







在做RAG分块部分时,涉及到了基于内容意图分块这就需要一些NLP库来对句子的语义进行切分等操作。
nltk
NLTK是一个高效的Python构建的平台,用来处理人类自然语言数据。它提供了易于使用的接口,通过这些接口可以访问超过50个语料库和词汇资源(如WordNet),还有一套用于分类、标记化、词干标记、解析和语义推理的文本处理库,以及工业级NLP库的封装器和一个活跃的讨论论坛。
快速开始
使用pip命令即可快速安装nltk库:pip install nltk
nltk需要配套的语料库,因此需要安装nltk语料库,
在NLTK模块中包含数十种完整的语料库,可用来练习使用,如下所示:
古腾堡语料库:gutenberg,包含古藤堡项目电子文档的一小部分文本,约有36000本免费电子书。
网络聊天语料库:webtext、nps_chat
布朗语料库:brown
路透社语料库:reuters
影评语料库:movie_reviews,拥有评论、被标记为正面或负面的语料库;
就职演讲语料库:inaugural,有55个文本的集合,每个文本是某个总统在不同时间的演说.
在线下载语料库(失败率较高):
import nltk
nltk.download()
手动下载,离线安装(https://github.com/nltk/nltk_data/tree/gh-pages):
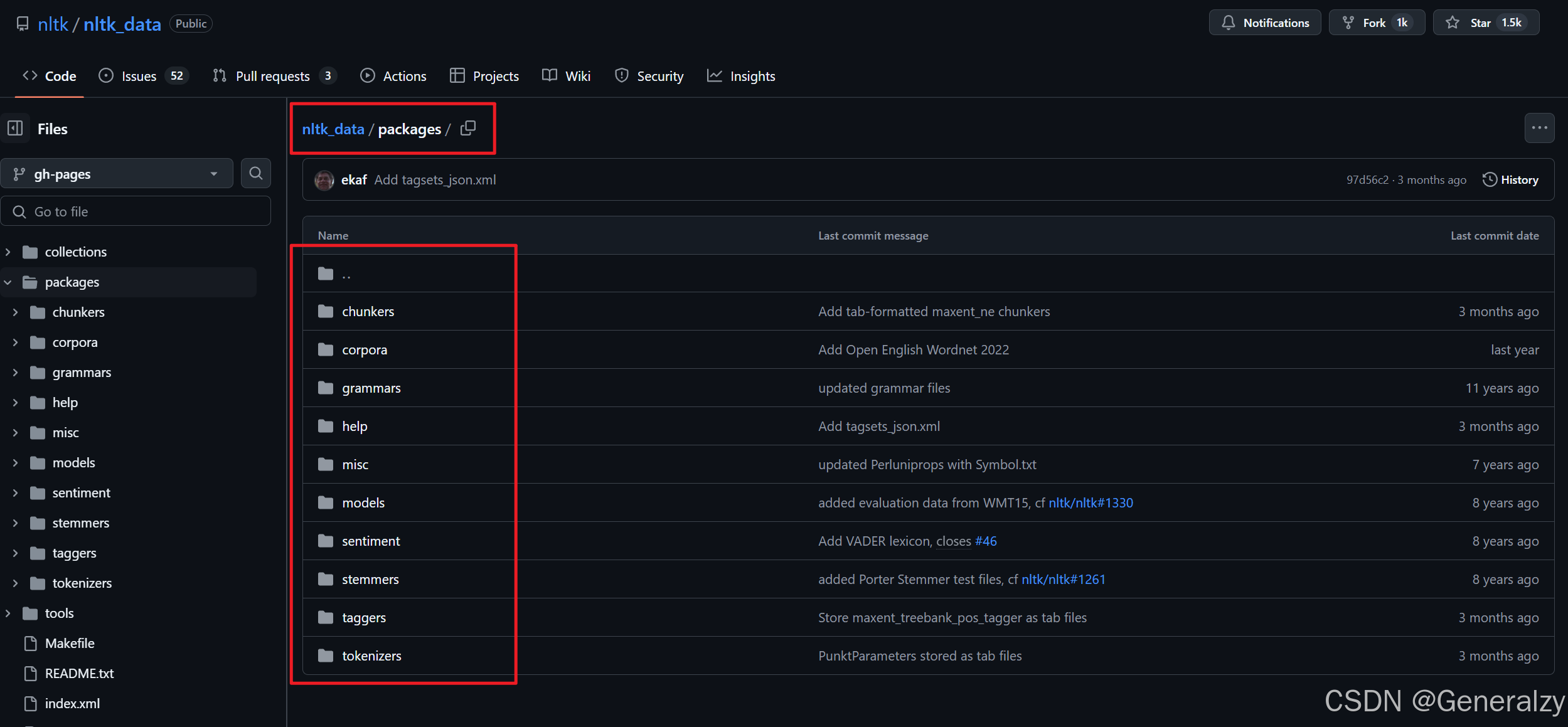
查看packages文件夹应该放在哪个路径下:
import nltk
print(nltk.data.path)

将下载的packages文件夹改名为nltk_data,放在如下文件夹:
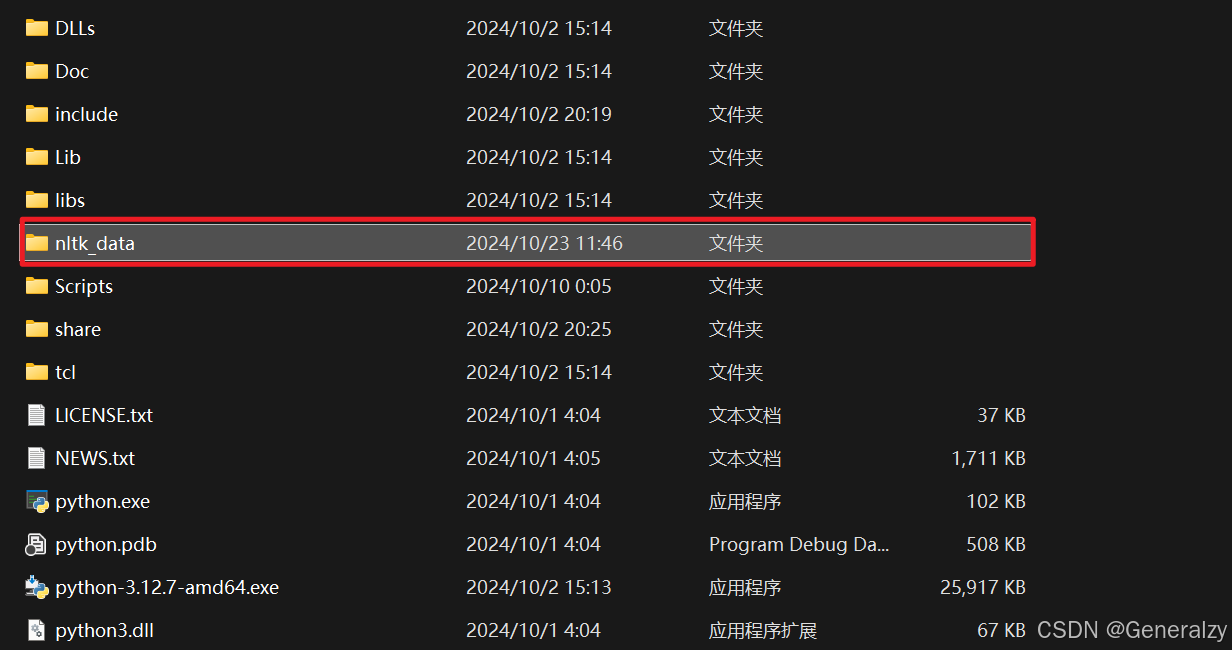
验证是否安装成功:
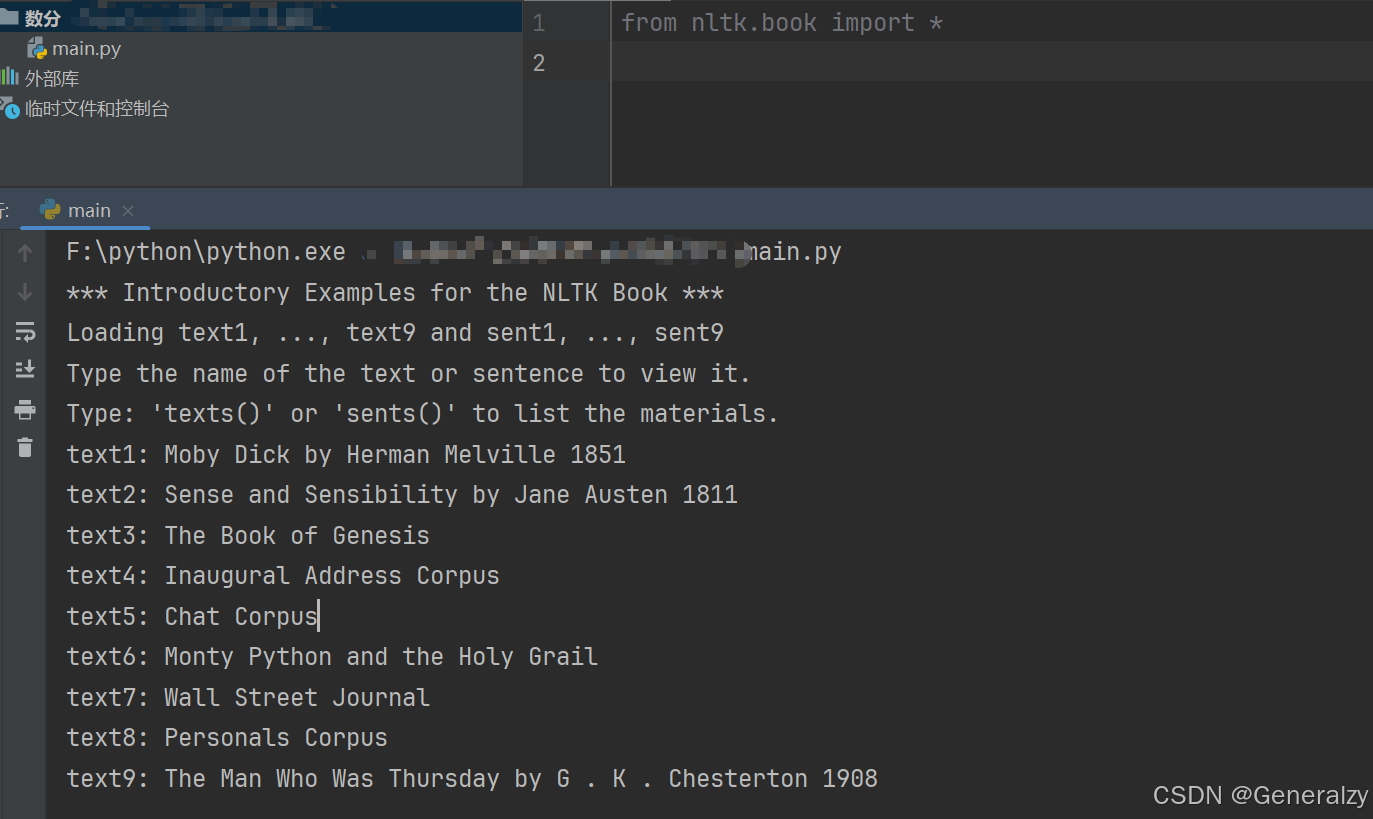
分词测试:
import nltk
ret = nltk.word_tokenize("A pivot is the pin or the central point on which something balances or turns")
print(ret)
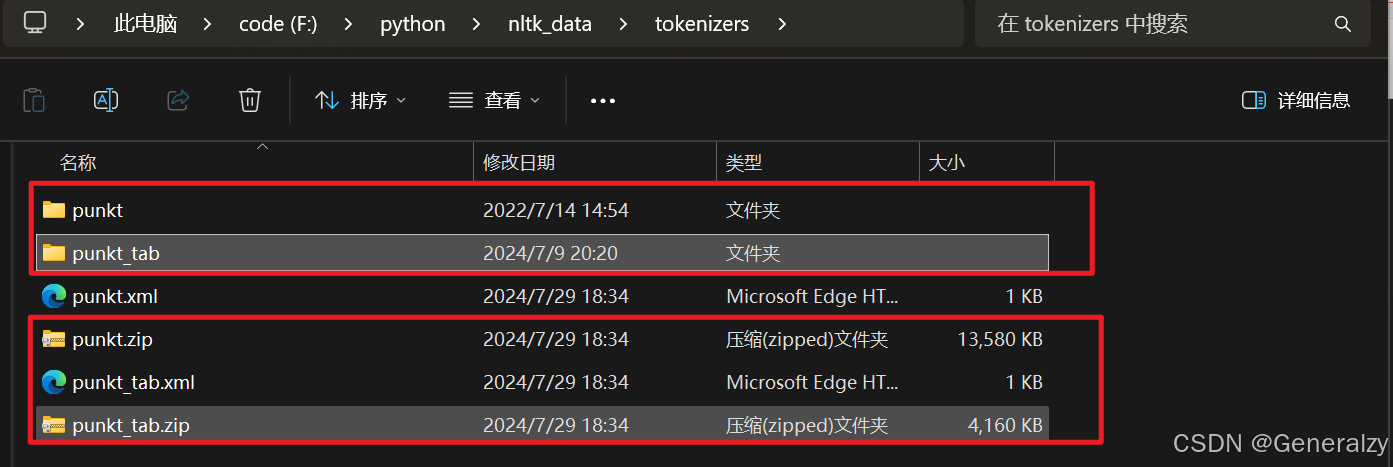
如果出现类似FileNotFoundError: [Errno 2] No such file or directory: 'F:\\python\\nltk_data\\tokenizers\\punkt_tab.zip\\punkt_tab\\english/collocations.tab'的错误,将目录下的压缩包全部解压就行:
nltk使用
分句分词
英文分句:nltk.sent_tokenize :对文本按照句子进行分割
英文分词:nltk.word_tokenize:将句子按照单词进行分隔,返回一个列表
from nltk.tokenize import sent_tokenize, word_tokenize
EXAMPLE_TEXT = "Hello Mr. Smith, how are you doing today? The weather is great, and Python is awesome. The sky is pinkish-blue. You shouldn't eat cardboard."
print(sent_tokenize(EXAMPLE_TEXT))
print(word_tokenize(EXAMPLE_TEXT))
from nltk.corpus import stopwords
stop_word = set(stopwords.words('english')) # 获取所有的英文停止词
word_tokens = word_tokenize(EXAMPLE_TEXT) # 获取所有分词词语
filtered_sentence = [w for w in word_tokens if not w in stop_word] #获取案例文本中的非停止词
print(filtered_sentence)
['Hello Mr. Smith, how are you doing today?', 'The weather is great, and Python is awesome.', 'The sky is pinkish-blue.', "You shouldn't eat cardboard."]
['Hello', 'Mr.', 'Smith', ',', 'how', 'are', 'you', 'doing', 'today', '?', 'The', 'weather', 'is', 'great', ',', 'and', 'Python', 'is', 'awesome', '.', 'The', 'sky', 'is', 'pinkish-blue', '.', 'You', 'should', "n't", 'eat', 'cardboard', '.']
['Hello', 'Mr.', 'Smith', ',', 'today', '?', 'The', 'weather', 'great', ',', 'Python', 'awesome', '.', 'The', 'sky', 'pinkish-blue', '.', 'You', "n't", 'eat', 'cardboard', '.']
punkt 和 punkt_tab 都是NLTK中的分词和分句模型,但它们有一些区别:
-
punkt:punkt是NLTK的主要分词和分句模型,使用无监督学习方法,适用于多种语言,包括英语、德语、法语等。- 该模型基于文本中的标点符号和其他特征进行分句。
punkt在默认情况下提供对多种语言的支持,但主要用于英语和一些欧洲语言。
-
punkt_tab:punkt_tab是punkt模型的扩展版本,主要用于支持表格或结构化文本的情况。- 它提供了一些额外的功能,特别是在处理包含表格的文档时,可以帮助更好地识别和处理文本结构。
- 此外,
punkt_tab主要用于处理具有特定格式的文本,如学术论文、技术文档等。
总结来说,punkt是常规的分词和分句工具,而punkt_tab则是在此基础上,针对更复杂的文本结构进行优化的扩展版本。对于一般的文本处理,punkt通常就足够了。如果你处理的是结构化文本,可以考虑使用punkt_tab。
由于这两个模型里面都没有中文字样,所以nltk对中文的支持非常有限。
停用词过滤
from nltk.corpus import stopwords
# 获取英文停用词
english_stopwords = set(stopwords.words('english'))
print(english_stopwords)
# 中文停用词语
chinese_stopwords = set(stopwords.words('chinese'))
print(chinese_stopwords)

from nltk.tokenize import sent_tokenize, word_tokenize #导入 分句、分词模块
from nltk.corpus import stopwords #导入停止词模块
def remove_stopwords(text):
text_lower=[w.lower() for w in text if w.isalpha()]
stopword_set =set(stopwords.words('english'))
result = [w for w in text_lower if w not in stopword_set]
return result
example_text = "Stray birds of summer come to my window to sing and fly away. And yellow leaves of autumn,which have no songs,flutter and fall there with a sigh."
word_tokens = word_tokenize(example_text)
print(remove_stopwords(word_tokens))
值得一提的是,ntlk有中文停用词。
词干提取
词干提取:是去除词缀得到词根的过程,例如:fishing、fished,为同一个词干 fish,Nltk提供PorterStemmer进行词干提取。
from nltk.stem import PorterStemmer
ps = PorterStemmer()
example_words = ["python", "pythoner", "pythoning", "pythoned", "pythonly"]
print(example_words)
for w in example_words:
print(ps.stem(w), end=' ')
词形/词干还原
与词干提取类似,词干提取包含被创造出的不存在的词汇,而词形还原的是实际的词汇。(
from nltk.stem import WordNetLemmatizer
lemmatizer = WordNetLemmatizer()
print('cats\t', lemmatizer.lemmatize('cats'))
# lemmatize接受词性参数pos。 如果没有提供,默认是“名词”。
print('better\t', lemmatizer.lemmatize('better', pos='a'))
cats cat
better good
from nltk.stem import WordNetLemmatizer
lemmatizer = WordNetLemmatizer()
print(lemmatizer.lemmatize("cats"))
print(lemmatizer.lemmatize("cacti"))
print(lemmatizer.lemmatize("geese"))
print(lemmatizer.lemmatize("rocks"))
print(lemmatizer.lemmatize("python"))
print(lemmatizer.lemmatize("better", pos="a"))
print(lemmatizer.lemmatize("best", pos="a"))
print(lemmatizer.lemmatize("run"))
print(lemmatizer.lemmatize("run",'v'))
cat
cactus
goose
rock
python
good
best
run
run
时态和单复数:
from nltk.tokenize import sent_tokenize, word_tokenize
from nltk.stem import PorterStemmer
tokens = word_tokenize(text="All work and no play makes jack a dull boy, all work and no play,playing,played", language="english")
ps=PorterStemmer()
stems = [ps.stem(word)for word in tokens]
print(stems)
from nltk.stem import SnowballStemmer
snowball_stemmer = SnowballStemmer('english')
ret = snowball_stemmer.stem('presumably')
print(ret)
from nltk.stem import WordNetLemmatizer
wordnet_lemmatizer = WordNetLemmatizer()
ret = wordnet_lemmatizer.lemmatize('dogs')
print(ret)
['all', 'work', 'and', 'no', 'play', 'make', 'jack', 'a', 'dull', 'boy', ',', 'all', 'work', 'and', 'no', 'play', ',', 'play', ',', 'play']
presum
dog
同义词与反义词
nltk提供了WordNet进行定义同义词、反义词等词汇数据库的集合。
同义词:
from nltk.corpus import wordnet
# 单词boy寻找同义词
syns = wordnet.synsets('girl')
print(syns[0].name())
# 只是单词
print(syns[0].lemmas()[0].name())
# 第一个同义词的定义
print(syns[0].definition())
# 单词boy的使用示例
print(syns[0].examples())
近义词与反义词:
from nltk.corpus import wordnet
synonyms = [] # 定义近义词存储空间
antonyms = [] # 定义反义词存储空间
for syn in wordnet.synsets('bad'):
for i in syn.lemmas():
synonyms.append(i.name())
if i.antonyms():
antonyms.append(i.antonyms()[0].name())
print(set(synonyms))
print(set(antonyms))
语义相关性
wup_similarity() 方法用于语义相关性。
from nltk.corpus import wordnet
w1 = wordnet.synset('ship.n.01')
w2 = wordnet.synset('boat.n.01')
print(w1.wup_similarity(w2))
w1 = wordnet.synset('ship.n.01')
w2 = wordnet.synset('car.n.01')
print(w1.wup_similarity(w2))
w1 = wordnet.synset('ship.n.01')
w2 = wordnet.synset('cat.n.01')
print(w1.wup_similarity(w2))
0.9090909090909091
0.6956521739130435
0.32
NLTK 提供多种 相似度计分器(similarity scorers),比如:
- path_similarity
- lch_similarity
- wup_similarity
- res_similarity
- jcn_similarity
- lin_similarity
词性标注
把一个句子中的单词标注为名词,形容词,动词等。
from nltk.tokenize import sent_tokenize, word_tokenize #导入 分句、分词模块
example_text = "Stray birds of summer come to my window to sing and fly away. And yellow leaves of autumn,which have no songs,flutter and fall there with a sigh."
word_tokens = word_tokenize(example_text)
from nltk import pos_tag
tags = pos_tag(word_tokens)
print(tags)
标注释义如下:
| POS Tag |指代 |
| --- | --- |
| CC | 并列连词 |
| CD | 基数词 |
| DT | 限定符|
| EX | 存在词|
| FW |外来词 |
| IN | 介词或从属连词|
| JJ | 形容词 |
| JJR | 比较级的形容词 |
| JJS | 最高级的形容词 |
| LS | 列表项标记 |
| MD | 情态动词 |
| NN |名词单数|
| NNS | 名词复数 |
| NNP |专有名词|
| PDT | 前置限定词 |
| POS | 所有格结尾|
| PRP | 人称代词 |
| PRP$ | 所有格代词 |
| RB |副词 |
| RBR | 副词比较级 |
| RBS | 副词最高级 |
| RP | 小品词 |
| UH | 感叹词 |
| VB |动词原型 |
| VBD | 动词过去式 |
| VBG |动名词或现在分词 |
| VBN |动词过去分词|
| VBP |非第三人称单数的现在时|
| VBZ | 第三人称单数的现在时 |
| WDT |以wh开头的限定词 |
//
POS tag list:
CC coordinating conjunction
CD cardinal digit
DT determiner
EX existential there (like: "there is" ... think of it like "there exists")
FW foreign word
IN preposition/subordinating conjunction
JJ adjective 'big'
JJR adjective, comparative 'bigger'
JJS adjective, superlative 'biggest'
LS list marker 1)
MD modal could, will
NN noun, singular 'desk'
NNS noun plural 'desks'
NNP proper noun, singular 'Harrison'
NNPS proper noun, plural 'Americans'
PDT predeterminer 'all the kids'
POS possessive ending parent's
PRP personal pronoun I, he, she
PRP$ possessive pronoun my, his, hers
RB adverb very, silently,
RBR adverb, comparative better
RBS adverb, superlative best
RP particle give up
TO to go 'to' the store.
UH interjection errrrrrrrm
VB verb, base form take
VBD verb, past tense took
VBG verb, gerund/present participle taking
VBN verb, past participle taken
VBP verb, sing. present, non-3d take
VBZ verb, 3rd person sing. present takes
WDT wh-determiner which
WP wh-pronoun who, what
WP$ possessive wh-pronoun whose
WRB wh-abverb where, when
如果报错类似不能将str和zipPathPtr用+号拼接`的错误,同上将taggers目录下的压缩包全部解压:

命名实体识别
命名实体识别(NER)是信息提取的第一步,旨在在文本中查找和分类命名实体转换为预定义的分类,例如人员名称,组织,地点,时间,数量,货币价值,百分比等。
import nltk
from nltk.tokenize import word_tokenize
from nltk.tag import pos_tag
ex = 'European authorities fined Google a record $5.1 billion on Wednesday for abusing its power in the mobile phone market and ordered the company to alter its practices'
def preprocess(sent):
sent = nltk.word_tokenize(sent)
sent = nltk.pos_tag(sent)
return sent
# 单词标记和词性标注
sent = preprocess(ex)
print(sent)
# 名词短语分块
pattern = 'NP: {<DT>?<JJ> * <NN>}'
cp = nltk.RegexpParser(pattern)
cs = cp.parse(sent)
print(cs)
# IOB标签
from nltk.chunk import conlltags2tree, tree2conlltags
from pprint import pprint
iob_tagged = tree2conlltags(cs)
pprint(iob_tagged)
# 分类器识别命名实体,类别标签(如PERSON,ORGANIZATION和GPE)
from nltk import ne_chunk
ne_tree = ne_chunk(pos_tag(word_tokenize(ex)))
print(ne_tree)
--------------------------------
[('European', 'JJ'), ('authorities', 'NNS'), ('fined', 'VBD'), ('Google', 'NNP'), ('a', 'DT'), ('record', 'NN'), ('$', '$'), ('5.1', 'CD'), ('billion', 'CD'), ('on', 'IN'), ('Wednesday', 'NNP'), ('for', 'IN'), ('abusing', 'VBG'), ('its', 'PRP$'), ('power', 'NN'), ('in', 'IN'), ('the', 'DT'), ('mobile', 'JJ'), ('phone', 'NN'), ('market', 'NN'), ('and', 'CC'), ('ordered', 'VBD'), ('the', 'DT'), ('company', 'NN'), ('to', 'TO'), ('alter', 'VB'), ('its', 'PRP$'), ('practices', 'NNS')]
(S
European/JJ
authorities/NNS
fined/VBD
Google/NNP
a/DT
record/NN
$/$
5.1/CD
billion/CD
on/IN
Wednesday/NNP
for/IN
abusing/VBG
its/PRP$
power/NN
in/IN
the/DT
mobile/JJ
phone/NN
market/NN
and/CC
ordered/VBD
the/DT
company/NN
to/TO
alter/VB
its/PRP$
practices/NNS)
[('European', 'JJ', 'O'),
('authorities', 'NNS', 'O'),
('fined', 'VBD', 'O'),
('Google', 'NNP', 'O'),
('a', 'DT', 'O'),
('record', 'NN', 'O'),
('$', '$', 'O'),
('5.1', 'CD', 'O'),
('billion', 'CD', 'O'),
('on', 'IN', 'O'),
('Wednesday', 'NNP', 'O'),
('for', 'IN', 'O'),
('abusing', 'VBG', 'O'),
('its', 'PRP$', 'O'),
('power', 'NN', 'O'),
('in', 'IN', 'O'),
('the', 'DT', 'O'),
('mobile', 'JJ', 'O'),
('phone', 'NN', 'O'),
('market', 'NN', 'O'),
('and', 'CC', 'O'),
('ordered', 'VBD', 'O'),
('the', 'DT', 'O'),
('company', 'NN', 'O'),
('to', 'TO', 'O'),
('alter', 'VB', 'O'),
('its', 'PRP$', 'O'),
('practices', 'NNS', 'O')]
(S
(GPE European/JJ)
authorities/NNS
fined/VBD
(PERSON Google/NNP)
a/DT
record/NN
$/$
5.1/CD
billion/CD
on/IN
Wednesday/NNP
for/IN
abusing/VBG
its/PRP$
power/NN
in/IN
the/DT
mobile/JJ
phone/NN
market/NN
and/CC
ordered/VBD
the/DT
company/NN
to/TO
alter/VB
its/PRP$
practices/NNS)
在NLTK中,
JJ是词性标记(Part of Speech, POS)中的一种,代表形容词(Adjective)。这些标记遵循了《乔伊斯的词性标注系统》(Penn Treebank Tag Set),该系统为英语中的词性提供了标准化的标签。以下是一些常见的词性标记及其含义:
- NN: 名词(Noun),单数形式
- NNS: 名词,复数形式
- NNP: 专有名词(Proper Noun),单数形式
- JJ: 形容词(Adjective)
- JJR: 比较级形容词(Comparative Adjective)
- JJS: 最高级形容词(Superlative Adjective)
- VB: 动词(Verb),原形
- VBD: 动词,过去式
- VBG: 动词,现在分词
- DT: 限定词(Determiner)
IOB标签是一种用于标记文本中命名实体的标准化格式,主要用于信息提取和自然语言处理任务,尤其是命名实体识别(NER)。IOB代表以下三种标签类型:
1. B(Beginning):表示一个命名实体的开始。例如,在“美国总统”这个短语中,“美国”将被标记为“B-LOC”(地理位置的开始)。
2. I(Inside):表示一个命名实体的内部部分。例如,在“美国总统”中,“总统”将被标记为“I-LOC”。
3. O(Outside):表示该单词不是命名实体的一部分。例如,在句子中的其他词将被标记为“O”。
例子:“Barack Obama是美国的总统。” 使用IOB标签标记的结果可能如下:
-Barack->B-PER(人名的开始)
-Obama->I-PER(人名的内部部分)
-是->O(不是命名实体)
-美国->B-LOC(地理位置的开始)
-的->O
-总统->O
通过这种标记方式,系统能够识别出句子中哪些部分是命名实体,并将其分类为不同的类型,如人名(PER)、地点(LOC)等。IOB标签广泛应用于各种自然语言处理任务,特别是在训练和评估NER模型时。
import nltk
from nltk.chunk import conlltags2tree, tree2conlltags
def learnAnaphora():
sentences = [
"John is a man. He walks",
"John and Mary are married. They have two kids",
"In order for Ravi to be successful, he should follow John",
"John met Mary in Barista. She asked him to order a Pizza"
]
for sent in sentences:
chunks = nltk.ne_chunk(nltk.pos_tag(nltk.word_tokenize(sent)), binary=False)
stack = []
print(sent)
items = tree2conlltags(chunks)
for item in items:
if item[1] == 'NNP' and (item[2] == 'B-PERSON' or item[2] == 'O'):
stack.append(item[0])
elif item[1] == 'CC':
stack.append(item[0])
elif item[1] == 'PRP':
stack.append(item[0])
print("\t {}".format(stack))
learnAnaphora()
John is a man. He walks
['John', 'He']
John and Mary are married. They have two kids
['John', 'and', 'Mary', 'They']
In order for Ravi to be successful, he should follow John
['Ravi', 'he', 'John']
John met Mary in Barista. She asked him to order a Pizza
['John', 'Mary', 'She', 'him']
IOB标签关注的是文本中的命名实体及其类别,而词性标记关注的是单词的语法功能。
import nltk # 导入NLTK库
# 定义要处理的句子
sentence = 'Peterson first suggested the name "open source" at Palo Alto, California'
# 先对句子进行分词
words = nltk.word_tokenize(sentence) # 将句子分割成单词
# 对分词后的单词进行词性标注
pos_tagged = nltk.pos_tag(words) # 为每个单词标记词性
# 运行命名实体标注器
ne_tagged = nltk.ne_chunk(pos_tagged) # 对词性标记进行命名实体识别
print("NE tagged text:") # 打印提示
print(ne_tagged) # 打印命名实体标注结果
# 只提取树结构中的命名实体
print("Recognized named entities:") # 打印提示
for ne in ne_tagged: # 遍历命名实体标注结果
if hasattr(ne, "label"): # 检查当前元素是否是命名实体(具有label属性)
print(ne.label(), ne[0:]) # 打印命名实体的标签和内容
# 可视化命名实体识别结果
ne_tagged.draw() # 绘制命名实体树结构
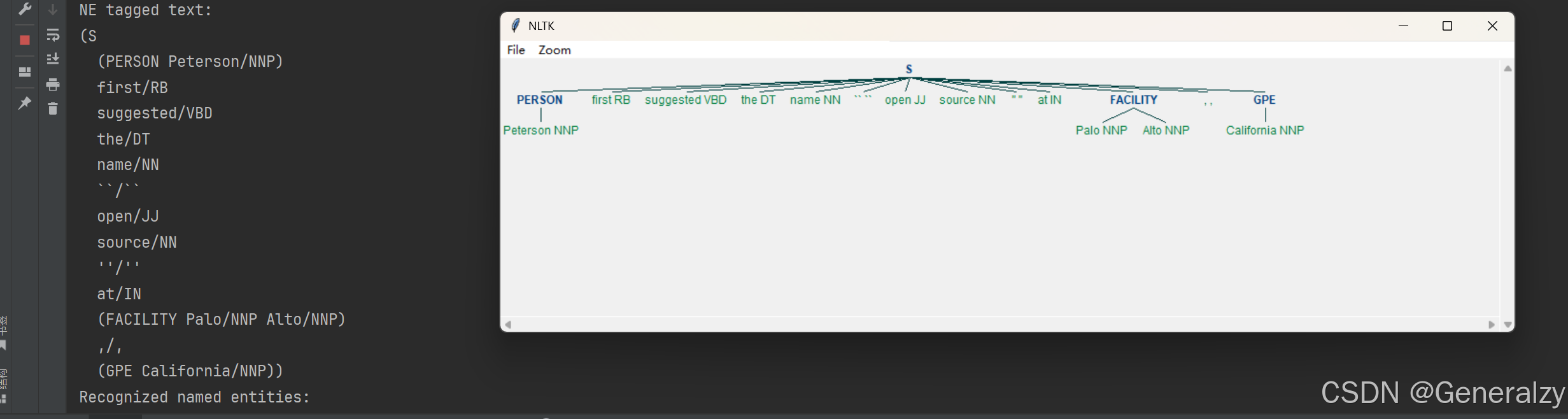
NLTK 内置的命名实体标注器(named-entity tagger),使用的是宾州法尼亚大学的 Automatic Content Extraction(ACE)程序。该标注器能够识别 组织机构(ORGANIZATION) 、人名(PERSON) 、地名(LOCATION) 、设施(FACILITY)和地缘政治实体(geopolitical entity)等常见实体(entites)。
NLTK 也可以使用其他标注器(tagger),比如 Stanford Named Entity Recognizer. 这个经过训练的标注器用 Java 写成,但 NLTK 提供了一个使用它的接口(详情请查看 nltk.parse.stanford 或 nltk.tag.stanford)。
Text对象
Text对象是NLTK库中的一个类,主要用于处理和分析文本数据。它提供了一些有用的方法和功能,使得文本分析更加方便和直观。
from nltk.tokenize import sent_tokenize, word_tokenize # 导入 分句、分词模块
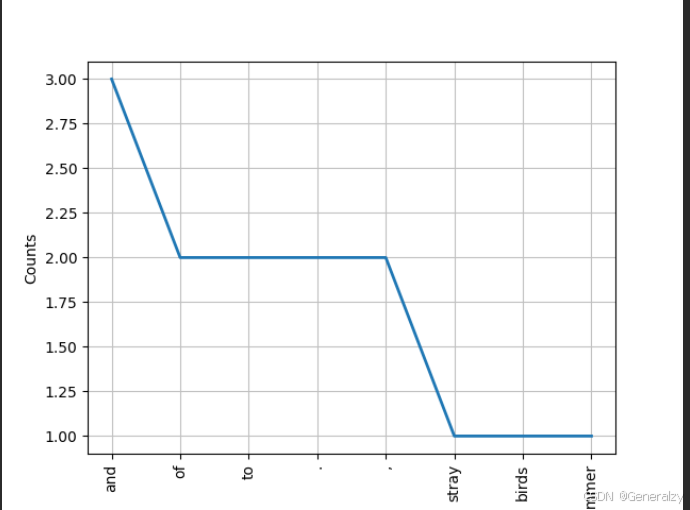
example_text = "Stray birds of summer come to my window to sing and fly away. And yellow leaves of autumn,which have no songs,flutter and fall there with a sigh."
word_tokens = word_tokenize(example_text)
word_tokens = [word.lower() for word in word_tokens]
from nltk.text import Text
t = Text(word_tokens)
print(t.count('and'))
print(t.index('and'))
t.plot(8)
import matplotlib.pyplot as plt
# plt.xticks(rotation=45) # 旋转45度
plt.xticks(rotation=0, ha='center') # 标签水平显示
plt.show()
文本分类
import nltk # 导入NLTK库
import random # 导入随机库
from nltk.corpus import movie_reviews # 从NLTK导入电影评论语料库
# 创建文档列表,每个文档是一个元组,包含分词后的评论和对应的类别
documents = [(list(movie_reviews.words(fileid)), category)
for category in movie_reviews.categories() # 遍历每个类别
for fileid in movie_reviews.fileids(category)] # 遍历该类别下的每个文件
random.shuffle(documents) # 随机打乱文档顺序
# 打印随机选择的一个文档(评论和类别)
print(documents[1])
all_words = [] # 初始化一个空列表,用于存储所有单词
# 遍历所有电影评论中的单词,将其转为小写并添加到列表中
for w in movie_reviews.words():
all_words.append(w.lower())
# 使用FreqDist计算单词频率
all_words = nltk.FreqDist(all_words)
# 打印出现频率最高的15个单词及其频率
print(all_words.most_common(15))
# 打印单词"stupid"的出现次数
print(all_words["stupid"])
其他分类器
下面列出的是NLTK中自带的分类器:
from nltk.classify.api import ClassifierI, MultiClassifierI
from nltk.classify.megam import config_megam, call_megam
from nltk.classify.weka import WekaClassifier, config_weka
from nltk.classify.naivebayes import NaiveBayesClassifier
from nltk.classify.positivenaivebayes import PositiveNaiveBayesClassifier
from nltk.classify.decisiontree import DecisionTreeClassifier
from nltk.classify.rte_classify import rte_classifier, rte_features, RTEFeatureExtractor
from nltk.classify.util import accuracy, apply_features, log_likelihood
from nltk.classify.scikitlearn import SklearnClassifier
from nltk.classify.maxent import (MaxentClassifier, BinaryMaxentFeatureEncoding,TypedMaxentFeatureEncoding,ConditionalExponentialClassifier
通过名字预测性别:
import nltk # 导入NLTK库
from nltk.corpus import names # 从NLTK导入名字语料库
from nltk import classify # 导入分类模块
# 定义特征提取函数,提取单词的最后一个字母
def gender_features(word):
return {'last_letter': word[-1]} # 返回一个字典,包含最后一个字母
# 数据准备:将男名和女名的标签组合成一个列表
name = [(n, 'male') for n in names.words('male.txt')] + [(n, 'female') for n in names.words('female.txt')]
print(len(name)) # 打印总数据量
# 特征提取和训练模型
features = [(gender_features(n), g) for (n, g) in name] # 提取特征
classifier = nltk.NaiveBayesClassifier.train(features[:6000]) # 训练朴素贝叶斯分类器,使用前6000条数据
# 测试分类器
print(classifier.classify(gender_features('Frank'))) # 分类测试名字 'Frank'
print(classify.accuracy(classifier, features[6000:])) # 计算并打印模型在测试集上的准确率
print(classifier.classify(gender_features('Tom'))) # 分类测试名字 'Tom'
print(classify.accuracy(classifier, features[6000:])) # 计算并打印模型在测试集上的准确率
print(classifier.classify(gender_features('Sonya'))) # 分类测试名字 'Sonya'
print(classify.accuracy(classifier, features[6000:])) # 计算并打印模型在测试集上的准确率

情感分析:
import nltk.classify.util # 导入NLTK的分类工具
from nltk.classify import NaiveBayesClassifier # 导入朴素贝叶斯分类器
from nltk.corpus import names # 导入名字语料库
# 定义特征提取函数,将单词列表转换为特征字典
def word_feats(words):
return dict([(word, True) for word in words]) # 每个单词作为键,值为True
# 数据准备:定义积极、消极和中性词汇
positive_vocab = ['awesome', 'outstanding', 'fantastic', 'terrific', 'good', 'nice', 'great', ':)']
negative_vocab = ['bad', 'terrible', 'useless', 'hate', ':(']
neutral_vocab = ['movie', 'the', 'sound', 'was', 'is', 'actors', 'did', 'know', 'words', 'not']
# 特征提取:将每个词汇的特征提取出来并标记其情感
positive_features = [(word_feats(pos), 'pos') for pos in positive_vocab]
negative_features = [(word_feats(neg), 'neg') for neg in negative_vocab]
neutral_features = [(word_feats(neu), 'neu') for neu in neutral_vocab]
# 合并训练集
train_set = negative_features + positive_features + neutral_features # 将所有特征合并为训练集
# 训练分类器
classifier = NaiveBayesClassifier.train(train_set) # 使用训练集训练朴素贝叶斯分类器
# 测试
neg = 0 # 初始化消极计数
pos = 0 # 初始化积极计数
sentence = "Awesome movie, I liked it" # 要测试的句子
sentence = sentence.lower() # 转换为小写
words = sentence.split(' ') # 按空格分词
# 对句子中的每个单词进行分类
for word in words:
classResult = classifier.classify(word_feats(word)) # 分类单词
if classResult == 'neg': # 如果分类为消极
neg += 1 # 增加消极计数
if classResult == 'pos': # 如果分类为积极
pos += 1 # 增加积极计数
# 打印每种情感的比例
print('Positive: ' + str(float(pos) / len(words))) # 打印积极情感的比例
print('Negative: ' + str(float(neg) / len(words))) # 打印消极情感的比例
Positive: 0.6
Negative: 0.2
总结
以下是NLTK(Natural Language Toolkit)的优缺点总结:
优点
-
功能丰富:NLTK提供了大量的文本处理和自然语言处理(NLP)工具,包括分词、词性标注、命名实体识别、句法分析等。
-
易于学习:NLTK的文档详细,示例丰富,适合初学者学习和理解自然语言处理的基本概念和技术。
-
社区支持:作为一个广泛使用的库,NLTK有一个活跃的用户社区,可以在论坛和在线资源中找到许多支持和解决方案。
-
数据集和语料库:NLTK内置了多种语言的语料库和数据集,方便用户进行研究和实验。
-
跨平台:NLTK是用Python编写的,因此可以在不同操作系统上使用,包括Windows、macOS和Linux。
缺点
-
性能问题:对于大规模文本处理,NLTK的性能可能较低,不如一些其他高性能的库(如spaCy)。
-
复杂性:虽然NLTK功能强大,但其API和工具可能会让初学者感到复杂,尤其是对于更高级的操作。
-
依赖性:NLTK有许多外部依赖,对于某些功能,用户可能需要安装额外的库或工具。
-
更新频率:相比一些新兴的NLP库(如Hugging Face的Transformers),NLTK在某些现代技术(如深度学习)方面的更新可能不够及时。
-
文档复杂性:尽管文档详细,但由于功能庞杂,初学者可能难以迅速找到所需的具体信息。
-
中文支持较差:中文支持方面,NLTK的数据包里很少有chinese的字眼,如果处理中文字符更推荐jieba库。
spaCy
除了NLTK,这几年spaCy的应用也非常广泛,功能与nltk类似,但是功能更强,更新也快,语言处理上也具有很大的优势。(spaCy 是一个用 Python 和 Cython 编写的用于高级自然语言处理的库)
它被广泛应用于各种 NLP 任务,包括信息提取、文本分类、命名实体识别、句法分析等。无论是学术研究还是实际应用,spaCy 都是一个强大的选择。 以下是 spaCy 的一些主要特点和功能:
高效的文本处理:spaCy 是一个高度优化的库,具有出色的性能和速度。它使用 Cython 编写,以提供快速的文本处理和分析能力。
多语言支持:spaCy 支持多种语言,包括英语、德语、法语、西班牙语、荷兰语、意大利语等。每种语言都有专门训练的模型和语言特定的功能。
分词(Tokenization):spaCy 可以将文本拆分为单个的语言单元,如单词、标点符号和符号。这是自然语言处理的基础步骤,为后续的处理任务提供了基础。
词性标注(Part-of-Speech Tagging):spaCy 可以为文本中的每个单词标注其词性,如名词、动词、形容词等。这对于语义分析、语法分析和实体识别很有用。
命名实体识别(Named Entity Recognition):spaCy 可以识别文本中的命名实体,如人名、地名、组织机构等。这对于信息提取、实体关系抽取和文本分类非常有用。
依存句法分析(Dependency Parsing):spaCy 可以分析句子中单词之间的依存关系,并构建句法树。这有助于理解句子的结构和语义关系。
向量表示(Word Vectors):spaCy 提供了训练好的词向量模型,可以将单词表示为向量。这些向量捕捉单词之间的语义和语法关系,可用于文本分类、语义相似度计算等任务。
文本分类和情感分析:spaCy 提供了用于文本分类和情感分析的工具和模型。您可以使用这些模型来对文本进行分类、情感分析、文档聚类等任务。
扩展性和定制化:spaCy 提供了灵活的架构,可以轻松扩展和定制。您可以训练自己的模型、添加自定义的组件和功能,以满足特定的任务需求。
快速开始
使用pip库安装spacy:pip install spacy
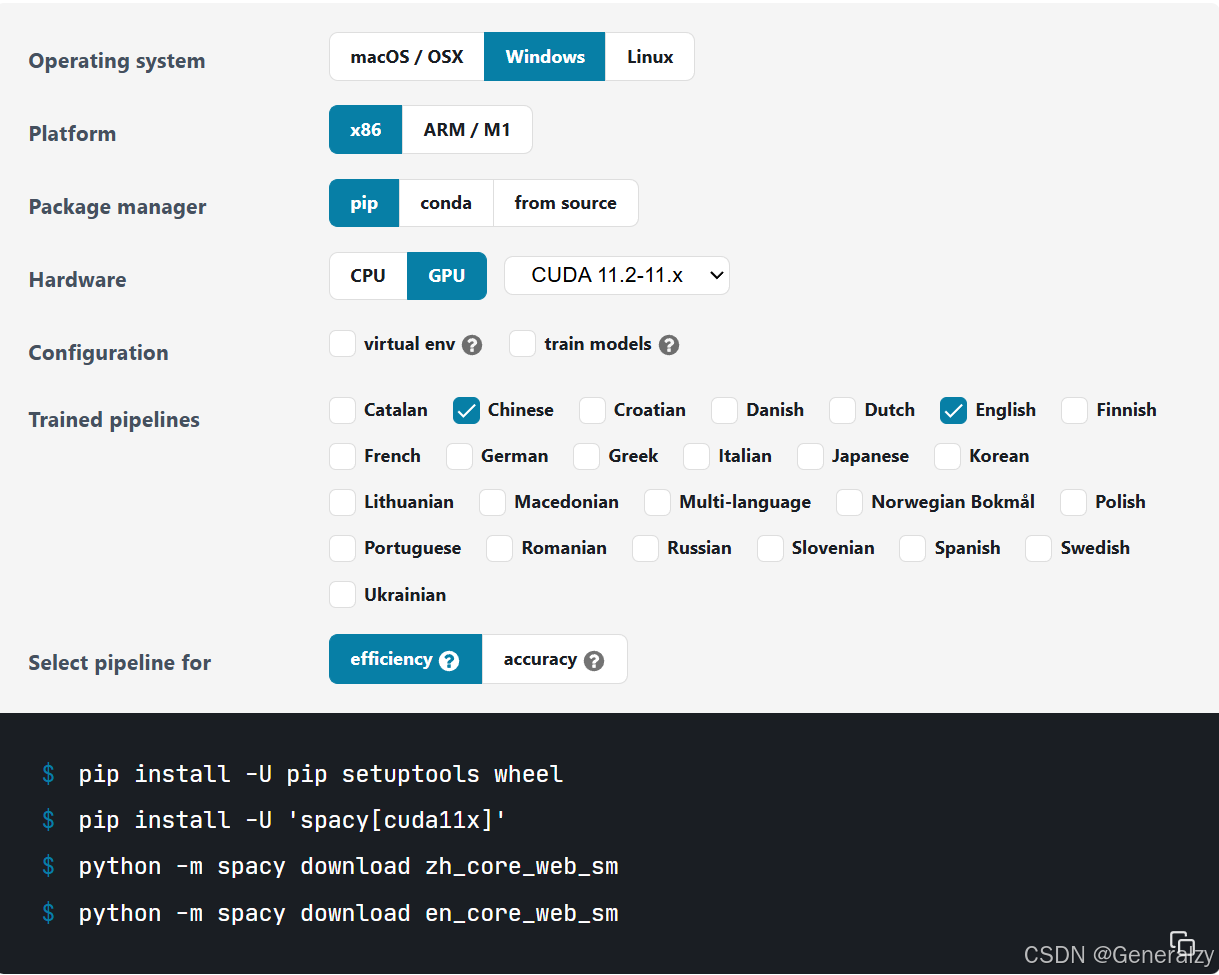
这里涉及到两种常见的模型优化方向:
-
Efficiency (效率):这种选择是针对性能优化的,即模型会更轻量、更快速,适合资源有限或需要实时响应的场景。这类模型通常会牺牲一些准确性以换取更高的处理速度和更少的内存占用。
-
Accuracy (准确性):这种选择是针对精度优化的,即模型会尽可能提高准确性,适合需要更高精度的任务(比如复杂的自然语言处理任务)。这类模型通常会更大、更慢,但预测结果更准确。
选择不同的模型取决于你的具体应用场景。如果你更注重速度,可以选择效率优先的模型;如果你更在意结果的准确性,可以选择精度优先的模型。
使用 GPU 运行 spaCy:spaCy 可以通过指定 spacy[cuda]、spacy[cuda102]、spacy[cuda112]、spacy[cuda113] 等来安装适用于 CUDA 兼容的 GPU 的版本。
pip install -U spacy[cuda113]
一旦你完成了支持 GPU 的安装,激活它的最佳方式是在脚本中加载任何管道之前的某个地方调用 spacy.prefer_gpu() 或 spacy.require_gpu()。require_gpu() 如果没有可用的 GPU 会抛出错误。
安装CUDA,定位到 CUDA Toolkit Archive 页面:
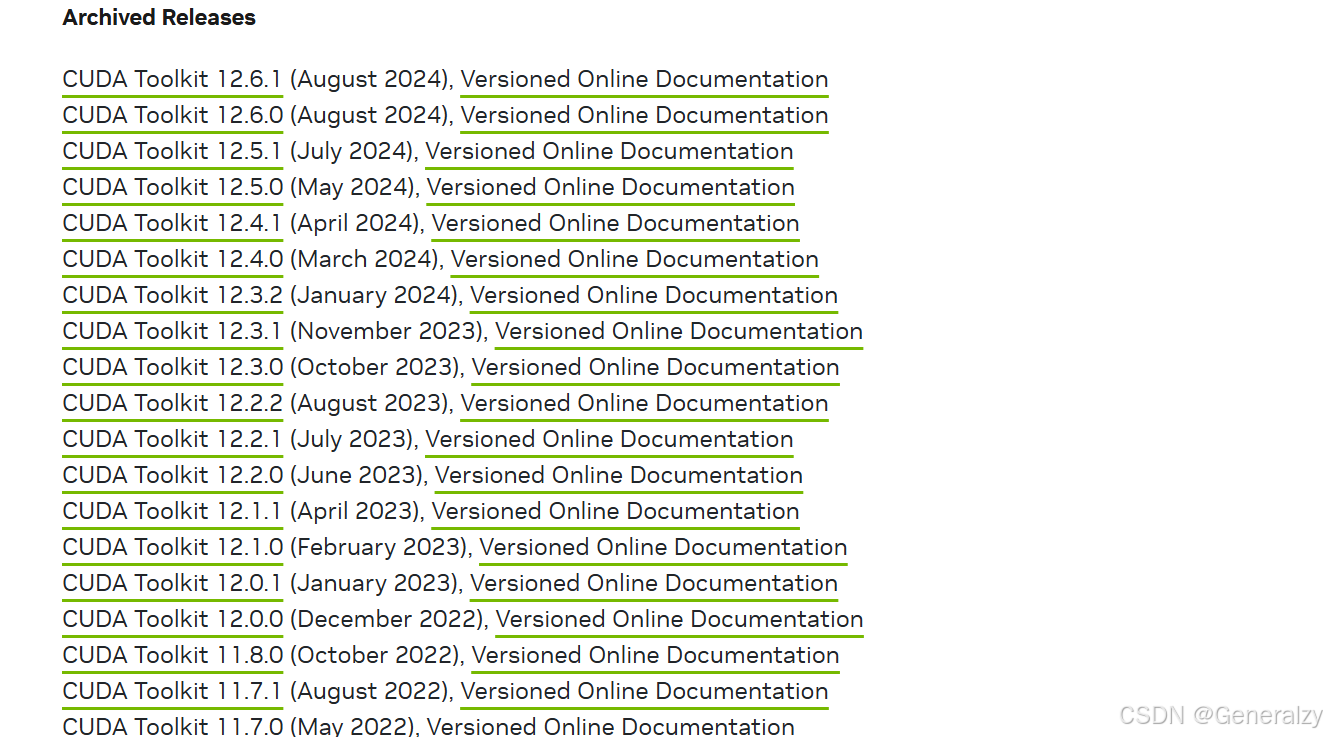
在此处根据刚才运行 nvidia-smi 得到的适合你显卡当前驱动的 CUDA 版本,下载对应版本的 CUDA 并安装。例如我这里是 CUDA 12.3,就选择 CUDA 12.3 的最新版本 CUDA Toolkit 12.3.0 并下载安装。

运行以下命令,应当能够看到终端显示相应的 CUDA 信息:
$ nvcc -V
安装好后,进去环境变量可以看到多了CUDA_PATH:

安装[cuDNN](可选)(https://developer.nvidia.com/rdp/cudnn-archive)(cuDNN(CUDA Deep Neural Network library)是 NVIDIA 提供的一个专门为深度学习优化的 GPU 加速库。它提供了高度优化的实现,用于在 NVIDIA GPU 上运行深度学习任务,可以显著提高训练和推理的速度。)
在这里下载对应你刚刚安装的 CUDA 版本的 cuDNN,并解压压缩包。
下载“Local Installer for Windows (Zip)”并解压,然后,将其中的文件移动到 CUDA 的安装目录(选择覆盖)。在 Windows 下,通常为 C:\Program Files\NVIDIA GPU Computing Toolkit\CUDA\v<版本号>\.
然后进入该目录下的 extras/demo_suite/ 目录,在终端中依次输入以下命令:
$ ./bandwidthTest
$ ./deviceQuery
若均输出 Result = PASS,说明安装成功!
然后就可以Run spaCy with GPU:
import spacy
spacy.prefer_gpu()
nlp = spacy.load("en_core_web_sm")
模型安装
Language support
| Language | Code | Language Data | Pipelines |
|---|---|---|---|
| Catalan | ca | lang/ca
| 4 packages |
| Chinese | zh | lang/zh
| 4 packages |
| Croatian | hr | lang/hr
| 3 packages |
| Danish | da | lang/da
| 4 packages |
| Dutch | nl | lang/nl
| 3 packages |
| English | en | lang/en
| 4 packages |
| Finnish | fi | lang/fi
| 3 packages |
| French | fr | lang/fr
| 4 packages |
| German | de | lang/de
| 4 packages |
| Greek | el | lang/el
| 3 packages |
| Italian | it | lang/it
| 3 packages |
| Japanese | ja | lang/ja
| 4 packages |
| Korean | ko | lang/ko
| 3 packages |
| Lithuanian | lt | lang/lt
| 3 packages |
| Macedonian | mk | lang/mk
| 3 packages |
| Multi-language | xx | lang/xx
| 2 packages |
| Norwegian Bokmål | nb | lang/nb
| 3 packages |
| Polish | pl | lang/pl
| 3 packages |
| Portuguese | pt | lang/pt
| 3 packages |
| Romanian | ro | lang/ro
| 3 packages |
| Russian | ru | lang/ru
| 3 packages |
| Slovenian | sl | lang/sl
| 4 packages |
| Spanish | es | lang/es
| 4 packages |
| Swedish | sv | lang/sv
| 3 packages |
| Ukrainian | uk | lang/uk
| 4 packages |
| Afrikaans | af | lang/af
| none yet |
| Albanian | sq | lang/sq
| none yet |
| Amharic | am | lang/am
| none yet |
| Ancient Greek | grc | lang/grc
| none yet |
| Arabic | ar | lang/ar
| none yet |
| Armenian | hy | lang/hy
| none yet |
| Azerbaijani | az | lang/az
| none yet |
| Basque | eu | lang/eu
| none yet |
| Bengali | bn | lang/bn
| none yet |
| Bulgarian | bg | lang/bg
| none yet |
| Czech | cs | lang/cs
| none yet |
| Estonian | et | lang/et
| none yet |
| Faroese | fo | lang/fo
| none yet |
| Gujarati | gu | lang/gu
| none yet |
| Hebrew | he | lang/he
| none yet |
| Hindi | hi | lang/hi
| none yet |
| Hungarian | hu | lang/hu
| none yet |
| Icelandic | is | lang/is
| none yet |
| Indonesian | id | lang/id
| none yet |
| Irish | ga | lang/ga
| none yet |
| Kannada | kn | lang/kn
| none yet |
| Kyrgyz | ky | lang/ky
| none yet |
| Latin | la | lang/la
| none yet |
| Latvian | lv | lang/lv
| none yet |
| Ligurian | lij | lang/lij
| none yet |
| Lower Sorbian | dsb | lang/dsb
| none yet |
| Luganda | lg | lang/lg
| none yet |
| Luxembourgish | lb | lang/lb
| none yet |
| Malay | ms | lang/ms
| none yet |
| Malayalam | ml | lang/ml
| none yet |
| Marathi | mr | lang/mr
| none yet |
| Nepali | ne | lang/ne
| none yet |
| Norwegian Nynorsk | nn | lang/nn
| none yet |
| Persian | fa | lang/fa
| none yet |
| Sanskrit | sa | lang/sa
| none yet |
| Serbian | sr | lang/sr
| none yet |
| Setswana | tn | lang/tn
| none yet |
| Sinhala | si | lang/si
| none yet |
| Slovak | sk | lang/sk
| none yet |
| Tagalog | tl | lang/tl
| none yet |
| Tamil | ta | lang/ta
| none yet |
| Tatar | tt | lang/tt
| none yet |
| Telugu | te | lang/te
| none yet |
| Thai | th | lang/th
| none yet |
| Tigrinya | ti | lang/ti
| none yet |
| Turkish | tr | lang/tr
| none yet |
| Upper Sorbian | hsb | lang/hsb
| none yet |
| Urdu | ur | lang/ur
| none yet |
| Vietnamese | vi | lang/vi
| none yet |
| Yoruba | yo | lang/yo
| none yet |
spaCy中的几个重要类
- nlp:该对象为spacy.Language类。spacy.load方法会返回该类对象。nlp(“…”)本质就是调了
Language.__call__方法 - doc: 该对象为spacy.tokens.Doc,里面包含分词、词性标注、词形还原等结果。doc是一个可迭代对象。
- token: 该对象为spacy.tokens.token.Token,可以通过该对象获取每个词的具体属性(单词、词性等)。
spaCy基本功能
分词
分词是将文本拆分为单词和标点符号等基本单位的过程,spaCy能够快速完成分词任务。
import spacy
nlp = spacy.load("en_core_web_sm")
# 如果是中文文本,则需要加载中文模型
# nlp = spacy.load("zh_core_web_sm")
text = "This is a sentence."
doc = nlp(text)
for token in doc:
print(token.text)

调用nlp(…)时会按照上图的顺序执行(先分词,然后进行词性标注等等)。对于不需要的组件,可以选择在加载模型时排除掉:
nlp = spacy.load("en_core_web_sm", exclude=["ner"])
或者禁用掉:
nlp = spacy.load("en_core_web_sm", disable=["tagger", "parser"])
对于禁用,可以在后续想要使用的时候解除禁用:
nlp.enable_pipe("tagger")
所有内置的组件可参考:https://spacy.io/usage/processing-pipelines/#built-in
import spacy # 导包
# 加载模型,并排除掉不需要的components
nlp = spacy.load("zh_core_web_sm", exclude=("tagger", "parser", "senter", "attribute_ruler", "ner"))
# 对句子进行处理
doc = nlp("自然语言处理是计算机科学领域与人工智能领域中的一个重要方向。它研究能实现人与计算机之间用自然语言进行有效通信的各种理论和方法。")
# for循环获取每一个token与它对应的向量
for token in doc:
# 这里为了方便展示,只截取5位,但实际该模型将中文词编码成了96维的向量
print(token.text, token.tensor[:5])
在官方提供的模型中,具有tok2vec这个组件,说明该模型可以对词进行embedding,很方便。最终的输出为:
自然 [ 0.37057963 1.8246111 1.2778698 -1.1491573 0.25807345]
语言 [ 0.17374131 -0.6028674 0.18325041 0.5439093 0.7313015 ]
处理 [-1.2380764 -2.3735037 0.63657546 -0.86613274 -1.5722377 ]
是 [-0.41822523 -1.3902699 0.1569121 0.37567973 0.44762707]
计算机 [-1.9590087 -1.7101797 -0.22338031 0.7913982 -0.31995714]
科学 [ 0.47895303 0.50575686 -0.17417973 -0.47532645 0.2037679 ]
领域 [-0.84817874 -0.8591294 0.13159308 1.2329116 0.37335375]
与 [-0.20685983 0.77568436 0.96640897 0.32521546 -0.4828711 ]
人工 [-1.9228098 0.3539041 1.0568599 -0.5931288 0.3723875]
智能 [ 0.6508624 -0.35842282 0.6270751 0.27846795 -0.7966483 ]
领域 [ 0.2145096 -0.8388241 -0.39721316 0.7592155 -0.11900109]
中 [ 0.31644845 0.18976086 -0.9282962 -2.0040188 -1.2477782 ]
的 [ 0.5911485 1.5453231 -2.5450878 -0.19011156 0.31331214]
一个 [-0.49211758 5.1315985 0.10296644 -0.7459179 1.4339893 ]
重要 [-1.682837 1.7616764 0.8204149 -1.5399362 1.5049763]
方向 [-0.05534762 1.1176102 -1.0234172 0.885965 -0.00181088]
。 [ 0.39516658 2.9981542 -0.7763258 -0.14647731 0.04217637]
它 [-2.064271 0.8584736 0.625129 -0.663707 -1.578072 ]
研究 [ 0.47816646 -2.0515437 -0.5179554 -2.127483 1.3120896 ]
能 [-0.06455326 -2.51721 0.30939427 3.3658504 0.48693198]
实现 [-1.6223323 -1.7219106 0.44011796 -0.92396545 -0.586532 ]
人 [-0.7175725 -1.6274955 1.3362231 0.55384713 1.1694282 ]
与 [-0.8587143 0.9526123 1.1991376 -0.3343922 0.9070784]
计算机 [-1.1371363 -1.956463 -1.2402079 1.5108601 -0.3195377]
之间 [ 0.4369435 -0.33879924 -1.2829965 1.0522144 -1.3901919 ]
用 [ 1.7453767 0.68878245 0.18888912 -0.7986256 0.19492418]
自然 [0.731742 0.2653773 0.70852286 0.79221356 0.4884435 ]
语言 [ 0.3116689 -1.2878461 0.4785774 1.5003114 -0.8815767]
进行 [-1.133515 -2.0582328 0.55113536 -0.628343 0.18500859]
有效 [ 0.39359272 1.6873502 0.40150648 -1.1653569 0.8404726 ]
通信 [ 0.6426629 -0.078107 0.06921832 -0.9389324 -1.0591191 ]
的 [-0.4489473 1.559729 -2.6469707 -0.15862937 1.2657177 ]
各种 [-1.2978505 3.0500581 -0.13821274 -1.77615 2.4044495 ]
理论 [-1.4581126 -0.9014263 1.991203 -0.05356146 1.1245289 ]
和 [-0.10766894 1.2422305 2.1004188 -2.4749365 1.7979685 ]
方法 [ 0.90456903 -0.15031374 -0.28229886 0.64082706 -1.3694704 ]
。 [ 2.1772957 2.6481817 -0.46231177 -0.92633843 0.28759593]
词性标注
词性标注是为文本中的每个单词分配一个词性(例如名词、动词等)的过程。spaCy使用预训练模型自动完成词性标注。
for token in doc:
print(token.text, token.pos_)
命名实体识别
命名实体识别(NER)是识别和分类文本中的命名实体(例如人名、地名、公司名等)的过程。spaCy的预训练模型可以自动识别多种类型的命名实体。
for ent in doc.ents:
print(ent.text, ent.label_)
依存关系解析
依存关系解析是确定文本中单词之间的句法关系(如主语、宾语等)的过程。spaCy可以自动分析单词之间的依存关系,从而帮助我们更好地理解文本结构。
for token in doc:
print(token.text, token.dep_, token.head.text)
文本分类
spaCy的文本分类主要依赖于其内置的TextCategorizer组件。首先,需要创建一个训练数据集,然后使用spaCy进行训练。
在处理中文文本分类的时候,spaCy试图加载一个中文分词库(pkuseg),因此需要安装pkuseg库及其相关的预训练模型。
pip install pkuseg
可以从GitHub上pkuseg-python项目的releases页面下载。下载完成后,将预训练模型文件解压缩到一个目录。
创建并配置分词器:
import spacy
from spacy.util import minibatch, compounding
from spacy.pipeline.textcat import Config, single_label_cnn_config
import random
from spacy.lang.zh import Chinese, try_pkuseg_import
from spacy.training import Example
# 创建训练数据
train_data = [
("这是一个好消息。", {"cats": {"POSITIVE": 1.0, "NEGATIVE": 0.0}}),
("我很高兴。", {"cats": {"POSITIVE": 1.0, "NEGATIVE": 0.0}}),
("这是一个糟糕的经历。", {"cats": {"POSITIVE": 0.0, "NEGATIVE": 1.0}}),
("我很沮丧。", {"cats": {"POSITIVE": 0.0, "NEGATIVE": 1.0}})
]
# 加载中文模型
class CustomChineseTokenizer(Chinese):
def initialize(self, get_examples, **kwargs):
self.pkuseg_seg = try_pkuseg_import(pkuseg_model="模型路径", pkuseg_user_dict=None)
return super().initialize(get_examples, **kwargs)
nlp = CustomChineseTokenizer()
# 添加TextCategorizer组件
config = Config().from_str(single_label_cnn_config)
if "textcat" not in nlp.pipe_names:
textcat = nlp.add_pipe("textcat", config=config , last=True)
else:
textcat = nlp.get_pipe("textcat")
# 添加标签
textcat.add_label("POSITIVE")
textcat.add_label("NEGATIVE")
# 训练模型
n_iter = 20
random.seed(1)
spacy.util.fix_random_seed(1)
optimizer = nlp.begin_training()
batch_sizes = compounding(4.0, 32.0, 1.001)
# 更新训练循环
for i in range(n_iter):
losses = {}
batches = minibatch(train_data, size=batch_sizes)
for batch in batches:
examples = []
for text, annotations in batch:
doc = nlp.make_doc(text)
example = Example.from_dict(doc, annotations)
examples.append(example)
nlp.update(examples, sgd=optimizer, drop=0.2, losses=losses)
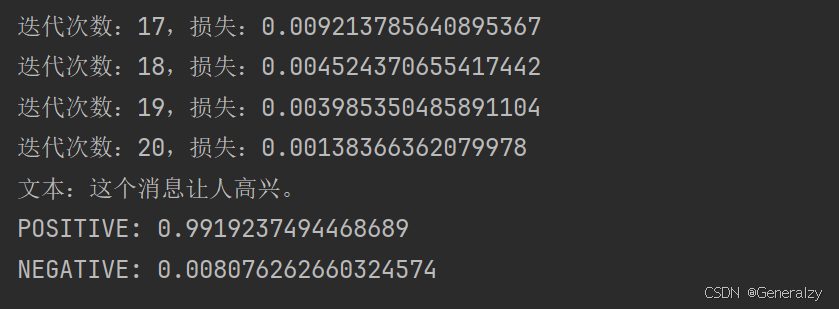
print(f"迭代次数:{i+1},损失:{losses['textcat']}")
# 测试分类器
test_text = "这个消息让人高兴。"
doc = nlp(test_text)
print(f"文本:{test_text}")
for label, score in doc.cats.items():
print(f"{label}: {score}")
训练自定义模型
参考spaCy官方文档的训练自定义模型指南。
FAQ
nvcc warning : The -std=c++11 flag is not supported with the configured host compiler. Flag will be ignored.
这个错误信息表明你在使用 nvcc(NVIDIA 的 CUDA 编译器)时遇到了问题。主要原因是你使用的 Microsoft Visual Studio 版本不在支持的范围内。
为什么spacy.prefer_gpu()会用到vs?
spacy.prefer_gpu() 在使用 GPU 时会涉及到 Visual Studio 编译器的原因主要与底层的 CUDA 和 CuPy 库有关。
-
GPU 加速依赖于 CUDA:
- spaCy 在进行 GPU 加速时,通常依赖于 NVIDIA 的 CUDA 平台。CUDA 是一种并行计算平台和编程模型,用于利用 NVIDIA GPU 进行计算。
- 使用 CUDA 需要编译和链接 GPU 代码,这通常依赖于系统上的 C/C++ 编译器。
-
CuPy 作为 GPU 数组库:
- spaCy 使用 CuPy 作为 GPU 数组库。CuPy 是一个与 NumPy 兼容的库,能够利用 CUDA 提供的 GPU 加速。
- CuPy 在编译某些模块时需要调用
nvcc(NVIDIA 的 CUDA 编译器),并且在某些情况下会需要 C/C++ 编译器(如 Visual Studio 的cl.exe)。
-
Visual Studio 编译器:
nvcc可能会调用系统的 C/C++ 编译器(如 Visual Studio)来编译一些 CUDA 代码。如果系统上未正确配置编译器或使用的编译器不被支持,就会导致错误。- spaCy 和 CuPy 的某些功能在后台会尝试编译和优化 GPU 代码,这就要求系统中必须有适当的编译器可用。
这个错误是由于 CUDA 12.3 的编译器 nvcc 与当前安装的 Microsoft Visual Studio 编译器版本不兼容造成的。具体而言,CUDA 12.3 只支持 Visual Studio 2017 到 2022 版本。
以下是几种解决方案:
-
安装支持的 Visual Studio 版本:如果你当前的 Visual Studio 版本不在 2017 到 2022 之间,可以尝试安装兼容的版本,如 Visual Studio 2019 或 2022,并在 CUDA 工具链中将其设置为默认编译器。
-
使用 CUDA 版本 12.2 或以下:有时切换到较低版本的 CUDA(如 12.2 或 11.x)可以规避不兼容问题,尤其是如果你并不依赖 CUDA 12.3 的特性。安装低版本 CUDA 后,请确保重新配置环境变量并重新编译 CuPy。
-
检查环境变量:在 Windows 上,请确认
CUPY_NVCC和CUDA_PATH等环境变量正确设置,以避免路径问题。 -
使用 CPU:如果 GPU 加速并非必要,可以选择在 Spacy 中强制使用 CPU,通过移除
spacy.prefer_gpu()来解决。
jieba
“结巴”中文分词:做最好的 Python 中文分词组件。
特点:
-
支持四种分词模式:
- 精确模式,试图将句子最精确地切开,适合文本分析;
- 全模式,把句子中所有的可以成词的词语都扫描出来, 速度非常快,但是不能解决歧义;
- 搜索引擎模式,在精确模式的基础上,对长词再次切分,提高召回率,适合用于搜索引擎分词。
- paddle模式,利用PaddlePaddle深度学习框架,训练序列标注(双向GRU)网络模型实现分词。同时支持词性标注。paddle模式使用需安装paddlepaddle-tiny,pip install paddlepaddle-tiny==1.6.1。目前paddle模式支持jieba v0.40及以上版本。jieba v0.40以下版本,请升级jieba,pip install jieba --upgrade 。PaddlePaddle官网:https://www.paddlepaddle.org.cn/
-
支持繁体分词
-
支持自定义词典
-
MIT 授权协议
jieba库是一个优秀的Python中文分词第三方库,主要用于将中文文本切分成词语或词汇单位,便于后续的自然语言处理(NLP)和文本分析任务。
算法实现:
-
基于前缀词典实现高效的词图扫描,生成句子中汉字所有可能成词情况所构成的有向无环图 (DAG)
-
采用了动态规划查找最大概率路径, 找出基于词频的最大切分组合
-
对于未登录词,采用了基于汉字成词能力的 HMM 模型,使用了 Viterbi 算法
快速开始
使用pip安装:pip3 install jieba
如果需要使用paddle模式下的分词和词性标注功能:pip install paddlepaddle-tiny==1.6.1。
基本使用
分词
jieba.cut 方法接受四个输入参数: 需要分词的字符串;cut_all 参数用来控制是否采用全模式;HMM 参数用来控制是否使用 HMM 模型;use_paddle 参数用来控制是否使用paddle模式下的分词模式,paddle模式采用延迟加载方式,通过enable_paddle接口安装paddlepaddle-tiny,并且import相关代码;
jieba.cut_for_search 方法接受两个参数:需要分词的字符串;是否使用 HMM 模型。该方法适合用于搜索引擎构建倒排索引的分词,粒度比较细
待分词的字符串可以是 unicode 或 UTF-8 字符串、GBK 字符串。注意:不建议直接输入 GBK 字符串,可能无法预料地错误解码成 UTF-8
jieba.cut 以及 jieba.cut_for_search 返回的结构都是一个可迭代的 generator,可以使用 for 循环来获得分词后得到的每一个词语(unicode),或者用
jieba.lcut 以及 jieba.lcut_for_search 直接返回 list
jieba.Tokenizer(dictionary=DEFAULT_DICT) 新建自定义分词器,可用于同时使用不同词典。jieba.dt 为默认分词器,所有全局分词相关函数都是该分词器的映射。
# encoding=utf-8
import jieba
jieba.enable_paddle()# 启动paddle模式。 0.40版之后开始支持,早期版本不支持
strs=["我来到北京清华大学","乒乓球拍卖完了","中国科学技术大学"]
for str in strs:
seg_list = jieba.cut(str,use_paddle=True) # 使用paddle模式
print("Paddle Mode: " + '/'.join(list(seg_list)))
seg_list = jieba.cut("我来到北京清华大学", cut_all=True)
print("Full Mode: " + "/ ".join(seg_list)) # 全模式
seg_list = jieba.cut("我来到北京清华大学", cut_all=False)
print("Default Mode: " + "/ ".join(seg_list)) # 精确模式
seg_list = jieba.cut("他来到了网易杭研大厦") # 默认是精确模式
print(", ".join(seg_list))
seg_list = jieba.cut_for_search("小明硕士毕业于中国科学院计算所,后在日本京都大学深造") # 搜索引擎模式
print(", ".join(seg_list))
【全模式】: 我/ 来到/ 北京/ 清华/ 清华大学/ 华大/ 大学
【精确模式】: 我/ 来到/ 北京/ 清华大学
【新词识别】:他, 来到, 了, 网易, 杭研, 大厦 (此处,“杭研”并没有在词典中,但是也被Viterbi算法识别出来了)
【搜索引擎模式】: 小明, 硕士, 毕业, 于, 中国, 科学, 学院, 科学院, 中国科学院, 计算, 计算所, 后, 在, 日本, 京都, 大学, 日本京都大学, 深造
添加自定义词典
开发者可以指定自己自定义的词典,以便包含 jieba 词库里没有的词。虽然 jieba 有新词识别能力,但是自行添加新词可以保证更高的正确率。
用法: jieba.load_userdict(file_name) # file_name 为文件类对象或自定义词典的路径
词典格式和 dict.txt 一样,一个词占一行;每一行分三部分:词语、词频(可省略)、词性(可省略),用空格隔开,顺序不可颠倒。file_name 若为路径或二进制方式打开的文件,则文件必须为 UTF-8 编码。
词频省略时使用自动计算的能保证分出该词的词频。
示例:
云计算 5
李小福 2 nr
创新办 3 i
easy_install 3 eng
好用 300
韩玉赏鉴 3 nz
八一双鹿 3 nz
台中
凱特琳 nz
Edu Trust认证 2000
#encoding=utf-8
from __future__ import print_function, unicode_literals
import sys
sys.path.append("../")
import jieba
jieba.load_userdict("userdict.txt")
import jieba.posseg as pseg
jieba.add_word('石墨烯')
jieba.add_word('凱特琳')
jieba.del_word('自定义词')
test_sent = (
"李小福是创新办主任也是云计算方面的专家; 什么是八一双鹿\n"
"例如我输入一个带“韩玉赏鉴”的标题,在自定义词库中也增加了此词为N类\n"
"「台中」正確應該不會被切開。mac上可分出「石墨烯」;此時又可以分出來凱特琳了。"
)
words = jieba.cut(test_sent)
print('/'.join(words))
print("="*40)
result = pseg.cut(test_sent)
for w in result:
print(w.word, "/", w.flag, ", ", end=' ')
print("\n" + "="*40)
terms = jieba.cut('easy_install is great')
print('/'.join(terms))
terms = jieba.cut('python 的正则表达式是好用的')
print('/'.join(terms))
print("="*40)
# test frequency tune
testlist = [
('今天天气不错', ('今天', '天气')),
('如果放到post中将出错。', ('中', '将')),
('我们中出了一个叛徒', ('中', '出')),
]
for sent, seg in testlist:
print('/'.join(jieba.cut(sent, HMM=False)))
word = ''.join(seg)
print('%s Before: %s, After: %s' % (word, jieba.get_FREQ(word), jieba.suggest_freq(seg, True)))
print('/'.join(jieba.cut(sent, HMM=False)))
print("-"*40)
之前: 李小福 / 是 / 创新 / 办 / 主任 / 也 / 是 / 云 / 计算 / 方面 / 的 / 专家 /
加载自定义词库后: 李小福 / 是 / 创新办 / 主任 / 也 / 是 / 云计算 / 方面 / 的 / 专家 /
调整词典:
-
使用 add_word(word, freq=None, tag=None) 和 del_word(word) 可在程序中动态修改词典。
-
使用 suggest_freq(segment, tune=True) 可调节单个词语的词频,使其能(或不能)被分出来。
-
注意:自动计算的词频在使用 HMM 新词发现功能时可能无效。
>>> print('/'.join(jieba.cut('如果放到post中将出错。', HMM=False)))
如果/放到/post/中将/出错/。
>>> jieba.suggest_freq(('中', '将'), True)
494
>>> print('/'.join(jieba.cut('如果放到post中将出错。', HMM=False)))
如果/放到/post/中/将/出错/。
>>> print('/'.join(jieba.cut('「台中」正确应该不会被切开', HMM=False)))
「/台/中/」/正确/应该/不会/被/切开
>>> jieba.suggest_freq('台中', True)
69
>>> print('/'.join(jieba.cut('「台中」正确应该不会被切开', HMM=False)))
「/台中/」/正确/应该/不会/被/切开
关键词提取
基于 TF-IDF 算法的关键词抽取
import jieba.analyse
- jieba.analyse.extract_tags(sentence, topK=20, withWeight=False, allowPOS=())
- sentence 为待提取的文本
- topK 为返回几个 TF/IDF 权重最大的关键词,默认值为 20
- withWeight 为是否一并返回关键词权重值,默认值为 False
- allowPOS 仅包括指定词性的词,默认值为空,即不筛选
- jieba.analyse.TFIDF(idf_path=None) 新建 TFIDF 实例,idf_path 为 IDF 频率文件
示例:
import sys
sys.path.append('../')
import jieba
import jieba.analyse
from optparse import OptionParser
USAGE = "usage: python extract_tags.py [file name] -k [top k]"
parser = OptionParser(USAGE)
parser.add_option("-k", dest="topK")
opt, args = parser.parse_args()
if len(args) < 1:
print(USAGE)
sys.exit(1)
file_name = args[0]
if opt.topK is None:
topK = 10
else:
topK = int(opt.topK)
content = open(file_name, 'rb').read()
tags = jieba.analyse.extract_tags(content, topK=topK)
print(",".join(tags))
关键词提取所使用逆向文件频率(IDF)文本语料库可以切换成自定义语料库的路径
- 用法: jieba.analyse.set_idf_path(file_name) # file_name为自定义语料库的路径
- 自定义语料库示例:https://github.com/fxsjy/jieba/blob/master/extra_dict/idf.txt.big
- 用法示例:https://github.com/fxsjy/jieba/blob/master/test/extract_tags_idfpath.py
关键词提取所使用停止词(Stop Words)文本语料库可以切换成自定义语料库的路径
- 用法: jieba.analyse.set_stop_words(file_name) # file_name为自定义语料库的路径
- 自定义语料库示例:https://github.com/fxsjy/jieba/blob/master/extra_dict/stop_words.txt
- 用法示例:https://github.com/fxsjy/jieba/blob/master/test/extract_tags_stop_words.py
关键词一并返回关键词权重值示例
- 用法示例:https://github.com/fxsjy/jieba/blob/master/test/extract_tags_with_weight.py
基于 TextRank 算法的关键词抽取:
- jieba.analyse.textrank(sentence, topK=20, withWeight=False, allowPOS=(‘ns’, ‘n’, ‘vn’, ‘v’)) 直接使用,接口相同,注意默认过滤词性。
- jieba.analyse.TextRank() 新建自定义 TextRank 实例
算法论文: TextRank: Bringing Order into Texts
基本思想:
- 将待抽取关键词的文本进行分词
- 以固定窗口大小(默认为5,通过span属性调整),词之间的共现关系,构建图
- 计算图中节点的PageRank,注意是无向带权图
示例:
#encoding=utf-8
from __future__ import unicode_literals
import sys
sys.path.append("../")
import jieba
import jieba.posseg
import jieba.analyse
print('='*40)
print('1. 分词')
print('-'*40)
seg_list = jieba.cut("我来到北京清华大学", cut_all=True)
print("Full Mode: " + "/ ".join(seg_list)) # 全模式
seg_list = jieba.cut("我来到北京清华大学", cut_all=False)
print("Default Mode: " + "/ ".join(seg_list)) # 默认模式
seg_list = jieba.cut("他来到了网易杭研大厦")
print(", ".join(seg_list))
seg_list = jieba.cut_for_search("小明硕士毕业于中国科学院计算所,后在日本京都大学深造") # 搜索引擎模式
print(", ".join(seg_list))
print('='*40)
print('2. 添加自定义词典/调整词典')
print('-'*40)
print('/'.join(jieba.cut('如果放到post中将出错。', HMM=False)))
#如果/放到/post/中将/出错/。
print(jieba.suggest_freq(('中', '将'), True))
#494
print('/'.join(jieba.cut('如果放到post中将出错。', HMM=False)))
#如果/放到/post/中/将/出错/。
print('/'.join(jieba.cut('「台中」正确应该不会被切开', HMM=False)))
#「/台/中/」/正确/应该/不会/被/切开
print(jieba.suggest_freq('台中', True))
#69
print('/'.join(jieba.cut('「台中」正确应该不会被切开', HMM=False)))
#「/台中/」/正确/应该/不会/被/切开
print('='*40)
print('3. 关键词提取')
print('-'*40)
print(' TF-IDF')
print('-'*40)
s = "此外,公司拟对全资子公司吉林欧亚置业有限公司增资4.3亿元,增资后,吉林欧亚置业注册资本由7000万元增加到5亿元。吉林欧亚置业主要经营范围为房地产开发及百货零售等业务。目前在建吉林欧亚城市商业综合体项目。2013年,实现营业收入0万元,实现净利润-139.13万元。"
for x, w in jieba.analyse.extract_tags(s, withWeight=True):
print('%s %s' % (x, w))
print('-'*40)
print(' TextRank')
print('-'*40)
for x, w in jieba.analyse.textrank(s, withWeight=True):
print('%s %s' % (x, w))
print('='*40)
print('4. 词性标注')
print('-'*40)
words = jieba.posseg.cut("我爱北京天安门")
for word, flag in words:
print('%s %s' % (word, flag))
print('='*40)
print('6. Tokenize: 返回词语在原文的起止位置')
print('-'*40)
print(' 默认模式')
print('-'*40)
result = jieba.tokenize('永和服装饰品有限公司')
for tk in result:
print("word %s\t\t start: %d \t\t end:%d" % (tk[0],tk[1],tk[2]))
print('-'*40)
print(' 搜索模式')
print('-'*40)
result = jieba.tokenize('永和服装饰品有限公司', mode='search')
for tk in result:
print("word %s\t\t start: %d \t\t end:%d" % (tk[0],tk[1],tk[2]))
TF-IDF
TF-IDF(Term Frequency-Inverse Document Frequency)是一种用于文本挖掘和信息检索的常用算法,它帮助衡量词语在文档集中的重要性。其核心思想是:某个词语在一篇文档中出现得越频繁,同时在整个文档集中越少见,则该词对该文档的区分度就越高。TF-IDF 算法是文本分类、聚类和搜索引擎的重要基础之一。
1. 算法概念
TF-IDF 由两个部分组成:
- TF(词频):表示一个词在当前文档中出现的频率。
- IDF(逆文档频率):表示一个词在整个文档集中有多普遍。如果一个词在很多文档中都出现,它的 IDF 值就会比较低,因为它对文档区分的贡献不大。
2. 计算公式

3. 具体示例
假设我们有以下 3 篇文档:
- 文档 1:
我 喜欢 学习 机器学习 - 文档 2:
机器学习 是 很有趣 的 - 文档 3:
我 喜欢 编程
目标:计算词语 “学习” 的 TF-IDF 值。
-
计算 TF 值:
- 文档 1 中 “学习” 出现 2 次,总词数为 4,TF = 2/4 = 0.5
- 文档 2 中 “学习” 出现 1 次,总词数为 5,TF = 1/5 = 0.2
- 文档 3 中 “学习” 未出现,TF = 0
-
计算 IDF 值:
- 文档集中有 3 篇文档,其中 2 篇包含 “学习”。
- IDF = ( \log(3/(2+1)) = \log(1) = 0 )
-
计算 TF-IDF 值:
- 对文档 1,“学习” 的 TF-IDF = 0.5 * 0 = 0
- 对文档 2,“学习” 的 TF-IDF = 0.2 * 0 = 0
- 对文档 3,“学习” 的 TF-IDF = 0 * 0 = 0
因此,“学习” 虽然在文档 1 和文档 2 中出现较多,但由于其在整个文档集中出现频率较高(IDF = 0),对文档的区分贡献较低。
4. 实际应用
- 文本相似度计算:可以使用 TF-IDF 表示文档中的词频,然后通过余弦相似度计算不同文档的相似性。
- 特征提取:在机器学习模型中,TF-IDF 值常作为文本分类、情感分析等任务的输入特征。
- 信息检索:搜索引擎使用 TF-IDF 来计算词语对文档的贡献,以提高搜索结果的相关性。
词性标注
- jieba.posseg.POSTokenizer(tokenizer=None) 新建自定义分词器,tokenizer 参数可指定内部使用的 jieba.Tokenizer 分词器。jieba.posseg.dt 为默认词性标注分词器。
- 标注句子分词后每个词的词性,采用和 ictclas 兼容的标记法。
- 除了jieba默认分词模式,提供paddle模式下的词性标注功能。paddle模式采用延迟加载方式,通过enable_paddle()安装paddlepaddle-tiny,并且import相关代码;
>>> import jieba
>>> import jieba.posseg as pseg
>>> words = pseg.cut("我爱北京天安门") #jieba默认模式
>>> jieba.enable_paddle() #启动paddle模式。 0.40版之后开始支持,早期版本不支持
>>> words = pseg.cut("我爱北京天安门",use_paddle=True) #paddle模式
>>> for word, flag in words:
... print('%s %s' % (word, flag))
...
我 r
爱 v
北京 ns
天安门 ns
paddle模式词性标注对应表如下:paddle模式词性和专名类别标签集合如下表,其中词性标签 24 个(小写字母),专名类别标签 4 个(大写字母)。
| 标签 | 含义 | 标签 | 含义 | 标签 | 含义 | 标签 | 含义 |
|---|---|---|---|---|---|---|---|
| n | 普通名词 | f | 方位名词 | s | 处所名词 | t | 时间 |
| nr | 人名 | ns | 地名 | nt | 机构名 | nw | 作品名 |
| nz | 其他专名 | v | 普通动词 | vd | 动副词 | vn | 名动词 |
| a | 形容词 | ad | 副形词 | an | 名形词 | d | 副词 |
| m | 数量词 | q | 量词 | r | 代词 | p | 介词 |
| c | 连词 | u | 助词 | xc | 其他虚词 | w | 标点符号 |
| PER | 人名 | LOC | 地名 | ORG | 机构名 | TIME | 时间 |
并行分词
-
原理:将目标文本按行分隔后,把各行文本分配到多个 Python 进程并行分词,然后归并结果,从而获得分词速度的可观提升
-
基于 python 自带的 multiprocessing 模块,目前暂不支持 Windows
-
用法:
- jieba.enable_parallel(4) # 开启并行分词模式,参数为并行进程数
- jieba.disable_parallel() # 关闭并行分词模式
-
例子:https://github.com/fxsjy/jieba/blob/master/test/parallel/test_file.py
-
实验结果:在 4 核 3.4GHz Linux 机器上,对金庸全集进行精确分词,获得了 1MB/s 的速度,是单进程版的 3.3 倍。
-
注意:并行分词仅支持默认分词器 jieba.dt 和 jieba.posseg.dt。
Tokenize:返回词语在原文的起止位置
注意,输入参数只接受 unicode
默认模式
result = jieba.tokenize(u'永和服装饰品有限公司')
for tk in result:
print("word %s\t\t start: %d \t\t end:%d" % (tk[0],tk[1],tk[2]))
word 永和 start: 0 end:2
word 服装 start: 2 end:4
word 饰品 start: 4 end:6
word 有限公司 start: 6 end:10
搜索模式
result = jieba.tokenize(u'永和服装饰品有限公司', mode='search')
for tk in result:
print("word %s\t\t start: %d \t\t end:%d" % (tk[0],tk[1],tk[2]))
word 永和 start: 0 end:2
word 服装 start: 2 end:4
word 饰品 start: 4 end:6
word 有限 start: 6 end:8
word 公司 start: 8 end:10
word 有限公司 start: 6 end:10
ChineseAnalyzer for Whoosh 搜索引擎
- 引用: from jieba.analyse import ChineseAnalyzer
- 用法示例:https://github.com/fxsjy/jieba/blob/master/test/test_whoosh.py
延迟加载机制:jieba 采用延迟加载,import jieba 和 jieba.Tokenizer() 不会立即触发词典的加载,一旦有必要才开始加载词典构建前缀字典。如果你想手工初始 jieba,也可以手动初始化。
import jieba
jieba.initialize() # 手动初始化(可选)
在 0.28 之前的版本是不能指定主词典的路径的,有了延迟加载机制后,你可以改变主词典的路径:
jieba.set_dictionary('data/dict.txt.big')
例子: https://github.com/fxsjy/jieba/blob/master/test/test_change_dictpath.py
其他词典
-
占用内存较小的词典文件 https://github.com/fxsjy/jieba/raw/master/extra_dict/dict.txt.small
-
支持繁体分词更好的词典文件 https://github.com/fxsjy/jieba/raw/master/extra_dict/dict.txt.big
-
下载你所需要的词典,然后覆盖 jieba/dict.txt 即可;或者用 jieba.set_dictionary(‘data/dict.txt.big’)


















 519
519

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











