






 论文介绍了一种基于全局CNN的分层视觉定位方法,用于应对大规模环境中的变化。HF-Net结合了粗略到精细定位,首先定位大致位置,然后细化,表现出高精度和实时性。通过多任务蒸馏克服数据稀缺问题,HF-Net在大规模变化数据集上表现出色。
论文介绍了一种基于全局CNN的分层视觉定位方法,用于应对大规模环境中的变化。HF-Net结合了粗略到精细定位,首先定位大致位置,然后细化,表现出高精度和实时性。通过多任务蒸馏克服数据稀缺问题,HF-Net在大规模变化数据集上表现出色。
标题:
《From Coarse to Fine: Robust Hierarchical Localization at Large Scale》
作者:Paul-Edouard Sarlin, Cesar Cadena, Roland Siegwart, Marcin Dymczyk
所属机构:1) Autonomous Systems Lab, ETH Zürich; 2) 2Sevensense Robotics AG
摘要:
- 这篇论文讨论了视觉定位,这是许多应用如自动驾驶、移动机器人和增强现实中的基础技术。
- 针对大规模环境中由于外观变化所导致的视觉定位难题,提出了一个基于单目全局卷积神经网络(CNN)的分层方法,该方法可以预测局部和全局特征。
- 提出的分层定位策略首先使用全局匹配来定位大体位置,然后使用局部匹配来进一步精细化位置。这种方法既节省了时间又提高了实时操作性。
- 实验表明,该方法在大规模变化的标准数据集上表现出了卓越的定位结果。
引言:
-
背景:精确的视觉定位在多种应用中至关重要。然而,大规模的环境变化和不同设备间的限制对于视觉定位技术提出了挑战。
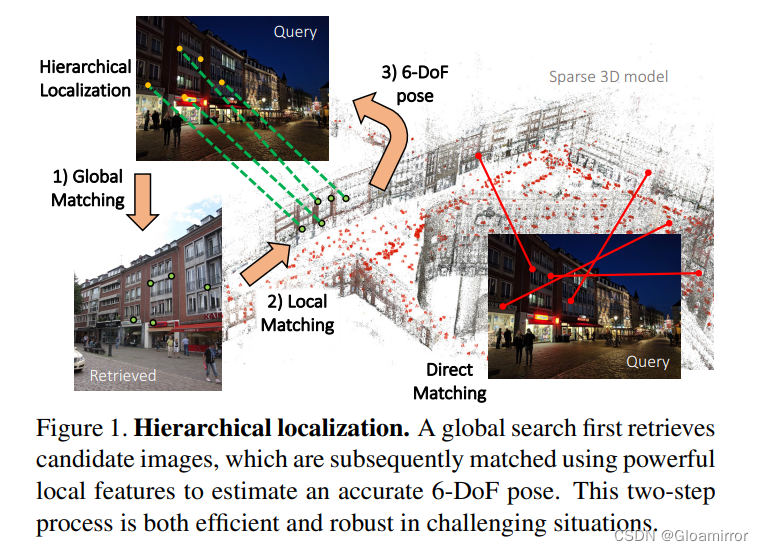
-
主要研究内容:作者提出了一种仿照人类定位机制的粗到细的策略,结合全局描述符和局部特征。该方法适应大型环境,并在实际应用中展示了提高的稳健性和效率。此外,他们介绍了HF-Net,一个可以联合预测局部和全局特征的单一卷积神经网络(CNN)。这种方法利用多任务蒸馏的技术,将多种预测器联合到一个模型中,实现了在不同的任务上都具有稳健性和计算效率的定位。
-
补充:多任务蒸馏通常涉及到使用一个或多个大型教师模型来指导一个小型学生模型,使其能够执行多个任务。学生模型的目标是在各个任务上都取得良好的性能,同时维持相对较小和高效的结构。这种技术是为了充分利用大型模型的能力,同时使得小型模型也能够从大型模型学习到的丰富信息中受益。
-
-
方法对比:
- 传统的6自由度的视觉定位方法主要依赖于3D SfM模型中的查询图像和3D点之间的局部描述符的直接匹配,但这些方法可能计算密集并随着模型规模的增长而变得复杂。
- 基于图像检索的方法只能提供近似结果,且可能不足够精确。
- 尽管尺度化定位考虑了额外的上下文信息,但其在减少计算量上受到限制。
- 学习的局部特征从CNN中自然产生,并为图像匹配提供了强大的表示形式。尽管它们在没有监督的情况下胜过了经典方法,但仍需要更多的计算资源。
-
主要贡献:
- 在多个公共基准测试中展现了卓越的大规模定位性能。
- 引入了HF-Net,一个用于快速而稳健定位的单一神经网络。
- 展示了多任务蒸馏在达到异质预测器的目标上的有效性。
相关工作
-
视觉定位:传统的6自由度(6-DoF)视觉定位方法通常基于3D SfM(Structure-from-Motion)模型,通过直接匹配查询图像与3D点之间的局部描述符来实现。尽管某些方法能够实时处理大规模数据,但它们在模型规模增长或出现模糊和歧义情况下的稳健性可能会下降。有些方法通过单一图像进行日常场景的定位,但在效率上可能不够竞争力。
-
图像检索:图像基方法与图像检索类似,但通常只能提供近似的定位,可能不足够精确。尽管基于深度学习的图像检索方法取得了进展,但大部分依赖于全局的粗略信息,这可能不足以满足所有应用的精确性要求。
-
尺度化定位:这种方法经常涉及处理额外的上下文信息,例如考虑建筑的结构和配合度。尽管这些方法改进了匹配的速度和准确性,但它们可能受到计算量的限制,尤其是在大规模定位场景中。
-
学习的局部特征:近年来,由卷积神经网络(CNN)产生的特征在图像匹配和定位任务上显示了其潜力。这些学习的特征比传统的手工制作的特征更为稳健和精确。此外,有些学习方法,如DELF,还引入了注意力机制来优化特征的选择和匹配。
-
在移动设备上的深度学习:尽管深度学习带来了视觉定位的性能提升,但其计算要求可能超出了移动设备的能力。最近的研究集中于多任务学习和知识蒸馏,以减少模型的大小和复杂性,从而使模型更适合移动部署。
综上所述,本部分主要回顾了与本文研究相关的各种视觉定位方法,从传统方法到基于深度学习的先进技术,并指出了每种方法在稳健性、效率和准确性方面的优势和限制
层次化定位 (Hierarchical Localization)
这一部分的内容主要描述了如何最大化定位的稳健性,尤其是在环境存在重大变化的情况下。
-
先验检索 (Prior retrieval): 在最粗糙的层次上,通过将查询与数据库中的图像进行匹配,形成所谓的"先验帧" (prior frames)。这些先验帧代表了在数据库图像中的候选位置,与SfM模型中的点相比,在数据库图像中的点要少。
-
可见性聚类 (Covisibility clustering): 基于它们共同观察到的3D结构,先验帧被聚类。这导致了一个可见性图,将数据库图像与3D点相连接。
-
局部特征匹配 (Local feature matching): 对于每个地点,依次匹配2D关键点到该地点包含的3D点,并尝试通过PnP来估计一个6-DoF位姿。这种匹配方法非常有效,尤其是当考虑的3D点数量有限时。一旦一个位置被估计,算法就停止。
-
描述子 (Descriptors): 一个先进的网络模型,NetVLAD,被简化为一个较小的模型,称为MobileNetVLAD (MNV)。这种方法在给定的资源限制下保持了原始模型的准确性。其局部匹配步骤建立在SIFT模型上,生成了大量的特征,这使其在小规模环境中表现良好。但在大光照变化下,SIFT不与近期的学习特征竞争。
这部分的重点是描述一个结合了粗糙到精细的层次化过程来提高定位的稳健性,特别是在存在显著变化的环境中。
提议的方法 (Proposed Approach)
这一部分描述了提议的方法和训练过程,并讨论了在多任务蒸馏中遇到的挑战。
-
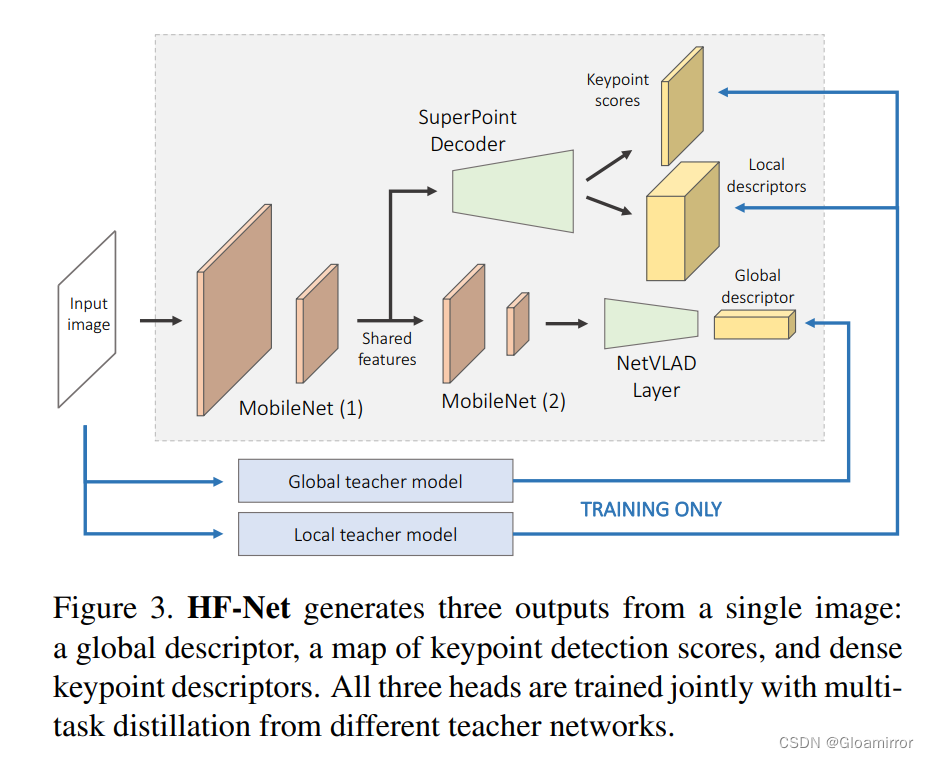
HF-Net的架构: HF-Net是一个网络,从单一图像中生成三种输出:全局描述符、地图关键点和局部描述符。三个头部与多任务蒸馏一起训练,从不同的教师网络中获得信息。
-
关于特征的处理:
- NetVLAD层:它位于MobileNet的顶层,用于处理全局描述符。
- SuperPoint:用于处理局部特征,预测固定数量的关键点和对应的描述符。
- LF-Net 和 Keypoint Transformer:这些是替代的关键点和描述符的生成方法,但由于其计算代价,HF-Net选择了SuperPoint方案。
-
-
训练过程:
- 数据稀缺性:局部和全局描述符通常通过正样本进行训练,但与真实数据匹配的正样本很难获得。由于这种数据稀缺性,从局部描述符中自然地获得全局监督变得非常困难。
- 数据增强:虽然数据增强可以增强描述符的鲁棒性,但这也可能破坏图像的全局一致性,使学习全局描述符变得更加困难。
- 多任务蒸馏:这是解决数据问题的方法,其中一个网络被训练来直接从教师网络获得表示。这通过简化和更灵活的训练步骤解决了上述问题。此外,这种方法通过多次训练运行来增强模型的稳健性。
这一部分的重点是描述提议的网络架构,处理特征的方式,以及面对数据稀缺性和其他挑战时的训练策略。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









