







目录
教程来源
极客兔兔——7天用Go从零实现分布式缓存GeeCache
目的
模仿groupcache(Go 语言版的 memcached)实现一个分布式缓存中间件。
思路
-
设计一个分布式缓存系统,需要考虑资源控制、淘汰策略、并发、分布式节点通信等各个方面的问题。而且,针对不同的应用场景,还需要在不同的特性之间权衡,例如,是否需要支持缓存更新?还是假定缓存在淘汰之前是不允许改变的。不同的权衡对应着不同的实现。
-
groupcache 是 Go 语言版的 memcached,目的是在某些特定场合替代 memcached。groupcache 的作者也是 memcached 的作者。无论是了解单机缓存还是分布式缓存,深入学习这个库的实现都是非常有意义的。
-
支持特性有:
- 单机缓存和基于 HTTP 的分布式缓存
- 最近最少访问(Least Recently Used, LRU) 缓存策略
- 使用 Go 锁机制防止缓存击穿
- 使用一致性哈希选择节点,实现负载均衡
- 使用 protobuf 优化节点间二进制通信
…
缓存淘汰(失效)算法:FIFO,LFU 和 LRU
FIFO(First In First Out)
- 先进先出,也就是淘汰缓存中最老(最早添加)的记录。
- FIFO 认为,最早添加的记录,其不再被使用的可能性比刚添加的可能性大。
- 这种算法的实现也非常简单,创建一个队列,新增记录添加到队尾,每次内存不够时,淘汰队首。但是很多场景下,部分记录虽然是最早添加但也最常被访问,而不得不因为呆的时间太长而被淘汰。这类数据会被频繁地添加进缓存,又被淘汰出去,导致缓存命中率降低。
LFU(Least Frequently Used)
- 最少使用,也就是淘汰缓存中访问频率最低的记录。
- LFU 认为,如果数据过去被访问多次,那么将来被访问的频率也更高。
- LFU 的实现需要维护一个按照访问次数排序的队列,每次访问,访问次数加1,队列重新排序,淘汰时选择访问次数最少的即可。
- LFU 算法的命中率是比较高的,但缺点也非常明显,维护每个记录的访问次数,对内存的消耗是很高的;另外,如果数据的访问模式发生变化,LFU 需要较长的时间去适应,也就是说 LFU 算法受历史数据的影响比较大。例如某个数据历史上访问次数奇高,但在某个时间点之后几乎不再被访问,但因为历史访问次数过高,而迟迟不能被淘汰。
LRU(Least Recently Used)
- 最近最少使用,相对于仅考虑时间因素的 FIFO 和仅考虑访问频率的 LFU,LRU 算法可以认为是相对平衡的一种淘汰算法。
- LRU 认为,如果数据最近被访问过,那么将来被访问的概率也会更高。
- LRU 算法的实现非常简单,维护一个队列,如果某条记录被访问了,则移动到队尾,那么队首则是最近最少访问的数据,淘汰该条记录即可。

这张图很好地表示了 LRU 算法最核心的 2 个数据结构:
- 蓝色的是字典(map),存储键和值的映射关系。这样根据某个键(key)查找对应的值(value)的复杂是O(1),在字典中插入一条记录的复杂度也是O(1)。
- 红色的是双向链表(double linked list)实现的队列。将所有的值放到双向链表中,这样,当访问到某个值时,将其移动到队尾的复杂度是O(1),在队尾新增一条记录以及删除一条记录的复杂度均为O(1)。
实现Lru
接下来创建一个包含字典和双向链表的结构体类型 Cache,方便实现后续的增删查改操作。
package Cache
import "container/list"
// Callback 回调函数
type Callback func(key string, value Value)
// Cache LRU缓存
type Cache struct {
// maxBytes 最大允许使用内存
maxBytes int64
// currentBytes 当前使用内存
currentBytes int64
// linker 底层链表
linker *list.List
// cache 底层缓存
cache map[string]*list.Element
// onEvicted 某个key被移除后的回调函数
onEvicted Callback
}
// Value 返回值所占用的内存大小
type Value interface {
Len() int
}
// entry linker的node
type entry struct {
key string
value Value
}
func NewCache(maxBytes int64, onEvicted Callback) *Cache {
return &Cache{
maxBytes: maxBytes,
linker: list.New(),
cache: make(map[string]*list.Element),
onEvicted: onEvicted,
}
}
- 直接使用 Go 语言标准库实现的双向链表list.List。
- 字典的定义是 map[string]*list.Element,键是字符串,值是双向链表中对应节点的指针。

- maxBytes 是允许使用的最大内存,nbytes 是当前已使用的内存,OnEvicted 是某条记录被移除时的回调函数,可以为 nil。
- 键值对 entry 是双向链表节点的数据类型,在链表中仍保存每个值对应的 key 的好处在于,淘汰队首节点时,需要用 key 从字典中删除对应的映射。
- 为了通用性,允许值是实现了 Value 接口的任意类型,该接口只包含了一个方法
Len() int,用于返回值所占用的内存大小。(只要可以调用len函数的类型,都实现了len接口) - 方便实例化 Cache,实现 New() 函数。
查找功能
查找主要有 2 个步骤,第一步是从字典中找到对应的双向链表的节点,第二步,将该节点移动到队尾。
// Get 查询key
func (c *Cache) Get(key string) (Value, bool) {
if val, ok := c.cache[key]; ok {
// 移到队尾部
c.linker.MoveToBack(val)
// 将list.Element.Value类型断言为entry
kv := val.Value.(*entry)
return kv.value, true
}
return nil, false
}
- 如果键对应的链表节点存在,则将对应节点移动到队尾,并返回查找到的值。
c.ll.MoveToBack,即将链表中的节点 ele 移动到队尾。
删除
这里的删除,实际上是缓存淘汰。即移除最近最少访问的节点(队首)。
// RemoveOldest OnEvicted: onEvicted
func (c *Cache) RemoveOldest() {
// 返回队首
ele := c.linker.Front()
if ele != nil {
// 从链表中删除元素
c.linker.Remove(ele)
kv := ele.Value.(*entry)
// 从cache中将key淘汰
delete(c.cache, kv.key)
// 修改当前cache占用大小
// 即减去一个k,一个v的大小
c.currentBytes -= int64(len(kv.key)) + int64(kv.value.Len())
// 如果用户定义的回调函数不为空则执行一下
if c.onEvicted != nil {
c.onEvicted(kv.key, kv.value)
}
}
}
新增/修改
// Add adds a value to the cache.
func (c *Cache) Add(key string, value Value) {
if ele, ok := c.cache[key]; ok {
// 修改节点
// 移动到队尾
c.linker.MoveToBack(ele)
// 获取entry(key,val)
kv := ele.Value.(*entry)
// 当前内存占用为旧val长度-新val长度
c.currentBytes += int64(value.Len()) - int64(kv.value.Len())
// 覆盖旧value
kv.value = value
} else {
// 从队尾加入
ele := c.linker.PushBack(&entry{key, value})
c.cache[key] = ele
// 增加一个key和一个val的长度
c.currentBytes += int64(len(key)) + int64(value.Len())
}
// 如果超过限制,则进行内存淘汰
for c.maxBytes != 0 && c.maxBytes < c.currentBytes {
c.RemoveOldest()
}
}
最后,为了方便测试,实现 Len() 用来获取添加了多少条数据。
// Len the number of cache entries
func (c *Cache) Len()int {
return c.linker.Len()
}
测试
type String string
func (s String) Len() int {
return len(s)
}
func main() {
c := Cache.NewCache(16, func(key string, value Cache.Value) {
fmt.Println(key, value)
})
for i := 0; i < 10; i++ {
s := String("德玛西亚")
c.Add(fmt.Sprintf("name_%d", i), s)
fmt.Println(c)
}
}
单机并发缓存
- 使用 sync.Mutex 封装 LRU 的几个方法,使之支持并发的读写。
- 在这之前,抽象了一个只读数据结构
ByteView用来表示缓存值,是 GeeCache 主要的数据结构之一。
// ByteView 保存字节的不可变视图。
type ByteView struct {
b []byte
}
// Len returns the view's length
func (v ByteView) Len() int {
return len(v.b)
}
// clone 拷贝功能
func clone(b []byte) []byte {
c := make([]byte, len(b))
copy(c, b)
return c
}
// CloneViewToSlice 返回ByteView的一份拷贝
func (v ByteView) CloneViewToSlice() []byte {
return clone(v.b)
}
// String 实现string接口
func (v ByteView) String() string {
return string(v.b)
}
- ByteView 只有一个数据成员,
b []byte,b 将会存储真实的缓存值。选择 byte 类型是为了能够支持任意的数据类型的存储,例如字符串、图片等。 - 实现
Len() int方法,我们在 lru.Cache 的实现中,要求被缓存对象必须实现 Value 接口,即 Len() int 方法,返回其所占的内存大小。 - b 是只读的,使用
CloneViewToSlice()方法返回一个拷贝,防止缓存值被外部程序修改。
接下来就可以为 lru.Cache 添加并发特性了。
// cache 封装lru
type cache struct {
// 互斥锁
mu sync.RWMutex
// lru 封装的lru缓存
lru *lru.Cache
// cacheBytes 等价于maxBytes最大允许使用内存
cacheBytes int64
}
// add 封装了Add方法
func (c *cache) add(key string, value ByteView) {
c.mu.Lock()
defer c.mu.Unlock()
// 懒加载lru.Cache
if c.lru == nil {
c.lru = lru.NewCache(c.cacheBytes, nil)
}
c.lru.Add(key, value)
}
// get 封装了Get方法
func (c *cache) get(key string) (ByteView, bool) {
c.mu.RLock()
defer c.mu.RUnlock()
// 若未初始化就获取值则返回nil
if c.lru == nil {
return ByteView{}, false
}
if v, ok := c.lru.Get(key); ok {
// ByteView实现了Len接口
// 因此v类型断言为ByteView
return v.(ByteView), ok
}
return ByteView{}, false
}
- cache.go 的实现非常简单,实例化 lru,封装
get和add方法,并添加互斥锁 mu。 - 在 add 方法中,判断了 c.lru 是否为 nil,如果等于 nil 再创建实例。这种方法称之为延迟初始化(Lazy Initialization),一个对象的延迟初始化意味着该对象的创建将会延迟至第一次使用该对象时。主要用于提高性能,并减少程序内存要求。
主体结构 Group
Group 是 GeeCache 最核心的数据结构,负责与用户的交互,并且控制缓存值存储和获取的流程。
是
接收 key --> 检查是否被缓存 -----> 返回缓存值 ⑴
| 否 是
|-----> 是否应当从远程节点获取 -----> 与远程节点交互 --> 返回缓存值 ⑵
| 否
|-----> 调用`回调函数`,获取值并添加到缓存 --> 返回缓存值 ⑶
|--lru/
|--lru.go // lru 缓存淘汰策略
|--byteview.go // 缓存值的抽象与封装
|--cache.go // 并发控制
|--generalcache.go // 负责与外部交互,控制缓存存储和获取的主流程
回调 Getter
- 思考一下,如果缓存不存在,应从数据源(文件,数据库等)获取数据并添加到缓存中。GeeCache 是否应该支持多种数据源的配置呢?不应该,一是数据源的种类太多,没办法一一实现;二是扩展性不好。
- 如何从源头获取数据,应该是用户决定的事情,我们就把这件事交给用户好了。因此,我们设计了一个回调函数(callback),在缓存不存在时,调用这个函数,得到源数据。
// A Getter loads data for a key.
type Getter interface {
Get(key string) ([]byte, error)
}
// A GetterFunc implements Getter with a function.
type GetterFunc func(key string) ([]byte, error)
// Get implements Getter interface function
// 调用该接口的方法 f.Get(key string),实际上就是在调用匿名回调函数
func (f GetterFunc) Get(key string) ([]byte, error) {
return f(key)
}
- 定义接口 Getter 和 回调函数 Get(key string)([]byte, error),参数是 key,返回值是 []byte。
- 定义函数类型 GetterFunc,并实现 Getter 接口的 Get 方法。
- 函数类型实现某一个接口,称之为接口型函数,方便使用者在调用时既能够传入函数作为参数,也能够传入实现了该接口的结构体作为参数。(借助 GetterFunc 的类型转换,将一个匿名回调函数转换成了接口 f Getter。)
Group 的定义
- 一个 Group 可以认为是一个缓存的命名空间,每个 Group 拥有一个唯一的名称
name。比如可以创建三个 Group,缓存学生的成绩命名为scores,缓存学生信息的命名为 info,缓存学生课程的命名为 courses。 - 第二个属性是
getter Getter,即缓存未命中时获取源数据的回调(callback)。 - 第三个属性是
mainCache cache,即一开始实现的并发缓存。 - 构建函数
NewGroup用来实例化 Group,并且将 group 存储在全局变量groups中。 GetGroup用来特定名称的Group,这里使用了只读锁RLock(),因为不涉及任何冲突变量的写操作。
// Group 对cache封装
type Group struct {
// 当前组的名称
name string
getter Getter
// mainCache 底层缓存
mainCache cache
}
var (
mu sync.RWMutex
groups = make(map[string]*Group)
)
// NewGroup create a new instance of Group
func NewGroup(name string, cacheBytes int64, getter Getter) *Group {
if getter == nil {
panic("nil Getter")
}
mu.Lock()
defer mu.Unlock()
g := &Group{
name: name,
getter: getter,
// 使用封装后的cache
mainCache: cache{cacheBytes: cacheBytes},
}
groups[name] = g
return g
}
// GetGroup returns the named group previously created with NewGroup, or
// nil if there's no such group.
func GetGroup(name string) *Group {
mu.RLock()
defer mu.RUnlock()
g := groups[name]
return g
}
Group 的 Get 方法
// Get value for a key from cache
func (g *Group) Get(key string) (ByteView, error) {
if key == "" {
return ByteView{}, fmt.Errorf("key is required")
}
if v, ok := g.mainCache.get(key); ok {
log.Println("[GeeCache] hit")
return v, nil
}
// 从getter中获取数据
return g.loadFromGetter(key)
}
func (g *Group) loadFromGetter(key string) (ByteView, error) {
// 从getter中获取数据
bytes, err := g.getter.Get(key)
if err != nil {
return ByteView{}, err
}
// 返回获取到数据的copy
value := ByteView{b: clone(bytes)}
// 加入缓存
g.mainCache.add(key, value)
return value, nil
}
- Get 方法实现了上述所说的流程 ⑴ 和 ⑶。
- 流程 ⑴ :从 mainCache 中查找缓存,如果存在则返回缓存值。
- 流程 ⑶ :缓存不存在,则调用
loadFromGetter方法,loadFromGetter调用用户回调函数g.getter.Get()获取源数据,并且将源数据添加到缓存 mainCache 中(通过 populateCache 方法)
HTTP 服务端
- 分布式缓存需要实现节点间通信,建立基于 HTTP 的通信机制是比较常见和简单的做法。
- 如果一个节点启动了 HTTP 服务,那么这个节点就可以被其他节点访问。
首先创建一个结构体 HTTPPool,作为承载节点间 HTTP 通信的核心数据结构。
const defaultBasePath = "/_generalcache/"
// HTTPPool implements PeerPicker for a pool of HTTP peers.
type HTTPPool struct {
// this peer's base URL, e.g. "https://example.net:8000"
self string
basePath string
}
// NewHTTPPool initializes an HTTP pool of peers.
func NewHTTPPool(self string) *HTTPPool {
return &HTTPPool{
self: self,
basePath: defaultBasePath,
}
}
- HTTPPool 只有 2 个参数,一个是 self,用来记录自己的地址,包括主机名/IP 和端口。
- 另一个是 basePath,作为节点间通讯地址的前缀,默认是 /_geecache/,那么 http://example.com/_geecache/ 开头的请求,就用于节点间的访问。因为一个主机上还可能承载其他的服务,加一段 Path 是一个好习惯。比如,大部分网站的 API 接口,一般以
/api作为前缀。
接下来,实现最为核心的 ServeHTTP 方法:
// Log info with server name
func (p *HTTPPool) Log(format string, v ...interface{}) {
log.Printf("[Server %s] %s", p.self, fmt.Sprintf(format, v...))
}
// ServeHTTP handle all http requests
func (p *HTTPPool) ServeHTTP(w http.ResponseWriter, r *http.Request) {
if !strings.HasPrefix(r.URL.Path, p.basePath) {
panic("HTTPPool serving unexpected path: " + r.URL.Path)
}
p.Log("%s %s", r.Method, r.URL.Path)
// /<basepath>/<groupname>/<key> required
parts := strings.SplitN(r.URL.Path[len(p.basePath):], "/", 2)
if len(parts) != 2 {
http.Error(w, "bad request", http.StatusBadRequest)
return
}
// 根据切片获取group和key信息
groupName := parts[0]
key := parts[1]
// 获取group
group := GetGroup(groupName)
if group == nil {
http.Error(w, "no such group: "+groupName, http.StatusNotFound)
return
}
// 获取val
view, err := group.Get(key)
if err != nil {
http.Error(w, err.Error(), http.StatusInternalServerError)
return
}
// 返回响应
w.Header().Set("Content-Type", "application/octet-stream")
// 写入val
_, _ = w.Write(view.ByteSlice())
}
- ServeHTTP 的实现逻辑是比较简单的,首先判断访问路径的前缀是否是 basePath,不是返回错误。
- 我们约定访问路径格式为
/<basepath>/<groupname>/<key>,通过 groupname 得到 group 实例,再使用 group.Get(key) 获取缓存数据。 - 最终使用 w.Write() 将缓存值作为 httpResponse 的 body 返回。
自测
var db = map[string]string{
"Tom": "630",
"Jack": "589",
"Sam": "567",
}
func main() {
// 初始化一个group
// 并绑定getter函数
Cache.NewGroup("test", 1<<10, Cache.GetterFunc(
func(key string) ([]byte, error) {
log.Println("[SlowDB] search key", key)
if v, ok := db[key]; ok {
return []byte(v), nil
}
return nil, fmt.Errorf("%s not exist", key)
}))
addr := "localhost:9999"
peers := Cache.NewHTTPPool(addr)
log.Println("geecache is running at", addr)
log.Fatal(http.ListenAndServe(addr, peers))
}
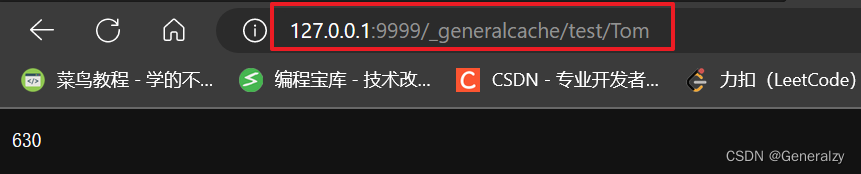
访问:http://127.0.0.1:9999/_generalcache/test/1
响应:1 not exist
访问:http://127.0.0.1:9999/_generalcache/test/Tom
响应:630
一致性哈希(hash)
Why一致性哈希
我该访问谁?
-
对于分布式缓存来说,当一个节点接收到请求,如果该节点并没有存储缓存值,那么它面临的难题是,从谁那获取数据?自己,还是节点1, 2, 3, 4… 。假设包括自己在内一共有 10 个节点,当一个节点接收到请求时,随机选择一个节点,由该节点从数据源获取数据。
-
假设第一次随机选取了节点 1 ,节点 1 从数据源获取到数据的同时缓存该数据;那第二次,只有 1/10 的可能性再次选择节点 1, 有 9/10 的概率选择了其他节点,如果选择了其他节点,就意味着需要再一次从数据源获取数据,一般来说,这个操作是很耗时的。这样做,一是缓存效率低,二是各个节点上存储着相同的数据,浪费了大量的存储空间。
那有什么办法,对于给定的 key,每一次都选择同一个节点呢?使用 hash 算法也能够做到这一点。那把 key 的每一个字符的 ASCII 码加起来,再除以 10 取余数可以吗?当然可以,这可以认为是自定义的 hash 算法。

从上面的图可以看到,任意一个节点任意时刻请求查找键 Tom 对应的值,都会分配给节点 2,有效地解决了上述的问题。
节点数量变化了怎么办?
-
简单求取 Hash 值解决了缓存性能的问题,但是没有考虑节点数量变化的场景。假设,移除了其中一台节点,只剩下 9 个,那么之前 hash(key) % 10 变成了 hash(key) % 9,也就意味着几乎缓存值对应的节点都发生了改变。即几乎所有的缓存值都失效了。节点在接收到对应的请求时,均需要重新去数据源获取数据,容易引起 缓存雪崩。
缓存雪崩:缓存在同一时刻全部失效,造成瞬时DB请求量大、压力骤增,引起雪崩。常因为缓存服务器宕机,或缓存设置了相同的过期时间引起。 -
一致性哈希算法可以解决上述问题。
一致性哈希
什么是一致性 hash 算法
一致性哈希算法也是使用取模的方法,但是取模算法是对服务器的数量进行取模,而一致性哈希算法是对 2^32 取模,具体步骤如下:
- 步骤一:一致性哈希算法将整个哈希值空间按照顺时针方向组织成一个虚拟的圆环,称为
Hash 环; - 步骤二:接着将各个服务器使用 Hash 函数进行哈希,具体可以选择服务器的
IP或主机名作为关键字进行哈希,从而确定每台机器在哈希环上的位置 - 步骤三:最后使用算法定位数据访问到相应服务器:将数据key使用相同的函数Hash计算出哈希值,并确定此数据在环上的位置,从此位置沿环顺时针寻找,第一台遇到的服务器就是其应该定位到的服务器
算法原理
一致性哈希算法将 key 映射到 2^32 的空间中,将这个数字首尾相连,形成一个环。
- 计算节点/机器(通常使用节点的名称、编号和 IP 地址)的哈希值,放置在环上,
哈希算法:hash(服务器的IP) % 2^32。 - 计算 key 的哈希值,放置在环上,顺时针寻找到的
第一个节点,就是应选取的节点/机器。
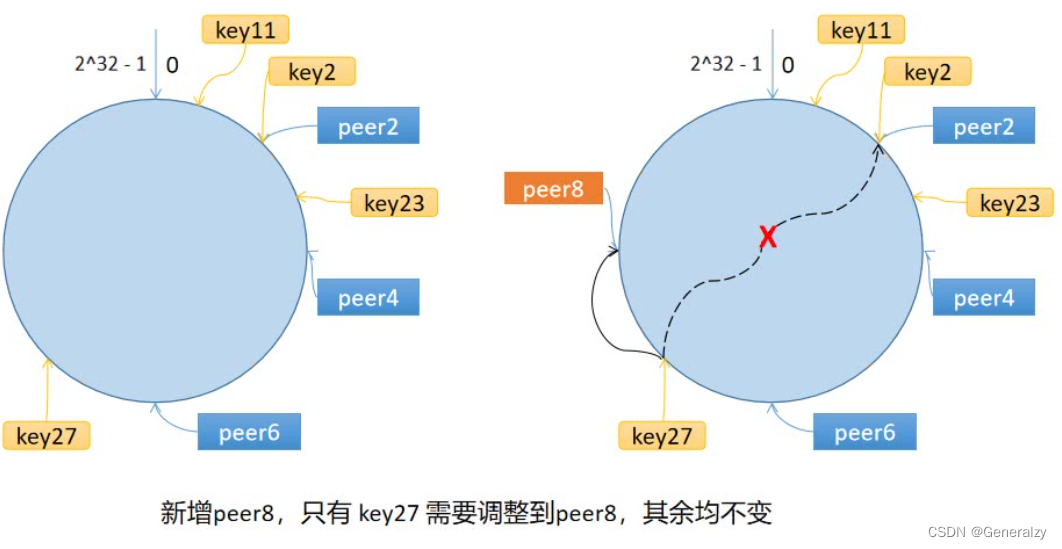
环上有 peer2,peer4,peer6 三个节点,key11,key2,key27 均映射到 peer2,key23 映射到 peer4。此时,如果新增节点/机器 peer8,假设它新增位置如图所示,那么只有 key27 从 peer2 调整到 peer8,其余的映射均没有发生改变。
也就是说,一致性哈希算法,在新增/删除节点时,只需要重新定位该节点附近的一小部分数据,而不需要重新定位所有的节点,这就解决了上述的问题。
数据倾斜问题
如果服务器的节点过少,容易引起 key 的倾斜。例如上面例子中的 peer2,peer4,peer6 分布在环的上半部分,下半部分是空的。那么映射到环下半部分的 key 都会被分配给 peer2,key 过度向 peer2 倾斜,缓存节点间负载不均。
为了解决这个问题,引入了虚拟节点的概念,一个真实节点对应多个虚拟节点。
假设 1 个真实节点对应 3 个虚拟节点,那么 peer1 对应的虚拟节点是 peer1-1、 peer1-2、 peer1-3(通常以添加编号的方式实现),其余节点也以相同的方式操作。
- 第一步,计算虚拟节点的 Hash 值,放置在环上。
- 第二步,计算 key 的 Hash 值,在环上顺时针寻找到应选取的虚拟节点,例如是 peer2-1,那么就对应真实节点 peer2。
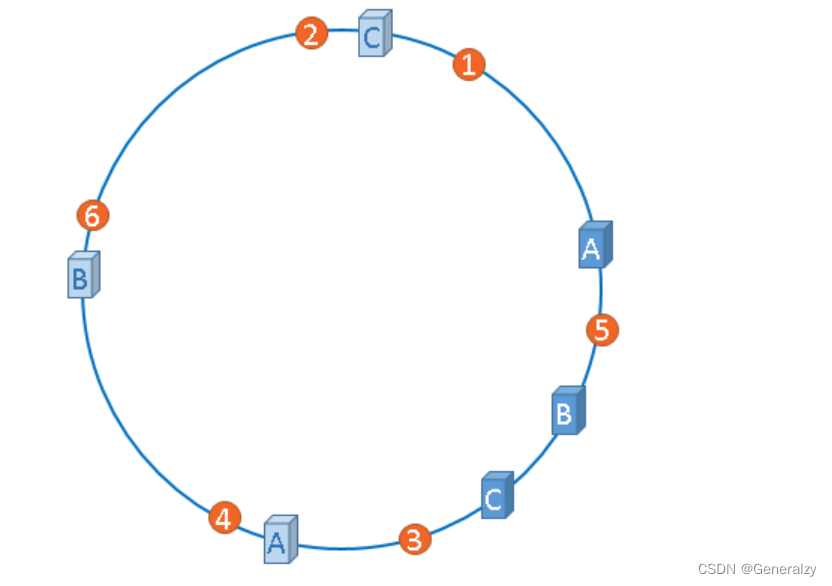
如上图,(A-1,A-2),(B-1,B-2),(C-1,C-2),
虚拟节点扩充了节点的数量,解决了节点较少的情况下数据容易倾斜的问题。而且代价非常小,只需要增加一个字典(map)维护真实节点与虚拟节点的映射关系即可。
Go语言实现
- 定义了函数类型 Hash,采取依赖注入的方式,允许用于替换成自定义的 Hash 函数,也方便测试时替换,默认为
crc32.ChecksumIEEE算法。 - Map 是一致性哈希算法的主数据结构,包含 4 个成员变量:Hash 函数 hash;虚拟节点倍数 replicas;哈希环 keys;虚拟节点与真实节点的映射表 hashMap,键是虚拟节点的哈希值,值是真实节点的名称。
- 构造函数 New() 允许自定义虚拟节点倍数和 Hash 函数。
// Hash maps bytes to uint32
type Hash func(data []byte) uint32
// Map constains all hashed keys
type Map struct {
hash Hash
// 虚拟节点倍数
replicas int
keys []int // Sorted
hashMap map[int]string
}
// New creates a Map instance
func New(replicas int, fn Hash) *Map {
m := &Map{
replicas: replicas,
hash: fn,
hashMap: make(map[int]string),
}
if m.hash == nil {
// CRC32:CRC本身是“冗余校验码”的意思,CRC32则表示会产生一个32bit(8位十六进制数)的校验值。由于CRC32产生校验值时源数据块的每一个bit(位)都参与了计算,所以数据块中即使只有一位发生了变化,也会得到不同的CRC32值.
m.hash = crc32.ChecksumIEEE
}
return m
}
接下来,实现添加真实节点/机器的 Add() 方法。
// Add adds some keys to the hash.
func (m *Map) Add(keys ...string) {
for _, key := range keys {
// 根据虚拟节点倍数添加虚拟节点
// key: host1:6379 host2:6379 host3:6379
for i := 0; i < m.replicas; i++ {
hash := int(m.hash([]byte(strconv.Itoa(i) + key)))
// 加入hash环
m.keys = append(m.keys, hash)
// 添加虚拟节点和真实节点的映射
m.hashMap[hash] = key
}
}
// 排序
sort.Ints(m.keys)
}
- Add 函数允许传入 0 或 多个真实节点的名称。
- 对每一个真实节点 key,对应创建 m.replicas 个虚拟节点,虚拟节点的名称是:strconv.Itoa(i) + key,即通过添加编号的方式区分不同虚拟节点。
- 使用 m.hash() 计算虚拟节点的哈希值,使用 append(m.keys, hash) 添加到环上。
- 在 hashMap 中增加虚拟节点和真实节点的映射关系。
- 最后一步,环上的哈希值排序。
最后一步,实现选择节点的 Get() 方法:
// Get gets the closest item in the hash to the provided key.
func (m *Map) Get(key string) string {
if len(m.keys) == 0 {
return ""
}
// 求key的哈希值
hash := int(m.hash([]byte(key)))
// Binary search for appropriate replica.
idx := sort.Search(len(m.keys), func(i int) bool {
return m.keys[i] >= hash
})
return m.hashMap[m.keys[idx%len(m.keys)]]
}
- 选择节点就非常简单了,第一步,计算 key 的哈希值。
- 第二步,顺时针找到第一个匹配的虚拟节点的下标 idx,从 m.keys 中获取到对应的哈希值。如果
idx == len(m.keys),说明应选择m.keys[0],因为 m.keys 是一个环状结构,所以用取余数的方式来处理这种情况。 - 第三步,通过
hashMap映射得到真实的节点。
至此,整个一致性哈希算法就实现完成了。
分布式节点
是
接收 key --> 检查是否被缓存 -----> 返回缓存值 ⑴
| 否 是
|-----> 是否应当从远程节点获取 -----> 与远程节点交互 --> 返回缓存值 ⑵
| 否
|-----> 调用`回调函数`,获取值并添加到缓存 --> 返回缓存值 ⑶
对于cache的流程如上所示,在这之前已经实现了流程 ⑴ 和 ⑶,今天实现流程 ⑵,从远程节点获取缓存值。
进一步细化流程 ⑵:
使用一致性哈希选择节点 是 是
|-----> 是否是远程节点 -----> HTTP 客户端访问远程节点 --> 成功?-----> 服务端返回返回值
| 否 ↓ 否
|----------------------------> 回退到本地节点处理。
抽象 PeerPicker
// PeerPicker is the interface that must be implemented to locate
// the peer that owns a specific key.
type PeerPicker interface {
PickPeer(key string) (peer PeerGetter, ok bool)
}
// PeerGetter is the interface that must be implemented by a peer.
type PeerGetter interface {
Get(group string, key string) ([]byte, error)
}
- 在这里,抽象出 2 个接口,PeerPicker 的
PickPeer()方法用于根据传入的 key 选择相应节点 PeerGetter。 - 接口 PeerGetter 的
Get()方法用于从对应 group 查找缓存值。PeerGetter 就对应于上述流程中的 HTTP 客户端。
节点选择与 HTTP 客户端
通信不仅需要服务端还需要客户端,因此,接下来要为 HTTPPool 实现客户端的功能。
首先创建具体的 HTTP 客户端类 httpGetter,实现 PeerGetter 接口:
type httpGetter struct {
baseURL string
}
func (h *httpGetter) Get(group string, key string) ([]byte, error) {
// 拼接请求group和key的url
u := fmt.Sprintf(
"%v%v/%v",
h.baseURL,
url.QueryEscape(group),
url.QueryEscape(key),
)
// 发送请求
res, err := http.Get(u)
if err != nil {
return nil, err
}
_ = res.Body.Close()
if res.StatusCode != http.StatusOK {
return nil, fmt.Errorf("server returned: %v", res.Status)
}
// 获取对应key的其他节点的响应
bytes, err := io.ReadAll(res.Body)
if err != nil {
return nil, fmt.Errorf("reading response body: %v", err)
}
return bytes, nil
}
var _ PeerGetter = (*httpGetter)(nil)
- baseURL 表示将要访问的远程节点的地址,例如
http://example.com/_geecache/。 - 使用
http.Get()方式获取返回值,并转换为[]bytes类型。
为 HTTPPool 添加节点选择的功能:
// 比较特殊的url前缀
// 举例: host:port/_general_cache/groupName/key 来获取某一个group的key
const (
defaultReplicas = 50
defaultBasePath = "/_general_cache/"
)
type HTTPPool struct {
// self 记录节点的ip和端口
self string
// http的url前缀
basePath string
mu sync.Mutex // guards peers and httpGetters
peers *consistenthash.Map
httpGetters map[string]*httpGetter // keyed by e.g. "http://10.0.0.2:8008"
}
- 新增成员变量 peers,类型是一致性哈希算法的 Map,用来根据具体的 key 选择节点。
- 新增成员变量 httpGetters,映射远程节点与对应的 httpGetter。每一个远程节点对应一个 httpGetter,因为 httpGetter 与远程节点的地址 baseURL 有关。
实现 PeerPicker 接口:
// Set updates the pool's list of peers.
func (p *HTTPPool) Set(peers ...string) {
p.mu.Lock()
defer p.mu.Unlock()
p.peers = consistenthash.New(defaultReplicas, nil)
p.peers.Add(peers...)
p.httpGetters = make(map[string]*httpGetter, len(peers))
for _, peer := range peers {
p.httpGetters[peer] = &httpGetter{baseURL: peer + p.basePath}
}
}
// PickPeer picks a peer according to key
func (p *HTTPPool) PickPeer(key string) (PeerGetter, bool) {
p.mu.Lock()
defer p.mu.Unlock()
if peer := p.peers.Get(key); peer != "" && peer != p.self {
p.Log("Pick peer %s", peer)
return p.httpGetters[peer], true
}
return nil, false
}
var _ PeerPicker = (*HTTPPool)(nil)
- Set() 方法实例化了一致性哈希算法,并且添加了传入的节点。
- 并为每一个节点创建了一个 HTTP 客户端 httpGetter。
- PickerPeer() 包装了一致性哈希算法的 Get() 方法,根据具体的 key,选择节点,返回节点对应的 HTTP 客户端。
至此,HTTPPool 既具备了提供 HTTP 服务的能力,也具备了根据具体的 key,创建 HTTP 客户端从远程节点获取缓存值的能力。
实现主流程
// CacheGroup 对cache封装
type CacheGroup struct {
// 当前组的名称
groupName string
// cacheGetter 外部加载key接口
cacheGetter Getter
// baseCache 底层缓存
baseCache cache
picker NodePicker
}
// RegisterPickerToCacheGroup registers a NodePicker for choosing remote peer
func (g *CacheGroup) RegisterPickerToCacheGroup(picker NodePicker) {
if g.picker != nil {
panic("RegisterPeerPicker called more than once")
}
g.picker = picker
}
func (g *CacheGroup) getKeyFromLocal(key string) (ReadOnlyByteView, error) {
// 从getter中获取数据
bytes, err := g.cacheGetter.Get(key)
log.Printf(`[LOCAL INFO] get "%s" from getter %s`, key, "\n")
if err != nil {
return ReadOnlyByteView{}, err
}
// 返回获取到数据的copy
value := ReadOnlyByteView{b: clone(bytes)}
// 加入缓存
g.baseCache.addKeyToCache(key, value)
return value, nil
}
func (g *CacheGroup) getKeyFromNode(getter NodeGetter, key string) (ReadOnlyByteView, error) {
bytes, err := getter.GetKeyFromGetter(g.groupName, key)
if err != nil {
return ReadOnlyByteView{}, err
}
return ReadOnlyByteView{b: bytes}, nil
}
修改 loadKeyFromGetter 方法,使用 NodePicker方法选择节点,若非本机节点,则调用 getKeyFromNode 从远程获取。若是本机节点或失败,则回退到 getKeyFromLocal。
func (g *CacheGroup) loadKeyFromGetter(key string) (ReadOnlyByteView, error) {
if g.picker != nil {
if node, ok := g.picker.GetNode(key); ok {
if value, err := g.getKeyFromNode(node, key); err == nil {
return value, err
}
}
}
return g.getKeyFromLocal(key)
}
测试
- 指定三个节点,并用命令行启动。
- 我们只在7777节点返回Tom,其他节点则需要http通信去获取Tom的信息。

func main() {
var port int
var hasTom int
flag.IntVar(&port, "port", 7777, "server port")
flag.IntVar(&hasTom, "hasTom", 0, "是否含有tom")
flag.Parse()
server := cachehttp.NewHTTPServerPool(fmt.Sprintf("127.0.0.1:%d", port))
server.AddNode("127.0.0.1:7777", "127.0.0.1:8888", "127.0.0.1:9999")
var c *Cache.CacheGroup
if hasTom == 1 {
c = Cache.NewCacheGroup("score", 1<<10, Cache.GetterFunc(func(key string) ([]byte, error) {
if key == "Tom" {
return []byte("看你爹做什么"), nil
}
return []byte(""), fmt.Errorf("%s not found", key)
}))
} else {
c = Cache.NewCacheGroup("score", 1<<10, Cache.GetterFunc(func(key string) ([]byte, error) {
return []byte(""), fmt.Errorf("%s not found", key)
}))
}
c.RegisterPickerToCacheGroup(server)
log.Println(http.ListenAndServe(fmt.Sprintf("127.0.0.1:%d", port), server))
}
防止缓存击穿
缓存雪崩、缓存击穿与缓存穿透
-
缓存雪崩:缓存在同一时刻全部失效,造成瞬时DB请求量大、压力骤增,引起雪崩。缓存雪崩通常因为缓存服务器宕机、缓存的 key 设置了相同的过期时间等引起。
-
缓存击穿:一个存在的key,在缓存过期的一刻,同时有大量的请求,这些请求都会击穿到 DB ,造成瞬时DB请求量大、压力骤增。
-
缓存穿透:查询一个不存在的数据,因为不存在则不会写到缓存中,所以每次都会去请求 DB,如果瞬间流量过大,穿透到 DB,导致宕机。
singleflight 的实现
之前并发了 N 个请求 ,key=Tom,其他节点向 7777 同时发起了 N 次请求。假设对数据库的访问没有做任何限制的,很可能向数据库也发起 N 次请求,容易导致缓存击穿和穿透。即使对数据库做了防护,HTTP 请求是非常耗费资源的操作,针对相同的 key, 其他节点向 7777 发起三次请求也是没有必要的。那这种情况下,我们如何做到只向远端节点发起一次请求呢?
generalcache 实现了一个名为 singleflight 的 package 来解决这个问题:
首先创建 call 和 Group 类型:
package singleflight
import "sync"
// request 一次请求
type request struct {
wg sync.WaitGroup
val any
err error
}
// RequestGroup 管理不同 key 的请求request
type RequestGroup struct {
mu sync.RWMutex
m map[string]*request
}
- call 代表正在进行中,或已经结束的请求。使用 sync.WaitGroup 锁避免重入。
- Group 是 singleflight 的主数据结构,管理不同 key 的请求(call)。
实现 Do 方法:
func (g *RequestGroup) Do(key string, fn func() (interface{}, error)) (interface{}, error) {
// 加锁:map不是线程安全的
g.mu.Lock()
if g.m == nil {
g.m = make(map[string]*request)
}
if req, ok := g.m[key]; ok {
// 如果request存在,则等待执行完成
g.mu.Unlock()
req.wg.Wait()
return req.val, req.err
}
// new一个request
// 此处为指针变量,便于后续修改request的值
req := new(request)
// wg计数器加一
req.wg.Add(1)
// 将当前key的request存入group
g.m[key] = req
// 操作结束解锁
g.mu.Unlock()
// 调用fn获取结果
req.val, req.err = fn()
// 计数器减一
req.wg.Done()
// 加锁处理map
g.mu.Lock()
delete(g.m, key)
g.mu.Unlock()
return req.val, req.err
}
- Do 方法,接收 2 个参数,第一个参数是 key,第二个参数是一个函数 fn。Do 的作用就是,针对相同的 key,无论 Do 被调用多少次,函数 fn 都只会被调用一次,等待 fn 调用结束了,返回返回值或错误。
- g.mu 是保护 Group 的成员变量 m 不被并发读写而加上的锁。
- 并发协程之间不需要消息传递,非常适合 sync.WaitGroup。
- wg.Add(1) 锁加1。
- wg.Wait() 阻塞,直到锁被释放。
- wg.Done() 锁减1。
应用到请求中
- 修改 geecache.go 中的 Group,添加成员变量 loader,并更新构建函数 NewGroup。
- 修改 load 函数,将原来的 load 的逻辑,使用 g.loader.Do 包裹起来即可,这样确保了并发场景下针对相同的 key,load 过程只会调用一次。
// CacheGroup 对cache封装
type CacheGroup struct {
// 当前组的名称
groupName string
// cacheGetter 外部加载key接口
cacheGetter Getter
// baseCache 底层缓存
baseCache cache
picker NodePicker
// 请求组
requestGroup *singleflight.RequestGroup
}
var (
mu sync.RWMutex
groups = make(map[string]*CacheGroup)
)
// NewCacheGroup 创建一个CacheGroup
func NewCacheGroup(groupName string, maxBytes int64, getter Getter) *CacheGroup {
if getter == nil {
panic("nil Getter")
}
mu.Lock()
defer mu.Unlock()
g := &CacheGroup{
groupName: groupName,
cacheGetter: getter,
// 使用封装后的cache
baseCache: cache{maxBytes: maxBytes},
requestGroup: new(singleflight.RequestGroup),
}
groups[groupName] = g
return g
}
func (g *CacheGroup) loadKeyFromGetter(key string) (ReadOnlyByteView, error) {
view, err := g.requestGroup.Do(key, func() (interface{}, error) {
if g.picker != nil {
if node, ok := g.picker.GetNode(key); ok {
if value, err := g.getKeyFromNode(node, key); err == nil {
return value, err
}
}
}
return g.getKeyFromLocal(key)
})
if err != nil {
return ReadOnlyByteView{}, err
}
return view.(ReadOnlyByteView), nil
}
我使用python更方便实现并发:
import requests
from concurrent.futures import ThreadPoolExecutor
def call():
url = "http://127.0.0.1:8888/_general_cache/score/Tom"
response = requests.get(url)
print(response.text.encode("utf-8"))
with ThreadPoolExecutor() as pool:
for i in range(10):
pool.submit(call)
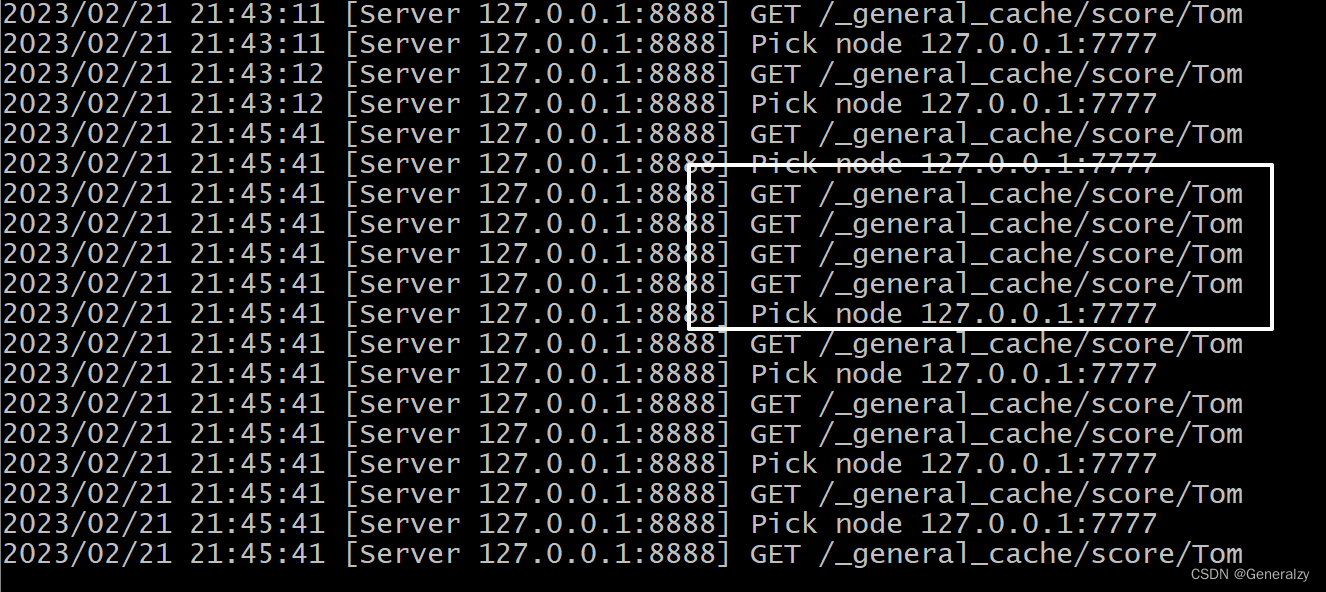
总结
- github地址:https://github.com/Generalzy/GeneralCache
- 学到了一致性哈希,Lru算法
















 521
521











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











