







连接跟踪(connection tracking,conntrack,CT)
原文连接:http://arthurchiao.art/blog/conntrack-design-and-implementation-zh/
本文代码参考linux-6.0.2
概念
连接跟踪,顾名思义,就是跟踪(并记录)连接的状态。
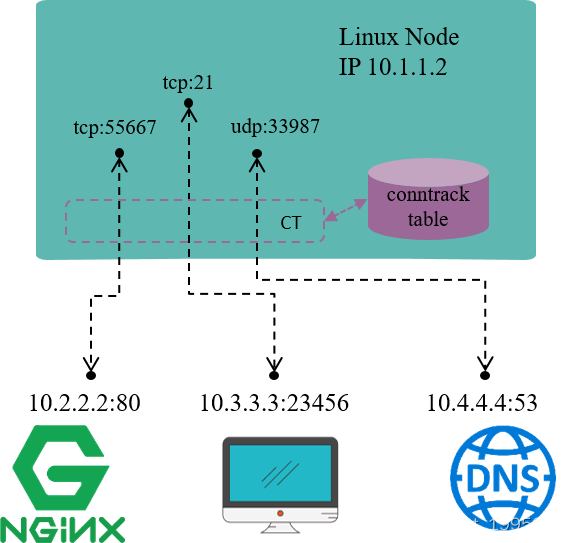
例如,图 1.1 是一台 IP 地址为 10.1.1.2 的 Linux 机器,我们能看到这台机器上有三条连接:
1. 机器访问外部 HTTP 服务的连接(目的端口 80)
2. 外部访问机器内 FTP 服务的连接(目的端口 21)
3. 机器访问外部 DNS 服务的连接(目的端口 53)
连接跟踪所做的事情就是发现并跟踪这些连接的状态,具体包括:
- 从数据包中提取元组(
tuple)信息,辨别数据流(flow)和对应的连接(connection) - 为所有连接维护一个状态数据库(
conntrack table),例如连接的创建时间、发送 包数、发送字节数等等 - 回收过期的连接(
GC) - 为更上层的功能(例如
NAT)提供服务
需要注意的是,连接跟踪中所说的“连接”,概念和 TCP/IP 协议中“面向连接”( connection oriented)的“连接”并不完全相同,简单来说:
- TCP/IP 协议中,连接是一个四层(
Layer 4)的概念。- TCP 是有连接的,或称面向连接的(
connection oriented),发送出去的包都要求对端应答(ACK),并且有重传机制 - UDP 是无连接的,发送的包无需对端应答,也没有重传机制
- TCP 是有连接的,或称面向连接的(
- CT 中,一个元组(
tuple)定义的一条数据流(flow)就表示一条连接(connection)。- 后面会看到 UDP 甚至是 ICMP 这种三层协议在 CT 中也都是有连接记录的
- 但不是所有协议都会被连接跟踪
本文中用到“连接”一词时,大部分情况下指的都是后者,即“连接跟踪”中的“连接”。
原理
要跟踪一台机器的所有连接状态,就需要
- 拦截(或称过滤)流经这台机器的每一个数据包,并进行分析。
- 根据这些信息建立起这台机器上的连接信息数据库(
conntrack table)。 - 根据拦截到的包信息,不断更新数据库
例如:
- 拦截到一个 TCP
SYNC包时,说明正在尝试建立 TCP 连接,需要创建一条新conntrack entry来记录这条连接 - 拦截到一个属于已有
conntrack entry的包时,需要更新这条conntrack entry的收发包数等统计信息
设计
Linux 的连接跟踪是在 Netfilter中实现的

Netfilter 是 Linux 内核中一个对数据 包进行控制、修改和过滤(manipulation and filtering)的框架。它在内核协议 栈中设置了若干**hook** 点,以此对数据包进行拦截、过滤或其他处理。
说地更直白一些,
hook机制就是在数据包的必经之路上设置若干检测点,所有到达这 些检测点的包都必须接受检测,根据检测的结果决定:
- 放行:不对包进行任何修改,退出检测逻辑,继续后面正常的包处理
- 修改:例如修改 IP 地址进行 NAT,然后将包放回正常的包处理逻辑
- 丢弃:安全策略或防火墙功能
连接跟踪模块只是完成连接信息的采集和录入功能,并不会修改或丢弃数据包,后者是其 他模块(例如 NAT)基于
Netfilter hook完成的。
Netfilter 是最古老的内核框架之一,1998 年开始开发,2000 年合并到 2.4.x 内 核主线版本
连接跟踪(CT)概念是独立于 Netfilter的,Netfilter只是 Linux 内核中的一种连接跟踪实现。只要具备了 hook 能力,能拦截到进出主机的每个包,完全可以在此基础上自 己实现一套连接跟踪。
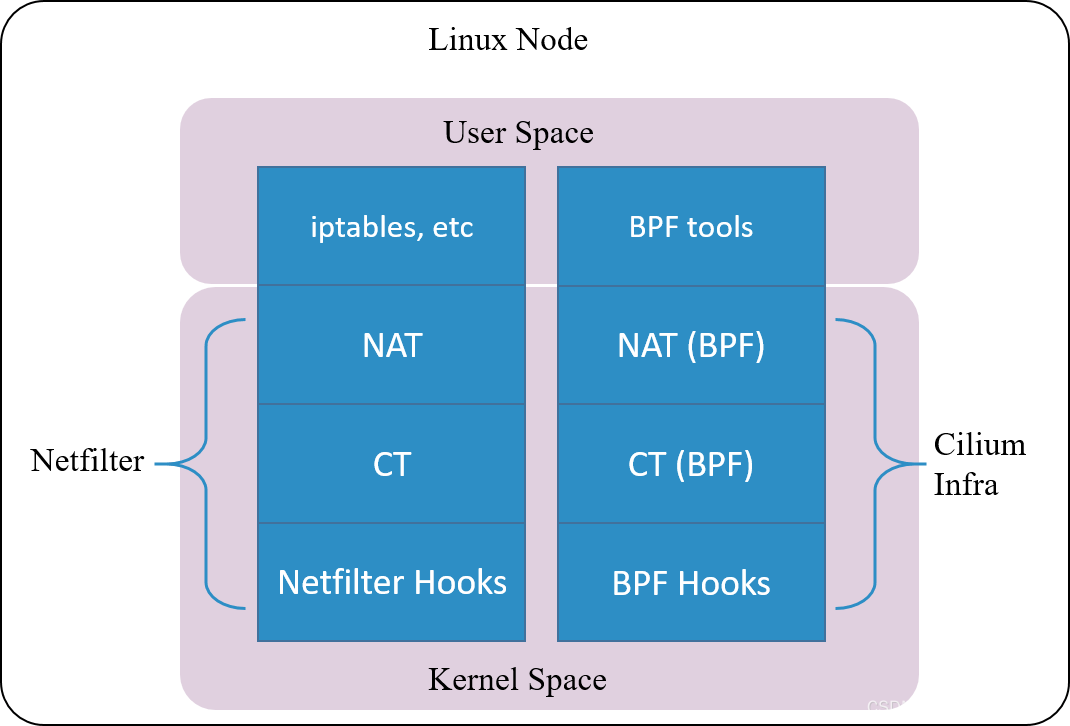
云原生网络方案 Cilium 在 1.7.4+ 版本就实现了这样一套独立的连接跟踪和 NAT 机制 (完备功能需要 Kernel 4.19+)。其基本原理是:
- 基于 BPF hook 实现数据包的拦截功能(等价于 netfilter 里面的 hook 机制)
- 在 BPF hook 的基础上,实现一套全新的 conntrack 和 NAT
因此,即便卸载 Netfilter,也不会影响 Cilium 对 Kubernetes ClusterIP、NodePort、ExternalIPs 和 LoadBalancer 等功能的支持 [2]。
应用
网络地址转换(NAT)
网络地址转换(NAT),名字表达的意思也比较清楚:对(数据包的)网络地址(IP + Port)进行转换。
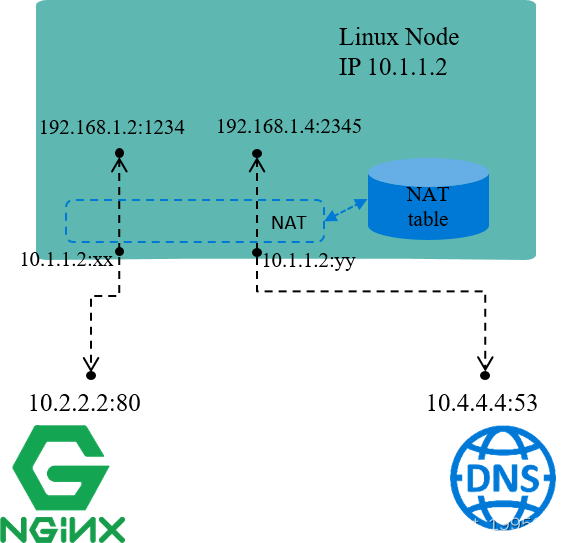
例如上图中,机器自己的 IP 10.1.1.2 是能与外部正常通信的,但 192.168 网段是私有 IP 段,外界无法访问,也就是说源 IP 地址是 192.168 的包,其应答包是无 法回来的。因此,
- 当源地址为
192.168网段的包要出去时,机器会先将源 IP 换成机器自己的10.1.1.2再发送出去; - 收到应答包时,再进行相反的转换。
这就是 NAT 的基本过程。
NAT 又可以细分为几类:
- SNAT:对源地址(source)进行转换
- DNAT:对目的地址(destination)进行转换
- Full NAT:同时对源地址和目的地址进行转换
以上场景属于SNAT,将不同私有IP都映射成同一个公有 IP,以使其能访问外部网络服务。这种场景也属于正向代理。
NAT依赖连接跟踪的结果。连接跟踪最重要的使用场景就是NAT。
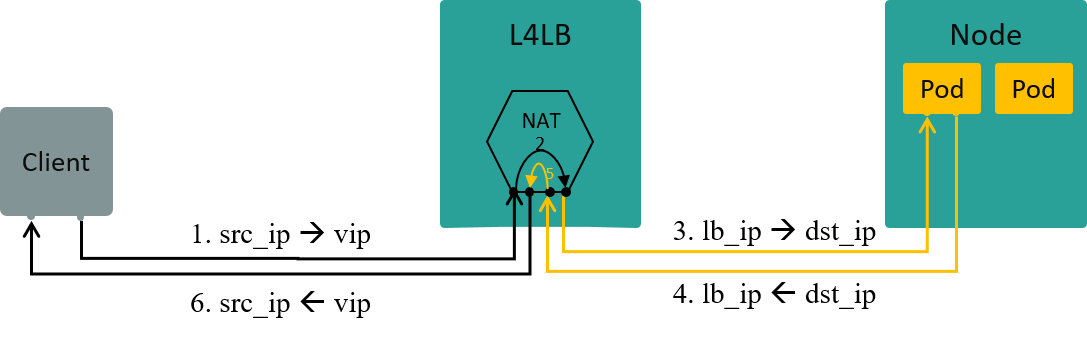
四层负载均衡(L4LB)
四层负载均衡是根据包的四层信息(例如 src/dst ip, src/dst port, proto)做流量分发。
VIP(Virtual IP)是四层负载均衡的一种实现方式:
- 多个后端
真实IP(Real IP)挂到同一个虚拟IP(VIP)上 - 客户端过来的流量先到达VIP,再经负载均衡算法转发给某个特定的后端IP
如果在 VIP 和 Real IP 节点之间使用的 NAT 技术(也可以使用其他技术),那客户端访 问服务端时,L4LB 节点将做双向 NAT(Full NAT),数据流如下图所示:
有状态防火墙
有状态防火墙(stateful firewall)是相对于早期的无状态防火墙(stateless firewall)而言的。
早期防火墙只能写 drop syn to port 443 或者 allow syn to port 80 这种非常简单直接 的规则,没有 flow 的概念,因此无法实现诸如 “如果这个 ack 之前已经有 syn, 就 allow,否则 drop”这样的规则,使用非常受限。
显然,要实现有状态防火墙,就必须记录 flow 和状态,这正是conntrack做的事情。
来看个更具体的防火墙应用:OpenStack 主机防火墙解决方案 —— 安全组(security group)
简单来说,安全组实现了虚拟机级别的安全隔离,具体实现是:在node上连接VM的网络设备上做有状态防火墙。在当时,最能实现这一功能的可能就是 Netfilter/iptables。
回到宿主机内网络拓扑问题: OpenStack 使用OVS bridge来连接一台宿主机内的所有VM。 如果只从网络连通性考虑,那每个VM应该直接连到OVS bridge br-int。但这里问题就来了:
(较早版本的)OVS 没有
conntrack模块,Linux 中有
conntrack模块,但基于conntrack的防火墙工作在IP层(L3),通过iptables控制,而
OVS是L2模块,无法使用 L3 模块的功能,
最终结果是:无法在OVS (连接虚拟机)的设备上做防火墙。
所以,2016 之前OpenStack的解决方案是,在每个OVS和VM之间再加一个 Linux bridge ,如下图所示,
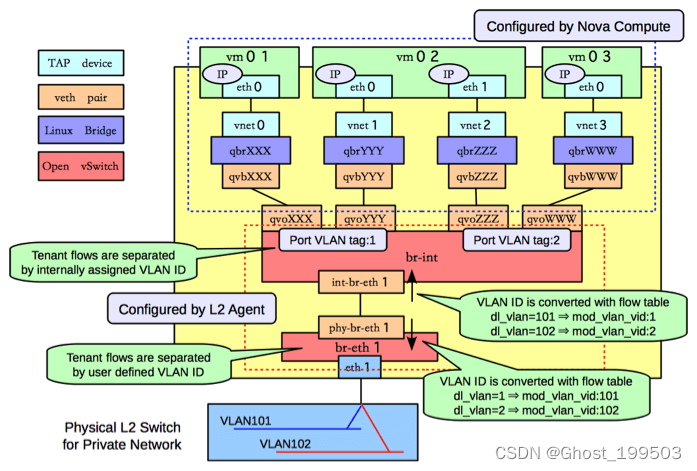
Linux bridge也是L2模块,按道理也无法使用 iptables。但是,它有一个 L2 工具ebtables,能够跳转到 iptables,因此间接支持了iptables,也就能用到 Netfilter/iptables 防火墙的功能。
Netfilter hook 机制实现
Netfilter由几个模块构成,其中最主要的是连接跟踪(CT)模块和网络地址转换(NAT)模块。
CT模块的主要职责是识别出可进行连接跟踪的包。CT模块独立于NAT模块,但主要目的是服务于后者。
Netfilter 框架
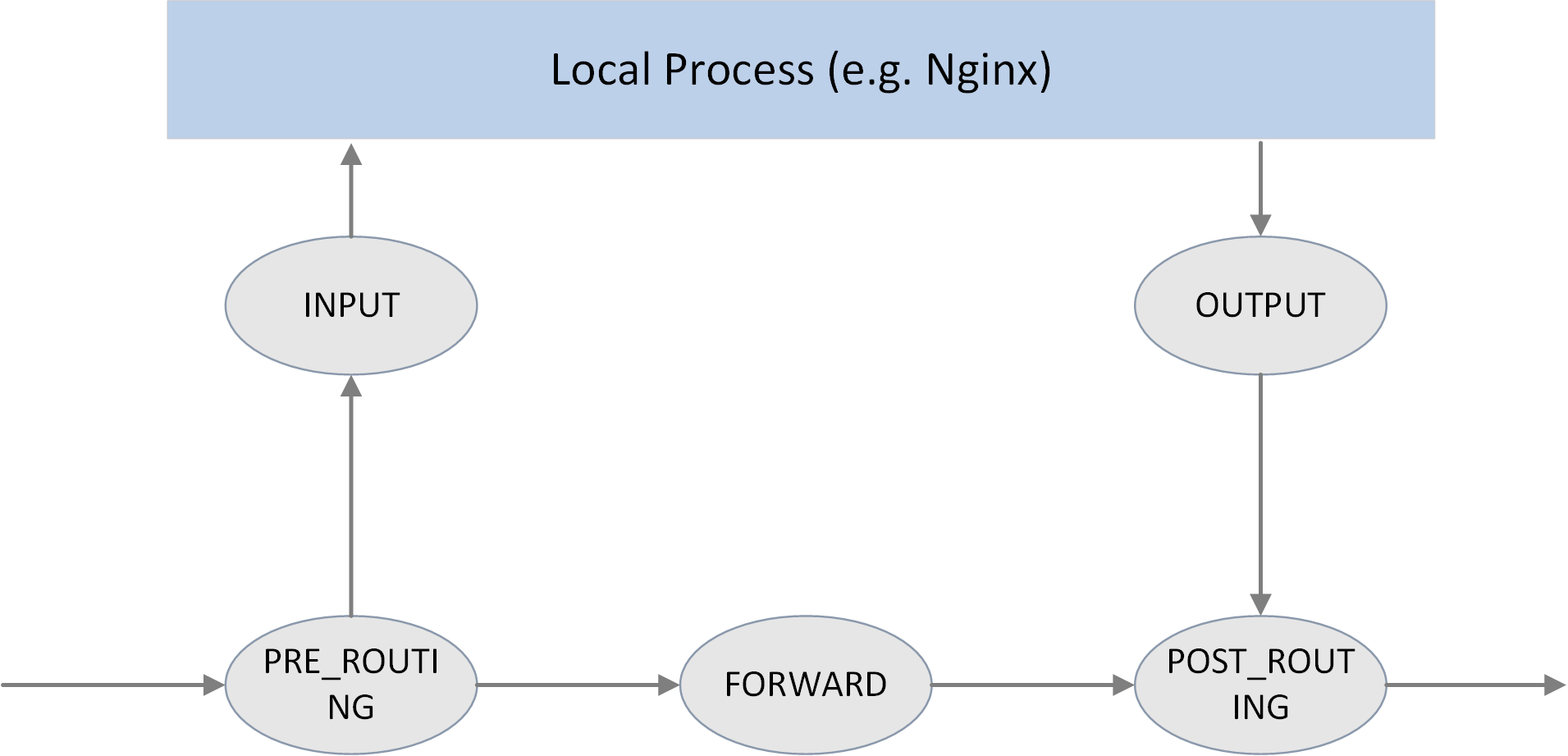
// include\uapi\linux\netfilter_ipv4.h
/* IP Hooks */
/* After promisc drops, checksum checks. */
#define NF_IP_PRE_ROUTING 0
/* If the packet is destined for this box. */
#define NF_IP_LOCAL_IN 1
/* If the packet is destined for another interface. */
#define NF_IP_FORWARD 2
/* Packets coming from a local process. */
#define NF_IP_LOCAL_OUT 3
/* Packets about to hit the wire. */
#define NF_IP_POST_ROUTING 4
#define NF_IP_NUMHOOKS 5
#endif /* ! __KERNEL__ */
用户可以在这些hook点注册自己的处理函数(handlers)。当有数据包经过hook点时, 就会调用相应的handlers。
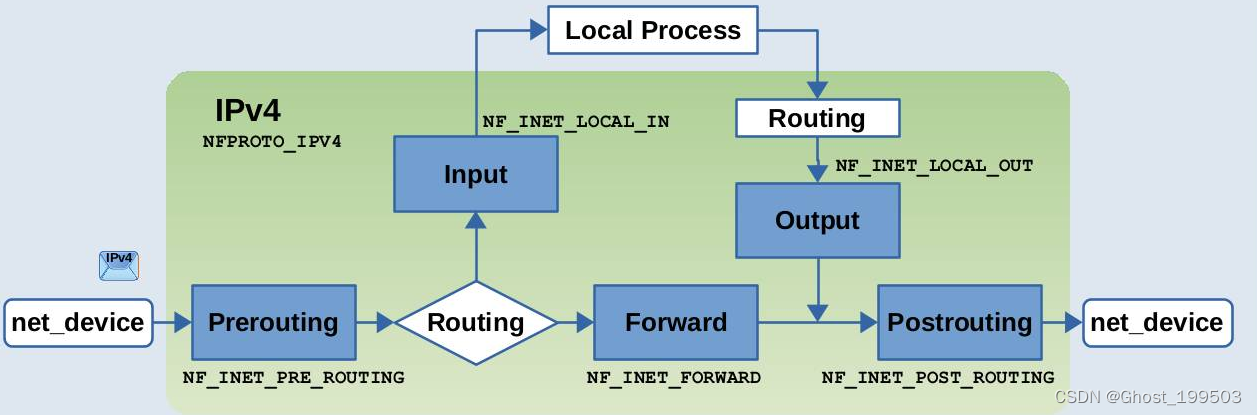
另一套
NF_INET_开头的定义定义位置.// include/uapi/linux/netfilter.h enum nf_inet_hooks { NF_INET_PRE_ROUTING, NF_INET_LOCAL_IN, NF_INET_FORWARD, NF_INET_LOCAL_OUT, NF_INET_POST_ROUTING, NF_INET_NUMHOOKS, NF_INET_INGRESS = NF_INET_NUMHOOKS, };
hook 返回值类型
hook函数对包进行判断或处理之后,需要返回一个判断结果,指导接下来要对这个包做什么。可能的结果有:
/* Responses from hook functions. */
#define NF_DROP 0 // 已丢弃这个包
#define NF_ACCEPT 1 // 接受这个包,结束判断,继续下一步处理
#define NF_STOLEN 2 // 临时 hold 这个包,不用再继续穿越协议栈了.常见的情形是缓存分片之后的包(等待重组)
#define NF_QUEUE 3 // 应当将包放到队列
#define NF_REPEAT 4 // 当前处理函数应当被再次调用
#define NF_STOP 5 /* Deprecated, for userspace nf_queue compatibility. */
hook 优先级
每个 hook 点可以注册多个处理函数(handler)。在注册时必须指定这些 handlers 的优先级,这样触发 hook 时能够根据优先级依次调用处理函数。
// include/uapi/linux/netfilter_ipv4.h
enum nf_ip_hook_priorities {
NF_IP_PRI_FIRST = INT_MIN,
NF_IP_PRI_RAW_BEFORE_DEFRAG = -450,
NF_IP_PRI_CONNTRACK_DEFRAG = -400,
NF_IP_PRI_RAW = -300,
NF_IP_PRI_SELINUX_FIRST = -225,
NF_IP_PRI_CONNTRACK = -200,
NF_IP_PRI_MANGLE = -150,
NF_IP_PRI_NAT_DST = -100,
NF_IP_PRI_FILTER = 0,
NF_IP_PRI_SECURITY = 50,
NF_IP_PRI_NAT_SRC = 100,
NF_IP_PRI_SELINUX_LAST = 225,
NF_IP_PRI_CONNTRACK_HELPER = 300,
NF_IP_PRI_CONNTRACK_CONFIRM = INT_MAX,
NF_IP_PRI_LAST = INT_MAX,
};
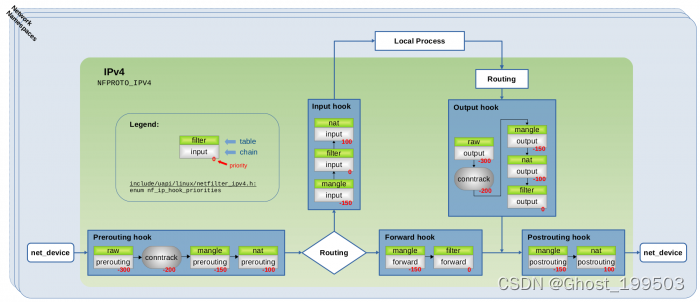
原图:https://thermalcircle.de/lib/exe/fetch.php?media=linux:nf-hooks-iptables1.png
Netfilter conntrack 实现
连接跟踪模块用于维护可跟踪协议(trackable protocols)的连接状态。 也就是说,连接跟踪针对的是特定协议的包,而不是所有协议的包。
重要结构体
struct nf_conntrack_tuple
Tuple 结构体中只有两个字段 src 和 dst,分别保存源和目的信息。src 和 dst 自身也是结构体,能保存不同类型协议的数据。
/* path: include/uapi/linux/netfilter.h */
union nf_inet_addr {
__u32 all[4];
__be32 ip;
__be32 ip6[4];
struct in_addr in;
struct in6_addr in6;
};
/* path: include/uapi/linux/netfilter/nf_conntrack_tuple_common.h */
/* The protocol-specific manipulable parts of the tuple: always in network order */
union nf_conntrack_man_proto {
/* Add other protocols here. */
__be16 all;
struct {__be16 port;} tcp;
struct {__be16 port;} udp;
struct {__be16 id;} icmp;
struct {__be16 port;} dccp;
struct {__be16 port;} sctp;
struct {__be16 key;} gre; /* GRE key is 32bit, PPtP only uses 16bit */
};
/* path: include/net/netfilter/nf_conntrack_tuple.h */
/* The manipulable part of the tuple. */
struct nf_conntrack_man {
union nf_inet_addr u3;
union nf_conntrack_man_proto u;
/* Layer 3 protocol */
u_int16_t l3num;
};
/* This contains the information to distinguish a connection. */
struct nf_conntrack_tuple {
struct nf_conntrack_man src; //源地址
/* These are the parts of the tuple which are fixed. */
struct {
union nf_inet_addr u3;
union {
/* Add other protocols here. */
__be16 all;
struct {__be16 port;} tcp;
struct {__be16 port;} udp;
struct {u_int8_t type, code;} icmp;
struct {__be16 port;} dccp;
struct {__be16 port;} sctp;
struct {__be16 key;} gre;
} u;
/* The protocol. */
u_int8_t protonum;
/* The direction (for tuplehash) */
u_int8_t dir;
} dst; //目的地址
};
五元组分别保存如下:
dst.protonum:协议类型src.u3.ip:源 IP 地址dst.u3.ip:目的 IP 地址src.u.udp.port:源端口号dst.u.udp.port:目的端口号从上面定义看
CT目前只支持以下六种协议:TCP、UDP、ICMP、DCCP、SCTP、GRE。
struct nf_conntrack_l4proto
支持连接跟踪的协议需要实现的方法集(以及其他协议相关字段)支持连接跟踪的协议都需要实现 struct nf_conntrack_l4proto {} 结构体中定义的方法
/* include/net/netfilter/nf_conntrack_l4proto.h */
struct nf_conntrack_l4proto {
/* L4 Protocol number. */
u_int8_t l4proto;
/* Resolve clashes on insertion races. */
bool allow_clash;
/* protoinfo nlattr size, closes a hole */
u16 nlattr_size;
/* called by gc worker if table is full */
bool (*can_early_drop)(const struct nf_conn *ct);
/* convert protoinfo to nfnetink attributes */
int (*to_nlattr)(struct sk_buff *skb, struct nlattr *nla, struct nf_conn *ct, bool destroy);
/* convert nfnetlink attributes to protoinfo */
int (*from_nlattr)(struct nlattr *tb[], struct nf_conn *ct);
// 从包(skb)中提取 tuple
int (*tuple_to_nlattr)(struct sk_buff *skb, const struct nf_conntrack_tuple *t);
/* Calculate tuple nlattr size */
unsigned int (*nlattr_tuple_size)(void);
int (*nlattr_to_tuple)(struct nlattr *tb[], struct nf_conntrack_tuple *t, u_int32_t flags);
const struct nla_policy *nla_policy;
struct {
int (*nlattr_to_obj)(struct nlattr *tb[], struct net *net, void *data);
int (*obj_to_nlattr)(struct sk_buff *skb, const void *data);
u16 obj_size;
u16 nlattr_max;
const struct nla_policy *nla_policy;
} ctnl_timeout;
#ifdef CONFIG_NF_CONNTRACK_PROCFS
/* Print out the private part of the conntrack. */
void (*print_conntrack)(struct seq_file *s, struct nf_conn *);
#endif
};
struct nf_conntrack_tuple_hash
/* 计算hash的接口,利用元组的不同字段来计算hash */
static u32 hash_conntrack_raw(const struct nf_conntrack_tuple *tuple, unsigned int zoneid,
const struct net *net)
struct hlist_nulls_node {
struct hlist_nulls_node *next, **pprev;
};
/* Connections have two entries in the hash table: one for each way */
/* 每条连接在哈希表中都对应两项,分别对应两个方向(egress/ingress) */
/* path: include/net/netfilter/nf_conntrack_tuple.h */
/* 哈希表(conntrack table)中的表项(value) */
struct nf_conntrack_tuple_hash {
struct hlist_nulls_node hnnode;
struct nf_conntrack_tuple tuple;
};
struct nf_conn
Netfilter 中每个 flow 都称为一个connection, 使是对那些非面向连接的协议(例如 UDP)。
typedef struct {
int counter;
} atomic_t;
typedef struct refcount_struct {
atomic_t refs;
} refcount_t;
/* /include/net/netfilter/nf_conntrack_common.h */
struct nf_conntrack {
refcount_t use;
};
/* path: include/net/netfilter/nf_conntrack.h */
/* per conntrack: protocol private data */
union nf_conntrack_proto {
/* insert conntrack proto private data here */
struct nf_ct_dccp dccp;
struct ip_ct_sctp sctp;
struct ip_ct_tcp tcp;
struct nf_ct_udp udp;
struct nf_ct_gre gre;
unsigned int tmpl_padto;
};
/* 每个 connection 用 struct nf_conn {} 表示*/
struct nf_conn {
/* Usage count in here is 1 for hash table, 1 per skb,
* plus 1 for any connection(s) we are `master' for
*
* Hint, SKB address this struct and refcnt via skb->_nfct and
* helpers nf_conntrack_get() and nf_conntrack_put().
* Helper nf_ct_put() equals nf_conntrack_put() by dec refcnt,
* except that the latter uses internal indirection and does not
* result in a conntrack module dependency.
* beware nf_ct_get() is different and don't inc refcnt.
*/
struct nf_conntrack ct_general;
spinlock_t lock;
/* jiffies32 when this ct is considered dead */
u32 timeout;
#ifdef CONFIG_NF_CONNTRACK_ZONES
struct nf_conntrack_zone zone;
#endif
/* XXX should I move this to the tail ? - Y.K */
/* These are my tuples; original and reply */
struct nf_conntrack_tuple_hash tuplehash[IP_CT_DIR_MAX];
/* Have we seen traffic both ways yet? (bitset) */
unsigned long status;
possible_net_t ct_net;
#if IS_ENABLED(CONFIG_NF_NAT)
struct hlist_node nat_bysource;
#endif
/* all members below initialized via memset */
struct { } __nfct_init_offset;
/* If we were expected by an expectation, this will be it */
struct nf_conn *master;
#if defined(CONFIG_NF_CONNTRACK_MARK)
u_int32_t mark;
#endif
#ifdef CONFIG_NF_CONNTRACK_SECMARK
u_int32_t secmark;
#endif
/* Extensions */
struct nf_ct_ext *ext;
/* Storage reserved for other modules, must be the last member */
union nf_conntrack_proto proto;
};
连接的状态集合
/* path: include/uapi/linux/netfilter/nf_conntrack_common.h*/
/* Bitset representing status of connection. */
enum ip_conntrack_status {
/* It's an expected connection: bit 0 set. This bit never changed */
IPS_EXPECTED_BIT = 0,
IPS_EXPECTED = (1 << IPS_EXPECTED_BIT),
/* We've seen packets both ways: bit 1 set. Can be set, not unset. */
IPS_SEEN_REPLY_BIT = 1,
IPS_SEEN_REPLY = (1 << IPS_SEEN_REPLY_BIT),
/* Conntrack should never be early-expired. */
IPS_ASSURED_BIT = 2,
IPS_ASSURED = (1 << IPS_ASSURED_BIT),
/* Connection is confirmed: originating packet has left box */
IPS_CONFIRMED_BIT = 3,
IPS_CONFIRMED = (1 << IPS_CONFIRMED_BIT),
/* Connection needs src nat in orig dir. This bit never changed. */
IPS_SRC_NAT_BIT = 4,
IPS_SRC_NAT = (1 << IPS_SRC_NAT_BIT),
/* Connection needs dst nat in orig dir. This bit never changed. */
IPS_DST_NAT_BIT = 5,
IPS_DST_NAT = (1 << IPS_DST_NAT_BIT),
/* Both together. */
IPS_NAT_MASK = (IPS_DST_NAT | IPS_SRC_NAT),
/* Connection needs TCP sequence adjusted. */
IPS_SEQ_ADJUST_BIT = 6,
IPS_SEQ_ADJUST = (1 << IPS_SEQ_ADJUST_BIT),
/* NAT initialization bits. */
IPS_SRC_NAT_DONE_BIT = 7,
IPS_SRC_NAT_DONE = (1 << IPS_SRC_NAT_DONE_BIT),
IPS_DST_NAT_DONE_BIT = 8,
IPS_DST_NAT_DONE = (1 << IPS_DST_NAT_DONE_BIT),
/* Both together */
IPS_NAT_DONE_MASK = (IPS_DST_NAT_DONE | IPS_SRC_NAT_DONE),
/* Connection is dying (removed from lists), can not be unset. */
IPS_DYING_BIT = 9,
IPS_DYING = (1 << IPS_DYING_BIT),
/* Connection has fixed timeout. */
IPS_FIXED_TIMEOUT_BIT = 10,
IPS_FIXED_TIMEOUT = (1 << IPS_FIXED_TIMEOUT_BIT),
/* Conntrack is a template */
IPS_TEMPLATE_BIT = 11,
IPS_TEMPLATE = (1 << IPS_TEMPLATE_BIT),
/* Conntrack is a fake untracked entry. Obsolete and not used anymore */
IPS_UNTRACKED_BIT = 12,
IPS_UNTRACKED = (1 << IPS_UNTRACKED_BIT),
#ifdef __KERNEL__
/* Re-purposed for in-kernel use:
* Tags a conntrack entry that clashed with an existing entry
* on insert.
*/
IPS_NAT_CLASH_BIT = IPS_UNTRACKED_BIT,
IPS_NAT_CLASH = IPS_UNTRACKED,
#endif
/* Conntrack got a helper explicitly attached (ruleset, ctnetlink). */
IPS_HELPER_BIT = 13,
IPS_HELPER = (1 << IPS_HELPER_BIT),
/* Conntrack has been offloaded to flow table. */
IPS_OFFLOAD_BIT = 14,
IPS_OFFLOAD = (1 << IPS_OFFLOAD_BIT),
/* Conntrack has been offloaded to hardware. */
IPS_HW_OFFLOAD_BIT = 15,
IPS_HW_OFFLOAD = (1 << IPS_HW_OFFLOAD_BIT),
/* Be careful here, modifying these bits can make things messy,
* so don't let users modify them directly.
*/
IPS_UNCHANGEABLE_MASK = (IPS_NAT_DONE_MASK | IPS_NAT_MASK |
IPS_EXPECTED | IPS_CONFIRMED | IPS_DYING |
IPS_SEQ_ADJUST | IPS_TEMPLATE | IPS_UNTRACKED |
IPS_OFFLOAD | IPS_HW_OFFLOAD),
__IPS_MAX_BIT = 16,
};
连接事件集合
/* path: include/uapi/linux/netfilter/nf_conntrack_common.h*/
/* Connection tracking event types */
enum ip_conntrack_events {
IPCT_NEW, /* new conntrack */
IPCT_RELATED, /* related conntrack */
IPCT_DESTROY, /* destroyed conntrack */
IPCT_REPLY, /* connection has seen two-way traffic */
IPCT_ASSURED, /* connection status has changed to assured */
IPCT_PROTOINFO, /* protocol information has changed */
IPCT_HELPER, /* new helper has been set */
IPCT_MARK, /* new mark has been set */
IPCT_SEQADJ, /* sequence adjustment has changed */
IPCT_NATSEQADJ = IPCT_SEQADJ,
IPCT_SECMARK, /* new security mark has been set */
IPCT_LABEL, /* new connlabel has been set */
IPCT_SYNPROXY, /* synproxy has been set */
#ifdef __KERNEL__
__IPCT_MAX
#endif
};
重要函数
hash_conntrack_raw()
path: net\netfilter\nf_conntrack_core.c
根据 tuple 计算出一个 32 位的哈希值(hash key)。
nf_conntrack_in():
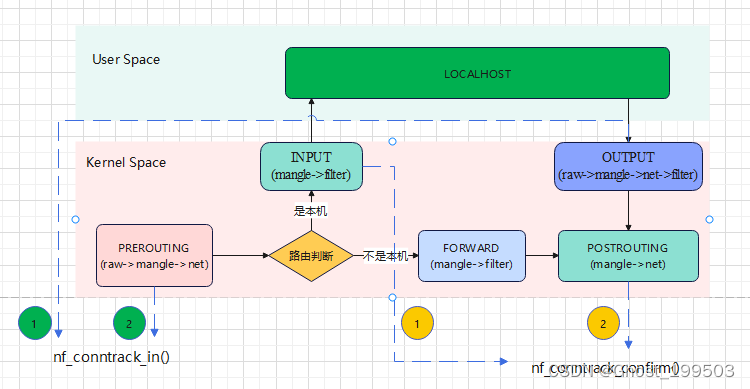
连接跟踪模块的核心,包进入连接跟踪的地方。调用nf_conntrack_in()开始连接跟踪, 正常情况下会创建一条新连接记录,然后将 conntrack entry 放到unconfirmed list。
PREROUTING是外部主动和本机建连时包最先到达的地方OUTPUT是本机主动和外部建连时包最先到达的地方
nf_conntrack_confirm()
确认前面通过 nf_conntrack_in() 创建的新连接(是否被丢弃)。调用 nf_conntrack_confirm() 将 nf_conntrack_in() 创建的连接移到 confirmed list。为什么选这两个HOOK点因为如果新连接的第一个包没有被丢弃,那这 是它们**离开netfilter 之前的最后 hook 点
-
INPUT外部主动和本机建连的包,如果中间没有被丢弃,INPUT是其送到LOCALHOST最后的HOOK点 -
POSTROUTING本机主动和外部建连的包,如果中间没有被丢弃,POSTROUTING是其出LOCALHOST最后的HOOK点
那么这些handler是如何注册的呢?以ipv4为例:
/* path: include/linux/netfilter.h */
struct nf_hook_ops {
/* User fills in from here down. */
nf_hookfn *hook;
struct net_device *dev;
void *priv;
u8 pf;
enum nf_hook_ops_type hook_ops_type:8;
unsigned int hooknum;
/* Hooks are ordered in ascending priority. */
int priority;
};
/* path: net/netfilter/nf_conntrack_core.c */
unsigned int
nf_conntrack_in(struct sk_buff *skb, const struct nf_hook_state *state) {}
/* path: include/net/netfilter/nf_conntrack_core.h */
static inline int nf_conntrack_confirm(struct sk_buff *skb)
|
|->int __nf_conntrack_confirm(struct sk_buff *skb)
|->/* path: net/netfilter/nf_conntrack_core.c */
/* net/netfilter/nf_conntrack_proto.c */
/* Connection tracking may drop packets, but never alters them, so make it the first hook */
static const struct nf_hook_ops ipv4_conntrack_ops[] = {
{
.hook = ipv4_conntrack_in, // nf_conntrack_in
.pf = NFPROTO_IPV4,
.hooknum = NF_INET_PRE_ROUTING, // PREROUTING(PRE_ROUTING)
.priority = NF_IP_PRI_CONNTRACK, // NF_IP_PRI_CONNTRACK = -200,
},
{
.hook = ipv4_conntrack_local, // nf_conntrack_in
.pf = NFPROTO_IPV4,
.hooknum = NF_INET_LOCAL_OUT, // OUTPUT(LOCAL_OUT)
.priority = NF_IP_PRI_CONNTRACK, // NF_IP_PRI_CONNTRACK = -200,
},
{
.hook = ipv4_confirm, // nf_conntrack_confirm
.pf = NFPROTO_IPV4,
.hooknum = NF_INET_POST_ROUTING, // POSTROUTING(POST_ROUTING)
.priority = NF_IP_PRI_CONNTRACK_CONFIRM, // NF_IP_PRI_CONNTRACK_CONFIRM = INT_MAX,
},
{
.hook = ipv4_confirm, // nf_conntrack_confirm
.pf = NFPROTO_IPV4,
.hooknum = NF_INET_LOCAL_IN, // INPUT(LOCAL_IN)
.priority = NF_IP_PRI_CONNTRACK_CONFIRM, // NF_IP_PRI_CONNTRACK_CONFIRM = INT_MAX,
},
};
resolve_normal_ct
resolve_normal_ct() -> init_conntrack() -> ct = __nf_conntrack_alloc(); l4proto->new(ct)
创建一个新的连接记录(conntrack entry),然后初始化。
-
init_conntrack()如果连接不存在(flow 的第一个包),
resolve_normal_ct()会调用init_conntrack,进而会调用new()方法创建一个新的conntrack entry
/* path: net/netfilter/nf_conntrack_core.c */
/* Allocate a new conntrack: we return -ENOMEM if classification
failed due to stress. Otherwise it really is unclassifiable. */
static noinline struct nf_conntrack_tuple_hash *
init_conntrack(struct net *net, struct nf_conn *tmpl,
const struct nf_conntrack_tuple *tuple,
struct sk_buff *skb,
unsigned int dataoff, u32 hash)
l4proto->new(ct),有各个协议自己实现

















 2041
2041

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









