







1 过拟合
过拟合——过多的变量(特征),同时只有非常少的训练数据,会导致出现过度拟合的问题
1 、方法一:尽量减少选取变量的数量
2、正则化
正则化中我们将保留所有的特征变量,但是会减小特征变量的数量级
这个方法非常有效,当我们有很多特征变量时,其中每一个变量都能对预测产生一点影响。正如我们在房价预测的例子中看到的那样,我们可以有很多特征变量,其中每一个变量都是有用的,因此我们不希望把它们删掉,这就导致了正则化概念的发生。
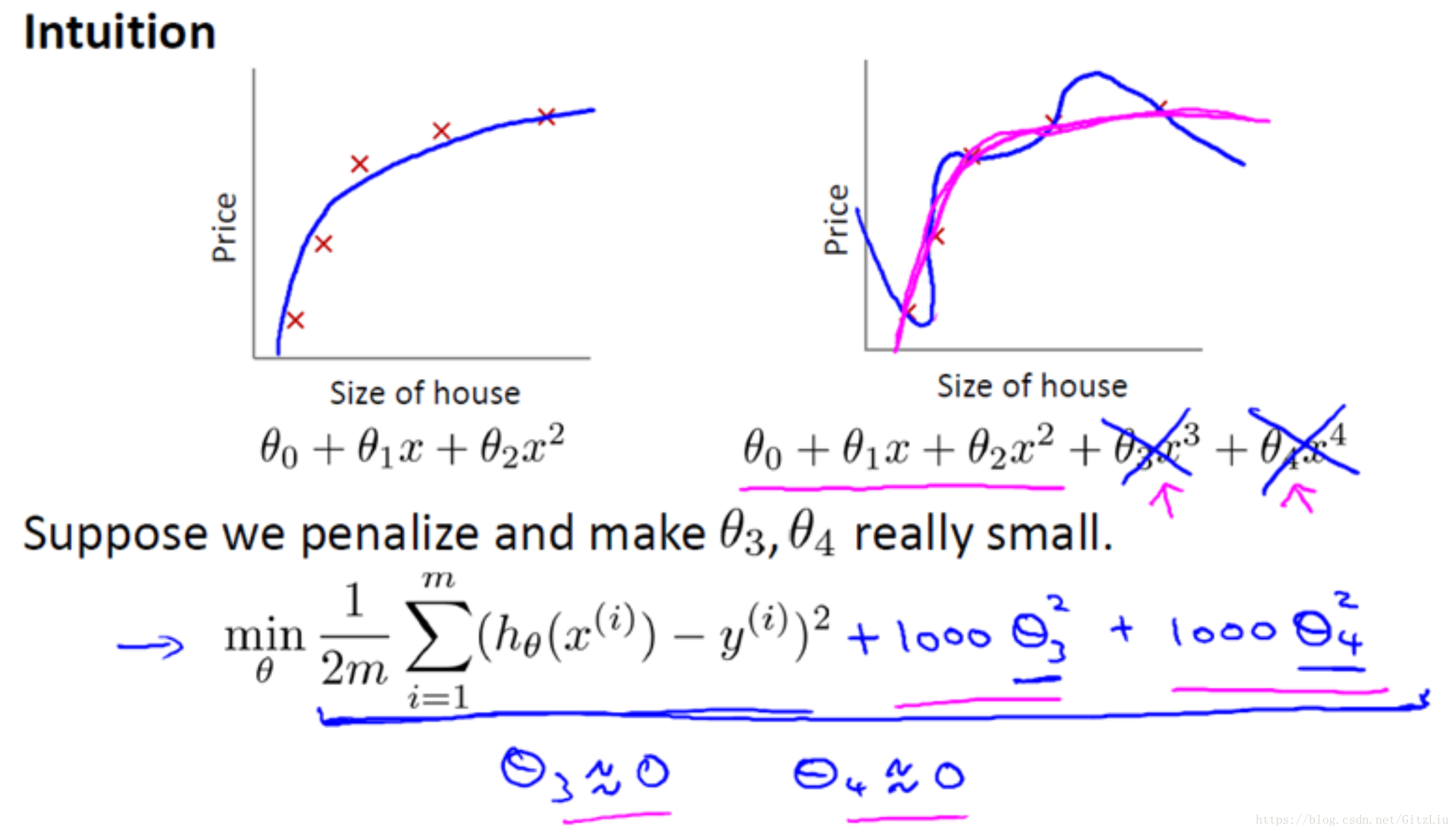
让我们考虑下面的假设,我们想要加上惩罚项,从而使参数 θ3 和 θ4 足够的小。
这里我的意思就是,上图的式子是我们的优化目标,也就是说我们需要尽量减少代价函数的均方误差。
对于这个函数我们对它添加一些项,加上 1000 乘以 θ3 的平方,再加上 1000 乘以 θ4 的平方,
1000 只是我随便写的某个较大的数字而已。现在,如果我们要最小化这个函数,那么为了最小化这个新的代价函数,我们要让 θ3 和 θ4 尽可能小。因为,如果你在原有代价函数的基础上加上 1000 乘以 θ3 这一项 ,那么这个新的代价函数将变得很大,所以,当我们最小化这个新的代价函数时, 我们将使 θ3 的值接近于 0,同样 θ4 的值也接近于 0,就像我们忽略了这两个值一样。如果我们做到这一点( θ3 和 θ4 接近 0 ),那么我们将得到一个近似的二次函数。
因此,我们最终恰当地拟合了数据,我们所使用的正是二次函数加上一些非常小,贡献很小项(因为这些项的 θ3、 θ4 非常接近于0)。显然,这是一个更好的假设。
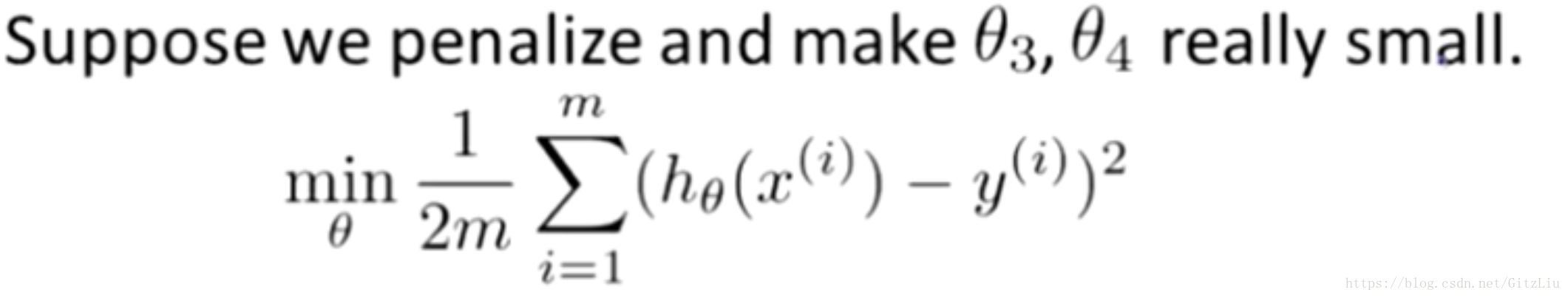
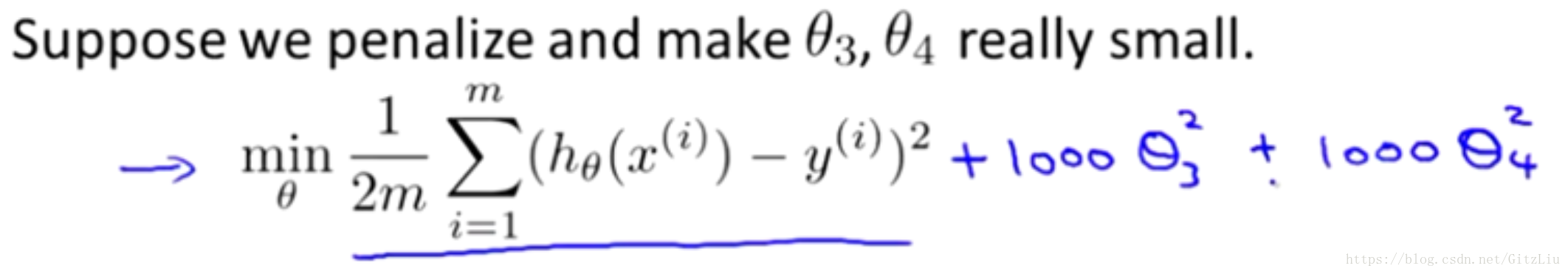
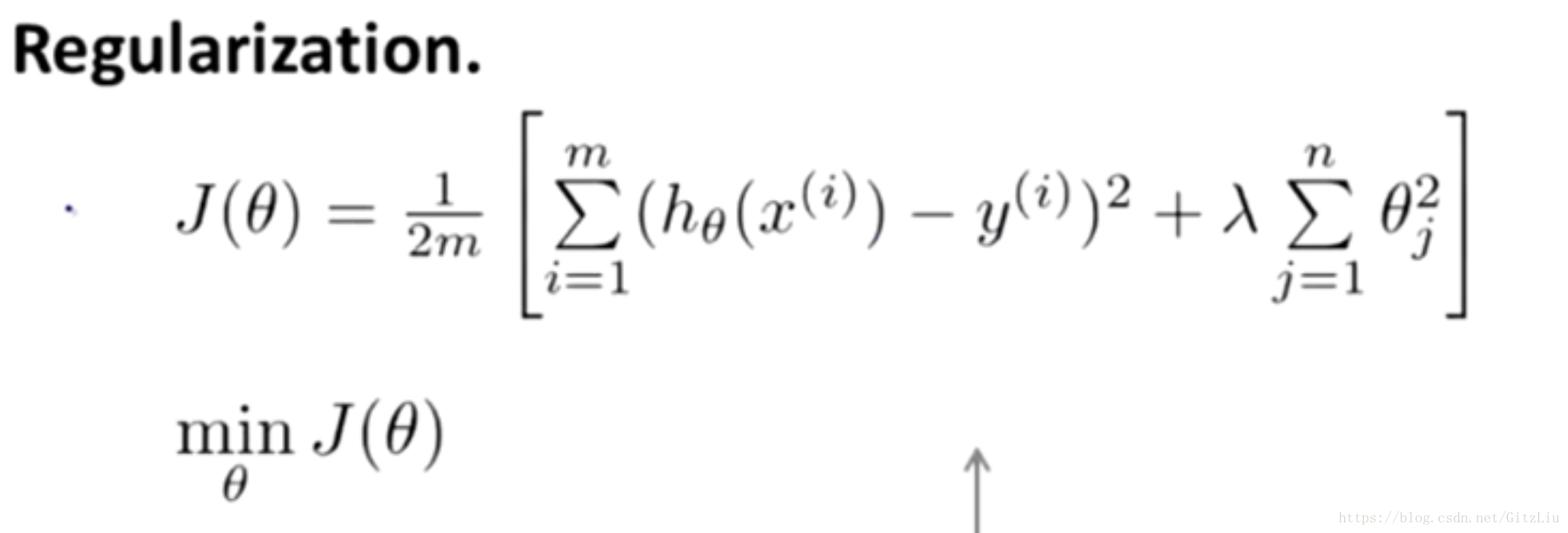
并且 λ 在这里我们称做正则化参数。
λ 要做的就是控制在两个不同的目标中的平衡关系。
但是如果 λ过大,则会将对应的特征的影响降到最小,取极限情况就是为0,因此如果 λ过大,可能会产生欠拟合。
如果想更仔细了解,可参加这篇博文:
[ 正则化处理 ]
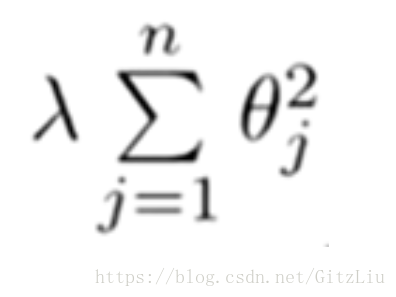
过拟合解决方法概括:
- 我们可以增大训练集,降低模型复杂度,
- 增大正则项,
- 或者通过特征选择减少特征数,即做一下feature2、增大正则项, 3、或者通过特征选择减少特征数,即做一下feature、或者通过特征选择减少特征数,即做一下feature2、增大正则项, 3、或者通过特征选择减少特征数,即做一下feature
selection,挑出较好的feature的subset来做training
2 欠拟合
相应的,
- 我们可以增加模型参数(特征),比如,构建更多的特征
- 减小正则项。(其实在某种意义上说,减小正则项也可以理解为是为了增加特征)
- 采用更复杂的模型3、采用更复杂的模型
此时通过增加数据量是不起作用的。
关于如何处理 过拟合 和 欠拟合,其实我在这篇博文中
[ 学习曲线-Learning Curve ]
也记录过,只不过本篇博文更详细说明了 过拟合的正则化处理。














 321
321











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









