







1、HDFS简介
Hadoop1.0与Hadoop2.0结构图

Hadoop 2.0的主要改进有:
1、通过YARN实现资源的调度与管理,从而使Hadoop 2.0可以运行更多种类的计算框架,如Spark等。
2、实现了NameNode的HA方案,即同时有2个NameNode(一个Active另一个Standby),如果ActiveNameNode挂掉的话,另一个NameNode会转入Active状态提供服务,保证了整个集群的高可用。
3、实现了HDFS federation,由于元数据放在NameNode的内存当中,内存限制了整个集群的规模,通过HDFS federation使多个NameNode组成一个联邦共同管理DataNode,这样就可以扩大集群规模。
4、Hadoop RPC序列化扩展性好,通过将数据类型模块从RPC中独立出来,成为一个独立的可插拔模块。
HDFS是一个分布式文件系统,具有高容错的特点。它可以部署在廉价的通用硬件上,提供高吞吐率的数据访问,适合需要处理海量数据集的应用程序。
主要特点:
1、支持超大文件:支持TB级的数据文件。
2、检测和快速应对硬件故障:HDFS的检测和冗余机制很好克服了大量通用硬件平台上的硬件故障问题。
3、高吞吐量:批量处理数据。
4、简化一致性模型:一次写入多次读取的文件处理模型有利于提高吞吐量。
HDFS不适合的场景:低延迟数据访问;大量的小文件;多用户写入文件、修改文件。
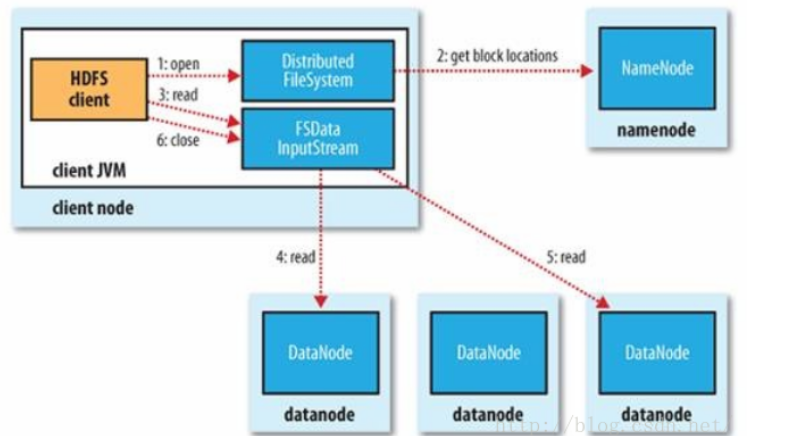
HDFS读写流程
2、YARN原理介绍
产生背景:
Hadoop 1.0的弊端包括:
1、扩展性差
2、可靠性差
3、资源利用率低
4、无法支持多种计算框架
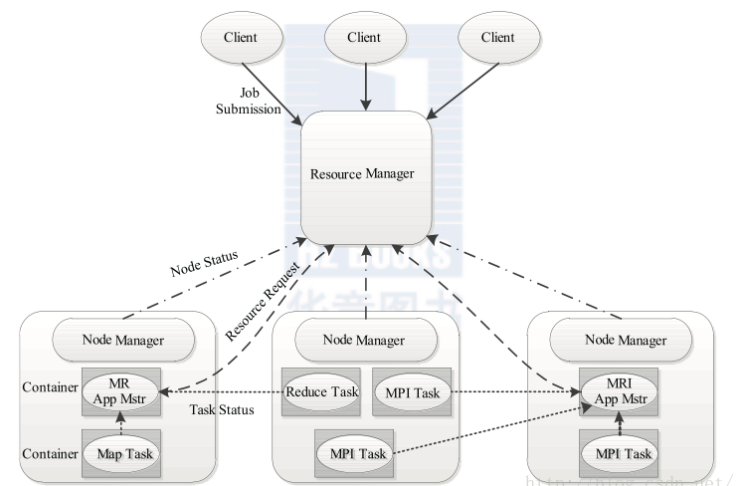
YARN基本架构
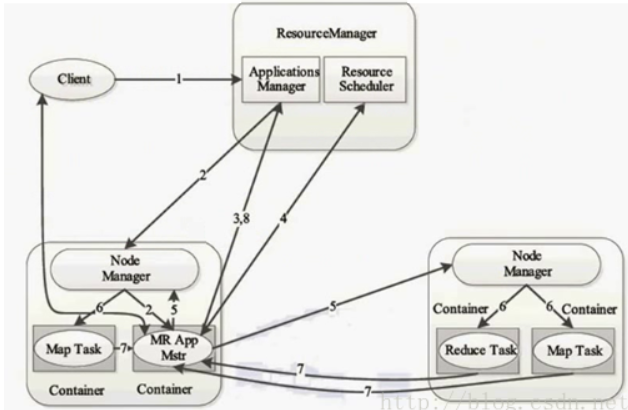
YARN工作流程
3、MapReduce原理介绍
MapReduce是由Google公司研究提出的一种面向大规模数据处理的并行计算模型和方法,是Hadoop面向大数据并行处理的计算模型、框架和平台。
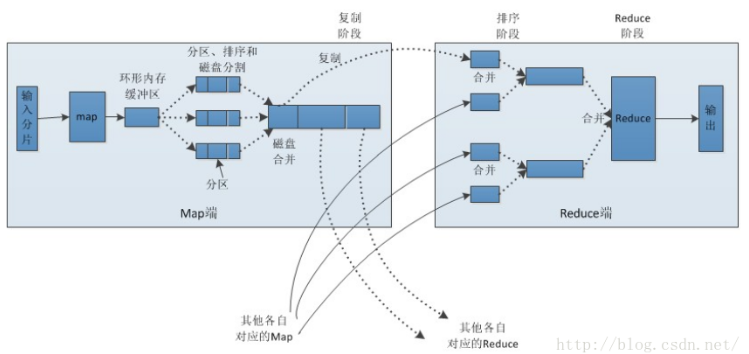
MapReduce执行流包括input、map、shuffle、reduce和output共5个过程

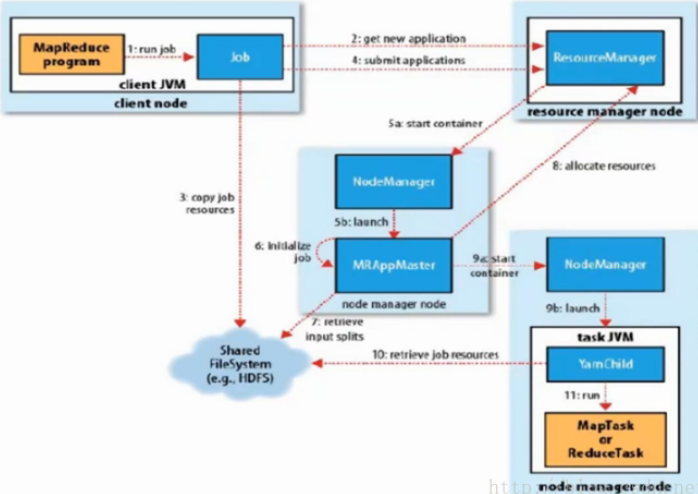
YARN框架下的Mapreduce工作流程:
shuffle及排序:















 609
609











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









