







一、YARN的配置
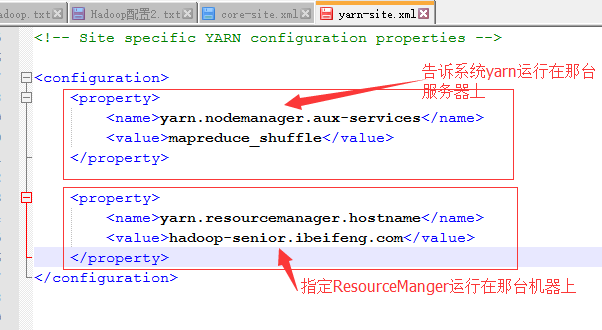
启动命令
$ sbin/yarn-daemon.sh start resourcemanager
$ sbin/yarn-daemon.sh start nodemanager
二、配置MapReduce
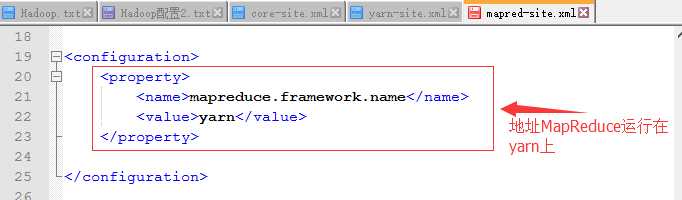
三、运行MapReduce程序案例
要求:写MR程序的一定要有输入和输出的路径
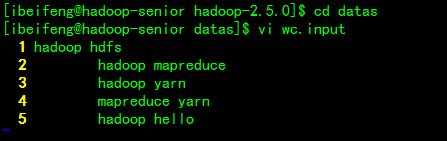
准备数据
$ vi wc.input
hadoop hdfs
hadoop mapreduce
hadoop yarn
mapreduce yarn
hadoop hello
HDFS创建测试目录

HDFS上传数据
input输入路径需要手动创建
output输出路径不需要去手动创建
MapReduce要求输出路径不能存在

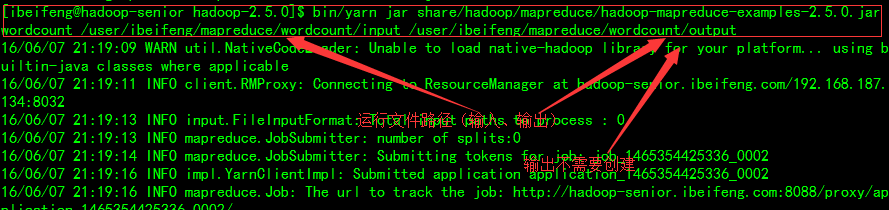
运行wordcount程序
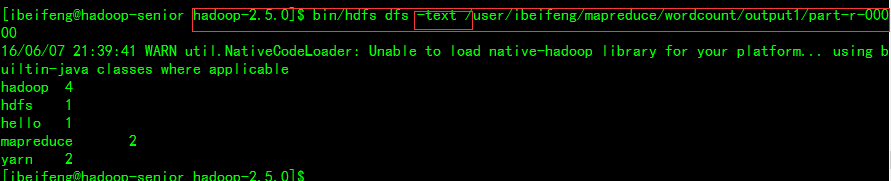
MapReduce的输出结果会对KEY进行排序
查看
四、历史服务器
启动命令:
$ sbin/mr-jobhistory-daemon.sh start historyserver
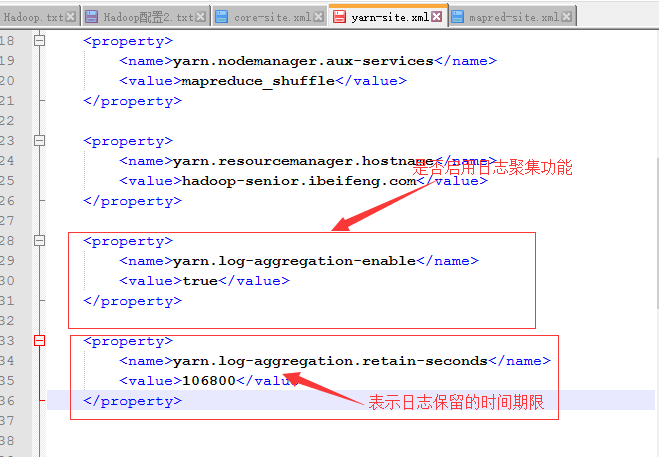
五、日志聚集功能
聚集的概念:
将MR程序运行时产生的日志文件传到HDFS上对应的目录中,然后我们就可以从外部页面去查看HDFS上存储的数据。日志聚集是YARN的中央化的管理功能,日志是有保留的期限的 。
配置文件:yarn-site.xml
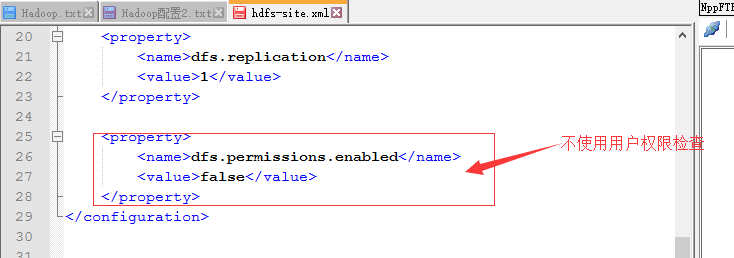
六、HDFS不进行用户权限检测
配置文件:hdfs-site.xml
表示是否启用HDFS文件系统的用户权限检测功能
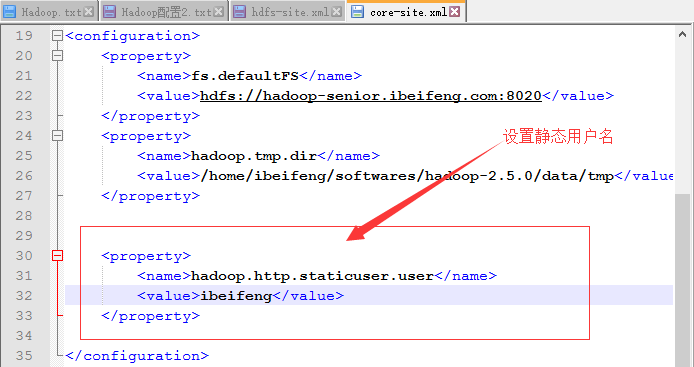
七、修改默认的静态用户名
配置文件:core-site.xml
八、HDFS元数据
数据的属性
名称
位置
存储的块
在哪些节点上
….
HDFS块的大小设置参数
<property>
<name>dfs.blocksize</name>
<value>134217728</value>
<property>
四个模块对应有四个不同的默认配置文件
一定要记住:HDFS设计理念:一次写入,多次读取
HDFS适合:
适合存储大量的超大文件
流式数据访问
适合商用硬件
不适合:
低延时的数据访问
大量小文件
多用户写入、不能任意修改文件
修改文件流程:
如果要修改HDFS上的文件,首先需要下载到本地磁盘,然后将HDFS上的文件删除,接着修改本地磁盘的文件,最后再上传到HDFS上。
系统配置文件:
1、default.xml默认配置文件
2、*-site.xml 自定义配置文件自定义的文件优先级高于默认配置文件。
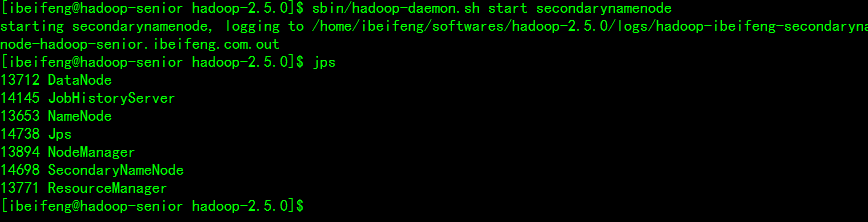
九、SecondaryNameNode
HDFS格式化其实是对于namenode进行格式化
作用是:
产生HDFS初始的元数据,并存储在本地系统文件中,格式化之后会产生fsimage的文件,namenode在启动的时候就会去读取fsimage文件
fsimage:它是在namenode启动时对整个文件系统的快照
editlogs:它是在namenode启动后对文件系统的改动序列
namenode遇到的问题:
只有在namenode重启的时候,fsimage和edit logs才会合并。导致edit logs文件越来越大
edit logs文件越来越大 如何去管理?
namenode重启花费时间长,很多改动需要合并到fsimage上,如果namenode挂掉了,可能会造成丢失
SecondaryNameNode就是为了解决上述的问题
它的作用:***就是将editlogs合并到fsimage文件中 ***
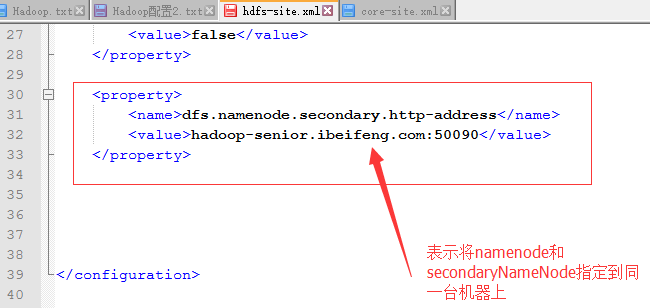
配置文件:hdfs-site.xml
<property>
<name>dfs.namenode.secondary.http-address</name>
<value>hadoop-senior01.ibeifeng.com:50090</value>
</property>
重启:
十、Hadoop本地库
查看系统目录:
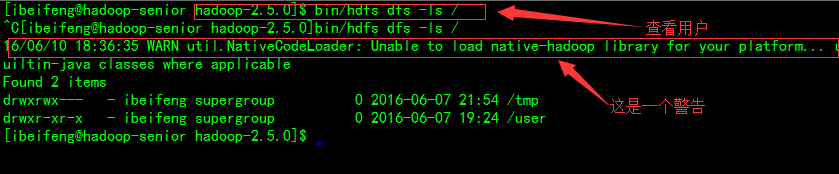
这是一个警告:
不能加载本地库(native-hadoop library)到你的平台上
WARN util.NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable
本地库位置:
/opt/modlues/hadoop-2.5.0/lib下的native目录
报错原因:
是因为native下的文件没有生效引起的
查看版本:
$ bin/hadoop version
版本不一致导致不能加载本地库.

因此需要对Hadoop源码包,进行编译















 44万+
44万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









