







说明
本文用于记录学习 go 语言过程中的笔记, 文中的代码都是在文本中敲出来的 伪代码, 并不能直接运行, 如有需要可以参考原教程.
本文的整体思路是对原系列教程阅读后的自我思考.
关于本文参考的 学习教程 可以访问原教程链接:
本文如有侵占原教程博主的权益, 还请指出, 本人尽可能及时做出调整.
因为原教程也是参考开源项目 groupcache 开发的此缓存系统.
所以在学习之前, 我们必须要了解 groupcache 的相关用法以及设计思想等等,
不然看到最后会很懵逼, 因为这个项目跟我们常用的 redis 之类的缓存还是有很大的区别…
具体可以看如下参考链接:
笔记大纲
-
第一天,为了解决资源限制的问题,实现了 LRU 缓存淘汰算法;
-
第二天实现了单机并发,并给用户提供了自定义数据源的回调函数;
-
第三天实现了 HTTP 服务端;
-
第四天实现了一致性哈希算法,解决远程节点的挑选问题;
-
第五天创建 HTTP 客户端,实现了多节点间的通信;
-
第六天实现了 singleflight 解决缓存击穿的问题;
-
第七天,使用 protobuf 库,优化了节点间通信的性能。
第一天 LRU 缓存淘汰
一、 定义缓存的存储容量以及缓存容量达到上限时的解决方案
当我们设计缓存时, 我们需要考虑到一个问题, 我们缓存容量一定要是可控的, 不能无限量存储, 因此需要定义一个最大存储容量, 这个我们定义为 maxBytes ,为了和最大存储容量进行比较, 我们还需要计算已占用的字节大小, 我们定义为 nbytes.
当我们定义完最大容量后, 我们要考虑到, 如果存储容量达到设定的最大值时, 想要继续存储数据时, 改怎么办?
有如下两种办法:
-
抛异常提示, 容量达到上限, 让管理员自己去清理.
这个我们通过对外暴露接口, 让客户端调用对应增删改查的 API 就能实现.
-
使用缓存淘汰策略, 淘汰掉 “不需要的已缓存数据”.
这时我们就需要考虑具体要提供哪几种缓存淘汰策略. 这里就先不多说, 我们直接采用 LRU(最近最少使用). 详情参考原文的博客.
二、定义缓存对象
定义缓存数据的数据结构, 以及 LRU 算法(这里省略思考过程, 直接说答案, 具体可参考原文连接)
巧妙结合 list 和 map 实现缓存数据的存储问题,以及 LRU 算法
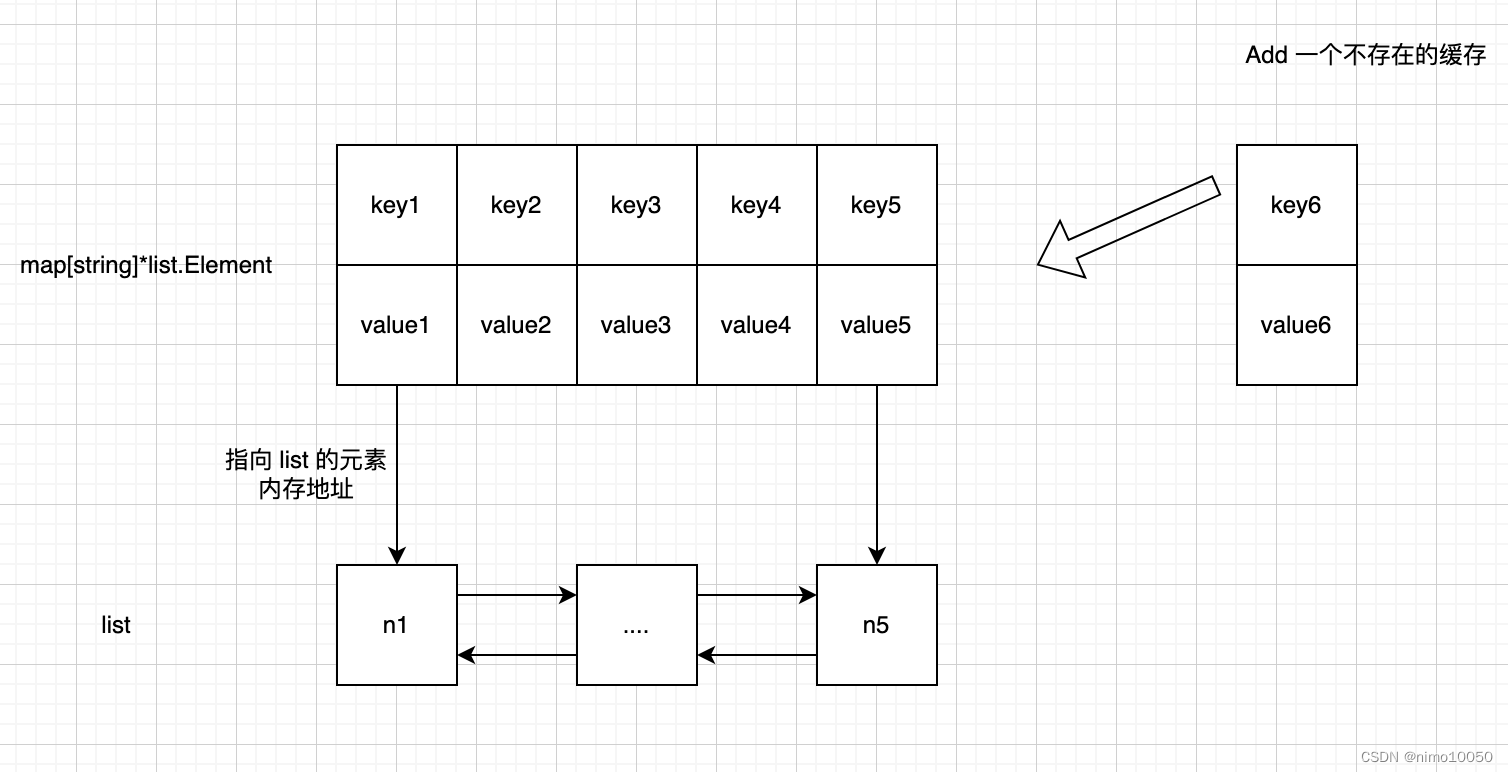
定义数据结构
var ll = list.New()
var m = make(map[string]*list.Element)
因为我们是 k-v 存储, key 的类型已经确定了, 就是 string, 然后结合上一章节的问题, 因为我们要实时统计存储大小, 所以存储的 元素 都要能够计算大小.所以我们抽象出如下接口, 定义要存储的 value:
type Value interface {
Length() int// 存储元素的大小
}
所以我们整个要存储的元素也就定下来了:
type entry struct {
key string
value Value
}
综合上面的描述, 我们定义如下的 缓存 对象:
type Cache struct {
maxBytes int64 // 最大存储容量
nBytes int64 // 已占用的容量
ll *list.List // 双向链表
cache map[string]*list.Element // map
OnEvicted func(key string, value Value) // 缓存删除后的回调方法
}
三、定义创建缓存对象的方法
func New(maxBytes int64, OnEvicted func(key string, value Value)) (c *Cache) {
return &Cache{
maxBytes: maxBytes,
nBytes: 0,
ll: list.New(),
cache: make(map[string]*list.Element),
OnEvicted: OnEvicted
}
}
四、定义 LRU 缓存淘汰策略
func (c *Cache) RemoveOldest() {
// 拿出队尾元素
e := c.ll.Back()
// 从队列中删除
c.ll.Remove(e)
entry := e.Value.(*Entry)
// 删除缓存中的 key
delete(c.cache, entry.key)
// 已使用的大小 - 删除的元素大小
c.cache.nBytes -= (entry.Value.length + len(entry.key))
// callback
OnEvicted(entry.key, entry.Value)
}
五、定义增删改查的方法:
// 添加或更新缓存
func (c *Cache) Add(key string, value Value) {
if c == nil {
panic("breaking error, cache object is nil!")
}
// 如果缓存已经存在
if e, ok := c.cache[key], ok {
// 将元素移到队首
c.ll.MoveToFront(e)
// 覆盖之前的值
c.cache[key] = value
// 减去原先的元素占用的大小
c.nBytes -= e.Value.(*Entry).Value.Length() + len(key)
} else {
// 如果元素不存在, 就创建一个
e := &entry{key, value}
// 放入队首
ll.PushFront(e)
// 放入缓存
c.cache[key] = e
}
// 要存储的元素大小
entryLength := len(key) + value.Length()
// 新元素进入缓存后, 重新计算已占用大小
c.nBytes += entryLength
// 触发缓存淘汰策略, 一直到已占用容量小于最大值
for (c.nBytes + entryLength) > maxBytes {
c.RemoveOldest()
}
}
// 查询缓存
func (c *Cache) Get(key String) (val Value, ok bool) {
// 取出元素
e := c.cache[key]
// 如果查询到了
if e != nil {
// 因为成为了热点数据, 所以要往队首放
c.ll.PushFront(e)
return e.Value.(*Entry).Value, true
}
}
第二天 单机并发,并给用户提供了自定义数据源的回调函数;
一、 定义统一的缓存的 value 对象
根据上文可知, 为了实现缓存容量大小可控,我们存入的每一个元素(k-v)都要计算大小, 为了计算大小,存入缓存的 value 对象必须实现 Length()方法. 那么问题来了, 我们存入的 value 可能是 string, int, 自定义的User, Student 等等, 如果为每一种类型都实现一个 Length() 方法难免有些繁琐. 所以最好的办法就是我们将存入的每个 value 都转化为统一的类型, 比如:字节数组 []byte
考虑到接下来可能要基于存入的 value (字节数组)做一些操作,比如获取数组长度 Len() , 所以为了优雅一些, 我们需要定义一个对象用来做如下事情: 封装字节数组以及操作字节数组的一些操作:
// 定义存入缓存的 value 对象
type ByteView struct {
b []byte
}
// Len 获取字节数组长度
func (v ByteView) Len() int64 {
return int64(len(v.b))
}
二、提升缓存并发读写性能
2.1 线程安全问题
在第一天的实现中,我们设计的缓存系统存在一个明显的问题:
我们的缓存数据都是放在同一个 cache 对象, 也就是 lru.Cache, (如果有 Java 开发经验的话, 可以参考 java.util.HashMap )
拿一个电商系统举例:
库存、商品的缓存数据都放在一个 cache 对象中。当多个线程并发访问读写同一个 key 时,会出现所所谓的线程安全问题。
解决问题最简单的版本就是给 cache 对象加了一把锁。
2.2 锁引发的性能问题
引入锁之后, 就引发了系统性能问题, 考虑如下场景:
当有 N 个线程访问库存的缓存数据时, 我们给 cache 对象加了锁, 如果此时有 M 个线程来访问商品缓存数据,这 N + M 个线程就需要共同竞争一把锁.
2.3 将缓存数据进行分组
为了提高缓存系统的并发读写的性能(降低锁的竞争程度), 我们同样可以参考 Java 中 java.util.concurrent.ConcurrentHashMap 的分段锁的设计思想。
将需要缓存的数据进行分组,比如 库存 数据缓存到 storage 分组, 商品 数据缓存到 item 分组, 如下所示:
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-jhoqMVea-1670987731336)(https://raw.githubusercontent.com/nimo10050/diagram/main/uPic/IPZlxF.png?token=AFMVHTQVULXSZKJQZAP2RA3DTB3Y2)]](https://img-blog.csdnimg.cn/48381b03e91b4c5aa9297da084aec180.png)
如此设计之后, 商品缓存和库存缓存数据就隔离了起来, 访问同一组数据的线程才会互相竞争.
综上分析之后,我们下面就需要朝着如下两个大方向走:
-
go 语言中如何实现加锁,释放锁
-
既然把缓存数据分组了,那么就需要搞一个新的结构,来定义能分组的缓存对象。
2.4 Go 语言中的锁
关于 sync.Mutex 的使用这里不多描述.
2.5 定义能分组加锁的缓存对象
先回顾一下, 第一天实现的缓存对象, 结合我们上面的需求, 很明显这个缓存对象 Cache 已经不能满足我们的需求了.
当然我们可以在原先的基础上去修改这些对象的定义, 以及方法原有的逻辑, 但是这明显破坏了面向对象的设计原则.
我们完全可以重新封装一个新的对象,我们这里命名为 cache(因为它不需要被公开访问, 所以用了首字母小写) 从而减少对原有逻辑和定义的破坏.
type Cache struct {
maxBytes int64
nBytes int64
ll *list.List
cache map[string]*list.Element
onEvicted func(key string, value Value)
}
因为我们每个缓存对象都要持有一把锁 sync.Mutex, 所以我们新定义的缓存对象需要持有这个锁, 另外每个缓存对象都需要统计占用的字节大小, 所以我们需要一个 cacheBytes 字段来存储这个值, 于是我们很轻松便有了如下定义:
// 新的缓存对象
type cache struct {
lru *lru.Cache
mu sync.Mutex
cacheBytes int64
}
接下来要赋予这个缓存对象加锁的能力, 我们拿 get 方法举例:
// 紧接着我们要给这个新的缓存对象, 赋予 CRUD 的能力,比如查询缓存
// 因为锁要公用, 所以这里的 cache 是指针类型
func (c *cache) get(key string) ByteView {
c.mu.Lock()
defer c.mu.Unlock()
if v, ok := c.lru.Get(key); ok {
return v.(ByteView), ok
}
return
}
那么分组怎么体现呢?
// 紧接着我们定义一个 分组 类型
type Group struct {
name string // 分组名称
mainCache cache // 单个缓存对象
}
接下来就要通过 Group 公开对外访问的方法, 来间接访问缓存对象.
2.6 对外暴露访问缓存的方法
这里拿查询缓存说明:
func (g *Group) Get(key string) (ByteView, error) {
if v, ok := g.mainCache.get(key); ok {
return v, nil
}
return nil, fmt.Errorf("dont get cache.")
}
2.7 缓存查询回调方法
上面我们还漏掉了一个功能,如果缓存未命中,我们还要提供回调方法。这个回调方法我们可以直接定义在上面的 Get 方法的入参中,也可以放在 Group 对象中。为了方便, 我们定义在 Group 对象中。
关于回调的思想可以参考 [Go 接口型函数的使用场景 - 7days-golang Q & A](https://geektutu.com/post/7days-golang-q1.html)
type Group struct {
name string // 分组名称
mainCache cache // 单个缓存对象
// 新增回调函数
getter Getter
}
// Getter 定义函数式接口(一套组合拳)
type Getter interface {
Get(key string)
}
type GetterFunc func(key string) ([]byte, error)
func (f GetterFunc) Get(key string) ([]byte, error) {
return f(key)
}
// Get 重新定义 Group 的 Get 方法
func (g *Group) Get(key string) (ByteView, error) {
if v, ok := g.mainCache.get(key); ok {
return v, nil
}
// 从回调方法中取
return g.getter.Get(key)
}
其实这个回调实现类似于 Java 中的函数式接口
2.9 Group 的存储问题以及线程安全问题
接下来我们要考虑的就是,如何存放多个 Group 对象的.
var groups = make(map[string]*Group)
那么问题又来了,既然有多个 Group 对象, 那肯定又涉及到多个线程并发读写 groups 。这时候我们就要考虑用 读写锁 来解决这个问题了。
var rwMutex = sync.RWMutex
紧接着定义读写 group 的方法:
// 创建 Group
func MewGroup(name string, cacheBytes int64) *Group {
rwMutex.Lock()
defer rwMutex.Unlock()
g := &Group{name: name, mainCache: cache{cacheBytes: cacheBytes}}
groups[name] = g
return g
}
// 获取 Group 对象的方法
func GetGroup(name string) *Group {
rwMutex.Lock()
defer rwMutex.Unlock()
g := groups[name]
return g
}
第三天 HTTP 服务端
前面我们实现了一个单机版的缓存服务, 但是我们最终目标是 分布式 缓存!!!
也就是我们需要把我们的 缓存服务 分成不同的节点部署到 多台机器 上, 然后对外提供 网络访问接口, 客户端通过调用这些接口可以实现缓存的增删改查.
常用的接口提供方式有 HTTP 和 RPC, 我们基于最简单的 HTTP 来实现我们的需求.
因此 本文的目标就是基于 Go 语言标准库 http 搭建 HTTP Server
1. 定义 API 接口
我们拿 查询缓存 的接口举例:
http://ip:port/basePath(固定路径)/groupName(缓存分组名称)/key(缓存key)
2. 启动 http 服务
通过如下方式, 我们就能启动一个 http 服务.
http.ListenAndServe("localhost:9999", customHandler)
customHandler 里面是接收请求和处理响应的逻辑,需要我们自己来实现,并且我们需要实现如下 http 库定义的接口.
这个其实类似于 Java 中的 HttpServlet 接口. 我们通过继承 HttpServlet 接口, 通过重新 service 方法就能做到同样的事情.
type Handler interface {
ServeHTTP(w ResponseWriter, r *Request)
}
接下来我们就需要定义一个 struct 去实现 Handler 接口, 另外 struct 里面还需要一些属性来支撑我们坐一些事情.
type HTTPPool struct {
addr string // localhost:8080
basePath string // 请求路径前缀
}
func (h *HTTPPool) ServeHTTP(w http.ResponseWriter, r *http.Request) {
// TODO 处理请求与响应
}
定义创建 HTTPPool 的方法
func NewHTTPPool(addr string, basePath string) (h *HTTPPool) {
return &HTTPPool{
addr: addr
basePath: basePath
}
}
启动 http 服务
func main() {
h := NewHTTPPool("localhost:9999", "geecache")
http.ListenAndServe("localhost:9999", h)
}
通过客户端查询缓存
curl http://localhost:9999/geecache/group/key
第四天 一致性哈希算法
个人认为原文作者对这个算法描述并没有十分到位, 可以参考另外一片博客: https://juejin.cn/post/6844903750860013576
1. 多节点部署缓存服务如何保证数据一致性
我们前面完成了一个 单节点 的缓存服务部署, 对于一个单节点来说, 我不管是读缓存还是写缓存, 都是针对的同一个节点, 所以理论上怎么访问都不会出错.
但是当我们的缓存服务节点多起来的时候, 比如有 10 个节点, 此时如果我们插入一条缓存数据 groupName=user, key=userid 时, 可以随机选一个 节点 A 进行插入, 但是当我们想要查询刚刚插入的那条缓存数据时, 怎么才能定位到 节点A 呢?
此时我们很容易想到 Java 中的 java.util.HashMap 的 哈希槽 的思想:
-
初始化一个长度为 10 的数组,对 10 个缓存节点进行编号, 0, 1, 2…9 , 分别放入数组对应的索引位置;
-
对存入的 key 进行 hash 运算, 拿到一个索引位置, 比如 index=1, 那么这条数据就路由到 index=1 的数组节点上;
-
当我们访问第二步写入的 key 时, 同样进行 hash 运算, 我们就能拿到 index=1 节点信息, 直接去访问即可.
2. hash 算法的缺陷 - 分布式节点数量变更
当节点数目固定不变时, hash 算法确实解决了我们的数据一致性的问题.
但是当我们的节点数量变更时,就会出现新的问题. 比如节点数从 10 变成了 100.
针对这个问题, 我们同样可以联想到 Java 中的 java.util.HashMap 发生扩容、缩容时,会做什么?
rehash 所有的数据都需要重新定位.
但是我们这些缓存数据是存在不同的网络节点的啊, 不可能像 HashMap 一样,在同一块内存里 rehash 的啊.
3. 一致性哈希算法
一致哈希 是一种特殊的哈希算法。在使用一致哈希算法后,哈希表槽位数(大小)的改变平均只需要对 K/n 个关键字重新映射,其中K是关键字的数量, n是槽位数量。然而在传统的哈希表中,添加或删除一个槽位的几乎需要对所有关键字进行重新映射。

如上图所示, 我们准备了 2^32-1 个槽位. 需要部署 3 台缓存节点, 我们通过 hash 算法对 3 台机器的 ip 地址 或者 主机名 进行计算, 得到上图中的 3 个 索引位置.
同样, 我们对存入的缓存数据的 N 个 key 分别进行 hash 计算, 也得到了上图中的 N 个位置.
针对上图来讲, 根据一致性哈希算法的规则, 得出如下结论:
k11 属于 node1 节点, k8 属于 node3 节点, k1, k33, k3 属于 node2 节点
当我们查询 k11 时, 我们计算出了 k11 在哈希环上的索引位置, 然后就通过顺时针查找离它最近的 node 节点, 也就是 node1
4. 一致性哈希算法的容错性和扩张性
当 node1 点宕机后,干扰的只有前面的数据(k11)(原数据被保存到顺时针的下一个服务器, 也就是 node3),而不会干扰到其他的数据。

假如增加一台节点 node4,具体位置如下图所示:

k1, k7 本来存到 node2 中,但由于增加了 node4,他们就被保存到 node4 中, 受干扰的节点也只有 node2 而已,受干扰的数据只有k1, k7 。
因此,一致性哈希算法对于节点的增减都只需重定位换空间的一小部分即可,具有较好的容错性和可扩展性
7. 一致性哈希实现
package consistenthash
import (
"fmt"
"hash/crc32"
"sort"
"strconv"
"testing"
)
// HashFunc 定义一个 hash 算法
type HashFunc func(data []byte) uint32
// HashRing 定义哈希环
type HashRing struct {
replicas int // 虚拟节点的数量
keys []int // 哈希环
hashFunc HashFunc // 定义的哈希算法
hashMap map[int]string // 虚拟节点与真实节点的映射关系 key 为虚拟节点的哈希值, 值是真实节点的名称
}
// New creates a Map instance
func NewHashRing(replicas int, fn HashFunc) *HashRing {
m := &HashRing{
replicas: replicas,
hashFunc: fn,
hashMap: make(map[int]string),
}
if m.hashFunc == nil {
m.hashFunc = crc32.ChecksumIEEE
}
return m
}
// replicas 为虚拟节点的数量, key 为真实节点拿来计算 hash 值的, 比如机器IP、名称等
func (m *HashRing) Add(keys ...string) {
for _, key := range keys {
for i := 0; i < m.replicas; i++ {
hash := int(m.hashFunc([]byte(strconv.Itoa(i) + key)))
m.keys = append(m.keys, hash)
m.hashMap[hash] = key
}
}
sort.Ints(m.keys)
}
func TestHashRing(t *testing.T) {
hash := NewHashRing(3, func(key []byte) uint32 {
i, _ := strconv.Atoi(string(key))
return uint32(i)
})
// Given the above hash function, this will give replicas with "hashes":
// 2, 4, 6, 12, 14, 16, 22, 24, 26
hash.Add("6", "4", "2")
fmt.Println(hash.keys)
}
5. 数据倾斜问题
如果服务器的节点过少,容易引起 key 的倾斜。如下所示, node1, node2, node3 都挤在左上方,其余部分是空的。那么映射到环的左下方的的 key 都会被分配给 node1,这就叫 过度倾斜,缓存节点间负载不均。

6. 虚拟节点
数据倾斜的问题, 主要原因是部署的节点太少了, 节点一少就会造成节点分布不均匀, 就跟上图中一样, 所以我们需要多部署几个节点, 但是为了解决这个问题, 部署几个真实的物理节点, 不就是浪费资源吗?
为了解决此类问题, 我们才需要引入 虚拟节点 的概念, 这里所谓的虚拟节点其实就是帮老大哥占个坑位, 我们需要额外定义一个结构用来存储真实节点与虚拟节点的映射关系.

如上图所示, 我们针对每个节点(node1, node2, node3), 都分别建立了一个虚拟节点 node1-1, node2-1, node3-1 .
当我们一个 key 索引到了 node1-1 的位置, 我们通过维护的节点的映射关系, 很容易就能找到 node1 的信息, 然后直接去访问即可.
如此处理之后, 原先大量倾斜到 node1 的 key 都被均匀分配到了 3 个真实节点上.
第五天 实现了多节点间的通信
1. 定义节点处理请求的逻辑
首先这里, 先明确一下我们查询缓存的逻辑:
当 客户端 发送一个查询请求达到某个缓存节点时, 该节点会先判断 key 是否在本地, 不在的话, 再通过发送网络请求去访问其他 node 节点.
所以每个 node 既要处理来自客户端这样的外部请求, 也要处理来自其他远端节点的内部请求.
为了划分职责, 我们需要在 node 内部, 启动两个 http 服务, 一个处理客户端请求(APIServer), 一个处理节点的请求(CacheServer).
假设我们部署了 3 个 node 节点. 一个简单的网络拓扑就如下所示:

2. 修改查询缓存的逻辑
我们先回顾下之前章节实现的单节点缓存查询.
func (g *Group) Get(key string) (ByteView, error) {
// 先查本地
if v, ok := g.mainCache.get(key); ok {
log.Println("[GeeCache] hit")
return v, nil
}
// 查不到就存进去
return g.load(key)
}
func (g *Group) load(key string) (value ByteView, err error) {
g.mainCache.add(key, value)
}
结合上一小节内容, 我们只需要修改 load 方法的逻辑:
2.1 定义查询节点的方法
我们需要定义一个查询节点的方法, 比如 PickPeer(), 那么这个事情由谁去做呢, 还需要定义一个 PeerPicker 接口.
type PeerPicker interface {
PickPeer() // 返回值待定
}
此时, 我们还需要想一下, 上述方法返回值如何定义, 也就是返回值需要为我们提供什么能力?
答案: 当然是能够通过网络请求帮我们拿到缓存结果, 所以我们不妨返回一个下面这样一个接口:
// 这个接口为我们提供需要的能力.
type PeerGetter interface {
Get(group string, key string) ([]byte, error)
}
接下来, 我们需要实现 PeerGetter#Get 方法:
// 首先需要定义一个 struct 实现 PeerGetter 接口
type httpGetter struct {
baseURL string
}
// 然后就是实现接口对应的方法, 我们上面已经说了, 我们希望这个接口能为我们提供访问网络接口拿到缓存数据.
func (h *httpGetter) Get(group string, key string) ([]byte, error) {
// 这里就是访问 http 接口的逻辑
}
到此, 我们的 PickPeer 方法已经定义好了:
type PeerPicker interface {
PickPeer() (getter PeerGetter)
}
接下来就是怎么实现PickPeer方法, 以及这个方法交给谁去实现. 上面我们已经说了, 这个接口提供的能力是发送 http 请求访问远端缓存节点.
所以我们让 HTTPPool 去实现这个接口再合适不过了.
type HTTPPool struct {
//... 新增如下
peers *consistenthash.HashRing // 哈希环
httpGetters map[string]*httpGetter // 映射远程节点与对应的 httpGetter key 为地址, httpGetter 是访问地址的逻辑
}
2.2 注册节点信息
当我们 cache 服务启动时, 肯定要往 hash 环 添加节点(真实 + 虚拟)的. 创建节点的方法上一章节已经实现了:
func (h *HashRing) Add(keys ...string);
现在我们需要在 HTTPPool 中再封装一层:
func (p *HTTPPool) Set(peers ...string) {
// 因为 hash 环的 map 不是线程安全的,所以这里要加锁.
p.mu.Lock()
defer p.mu.Unlock()
p.peers = consistenthash.New(defaultReplicas, nil)
// 调用上一章节的方法, 在 hash 环上添加真实节点和虚拟节点
p.peers.Add(peers...)
// 存储远端节点信息
p.httpGetters = make(map[string]*httpGetter, len(peers))
for _, peer := range peers {
p.httpGetters[peer] = &httpGetter{baseURL: peer + p.basePath}
}
}
2.3 PickPeer 方法的具体实现
func (p *HTTPPool) PickPeer(key string) (PeerGetter, bool) {
// 因为 hash 环的 map 不是线程安全的,所以这里要加锁.
p.mu.Lock()
defer p.mu.Unlock()
// p.peers 是个 哈希环, 通过调用它的 Get 方法拿到远端节点.
// 这里的 peer 是个地址.
if peer := p.peers.Get(key); peer != "" && peer != p.self {
p.Log("Pick peer %s", peer)
return p.httpGetters[peer], true
}
return nil, false
}
至此我们完成了所有的对象以及方法的定义. 我们来捋一下缓存节点启动的流程.
- 创建 Group 对象.(用于存储我们的缓存数据)
- 启动缓存 http 服务.(创建 HTTPPool,添加节点信息,注册到 gee 中)
- 启动 API 服务.(用于与客户端进行交互)
第六天 解决缓存击穿的问题
防止缓存击穿
缓存击穿:一个存在的key,在缓存过期的一刻,同时有大量的请求,这些请求都会击穿到 DB ,造成瞬时DB请求量大、压力骤增。
为了防止多个请求并发访问同一个 key, 需要过滤掉重复请求.
-
当一个请求到来时, 记录一下;
-
在一个请求处理完成之前, 如果有相同请求到达就排队等待, 直到正在处理的请求完成;
-
排队结束请求可以直接拿到前面请求完成返回的结果.
接下来就要考虑两个事情:
- 如何定义一次请求
- 如何存储这个请求对象
1. 定义请求对象
根据我们的需求定义, 这个对象要能够控制其他线程等待、通过的特性. 这个时候就需要了解一下 sync.WaitGroup, 具体使用这里不过多描述.
type call struct {
wg sync.WaitGroup // 控制线程是否等待
val interface{} // 请求返回结果
err error // 错误信息
}
2. 存储请求对象
当一个请求到达 server 端, server 端需要记录一下这次请求. 这里很容易就想到用 map[string]*call 来存储, key 为查询缓存的 key, value 是本次请求的对象.
另外, 如果用了 map, 就又得考虑线程安全问题, 所以就必须考虑上锁.
type Group struct {
m map[string]*call
mu sync.Mutex
}
3. 重新定义访问缓存的方法(非线程安全)
func (g *Group)Do(key string) {
c := g.m[key]
// 查询是否有相同的请求在查询缓存
if c != nil {
// 当前请求就要排队
c.wg.Wait()
// 排队完, 拿到前面处理完成的请求结果
return c.val, nil
}
// 创建一个请求对象
c = new(call)
// 占个坑位, 其他请求来的时候, 先等等
c.wg.Add(1)
g.m[key] = c
// TODO 请求缓存
// 请求完成, 要给其他请求放行
c.wg.Done()
// 删除
delete(g.m, key)
return xxx, nil
}
4. 让访问缓存的方法更加安全
涉及到操作 group#map 的方法都要加锁.
func (g *Group)Do(key string) (val interface{}, err error) {
c := g.m[key]
g.mu.Lock()
if g.m == nil {
g.[m] == make(map[string]*call)
}
// 查询是否有相同的请求在查询缓存
if c != nil {
// 当前请求就要排队
c.wg.Wait()
// 排队完, 拿到前面处理完成的请求结果
g.mu.UnLock()
return c.val, nil
}
// 创建一个请求对象
c = new(call)
c.wg.Add(1)
g.m[key] = c
// TODO =======请求缓存
// 请求完成, 要给其他请求放行
c.wg.Done()
g.mu.UnLock()
// 删除
g.mu.Lock()
delete(g.m, key)
g.mu.UnLock()
return xxx, nil
}
5. 增加回调方法查询缓存
func (g *Group)Do(key string, fn func(key string) (val interface{}, error)) {
// ====省略前后之前写好的代码
// 请求缓存
fn()
}
第七天 使用 protobuf 库,优化了节点间通信的性能
使用 protobuf 进行通信.
这一章节没什么好说的, 就是把原先的 http 换成了 rpc, 目的就是提升性能
protobuf 即 Protocol Buffers,Google 开发的一种数据描述语言,是一种轻便高效的结构化数据存储格式,与语言、平台无关,可扩展可序列化。protobuf 以二进制方式存储,占用空间小。
protobuf 的具体使用请参考 protobuf的简明教程
1. 定义 protpbuf 文件
syntax="proto3";
package geecachepb;
// 原博文中漏掉了这个, 不知道是什么原因, 不加这一行, protoc --go_out=. *.proto 会执行失败.
option go_package = "./"; // 指定生成的go文件所在path
message Request {
string group = 1;
string key = 2;
}
message Response {
bytes value = 1;
}
service GroupCache {
rpc Get(Request) returns (Response);
}
2. 重新定义原有的方法
因为要用 rpc 替换到 http, 所以这个方法也要进行同步修改.
type PeerGetter interface {
Get(in *pb.Request, out *pb.Response) error
}
func (g *Group) getFromPeer(peer PeerGetter, key string) (ByteView, error) {
req := &pb.Request{
Group: g.name,
Key: key,
}
res := &pb.Response{}
err := peer.Get(req, res)
if err != nil {
return ByteView{}, err
}
return ByteView{b: res.Value}, nil
}
func (p *HTTPPool) ServeHTTP(w http.ResponseWriter, r *http.Request) {
// ...
// Write the value to the response body as a proto message.
body, err := proto.Marshal(&pb.Response{Value: view.ByteSlice()})
if err != nil {
http.Error(w, err.Error(), http.StatusInternalServerError)
return
}
w.Header().Set("Content-Type", "application/octet-stream")
w.Write(body)
}
func (h *httpGetter) Get(in *pb.Request, out *pb.Response) error {
u := fmt.Sprintf(
"%v%v/%v",
h.baseURL,
url.QueryEscape(in.GetGroup()),
url.QueryEscape(in.GetKey()),
)
res, err := http.Get(u)
// ...
if err = proto.Unmarshal(bytes, out); err != nil {
return fmt.Errorf("decoding response body: %v", err)
}
return nil
}














 261
261











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









