
Photobook with FourEyes learner uses three decision strategies:
- Set covering (SC) that approximates the smallest union of sets in the feature space which covers all of the positive examples and none of the negative ones.
- Decision list (DL) choosing sets which either include positive but no negative examples or include negative but no positive examples.
- Decision tree (DT) making the best division of examples into two parts, each of which may require further division.
References
- R. Blumberg and P. Hughes. Visual realism and interactivity for the Internet. Proc. IEEE Computer Society Conf. (Compcon'97), 23-26 Feb. 1997, pp. 269 - 273.
- R. R. Buckley and G. B. Beretta. Color Imaging on the Internet. NIP-16: Vancouver, 2000.
- G. Chang, M. J. Healey , J. A. M. McHugh, and J. T. L. Wang. Mining the World Wide Web: An Information Search Approach. Kluwer Academic: Norwell, 2001.
- S.-F. Chang, J. R. Smith, M. Beigi, and A. Benitez. Visual information retrieval from large distributed online repositories. Communications of the ACM, vol. 40, no. 12, 1997, 63 - 71.
- V. Della Mea, V. Roberto, and C. A. Beltrami. Visualization issues in Telepathology: the role of the Internet Imaging Protocol. Proc. 5th Int. Conf. Information Visualization, 2001, pp. 717 - 722.
- A.Hanjalic, G. C. Langelaar, P. M. B. van Roosmalen, J. Biemond, and R. Lagendijk. Image and Video Data Bases: Restoration, Watermarking and Retrieval. Elsevier Science: Amsterdam, 2000.
- M. Flickner, H. Sawheney, W. Niblack, J. Ashley, Q. Huang, B. Dom, M. Gorkani, J. Hafner, D. Lee, D. Petkovic, D. Steele, and P. Yanker. Query by image and video content: the QBIC system. IEEE Computer, vol. 28, no. 9, 1995, 23 - 32.
- D. Lee, R. Barber, and W. Niblack. Indexing for complex queries on a query-by-content image database. Proc. 12th IAPR Int. Conf. on Pattern Recognition, Jerusalem, Israel, 9-13 Oct. 1994. Vol.1: Computer Vision & Image Processing. IEEE Computer Soc. Press: Los Alamitos, 1994, pp. 142 - 146.
- T. Minka. An Image Browser that Learns from User Interaction. MIT Media Lab. Tech. Report 365, 1995.
- A. Pentland, R. W. Pentland, and S. Sclaroff. Photobook: tools for content-based manipulation of image databases. Proc. SPIE Conf. Storage and Retrieval of Image & Video Databases II, San Jose, Calif., Feb. 1994, SPIE Press, 1994, pp. 34 - 47.
- S. M. Rahman (Ed.). Interactive Multimedia Systems. IRM Press: Hershey, 2002.
- T. K. Shih. Distributed Multimedia Databases: Techniques & Applications. Idea Group Publishing: Hershey, 2002.
- J. R. Smith and S.-F. Chang. VisualSEEk: A Content-based Image/Video Retrieval System.. System Report and User's Manual, version 1.0 beta. Columbia Univ. El. Eng. Dept and Center fot Telecommunications Research, New York, N.Y., December 1995.
- A. W. M. Smeulders and R. Jain (Eds.). Image Databases and Multimedia Search. World Scientific: Singapore, 1997.
- M. Stokes, M. Anderson, S. Chandrasekar, R. Motta. A standard default colot space for the Internet - sRGB. Version 1.10, Nov. 5, 1996. ICC, 1996.
Return to the general table of contents
from: https://www.cs.auckland.ac.nz/courses/compsci708s1c/lectures/Glect-html/topic6c708FSC.htm















 6万+
6万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









