









多元线性回归(Multivariate linear regression)
Attention:下标m表示第m个特征,上标m表示第m组数据。
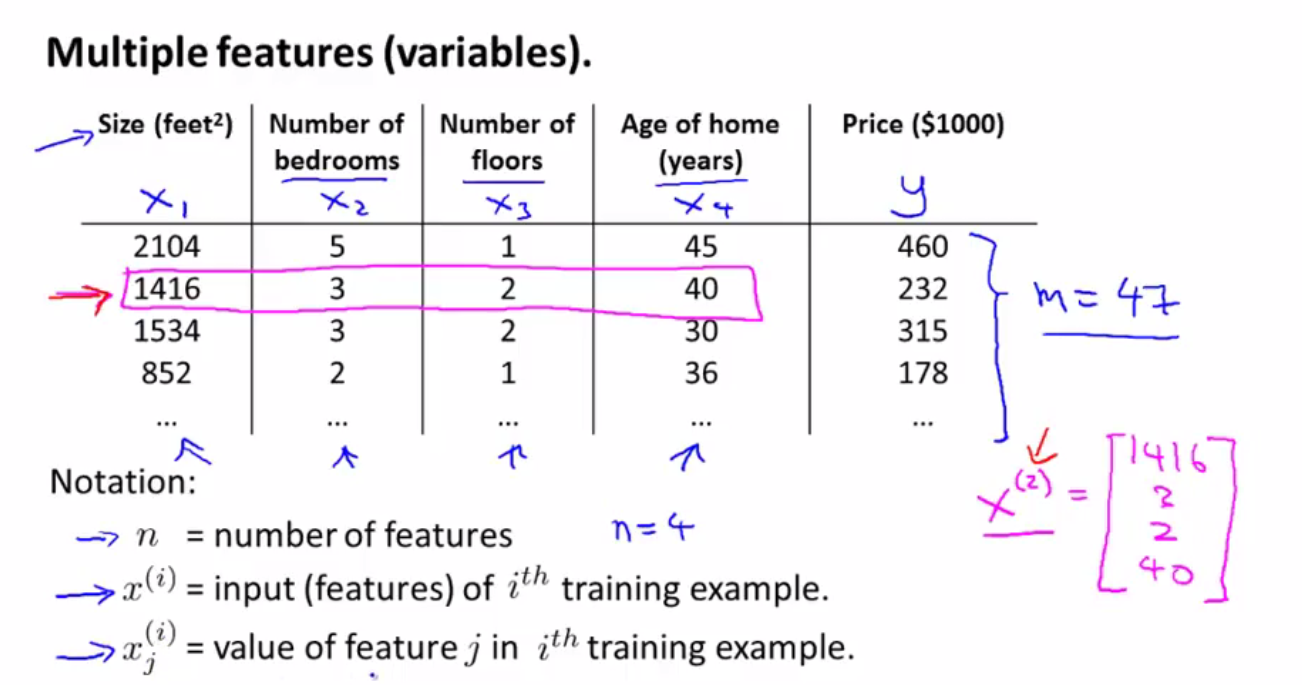
为方便将公式表现为向量相乘,增加变量x0=1【这个x0的数字0是下标,意味着是增加了一个特征(feature)x0】。
所以在计算的时候,要注意如果提起X的下标m时,那么需要注意X的下标m是从0开始,如果提起X的上标n时,那么需要注意X的上标n是从1开始。

例题如下:
多元线性回归的梯度下降法公式:

Ps:一定要谨记:X的上标指代第i组数据 X的下标指代第i个特征值
梯度下降法的实用技巧I:特征缩放(Feature Scaling)
运用这个小技巧 ,可以将梯度下降的速度变得更快,让梯度下降收敛所需要的循环次数更少
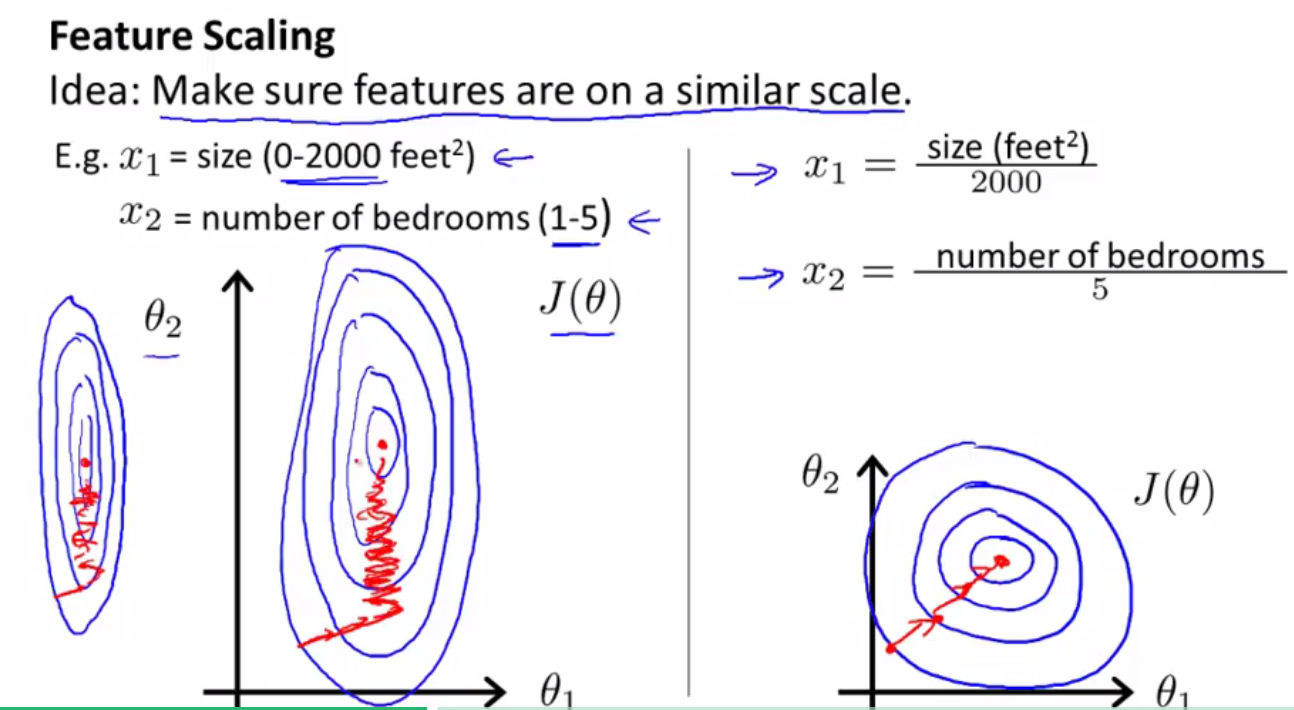
适用情况:如果你有一个机器学习问题,该问题有多个特征,如果你能确定这些特征的取值处在一个相近的范围,这样梯度下降法会更快的收敛。
假设现在需要解决的机器学习问题有两个特征值X1(size)和X2(number of bedrooms),X1取值为0~2000,X2取值为1~5,因为两个变量取值大小差异太大,那么画出来的代价函数J(theta)轮廓图是一个非常高大细长的椭圆,如果在这样的情况下进行梯度下降的话,那么需要花费很长的时间才可以最终收敛到全局最小值,在收敛的过程中可能会来回波动。
在这样的情况下如果采取特征缩放的话:
令x1 = size(feet^2)/2000,x2 = number of bedrooms /5
那么代价函数的轮廓图会更接近一个圆,使用梯度下降法的话也会花费更短的时间收敛到全局最小值。
当然采取特征缩放以后,特征值的取值范围最好在-1~1之间,但是视具体情况决定,如果特征值的取值范围特别特别小,比如说在-0.000001~0.0000001之间的话,也可以采取特征缩放的方法,将特征值的取值范围正常化。
在特征缩放中除了将特征除以最大值以外,还会采取均值归一化的工作。(mean normalization)
这个方法是将原本的特征值x1 替换为 (x1-μ)/(max-min)

梯度下降法的实用技巧II:学习速率(Learning Rate)
通常为了确定合适的学习速率,需要画一个图,横轴为迭代的次数,纵轴为代价函数J(theta)的大小,根据这个图来判断学习速率取值偏大还是取值偏小。

一般观看曲线最右端,是否趋于水平,如果趋于水平的话,那么梯度下降收敛到全局最小值。
还有一个自动收敛测试,来观看每次迭代J(theta)的值的减小量是否比10^-3小,如果是的话则梯度下降已经收敛到全局最小值。(一般不采用这种方法)
同一个机器学习问题采用不同的学习速率,对应的图像曲线如下:
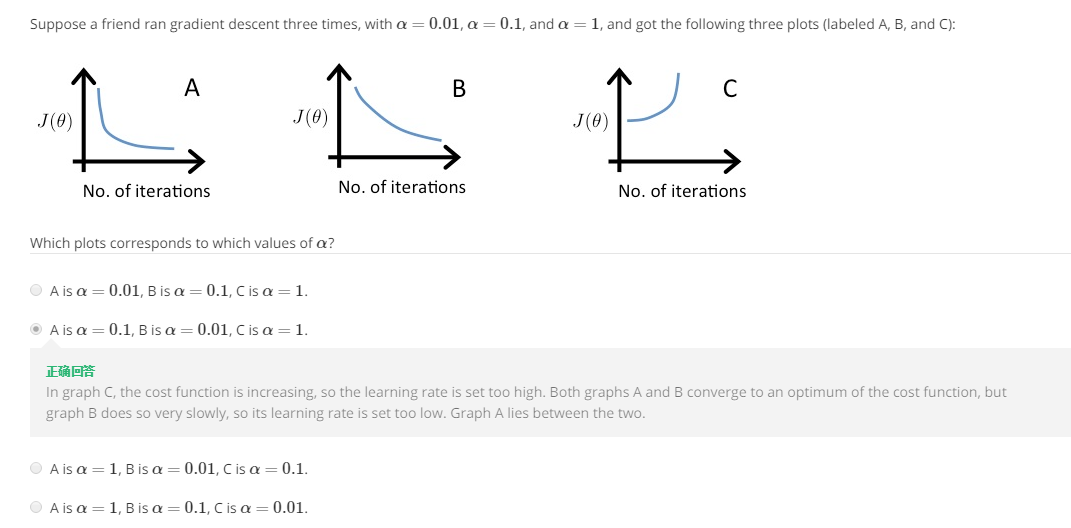
像选项C的那种情况,属于选取的学习速率过大,导致J(theta)无法收敛,甚至发散,使得随着迭代次数的增加,J(theta)的值不降反增。
正常情况下,J(theta)的值随着迭代次数的增加而逐渐下降。
多项式回归:使用线性回归的方法来拟合非常复杂的函数,甚至是非线性函数(如何将一个多项式,如一个二次函数或一个三次函数拟合到数据集上面)
在使用特征时的选择性:通过采取适当的角度来观察,就可以选择出合适的特征来构造更符合自己数据集的模型,比如说不使用房屋的临街宽度和纵深,而使用房子的土地面积(临街宽度*纵深)这个特征
通过使用多项式回归我们可以使用更加复杂的函数来拟合我们的训练集,而不仅仅局限在之前的“使用一根简单直线”,譬如以房价预测为例,我们可以采取三次方程、根号方程来对数据进行拟合,然后对照着线性回归方程,将变量一一对应,多项式回归的X^3可以对应线性回归中的X3变量,以此类推,这就是所谓的多项式回归。
多项式回归(三次方程)和多项式回归(二次方程)如下所示:
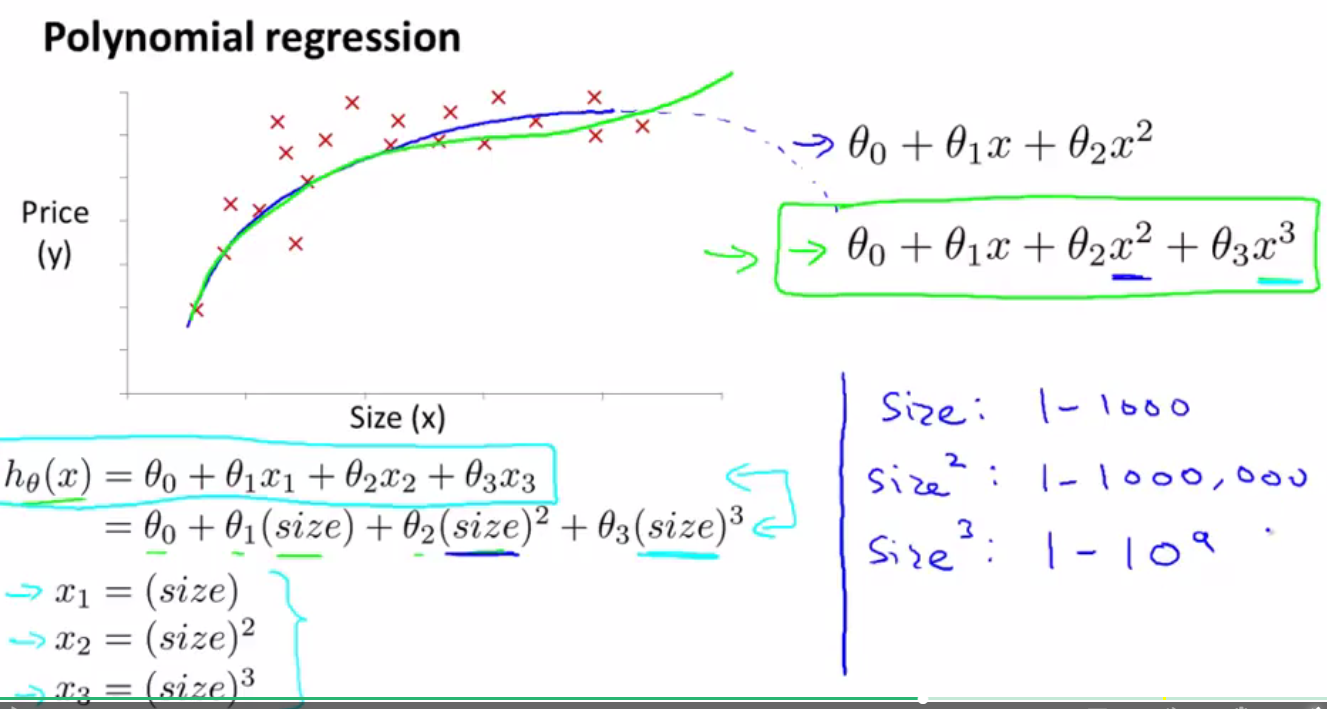
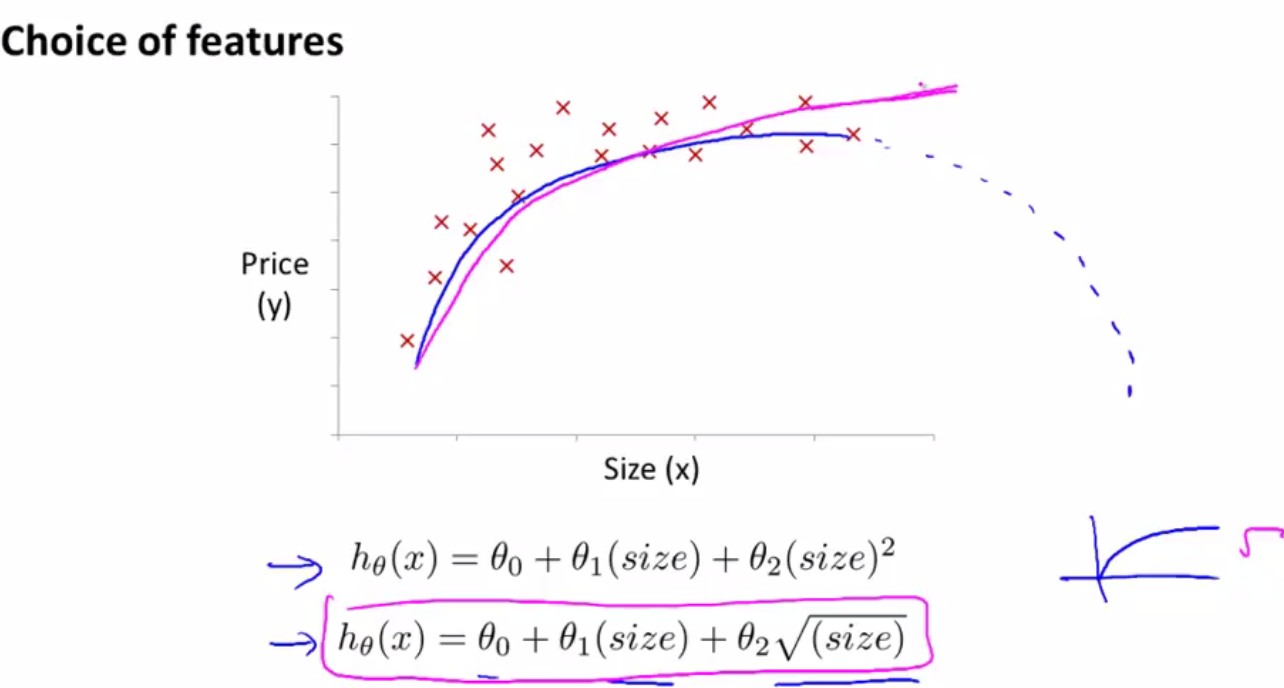
在使用多项式回归的过程中,需要注意的是,因为在多项式回归中,存在着二次方、三次方,所以需要进行变量的归一化(即特征缩放),如下题所示:

正规方程(Normal Equation)
正规方程法的基本思想:代价函数J(theta)是关于theta的函数,(theta可以为一个具体的值,也可以是许多theta集合在一起的向量),根据微积分,当J(theta)的导数为0的时候,J(theta)关于theta的函数图像取min,此时J(theta)最小,对应着也可以求出使得J(theta)最小的theta值。
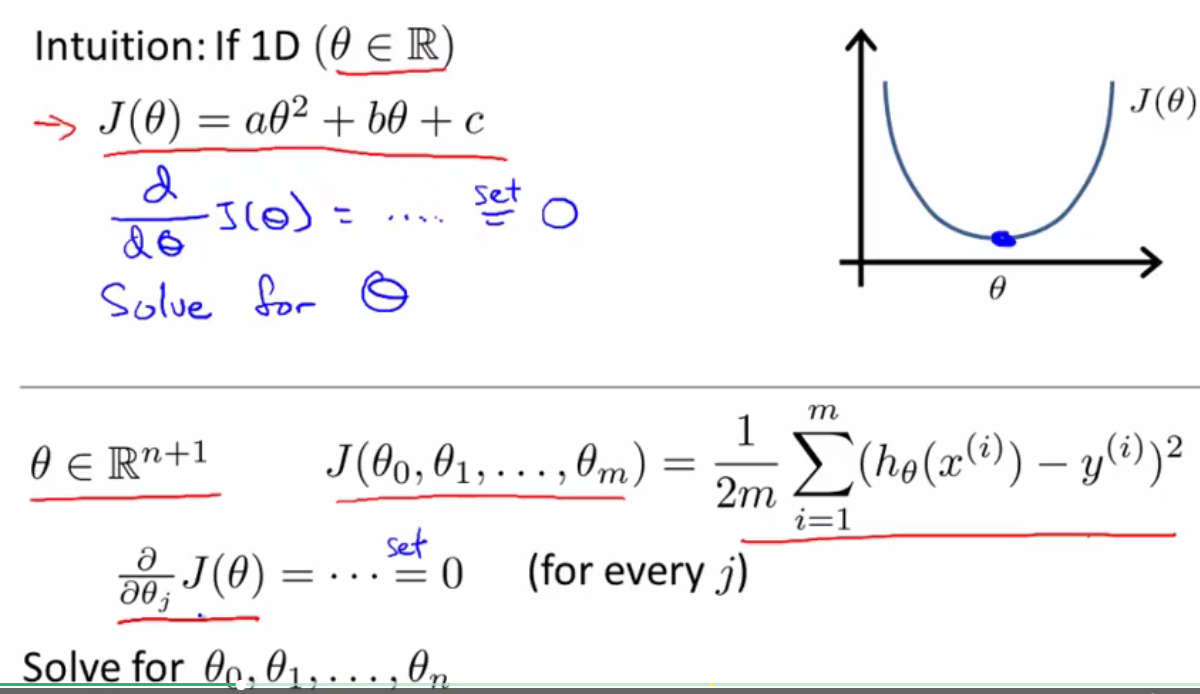
具体操作如下:

Octave中的操作如下:
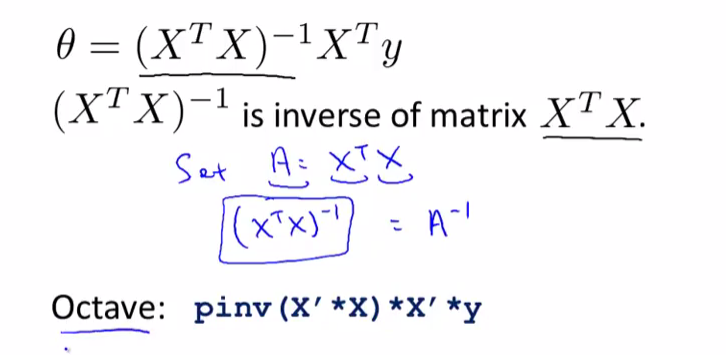
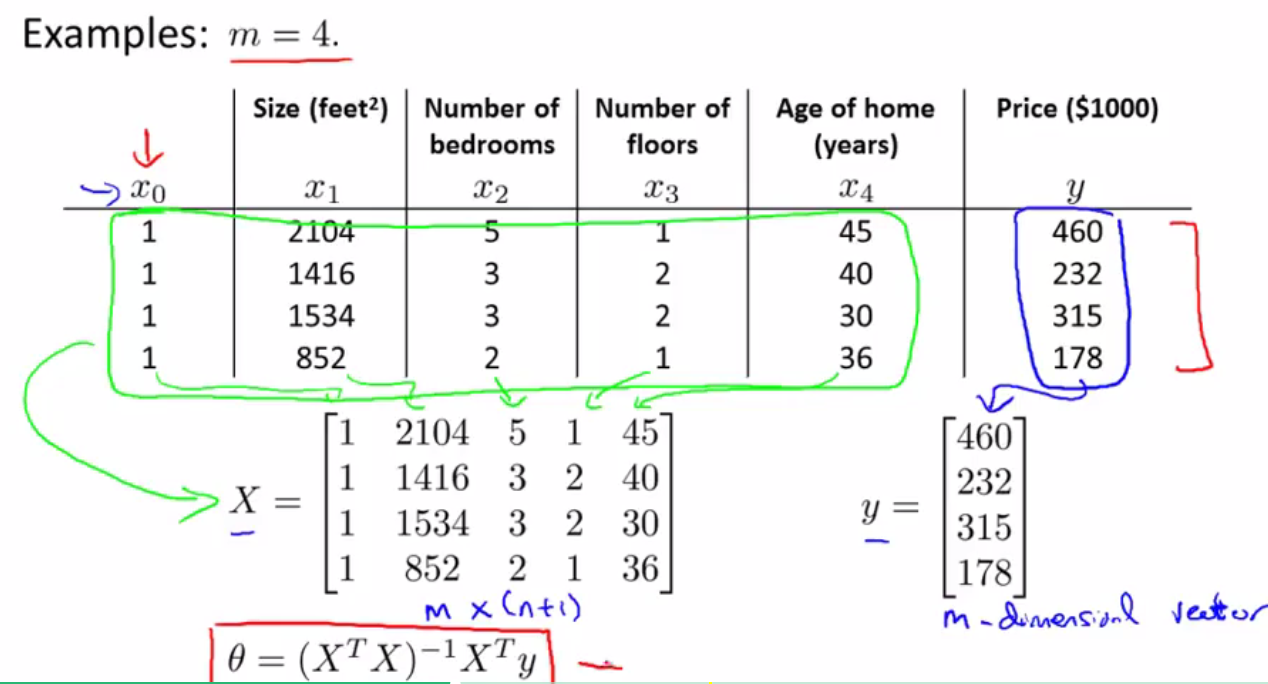
如果使用正规方程来求解机器学习问题的话,那么不需要使用特征变量归一化,即不需要使用特征缩放。It’s OK。
正规方程法和梯度下降法的优劣之分:
随着特征数量的增加,正规方程法完成计算所花费的时间也越来越长,特征数量设为n,那么花费的时间为O(n^3),So:
一般在特征数量在>1W的情况下考虑使用梯度下降法,在特征数量<1W的情况下考虑使用正规方程法。

如果出现X^T*X为不可逆矩阵(奇异矩阵)的话,有两种处理方法:
1、删除冗余的特征,譬如X1与X2线性相关,X1=2.45*X2,这个的话删除X1与X2中的任意一个。
2、删除过多的特征,譬如训练集有十组样本m=10,特征值有n=100个,删除过多的特征。














 804
804











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









