







上篇:
1.arm64内屏屏障指令
数据存储屏障(DMB)
仅当所有在它前面的的存储器访问操作都执行完毕后,才提交后面的访问指令。DMB保证的是DMB指令之前的所有内存访问指令和DMB之后的所有内存访问指令的执行顺序,也就是说DMB之后的内存访问指令不会被处理起重排到DMB指令前面。DMB不保证内存访问指令在内存屏障之前完成,仅仅保证内存屏障指令的前后内存访问顺序。DMB指令仅仅影响内存访问指令/数据告诉缓存指令及告诉缓存管理指令,并不影响其他指令(例如算数运算指令)的顺序。
数据同步屏障(DSB)
跟DMB区别:比DMB更严格,仅当DSB之前的内存访问指令都执行完成,才会执行DSB之后的指令,即任何指令都要等待DSB指令前面的内存访问指令完成(DMB不保证非内存指令的顺序)。
指令同步屏障(ISB)
2.屏障指令参数
域:DMB和DSB都可以带参数,用于指定共享属性域及具体的访问顺序。ARMV8定义的四种域
- 全系统共享域(full system sharable),指全系统范围。
- 外部共享域(outer sharable)。
- 内部共享域(inner sharable)。
- 不指定共享域(non-sharable)。
看完手册的描述就懵逼了,大白话:Inner是CPU跟CPU之间的域,Outer是CPU之外的,比如DMA和GPU的域。
访存方向:
- 读内存屏障(Load-Load/Store),参数后缀:LD。该内存屏障钱的所有load指令必须完成,但是不需要保证存储指令完成。在读内存屏障后面的加载和存储指令必须等待读内存屏障执行完成。
- 写内存屏障(Store-Store),参数后缀:ST。写内存屏障仅影响存储操作,对于加载操作没影响。
- 读写内存屏障:内存屏障之前的所有读写指令必须在内存屏障之前完成。默认不带LD和ST即为读写屏障。
3.DMB举例
【1】CPU执行如下指令:不需要内存屏障,因为两条指令存在数据依赖关系,CPU会自动保证
ldr x0, [x1]
str x0, [x3]【2】CPU执行如下3条指令:
ldr x0, [x1]
dmb ish //ish = inner sharable,没有LD/ST后缀,为读写屏障
add x2, x3, x4分析:由于dmb指令只限制访存指令,add指令是运算指令,所以add指令可能在ldr指令之前完成。
【3】CPU执行如下4条指令:
ldr, x0, [x2]
dmb ish
add x3, x3, #1
str x4, [x5]分析:ldr和str指令顺序会保证,即STR肯定会观察到LDR的结果,但是由于add是非数据访问指令,可以乱序重排到ldr , x0, x[2]之前执行。
3.DSB指令使用
DSB指令要比DMB指令严格,DSB之后的任何指令必须满足下面两个条件才开始执行:
- DSB之前的所有内存访问指令执行完成。
- DSB之前的高速缓存,分支预测,TLB等维护指令执行完成。
【1】CPU执行如下3条指令:(该例子可以看到dsb和dmb区别)
ldr x0, [x1]
dsb ish
add x2, x3, x4分析:add指令必须要等到dsb指令执行完成才能开始(如果这里用dmb无法保证),add不能重排到ldr之前。对比dmb 【2】例子,此处换成dmb ish add指令就可能乱序,因为dmb无法限制add这种非访存指令。
4.单方向内存屏障指令
DMB和DSB指令是双向限制,即内存屏障前后的访存指令都不能越过内存屏障指令,ARMV8指令集还支持单方向的指令:
- 加载-获取(load-acquire)屏障原语:所有加载-获取内存屏障指令后面的内存访问指令只能在加载-获取内存屏障指令之后才能开始执行,并且被其他CPU观察到。
- 存储-释放(store-release)屏障原语:只有所有存储-释放屏障原语之前的指令完成,才执行store-release之后的指令,这样其他CPU可以观察到store-release之前的指令已经执行完。
5.C++内存屏障
arm64指令集支持了内存屏障指令,c++应用程序程序员在开发多线程程序时可以使用std库中的内存屏障封装,看过很多文章发现c++手册中的解释最清楚:
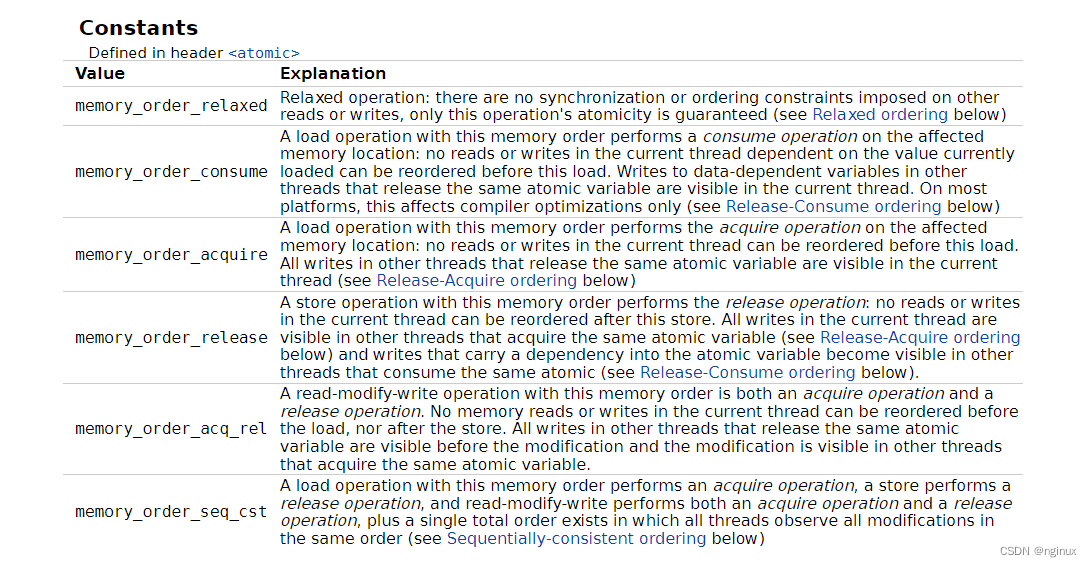
- memory_order_relaxed:只保证原子性,不保证顺序。
- memory_order_acquire:当前线程(CPU)中的读写不能重排到当前读(load)之前。其他线程(CPU)中的写(store-release)同一个原子变量的,对于当前线程(CPU)是可见的。对应arm64中load-acquire单向原语的功能。
- memory_order_release:当前线程中读写操作不能重排到该store之后,当前线程中atomic变量的写操作结果,对于其他线程中acquire同一个atomic变量是可见的。对应arm64中store-release单向原语功能。
- memory_order_acq_rel:当前线程中的读写操作不能重排到load之前或者store之后,等同于acquire release的组合。
- memory_order_seq_cst: 相当于memory_order_acq_rel之外增加了“a single total order”,全局的顺序一致性
memory_order_relaxed使用场景:
典型的使用场景是计数器(累加变量),因为只需要原子性,不需要同步和顺序:
#include <vector>
#include <iostream>
#include <thread>
#include <atomic>
std::atomic<int> cnt = {0};
void f()
{
for (int n = 0; n < 1000; ++n) {
cnt.fetch_add(1, std::memory_order_relaxed);
}
}
int main()
{
std::vector<std::thread> v;
for (int n = 0; n < 10; ++n) {
v.emplace_back(f);
}
for (auto& t : v) {
t.join();
}
std::cout << "Final counter value is " << cnt << '\n';
}memory_order_acquire和memory_order_release使用场景:
If an atomic store in thread A is tagged memory_order_release and an atomic load in thread B from the same variable is tagged memory_order_acquire, all memory writes (non-atomic and relaxed atomic) that happened-before the atomic store from the point of view of thread A, become visible side-effects in thread B. That is, once the atomic load is completed, thread B is guaranteed to see everything thread A wrote to memory. This promise only holds if B actually returns the value that A stored, or a value from later in the release sequence.
The synchronization is established only between the threads releasing and acquiring the same atomic variable. Other threads can see different order of memory accesses than either or both of the synchronized threads.
On strongly-ordered systems — x86, SPARC TSO, IBM mainframe, etc. — release-acquire ordering is automatic for the majority of operations. No additional CPU instructions are issued for this synchronization mode; only certain compiler optimizations are affected (e.g., the compiler is prohibited from moving non-atomic stores past the atomic store-release or performing non-atomic loads earlier than the atomic load-acquire). On weakly-ordered systems (ARM, Itanium, PowerPC), special CPU load or memory fence instructions are used.
Mutual exclusion locks, such as std::mutex or atomic spinlock, are an example of release-acquire synchronization: when the lock is released by thread A and acquired by thread B, everything that took place in the critical section (before the release) in the context of thread A has to be visible to thread B (after the acquire) which is executing the same critical section.
线程A中的原子变量使用memory_order_release store存储值,线程B使用memory_order_acquire load同一个原子变量,线程A中所有在原子变量store之前的所有写操作对线程B是可见的。也就是说,一旦线程B中的load操作完成,线程B可以看到线程A中的写操作。注意,只有在B确实读到了A线程store的原子变量才可以(一般使用while循环load)。
同步性只有在acquire/release同一个原子变量的线程中间保证,其他线程可能看到不同的内存访问次序。互斥锁(比如std::mutex或者spinlock自旋锁),就是release/acquire同步的使用场景。线程A release锁,线程B acquire获取锁,线程A执行过程中的临界区(before the release)执行结果,对于线程B是可见的(after the acquire)。
#include <thread>
#include <atomic>
#include <cassert>
#include <string>
std::atomic<std::string*> ptr;
int data;
void producer()
{
std::string* p = new std::string("Hello");
data = 42;
ptr.store(p, std::memory_order_release);
}
void consumer()
{
std::string* p2;
while (!(p2 = ptr.load(std::memory_order_acquire)))
;
assert(*p2 == "Hello"); // never fires
assert(data == 42); // never fires
}
int main()
{
std::thread t1(producer);
std::thread t2(consumer);
t1.join(); t2.join();
}线程cosume中使用 memory_order_acquire内存屏障,保证了consumer线程后面的所有读写(包括非原子)操作不能重排序到acquire之前,并且consumer的load操作一旦完成,线程producer release之前的读写操作对producer线程可见。所以该实例很好的展示了acquire/release内存屏障的使用场景。
试题:如下程序中assert能否触发?
#include <atomic>
#include <stdio.h>
#include <stdlib.h>
#include <thread>
#include <assert.h>
#include <unistd.h>
std::atomic<bool> x,y;
std::atomic<int> z;
void write_x() {
x.store(true, std::memory_order_release);
}
void write_y() {
y.store(true, std::memory_order_release);
}
void read_x_then_y() {
while(!x.load(std::memory_order_acquire));
if(y.load(std::memory_order_acquire))
++z;
}
void read_y_then_x() {
while(!y.load(std::memory_order_acquire));
if(x.load(std::memory_order_acquire))
++z;
}
int main() {
x = false;
y = false;
z = 0;
std::thread a(write_x);
std::thread b(write_y);
std::thread c(read_x_then_y);
std::thread d(read_y_then_x);
a.join();
b.join();
c.join();
d.join();
assert(z.load() != 0);
} 答案:assert可能失败,即z最终可以是0
我们知道,acquire/release只保证load完成之后,release之前的内存操作在load之后是可见,但是并不保证一个线程中的store(release)操作,立马对其他线程的load(acquire)可见。这其实只有使用memory_order_seq_cst内存屏障才可以。
memory_order_seq_cst:
Atomic operations tagged memory_order_seq_cst not only order memory the same way as release/acquire ordering (everything that happened-before a store in one thread becomes a visible side effect in the thread that did a load), but also establish a single total modification order of all atomic operations that are so tagged.
上面例子中如果使用 memory_order_seq_cst可以保证assert不会失败如下:
#include <thread>
#include <atomic>
#include <cassert>
std::atomic<bool> x = {false};
std::atomic<bool> y = {false};
std::atomic<int> z = {0};
void write_x()
{
x.store(true, std::memory_order_seq_cst);
}
void write_y()
{
y.store(true, std::memory_order_seq_cst);
}
void read_x_then_y()
{
while (!x.load(std::memory_order_seq_cst))
;
if (y.load(std::memory_order_seq_cst)) {
++z;
}
}
void read_y_then_x()
{
while (!y.load(std::memory_order_seq_cst))
;
if (x.load(std::memory_order_seq_cst)) {
++z;
}
}
int main()
{
std::thread a(write_x);
std::thread b(write_y);
std::thread c(read_x_then_y);
std::thread d(read_y_then_x);
a.join(); b.join(); c.join(); d.join();
assert(z.load() != 0); // will never happen
}Sequential ordering may be necessary for multiple producer-multiple consumer situations where all consumers must observe the actions of all producers occurring in the same order.
Total sequential ordering requires a full memory fence CPU instruction on all multi-core systems. This may become a performance bottleneck since it forces the affected memory accesses to propagate to every core.
This example demonstrates a situation where sequential ordering is necessary. Any other ordering may trigger the assert because it would be possible for the threads
canddto observe changes to the atomicsxandyin opposite order.
memory_order_consume:
目前官方不推荐使用,不做讲解。
6. c++ volatile
c++中的关键字和java中的关键词含义不同,接触过java语言的volatile很容易跟c++的volatile含义搞混,c++手册中有如下描述:
Within a thread of execution, accesses (reads and writes) through volatile glvalues cannot be reordered past observable side-effects (including other volatile accesses) that are sequenced-before or sequenced-after within the same thread, but this order is not guaranteed to be observed by another thread, since volatile access does not establish inter-thread synchronization.
In addition, volatile accesses are not atomic (concurrent read and write is a data race) and do not order memory (non-volatile memory accesses may be freely reordered around the volatile access).
总结:
- 编译器不优化volatile变量,变量会立马写回内存
- 只保证多个volatile变量间在单线程内部的顺序,volatile和非volatile顺序还可以乱序
- 不具备原子性。
举例:
int a;
int b;
b = a+ 1; // 语句1
a = 10; // 语句2- 当 a和 b都没有使用 volatile 关键字进行修饰时,编译器会对“语句1”和“语句2”的执行顺序进行优化:即先执行“语句2”、再执行“语句1”;
- 当 b使用 volatile 关键字进行修饰时,编译器也可能会对“语句1”和“语句2”的执行顺序进行优化:即先执行“语句2”、再执行“语句1”;
- 当 a和 b都使用 volatile 关键字进行修饰时,编译器不会对“语句1”和“语句2”的执行顺序进行优化:即先执行“语句1”、再执行“语句2”;


















 272
272

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









