







1.从一个示例代码说起
探讨内存屏障的问题基本都会从如下代码作为示例讲解:
//假设a和b初始化为0 ,CPU 0执行foo函数,CPU 1执行bar函数。我们再进一步假设a变量
//在CPU 1的cache中,b在CPU 0 cache中,执行的操作序列如下:
CPU0:
void foo(void) {
a = 1;
b = 1;
}
CPU1:
void bar(void) {
while (b != 1);
assert (a == 1);
}
两方便原因可能导致assert失败:
- 编译层面:
- 如果前后代码无数据依赖关系,如果编译优化选项(-O2或者-O3)级别比较高会发生代码乱序,提升性能。
- 注意:c/c++的关键字volatile只保证内存即使从寄存器回写到主存,没有内存屏障功能,也不保证原子性。
- CPU层面:
- 现在的CPU处理器支持乱序执行(out-of-order)。如果刚刚接触这个概念,十有八九会对乱序执行产生误解,以为是因为单纯的cpu指令乱序执行导致了上面示例代码的assert失败,其实不然。
乱序执行的本质:
乱序执行是说,给定一串执行指令,cpu为了提升执行效率,会找出没有数据依赖的指令,让他们并行执行,但是,执行执行结果写回寄存器是顺序的。哪怕是先被执行的指令,它的运算结果也是按照指令次序写回到最终的寄存器的。这个和很多程序员理解的乱序执行是有区别的。所以在单核处理器系统中,虽然CPU内部支持乱序执行,但是CPU会保证最终执行结果符合程序员的要求,这种情况下不需要使用内存屏障。这里从linux内核内存屏障函数定义也可以看出:
#if defined(CONFIG_ARM_DMA_MEM_BUFFERABLE) || defined(CONFIG_SMP)
#define mb() __arm_heavy_mb()
#define rmb() dsb()
#define wmb() __arm_heavy_mb(st)
#define dma_rmb() dmb(osh)
#define dma_wmb() dmb(oshst)
#else
#define mb() barrier()
#define rmb() barrier()
#define wmb() barrier()
#define dma_rmb() barrier()
#define dma_wmb() barrier()
#endif
可以看到如果是非SMP系统,内存屏障都定义成barrier()函数,这个函数就是编译器层面的内存屏障函数,避免编译器乱序执行代码。
2.为什么SMP系统会乱序
乱序的核心原因是现代cpu为了追求性能,实现的memory model有关,现代cpu内部有store buffer/cache/invaliate queue和缓存一致性协议的方案导致乱序的可能。尤其arm64处理起是强乱序的处理起,读写,写读,读读,写写都可能乱序。
2.1 现代cpu架构存储图:
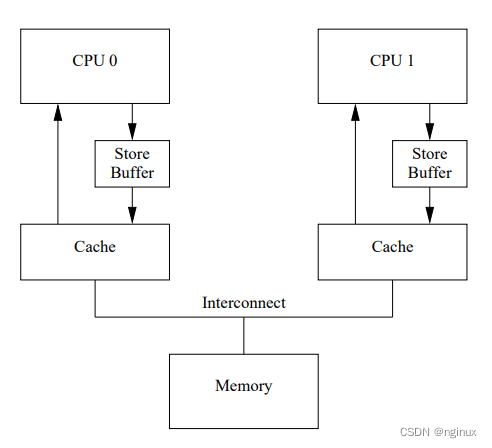
store buffer:
举例说明引入store buffer原因:
- 变量不在cpu的cache中,cpu想修改这个变量,需要发送read invalidate信号,等待信号返回之后才可以写入缓存cache中,如果cpu核数很大,等到每个cpu响应该信号导致性能差。
- 变量量在该CPU缓存中,如果该量的状态是exclusive则直接更改。而如果是shared则需要发 送invalidate消息让其它CPU感知到这一更改后再更改。
有了store buffer之后,cpu可以将变量写入store buffer,然后去忙其他事情,其他cpu响应信号之后再将store buffer中的变量写入缓存。
2.2 store buffer引入的乱序
store buffer提升了性能(本处解释假设不存在invalidate queue,方便理解问题),却引入了复杂性,考虑如下顺序:
- cpu0执行a = 1指令,其cache中值是0,那么由于store buffer的引入,cpu0直接将a = 1写入了store buffer,不需要等待cpu1的信号响应就可以执行b = 1。
- cpu0执行b = 1时,由于b在cpu0中的状态是exclusive独占(可以去参考文章看MESI协议),cpu0直接将b = 1写入了cpu 0 cache中,那么cpu1执行b != 1 成功,然后执行assert( a == 1),由于cpu0需要等到cpu1响应完invalidate才将 a= 1写入cache中(目前还在store buffer中),所以cpu1读取到的任然是0,assert失败。
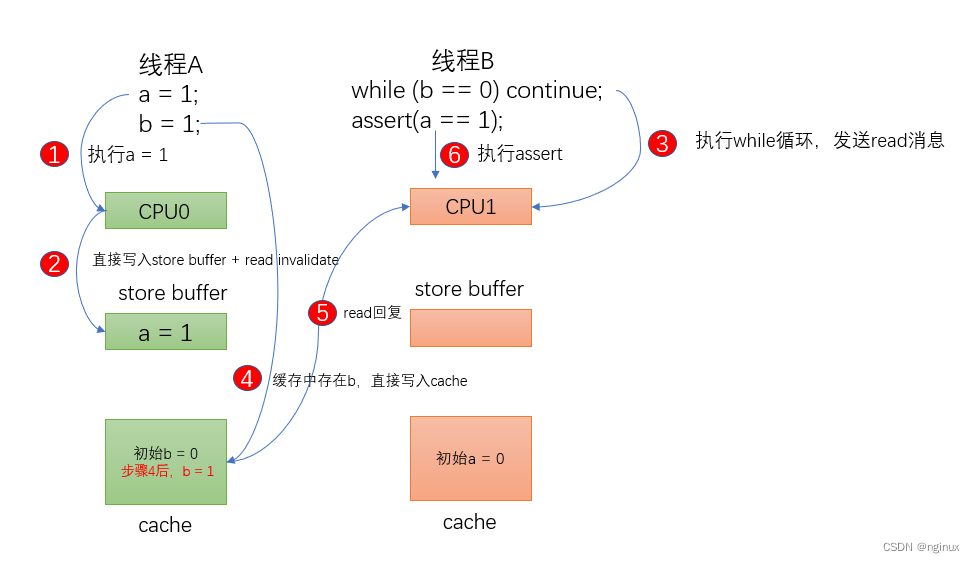
从图例可以看到第六步assert失败的核心原因在于,cpu0上缓存过b,所以cpu0执行b = 1k立马写入cache,然后线程B所在的cpu1执行while(b==0)迅速跳出,然后执行 a = 1,由于此时 a 还在cpu0的store buffer中,所以导致assert失败。
2.3 解决方案
void foo(void) {
a = 1;
smp_wmb();
b = 1;
}
smp_mb保证 b = 1执行前,先把store buffer内存刷新到cache中。CPU1 执行assert( a == 1),发现a 不在cache中,向CPU0发送read消息,CPU0的cache中存在a,所以CPU1获取到a = 1,assert成功。
2.4 invalidate queue引入的乱序
引入原因:
由于store buffer的大小是有限,上面例子中如果cpu1无法快速处理read invalidate消息,那么cpu0中的store buffer马上就会满了,所以arm增加了invalidate queue存放收到invalidate消息,收到invalidate消息放入invalidate queue中,然后给对方(cpu0)发送一个respone响应,但是此时并不真正处理invalidate消息,正因如此,invalidate queue又引入新的复杂性。
invalidate queue导致的乱序:
还是使用上面的代码,始状态CPU0拥有b=0(独有),存有a=0(shared),CPU1存有a=0(shared),CPU0执行foo,CPU1执行bar。

1和2. CPU0 执行 a = 1,由于a是shared的状态,不能直接写入cache,先放入store buffer,发送invalidate消息(等到CPU1响应Invalidate消息才从store buffer写入cache)
3. CPU1执行while 循环,由于cache中不存在b,发送read消息给CPU0。
4.CPU0执行b = 1,由于b是cache独有,直接写入cache
5. CPU1收到Invalidate消息,直接放入invalidate queue
6. CPU1收到read消息回复,同步到b = 1,结束while循环
7. CPU1执行assert,由于此时CPU1未处理invalidate消息,cache中 a = 0,所以assert失败。
这种情况失败的主要原因是,CPU1不及时的处理invalidate queue的消息,导致cache中的数据是失效的。
2.5 解决方案
void bar(void) {
while (b != 1);
smb_rmb();
assert (a == 1);
}
3. 内存屏障指令
参考文章:















 599
599











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









