







目录
filebeat概览
Filebeat 是一个用于转发和集中日志数据的轻量级传送器。Filebeat 作为agent安装在服务器上,监视指定的日志文件或位置,收集日志事件,并将它们转发到Elasticsearch或 Logstash进行索引。
Filebeat 的工作原理如下:当启动 Filebeat 时,它会启动一个或多个input查找指定的日志数据位置。对于 Filebeat 找到的每个日志,Filebeat 都会启动一个harvester。每个harvester都会读取单个日志以获取新内容,并将新日志数据发送到 libbeat,libbeat 会聚合事件并将聚合数据发送到您为 Filebeat 配置的输出。
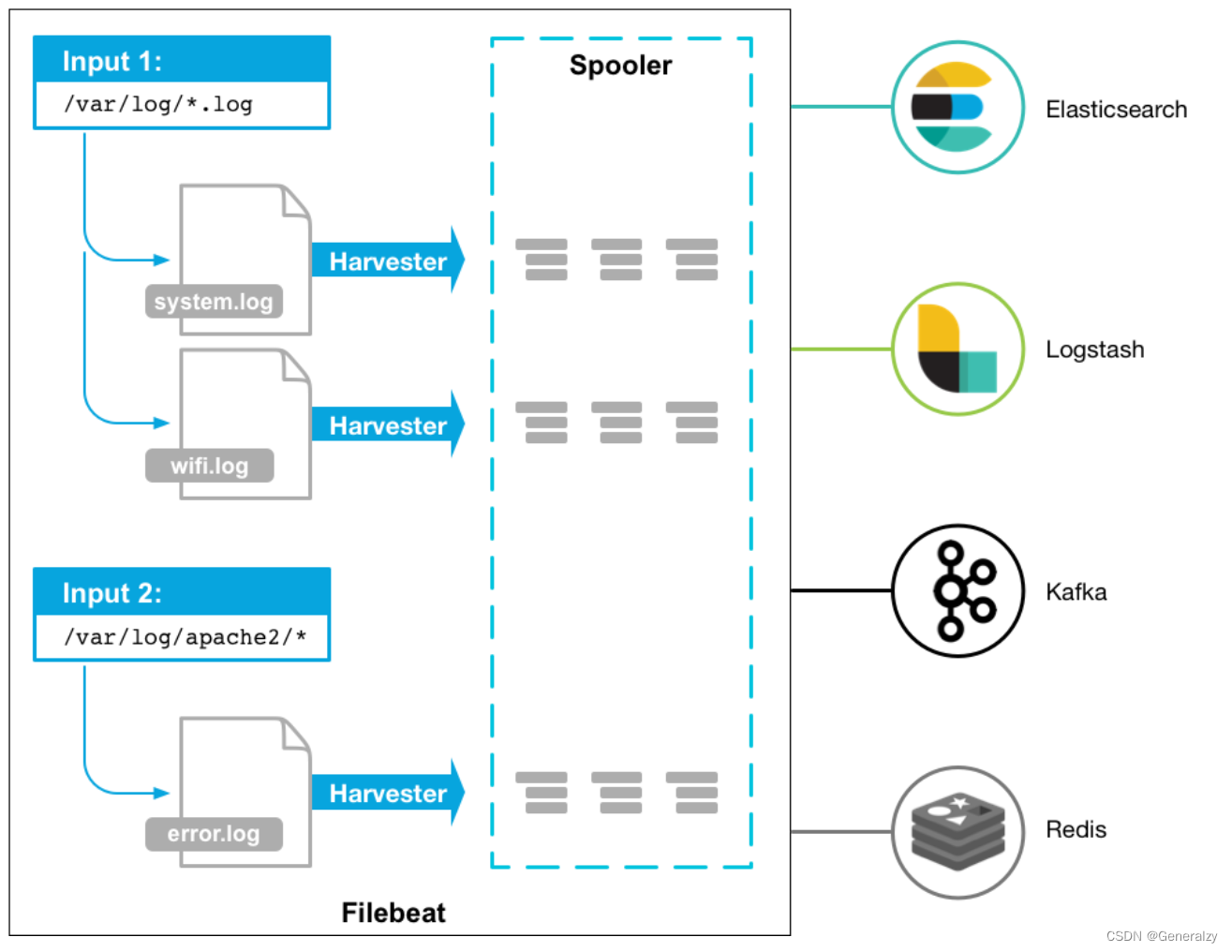
filebeat是如何工作的
Filebeat 由两个主要组件组成:input和harvester。这些组件协同工作来跟踪文件并将事件数据发送到指定的output。
什么是harvester:
- harvester负责读取单个文件的内容。
- harvester逐行读取每个文件,并将内容发送到输出。
- 每个文件启动一个harvester。
- harvester负责打开和关闭文件,这意味着harvester运行时文件描述符保持打开状态。
什么是input:
-
input负责管理harvester并查找所有可供读取的源。
-
如果input类型为log,则input会查找驱动器上与定义的全局路径匹配的所有文件,并为每个文件启动harvester。每个input都在自己的 Go 协程中运行。
-
以下示例将 Filebeat 配置为从与指定 glob 模式匹配的所有日志文件中收集行:
filebeat.inputs: - type: log paths: - /var/log/*.log - /var/path2/*.log
不同的harvester goroutine采集到的日志数据都会发送至一个全局的队列queue中,filebeat默认启用的是基于内存的缓存队列。
每当队列中的数据缓存到一定的大小或者超过了定时的时间(默认1s),会被注册的client从队列中消费,发送至配置的后端。目前可以设置的client有kafka、elasticsearch、redis等。
工作原理
采集日志
filebeat 每采集一条日志文本,都会保存为 JSON 格式的对象,称为日志事件(event)。
filebeat 的主要模块:
- input :输入端。
- output :输出端。
- harvester :收割机,负责采集日志。
filebeat 会定期扫描(scan)日志文件,如果发现其最后修改时间改变,则创建 harvester 去采集日志。
- 对每个日志文件创建一个 harvester ,逐行读取文本,转换成日志事件,发送到输出端。
- 每行日志文本必须以换行符分隔,最后一行也要加上换行符才能视作一行。
- harvester 开始读取时会打开文件描述符,读取结束时才关闭文件描述符。
- 默认会一直读取到文件末尾,如果文件未更新的时长超过 close_inactive ,才关闭。
- 对每个日志文件创建一个 harvester ,逐行读取文本,转换成日志事件,发送到输出端。
假设让 filebeat 采集日志文件 A 。轮换日志文件时,可能经常出现将文件 A 重命名为 B 的情况,比如
mv A B。filebeat 会按以下规则处理:- 如果没打开文件 A ,则以后会因为文件 A 不存在而采集不了。
- 在类 Unix 系统上,当 filebeat 打开文件时,允许其它进程重命名文件。而在 Windows 系统上不允许,因此总是这种情况。
- 如果打开了文件 A ,则会继续读取到文件末尾,然后每隔 backoff 时间检查一次文件:
- 如果在 backoff 时长之内又创建文件 A ,比如
touch A。则 filebeat 会认为文件被重命名(renamed)。- 默认配置了
close_renamed: false,因此会既采集文件 A ,又采集文件 B ,直到因为 close_inactive 超时等原因才关闭文件 B 。 - 此时两个文件的状态都会记录在 registry 中,文件路径 source 相同,只是 inode 不同。
- 默认配置了
- 如果在 backoff 时长之后,依然没有创建文件 A 。则 filebeat 会认为文件被删除(removed)。
- 默认配置了
close_removed: true,因此会立即关闭文件 B 而不采集,而文件 A 又因为不存在而采集不了。此时 filebeat 的日志如下:2021-02-02T15:49:49.446+0800 INFO log/harvester.go:302 Harvester started for file: /var/log/A.log # 开始采集文件 A 2021-02-02T15:50:55.457+0800 INFO log/harvester.go:325 File was removed: /var/log/A.log. Closing because close_removed is enabled. # 发现文件 A 被删除了,停止采集
- 默认配置了
- 如果在 backoff 时长之内又创建文件 A ,比如
- 如果没打开文件 A ,则以后会因为文件 A 不存在而采集不了。
注册表
filebeat 通常会监听多个日志文件,当有新增日志时,就自动采集。
- 监听日志文件时,需要记录一些重要信息,比如:日志文件的路径、inode 、已采集到第几行日志(表示为字节偏移量)
- filebeat 将它采集的所有日志文件的状态信息(state)记录在内存中,统称为注册表(registry)。
为了避免 filebeat 重启时丢失内存中的 registry 数据,filebeat 还会将 registry 数据备份到
data/registry/磁盘目录下。如下:data/registry/filebeat/ ├── 237302.json # registry 快照文件,记录所有日志文件的当前状态,采用最后一次动作的编号作为文件名 ├── active.dat # 记录最新一个快照文件的绝对路径 ├── log.json # registry 日志文件,记录最近执行的一连串动作的日志 └── meta.json # registry 的元数据- filebeat 可能每秒采集多个日志文件,也就是执行大量动作。每执行一个动作,就记录日志到 log.json 文件中,代表某个日志文件的状态发生变化(主要是已采集的 offset 变化)。
- 为了避免 log.json 文件体积过大,默认当 log.json 文件达到 10MB 时,filebeat 会清空该文件,重新写入。并将所有日志文件的当前状态记录成快照文件 xxx.json 。
- 如果删除该目录,则 filebeat 会重新采集所有日志文件,这会导致重复采集。
filebeat 每执行一个动作,会在 log.json 文件中记录两行 JSON 日志,如下:
{"op":"set", "id":237302} // 本次动作的编号 { "k": "filebeat::logs::native::778887-64768", // key ,由 beat 类型、日志文件的 id 组成 "v": { "id": "native::778887-64768", // 日志文件的 id ,由 identifier_name、inode、device 组成 "prev_id": "", "ttl": -1, // -1 表示永不失效 "type": "log", "source": "/var/log/supervisor/supervisord.log", // 日志文件的路径(文件被重命名之后,并不会更新该参数) "timestamp": [2061628216741, 1611303609], // 日志文件最后一次修改的 Unix 时间戳 "offset": 1343, // 当前采集的字节偏移量,表示最后一次采集的日志行的末尾位置 "identifier_name": "native", // 识别日志文件的方式,native 表示原生方式,即根据 inode 和 device 编号识别 "FileStateOS": { // 文件的状态 "inode": 778887, // 文件的 inode 编号 "device": 64768 // 文件所在的磁盘编号 } } }filbeat 采集每个日志文件时,会通过 registry 记录已采集的字节偏移量(bytes offset)。
- 每次 harvester 读取日志文件时,会从 offset 处继续采集。
- 如果 harvester 发现文件体积小于已采集的 offset ,则认为文件被截断了,会从 offset 0 处重新开始读取。这可能会导致重复采集。
发送日志
filebeat 将采集的日志事件经过处理之后,会发送到输出端,该过程称为发布事件(publish event)。
- event 保存在内存中,不会写入磁盘。
- 每个 event 只有成功发送到输出端,且收到 ACK 回复,确认被接收,才视作发送成功。
- 如果发送 event 到输出端失败,则会自动重试。直到发送成功,才更新记录。
- 因此,采集到的 event 至少会被发送一次。但如果在 ACK 之前重启 filebeat ,则可能重复发送。
一个 event 的内容示例:
{ "@timestamp":"2021-02-02T12:03:21.027Z", // 自动加上时间戳字段 "@metadata":{ "beat": "filebeat", "type": "_doc", "version": "7.14.0" }, "agent": { // Beats 的信息 "type": "filebeat", "version": "7.14.0", "name": "CentOS-1", "hostname": "CentOS-1", "ephemeral_id": "ed02583b-0823-4e25-bed3-e8af69ad7d82", "id": "49f74a3e-bfec-452c-b119-32c8014b19b2" }, "log": { "file": { // 采集的日志文件的路径 "path": "/var/log/nginx/access.log" }, "offset": 765072 // 采集的偏移量 }, "message": "127.0.0.1 - [2/Feb/2021:12:02:34 +0000] GET /static/bg.jpg HTTP/1.1 200 0", // 日志的原始内容,之后可以进行解析 "fields": {}, // 可以给 event 加上一些字段 "tags": [], // 可以给 event 加上一些标签,便于筛选 ... }
容器日志采集的三种方式
方式一:Filebeat 与 应用运行在同一容器(不推荐)
- 部署Filebeat:首先,在Kubernetes中或Docker环境中,部署 Filebeat 作为一个从属容器,它将与应用容器一起运行(在同一个容器/POD中运行)。
- 配置Filebeat:在Filebeat的配置文件(filebeat.yml)中,定义日志路径,以告诉 Filebeat 从哪里采集容器日志。
- 输出设置:配置Filebeat将采集到的日志数据发送到所需的目的地,如Elasticsearch、Logstash或Kafka。
- 启动Filebeat:启动Filebeat容器,它将开始采集容器的日志,并将其发送到配置的目的地。
方式二:Filebeat 与 应用运行不在同一容器
- 部署Filebeat:同样,在Kubernetes中或Docker环境中,部署 Filebeat作为一个独立的 Sidecar 容器。
- 配置Filebeat:在Filebeat的配置文件中,使用Docker日志驱动来采集容器日志。
- 输出设置:配置Filebeat的输出,以将采集到的日志数据发送到目标。
- 启动Filebeat:启动Filebeat容器,它将开始采集容器的日志。
方式三:通过 Kubernetes Filebeat DaemonSet
- 部署 Filebeat:在Kubernetes中,可以使用Filebeat DaemonSet部署Filebeat作为一个集群级别的日志采集器。
- Filebeat配置:在Filebeat的配置中,设置输入插件以采集容器的日志。
- Filebeat输出:配置Filebeat的输出插件,以将采集到的日志数据发送到目标,如Elasticsearch或其他存储。
- 启动Filebeat:启动Filebeat DaemonSet,它将在Kubernetes集群中采集容器的日志。
配置解析——以7.10.2为例
filebeat 的 input 和 filebeat.autodiscover 是用于配置数据输入的两种不同方式,它们有一些区别:
-
静态配置 vs 动态发现:
- Input: 静态配置方式,你需要在
filebeat.yml(或者其他配置文件)中明确指定每个要监视的文件、路径或日志源。 - Autodiscover: 动态发现方式,通过配置自动发现规则,
filebeat可以动态地识别和监视符合规则的日志源。这对于动态环境(例如容器化环境)非常有用,因为新的容器可以自动添加到监视列表中。
- Input: 静态配置方式,你需要在
-
简单性 vs 灵活性:
- Input: 相对简单,适用于静态和固定的日志源。配置直截了当,适合那些你事先就知道路径的场景。
- Autodiscover: 更为灵活,适用于动态环境或者在日志源可能随时间变化的情况。可以定义规则来自动识别新的日志源,而无需手动修改配置。
-
单一输入源 vs 多源发现:
- Input: 配置文件通常涉及指定单个输入源(文件、目录、TCP 端口等)。
- Autodiscover: 可以配置多个自动发现规则,允许
filebeat同时监视多个来源,并根据规则动态添加新的来源。
-
适用场景:
- Input: 适用于静态或者不太变化的环境,对输入源的配置要求较为明确。
- Autodiscover: 适用于动态环境,例如容器化环境,或者对于那些可能在运行时动态添加或删除日志源的场景。
示例 filebeat.yml 中使用 filebeat.autodiscover 的配置:
filebeat.autodiscover:
providers:
- type: docker
hints.enabled: true
这个配置示例中,filebeat 使用 Docker 提供的元数据来动态发现并监视容器日志。
并且,在autodiscover模式下,filebeat在启动时就会去调用kubernetes API来获取当前集群下所有的namespace、pod、container等元数据的信息,然后根据这些元数据再去指定的目录采集对应的日志。
下面给出一个可用的限定采集源的filebeat.yml:
filebeat.autodiscover:
providers:
- type: kubernetes
hints.enabled: true
templates:
- condition:
and:
- or:
- equals:
kubernetes.namespace: testa
- equals:
kubernetes.namespace: testb
- equals:
kubernetes.container.name: nginx
kubernetes.labels:
k8s-app: nginx
config:
- type: container
paths:
- /var/log/containers/${data.kubernetes.pod.name}_${data.kubernetes.namespace}_${data.kubernetes.container.name}-*.log
output.elasticsearch:
hosts: ['x.x.x.x:9200']
username: "xxx"
password: "xxx"
上述配置中,用于限定采集源的就是condition模块下的部分,用于限定只采集testa 或者 testb命名空间下的nginx容器的日志。可以根据kubernetes元数据来限定采集源,可用的元数据有以下这些:
host
port (if exposed)
kubernetes.labels
kubernetes.annotations
kubernetes.container.id
kubernetes.container.image
kubernetes.container.name
kubernetes.namespace
kubernetes.node.name
kubernetes.pod.name
kubernetes.pod.uid
kubernetes.node.name
kubernetes.node.uid
kubernetes.namespace
kubernetes.service.name
kubernetes.service.uid
kubernetes.annotations

上述配置中,condition可以根据需求定义更复杂的限定条件,可以参考Conditions进行填写。
其他autodiscover详情参考:https://www.elastic.co/guide/en/beats/filebeat/current/configuration-autodiscover.html
下面给出一个综合的filebeat的helm values.yaml文件:
filebeatConfig:
filebeat.yml: |
processors:
# 不采集filebeat自身日志
- drop_event:
when:
regexp:
kubernetes.pod.name: "filebeat.*"
# 添加k8s元信息
- add_kubernetes_metadata:
in_cluster: true
host: ${NODE_NAME}
matchers:
- logs_path:
logs_path: "/var/lib/docker/containers/"
- logs_path:
logs_path: "/var/log/containers/"
# 删除无用字段
- drop_fields:
fields:
- agent.ephemeral_id
- agent.hostname
- agent.name
- agent.id
- agent.type
- agent.version
- ecs.version
- input.type
- log.offset
- version
-
# 配置集群自动发现
filebeat.autodiscover:
providers:
- type: kubernetes
hints.enabled: true
templates:
- condition:
or:
- equals:
kubernetes.namespace: tets1
- equals:
kubernetes.namespace: test2
config:
- type: container
paths:
- /var/lib/docker/containers/*/*.log
- /var/log/containers/*.log
# 日志json化处理
# 适用于日志文件的每一行本来就是json字符串的格式
json.keys_under_root: true
json.overwrite_keys: true
logging.level: error
logging.to_stderr: false
logging.json: true
output.elasticsearch:
username: '${ELASTICSEARCH_USERNAME}'
password: '${ELASTICSEARCH_PASSWORD}'
protocol: https
hosts: []
ssl.verification_mode: none
性能分析与调优
正常启动filebeat,一般确实只会占用3、40MB内存,但是偶发性的也会发现某些节点上的filebeat容器内存占用超过配置的pod limit限制(一般设置为200MB),并且不停的触发的OOM。
究其原因,一般容器化环境中,特别是裸机上运行的容器个数可能会比较多,导致创建大量的harvester(协程)去采集日志。
如果没有很好的配置filebeat,会有较大概率导致内存急剧上升。
当然,filebeat内存占据较大的部分还是memqueue,所有采集到的日志都会先发送至memqueue聚集,再通过output发送出去。
每条日志的数据在filebeat中都被组装为event结构,filebeat默认配置的memqueue缓存的event个数为4096,可通过queue.mem.events设置。
默认最大的一条日志的event大小限制为10MB,可通过max_bytes设置。4096 * 10MB = 40GB,可以想象,极端场景下,filebeat至少占据40GB的内存。
特别是配置了multiline多行模式的情况下,如果multiline配置有误,单个event误采集为上千条日志的数据,很可能导致memqueue占据了大量内存,致使内存爆炸。
所以,合理的配置日志文件的匹配规则,限制单行日志大小,根据实际情况配置memqueue缓存的个数,才能在实际使用中规避filebeat的内存占用过大的问题。
全部配置
所有类型的 beats 都支持以下 General 配置项(这些参数可以配置全局的,也可以给某个日志源单独配置。):
name: 'filebeat-001' # 该 Beat 的名称,默认使用当前主机名
tags: ['json'] # 给每条日志加上标签,保存到一个名为 tags 的字段中,便于筛选日志
fields: # 给每条日志加上字段,这些字段默认保存为一个名为 fields 的字段的子字段
project: test
fields_under_root: false # 是否将 fields 的各个字段保存为日志的顶级字段,此时如果与已有字段重名则会覆盖
filebeat.yml 的基本配置:
# path.config: ${path.home} # 配置文件的路径,默认是项目根目录
# filebeat.shutdown_timeout: 0s # 当 filebeat 关闭时,如果有 event 正在发送,则等待一定时间直到其完成。默认不等待
# filebeat.registry.path: ${path.data}/registry # registry 磁盘目录
# filebeat.registry.file_permissions: 0600 # registry 文件的权限
# filebeat.registry.flush: 0s # 每当 filebeat 发布一个 event 到输出端,等多久才记录到 registry 日志文件。v8.3 版本将默认值从 0s 改为 1s
# 配置 filebeat 自身的日志
logging.level: info # 只记录不低于该级别的日志
logging.json: true # 输出的日志采用 JSON 格式
logging.to_files: true # 将日志保存到文件 ./logs/filebeat
# logging.to_stderr: true # 将日志输出到终端
# logging.metrics.enabled: true # 是否在日志中记录监控信息,包括 filebeat 的状态、系统负载
# logging.metrics.period: 30s # 记录监控信息的时间间隔
filebeat.config.modules: # 加载模块
path: ${path.config}/modules.d/*.yml
output
filebeat 支持多种输出端,同时只能启用一种输出端。
# 输出到终端,便于调试
# output.console:
# pretty: true
# 输出到 Logstash
output.logstash:
hosts: ['localhost:5044']
# 输出到 ES
# output.elasticsearch:
# hosts: ['10.0.0.1:9200']
# username: 'admin'
# password: '******'
# index: 'filebeat-%{[agent.version]}-%{+yyyy.MM.dd}-%{index_num}' # 用于存储 event 的索引名
# 输出到 kafka
# output.kafka:
# hosts:
# - 10.0.0.1:9092
# topic: '%{[fields.project]}_log'
# partition.random: # 随机选择每个消息输出的 kafka 分区
# reachable_only: true # 是否只输出到可访问的分区。默认为 false ,可能输出到所有分区,如果分区不可访问则阻塞
# compression: gzip # 消息的压缩格式,默认为 gzip ,建议采用 lz4 。设置为 none 则不压缩
# keep_alive: 10 # 保持 TCP 连接的时长,默认为 0 秒
# max_message_bytes: 10485760 # 限制单个消息的大小为 10M ,超过则丢弃
processors
可以配置 processors ,在输出 event 之前进行处理:
processors:
- add_host_metadata: # 添加当前主机的信息,包括 os、hostname、ip 等
when.not.contains.tags: forwarded # 如果该日志不属于转发的
- add_docker_metadata: ~ # 如果存在 Docker 环境,则自动添加容器、镜像的信息。默认将 labels 中的点 . 替换成下划线 _
- add_kubernetes_metadata: ~ # 如果存在 k8s 环境,则自动添加 Pod 等信息
- drop_event: # 丢弃 event ,如果它满足条件
when:
regexp:
message: "^DEBUG"
- drop_fields: # 丢弃一些字段
ignore_missing: true # 是否忽略指定字段不存在的错误,默认为 false
fields:
- cpu.user
- cpu.system
- rate_limit:
limit: 1000/m # 限制全局发送 event 的速率,时间单位可以是 s、m、h 。超过阈值的 event 会被丢弃
# fields: # 设置 fields 时,则考虑指定的所有字段的组合值,对每组不同的值分别限制速率
# - log.file.path
可以配置全局的 processors ,作用于采集的所有日志事件,也可以给某个日志源单独配置。
配置了多个 processors 时,会按顺序执行。
支持声明 processors 的触发条件:
processors:
- <processor_name>:
<parameters>
when:
<condition>
- if:
<condition>
then:
- <processor>:
<parameters>
- <processor>:
<parameters>
else:
- <processor>:
<parameters>
文件日志
采集文件日志的配置示例(配置时间时,默认单位为秒,可使用 1、1s、2m、3h 等格式的值。):
filebeat.inputs: # 关于输入项的配置
- type: log # 定义一个输入项,类型为普通的日志文件
paths: # 指定日志文件的路径
- /var/log/mysql.log
- '/var/log/nginx/*' # 可以使用通配符
- type: log
# enabled: true # 是否启用该输入项
paths:
- '/var/log/nginx/*'
# fields: # 覆盖全局的 General 配置项
# project: test
# logformat: nginx
# fields_under_root: true
# 如果启用任何一个以 json 开头的配置项,则会将每行日志文本按 JSON 格式解析,解析的字段默认保存为一个名为 json 的字段的子字段
# 解析 JSON 的操作会在 multiline 之前执行。因此建议让 filebeat 只执行 multiline 操作,将日志发送到 Logstash 时才解析 JSON
# 如果 JSON 解析失败,则会将日志文本保存在 message 字段,然后输出
# json.add_error_key: true # 如果解析出错,则给 event 添加 error.message 等字段
# json.message_key: log # 指定存储日志内容的字段名。如果指定了该字段,当该字段为顶级字段、取值为字符串类型时,会进行 multiline、include、exclude 操作
# json.keys_under_root: false # 是否将解析出的 JSON 字段保存为 event 的顶级字段
# json.overwrite_keys: false # 在启用了 keys_under_root 时,如果解析出的字段与原有字段冲突,是否覆盖
# 默认将每行日志文本视作一个 event ,可以通过 multiline 规则将连续的多行文本记录成同一个 event
# multiline 操作会在 include_lines 之前执行
# multiline.type: pattern # 采用 pattern 方式,根据正则匹配处理多行。也可以采用 count 方式,根据指定行数处理多行
# multiline.pattern: '^\s\s' # 如果一行文本与 pattern 正则匹配,则按 match 规则与上一行或下一行合并
# multiline.negate: false # 是否反向匹配
# multiline.match: after # 取值为 after 则放到上一行之后,取值为 before 则放到下一行之前
# multiline.max_lines: 500 # 多行日志最多包含多少行,超过的行数不会采集。默认为 500
# exclude_files: ['\.tgz$'] # 排除一些正则匹配的文件
# exclude_lines: ['^DEBUG', '^INFO'] # 排除日志文件中正则匹配的那些行
# include_lines: ['^WARN', '^ERROR'] # 只采集日志文件中正则匹配的那些行。默认采集所有非空的行。该操作会在 exclude_lines 之前执行
# encoding: utf-8 # 编码格式
# scan_frequency: 10s # 每隔多久扫描一次日志文件,如果有变动则创建 harvester 进行采集
# ignore_older: 0s # 不扫描最后修改时间在多久之前的文件,默认不限制时间。其值应该大于 close_inactive
# harvester_buffer_size: 16384 # 每个 harvester 在采集日志时的缓冲区大小,单位 bytes
# max_bytes: 102400 # 每条日志的 message 部分的最大字节数,超过的部分不会发送(但依然会读取)。默认为 10 M ,这里设置为 100 K
# tail_files: false # 是否从文件的末尾开始,倒序读取
# backoff: 1s # 如果 harvester 读取到文件末尾,则每隔多久检查一次文件是否更新
# 配置 close_* 参数可以让 harvester 尽早关闭文件,但不利于实时采集日志
# close_timeout: 0s # harvester 每次读取文件的超时时间,超时之后立即关闭。默认不限制
# close_eof: false # 如果 harvester 读取到文件末尾,则立即关闭
# close_inactive: 5m # 如果 harvester 读取到文件末尾之后,超过该时长没有读取到新日志,则立即关闭
# close_removed: true # 如果 harvester 读取到文件末尾之后,检查发现日志文件被删除,则立即关闭
# close_renamed: false # 如果 harvester 读取到文件末尾之后,检查发现日志文件被重命名,则立即关闭
# 配置 clean_* 参数可以自动清理 registry 快照文件,避免它体积过大,但可能导致遗漏采集,或重复采集
# clean_removed: true # 如果某个日志文件在磁盘中被删除,则从 registry 快照文件中删除它
# clean_inactive: 0s # 如果某个日志文件长时间未活动,则从 registry 快照文件中删除它。默认不限制时间。其值应该大于 scan_frequency + ignore_older
# 给该日志源单独配置 processors
# processors:
# - drop_event: ...
filebeat v7.14 弃用了输入类型 type: log ,建议用户改用 type: filestream 。
type: log的特点:- 每次成功发布日志事件到输出端,就会重写一次 registry 快照文件,从而更新日志文件的当前状态(主要是 offset )。因此需要频繁 fsync 到磁盘,开销较大。
- 解析日志文本时,只能采用 json 或 multiline 格式。
type: filestream的特点:- 将 offset 更新信息以 append 方式写入 registry 日志文件,默认达到 10MB 时才重写一次 registry 快照文件,因此大幅减少了 fsync 的次数。
- 解析日志文本时,可依次采用多个 parsers 。
- 例:
- type: filestream id: mysql-filestream # 每个 filestream 需要配置一个唯一 ID paths: - /var/log/mysql.log # fields: # project: test # logformat: nginx # fields_under_root: true # exclude_lines: ... # include_lines: ... parsers: # 配置一组解析日志文本的规则 - ndjson: # 按 JSON 格式解析 target: "" # 将解析出的 JSON 字段保存为哪个字段的子字段,取值为空表示保存为顶级字段 # overwrite_keys: true # 如果解析出的字段与原有字段冲突,是否覆盖 # add_error_key: true # 如果解析出错,则给 event 添加 error.message 等字段 # message_key: msg # 可选,对 JSON 中某个字段执行 multiline 规则 - multiline: type: pattern pattern: '^\s\s' # - container: # 解析容器的日志文件 # stream: all # 默认会读取 stdout 和 stderr # format: auto # 表示容器日志的格式是 docker 还是 cri ,默认为 auto ,会自动识别 # - syslog: # 解析系统日志 # format: auto
可启用 filebeat 的一些内置模块,自动采集一些系统或流行软件的日志文件,此时不需要用户自行配置。
- 命令:
./filebeat modules enable [module]... # 启用一些模块 disable [module]... # 禁用一些模块 list # 列出启用、禁用的所有模块 - filebeat 支持的 模块列表 (opens new window)
容器日志
采集容器日志的配置示例:
filebeat.inputs:
- type: container
paths:
- /var/lib/docker/containers/*/*.log
# stream: all # 从哪个流读取日志,可以取值为 stdout、stderr、all ,默认为 all
# 兼容 type: log 的配置参数
注意 docker 的日志文件默认需要 root 权限才能查看。
上述配置会采集所有容器的日志,而使用以下自动发现(autodiscover)的配置,可以只采集部分容器的日志:
filebeat 支持对容器的自动发现(autodiscover),还支持从容器的元数据中加载配置,称为基于提示(hints)的自动发现。
filebeat.autodiscover:
providers:
# - type: docker # 声明一个自动发现的日志源,为 docker 类型。这会调用内置 docker 变量模板
# templates:
# - condition: # 只采集满足该条件的日志
# contains:
# docker.container.name: elasticsearch
# config:
# - type: container # 该 container 是指 filebeat.inputs 类型,不是指 providers 类型
# paths:
# - /var/lib/docker/containers/${data.docker.container.id}/*.log
# hints.enabled: false # 是否启用 hints ,从 Docker 容器的 Labels 加载配置
# hints.default_config: # 设置默认的 hints 配置
# enabled: true # 是否采集容器的日志,默认为 true 。如果禁用,则需要容器启用 co.elastic.logs/enabled 配置
# type: container
# paths:
# - /var/lib/docker/containers/${data.docker.container.id}/*.log # Docker 引擎的日志路径
- type: kubernetes
node: ${NODE_NAME}
hints.enabled: true # 从 k8s Pod 的 Annotations 加载配置
hints.default_config:
type: container
paths:
- /var/log/containers/*-${data.kubernetes.container.id}.log # CRI 标准的日志路径
fields_under_root: true
provider 为 docker 类型时,可引用一些变量,比如:
docker.container.id
docker.container.image
docker.container.name
docker.container.labels
使用 hints 功能时,可以在容器的 Labels 或 Annotations 中添加配置参数:
co.elastic.logs/enabled: true # 是否采集容器的日志,默认为 true
co.elastic.logs/json.*: ...
co.elastic.logs/multiline.*: ...
co.elastic.logs/exclude_lines: '^DEBUG'
co.elastic.logs/include_lines: ...
co.elastic.logs/processors.dissect.tokenizer: "%{key2} %{key1}"
源码解析
下载源码,filebeat github源码地址:https://github.com/elastic/beats/tree/v7.10.2
然后在beats目录下执行:
go mod tidy
待续
FAQ
配置了过滤不起作用
可以考虑删掉input和全局processor,直接用自动发现:
filebeat.yml: |
filebeat.autodiscover:
providers:
- type: kubernetes
hints.enabled: false
templates:
- condition:
or:
- equals:
kubernetes.namespace: "x1"
- equals:
kubernetes.namespace: "x2"
config:
- type: container
paths:
- /*.log
- /var/log/containers/*.log
processors:
- add_kubernetes_metadata:
in_cluster: true
host: ${NODE_NAME}
matchers:
- logs_path:
logs_path: "/"
- logs_path:
logs_path: "/var/log/containers/"
- drop_event:
when:
not:
or:
- regexp:
kubernetes.pod.name: "server*"
- regexp:
kubernetes.pod.name: "apix*"
- drop_fields:
fields:
- agent.ephemeral_id
- agent.hostname
- agent.id
- agent.type
- agent.version
- ecs.version
- input.type
- log.offset
- version
ignore_missing: true
logging.level: error
logging.to_files: false
logging.to_stderr: true
# 生命周期管理
setup.ilm.enabled: true
setup.ilm.rollover_alias: "filebeat"
setup.ilm.pattern: "{now/d}-000001"
setup.ilm.policy_name: "filebeat_policy"
output.elasticsearch:
username: '${ELASTICSEARCH_USERNAME}'
password: '${ELASTICSEARCH_PASSWORD}'
protocol: https
hosts: []
ssl.verification_mode: none
然后将processors改为局部processors,对应每一种配置进行特殊处理,注意配置文件修改完一定要重新部署或启动filebeat。















 1054
1054











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











