







一、实验目的/原理
1. 用D2RQ的SPARQL endpoint访问关系数据库查询知识库;
2. 用Python访问SPARQL endpoint服务获取数据。
3. 用Jena和Fuseki建立知识图谱并提供查询服务。
二、实验重难点
重点:用Jena和Fuseki建立知识图谱并提供查询服务。
难点:用Python访问SPARQL endpoint服务获取数据。
三、实验内容及步骤
(一)实验内容
1. 用D2RQ的SPARQL endpoint完成对电影知识库的查询;
2. 用Python访问SPARQL endpoint服务,完成电影知识查询;
3. 用Jena建立电影知识图谱;
4. 用Fuseki提供查询服务,并完成通过web的电影知识查询。
(二)实验步骤
1. 进入 d2rq 目录,使用下面的命令启动 D2R Server:
d2r-server.bat kgmovie_mapping.ttl

2.在浏览器输入“http://localhost:2020/” ,进入如下界面:
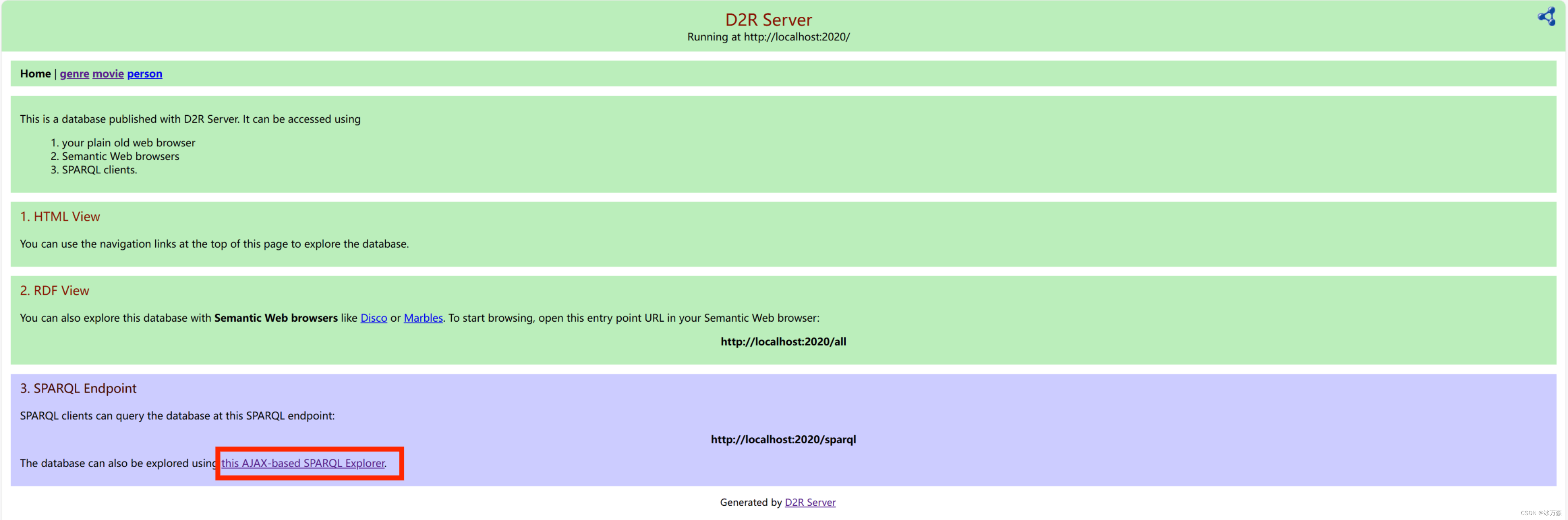
3.点击注点击红色方框中的链接,进入 SPARQL endpoint,如下图:

4.输入SPARQL 语句,点击 “Go!”,执行查询:
例1:“周星驰出演了哪些电影?”
SELECT ?moviename
WHERE {
?star rdf:type :Person .
?star :personName '周星驰' .
?star :hasActedIn ?movie .
?movie :movieTitle ?moviename
}
例2:“英雄这部电影有哪些演员参演?”
SELECT ?starname
WHERE {
?movie rdf:type :Movie .
?movie :movieTitle '英雄' .
?star :hasActedIn ?movie .
?star :personName ?starname
}

例3:“巩俐参演的评分大于 7 的电影有哪些?”
SELECT ?movie_name
WHERE {
?star rdf:type :Person .
?star :personName '巩俐' .
?star :hasActedIn ?movie .
?movie :movieTitle ?movie_name .
?movie :movieRating ?score .
FILTER(?score >= 7)
}

5. 安装SPARQLWrapper,编写 Python 脚本进行交互
(1)安装SPARQLWrapper
pip install SPARQLWrapper -i https://pypi.tuna.tsinghua.edu.cn/simple(2)调用SPARQLWrapper
from SPARQLWrapper import SPARQLWrapper, JSON
sparql = SPARQLWrapper("http://localhost:2020/sparql")
sparql.setQuery("""
PREFIX : <http://www.kgdemo.com#>
PREFIX rdf: <http://www.w3.org/1999/02/22-rdf-syntax-ns#>
PREFIX owl: <http://www.w3.org/2002/07/owl#>
PREFIX xsd: <http://www.w3.org/2001/XMLSchema#>
PREFIX vocab: <http://localhost:2020/resource/vocab/>
PREFIX rdfs: <http://www.w3.org/2000/01/rdf-schema#>
PREFIX map: <http://localhost:2020/resource/#>
PREFIX db: <http://localhost:2020/resource/>
SELECT ?moviename WHERE {
?star rdf:type :Person.
?star :personName '周星驰'.
?star :hasActedIn ?movie.
?movie :movieTitle ?moviename
}
""")
sparql.setReturnFormat(JSON)
results = sparql.query().convert()
for result in results["results"]["bindings"]:
print(result["moviename"]["value"])(3)将result里面的返回值提取并打印出来。

6.安装jena和fuseki
分别下载 apache-jena 和 apache-jena-fuseki,解压缩到硬盘,如:D:\jena和D:\ fuseki。
官网下载地址:https://jena.apache.org/download/index.cgi
7.配置环境变量和系统变量
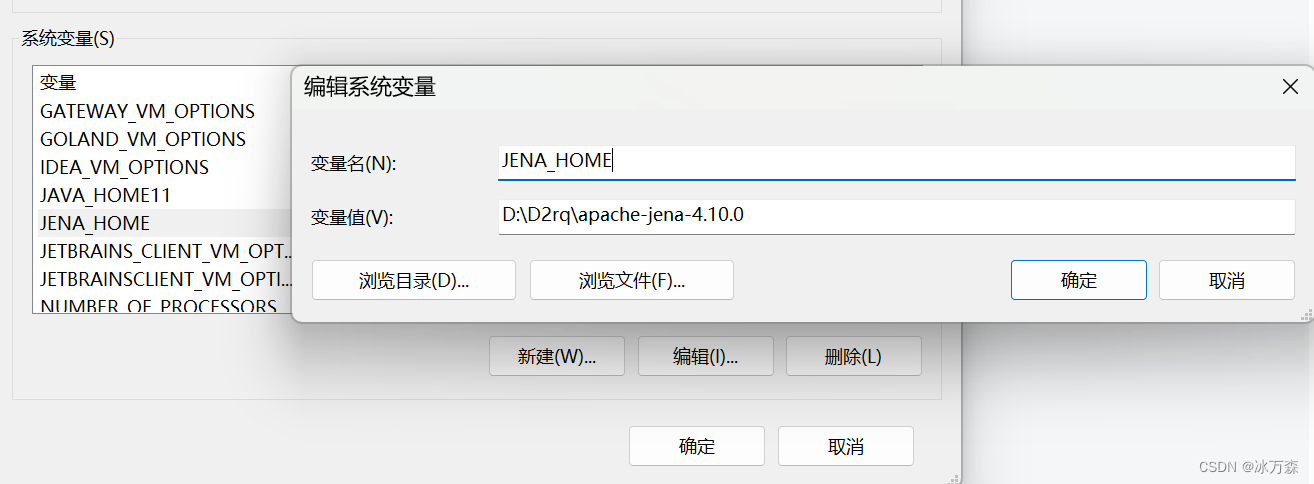
(1)我的电脑->属性->高级系统设置->环境变量,在系统变量里添加一项JENA_HOME:
变量名:JENA_HOME
值:D:\ jena(以自己的实际命名和路径为准)
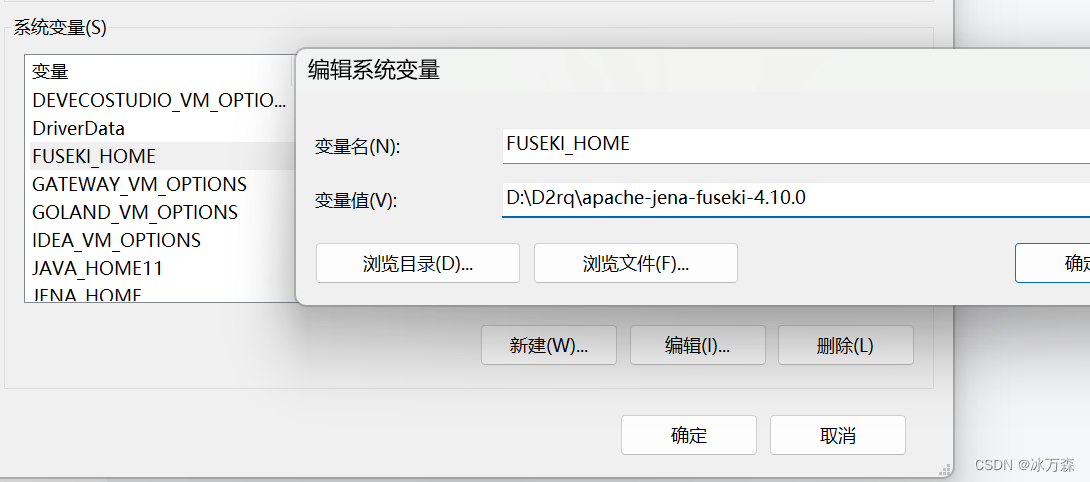
(2)我的电脑->属性->高级系统设置->环境变量,在系统变量里添加一项FUSEKI_HOME:
变量名:FUSEKI_HOME
值:D:\ fuseki(以自己的实际命名和路径为准)
(3)在Path中添加这些内容:
%FUSEKI_HOME%\bin
%JENA_HOME%\bin; %JENA_HOME%\bat;
8. 导入电影知识库
(1)创建一个目录(如“D:\jena\tdb”)用于存放 tdb 数据。
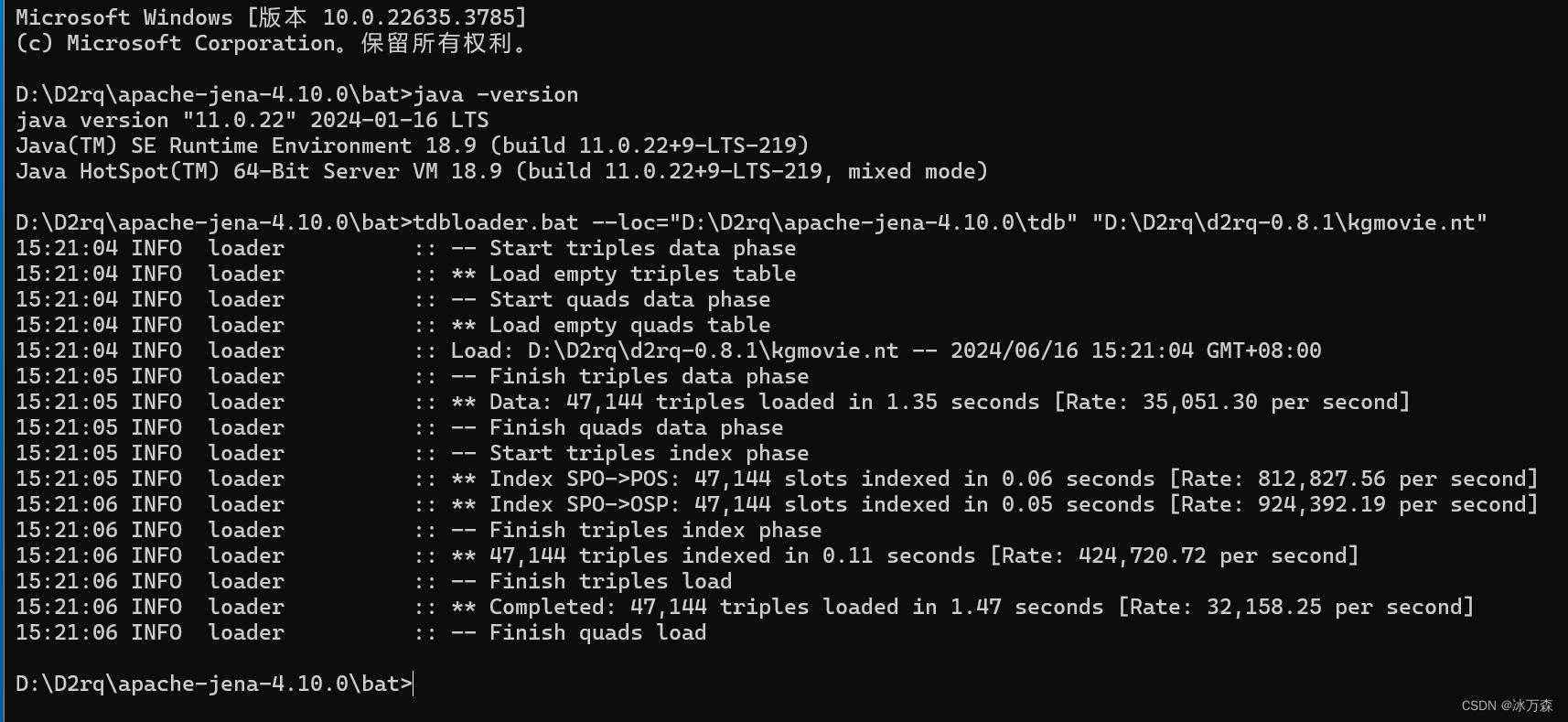
(2)进入jena文件夹下的 bat 目录,执行命令如下:
tdbloader.bat --loc="D:\D2rq\apache-jena-4.10.0\tdb" "D:\D2rq\d2rq-0.8.1\kgmovie.nt"
其中:“--loc” 指定tdb存储的位置,即自己创建的tqd文件夹;第二个参数是kgmovie.nt这个RDF数据。
9. 导入本体模型
(1)进入fuseki文件夹,运行“fuseki-server.bat”,然后退出,发现在当前目录下自动创建了“run” 文件夹。
(2)将通过PROTÉGÉ建立的本体模型文件 “ontology.owl”移动到“run”文件夹下的“databases”文件夹中,并将 “owl”后缀名改为“ttl”。(注意:该owl文件保存选择的是Turtle Syntax格式。)
10. 配置FUSEKI文件
在“run”文件夹下的“configuration”中,创建名为“fuseki_conf.ttl” 的文本文件
11. 启动FUSEKI服务
再次运行 “fuseki-server.bat”,如果出现如下界面表示运行成功:

12. 访问FUSEKI服务进行查询
浏览器访问“http://localhost:3030/” 进行 SPARQL 查询等操作。
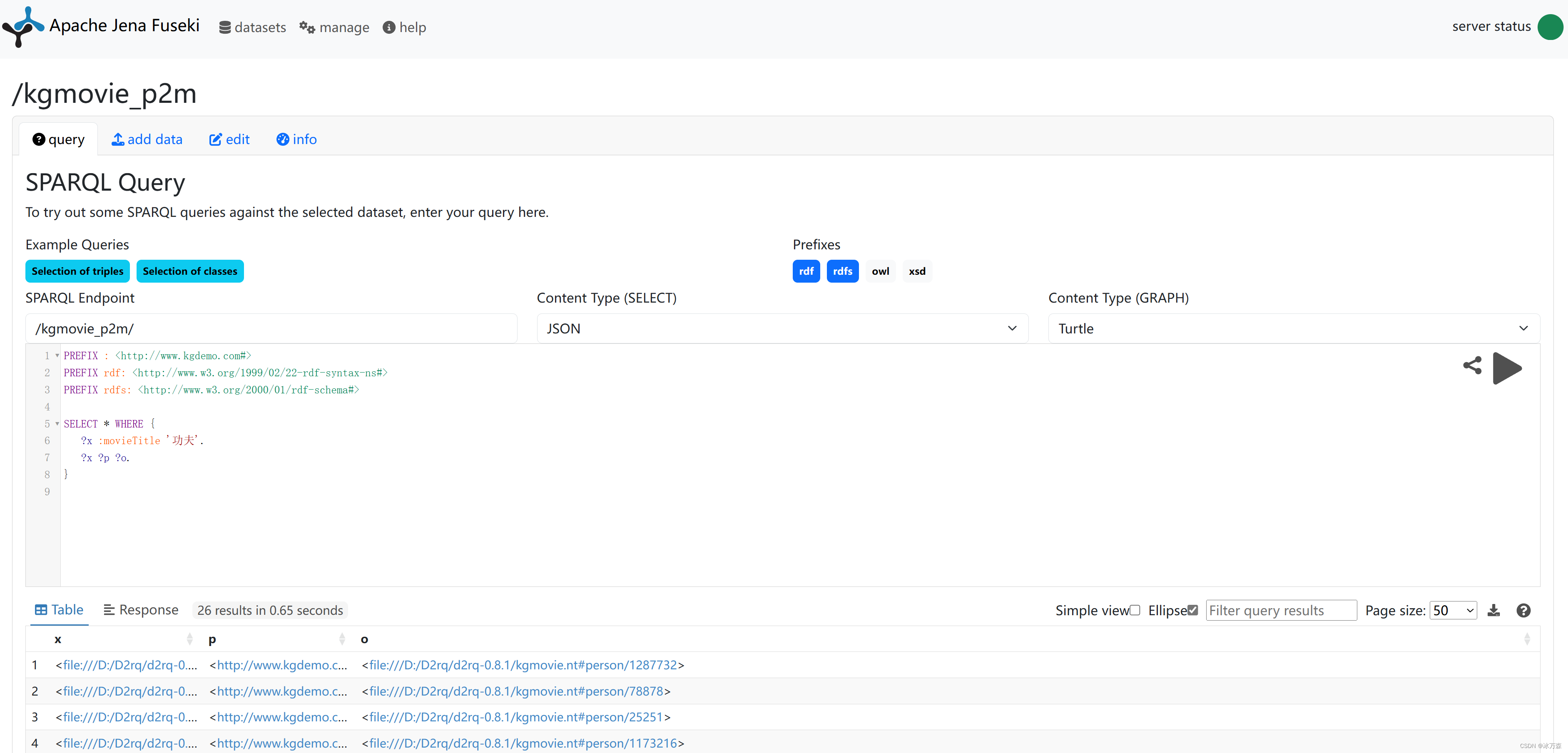
例1:查询电影《功夫》的所有属性
PREFIX : <http://www.kgdemo.com#>
PREFIX rdf: <http://www.w3.org/1999/02/22-rdf-syntax-ns#>
PREFIX rdfs: <http://www.w3.org/2000/01/rdf-schema#>
SELECT * WHERE {
?x :movieTitle '功夫'.
?x ?p ?o.
}
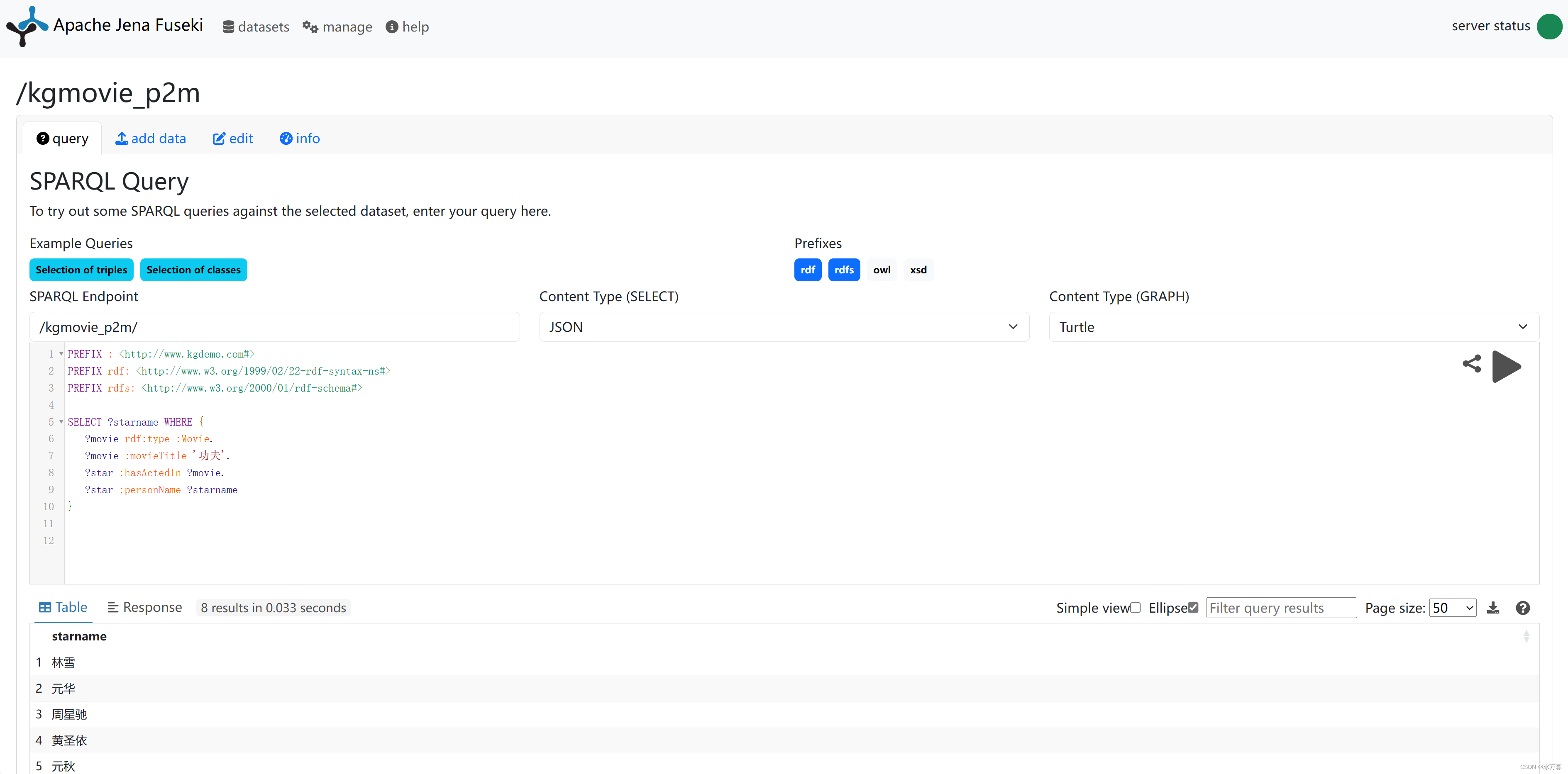
例2:查询“功夫”有哪些演员:
PREFIX : <http://www.kgdemo.com#>
PREFIX rdf: <http://www.w3.org/1999/02/22-rdf-syntax-ns#>
PREFIX rdfs: <http://www.w3.org/2000/01/rdf-schema#>
SELECT ?starname WHERE {
?movie rdf:type :Movie.
?movie :movieTitle '功夫'.
?star :hasActedIn ?movie.
?star :personName ?starname
}
13. 自定义推理规则
在 “databases” 文件夹下新建一个文本文件“rules.ttl”,填入如下内容:
@prefix : <http://www.kgdemo.com#> .
@prefix owl: <http://www.w3.org/2002/07/owl#> .
@prefix rdf: <http://www.w3.org/1999/02/22-rdf-syntax-ns#> .
@prefix xsd: <XML Schema> .
@prefix rdfs: <http://www.w3.org/2000/01/rdf-schema#> .
# 规则声明
[ruleComedian: (?p :hasActedIn ?m) (?m :hasGenre ?g) (?g :genreName '喜剧') -> (?p rdf:type :Comedian)]
# 反转规则声明
[ruleInverse: (?p :hasActedIn ?m) -> (?m :hasActor ?p)]
注:以上定义了两个规则
(1)喜剧演员:一个演员参演过电影,电影又是喜剧类型,那么他就是喜剧演员,这里的Comedian即是推理出来演员类型。
(2)取反规则:演员参演过电影,就一定有电影包含某个演员。
14. 修改配置文件打开自定义推理规则
修改配置文件“fuseki_conf.ttl”:
#关闭OWL推理机
#ja:reasoner [ja:reasonerURL <http://jena.hpl.hp.com/2003/OWLFBRuleReasoner>] .
#开启规则推理机,并指定规则文件路径
ja:reasoner [
ja:reasonerURL <http://jena.hpl.hp.com/2003/GenericRuleReasoner> ;
ja:rulesFrom <file:///D:/fuseki/run/databases/rules.ttl> ; ]
注:ja:rulesFrom <file:///D:/fuseki/run/databases/rules.ttl> ; ]中按实际情况修改成新建规则文件的路径和文件名。
15. 执行基于推理的查询
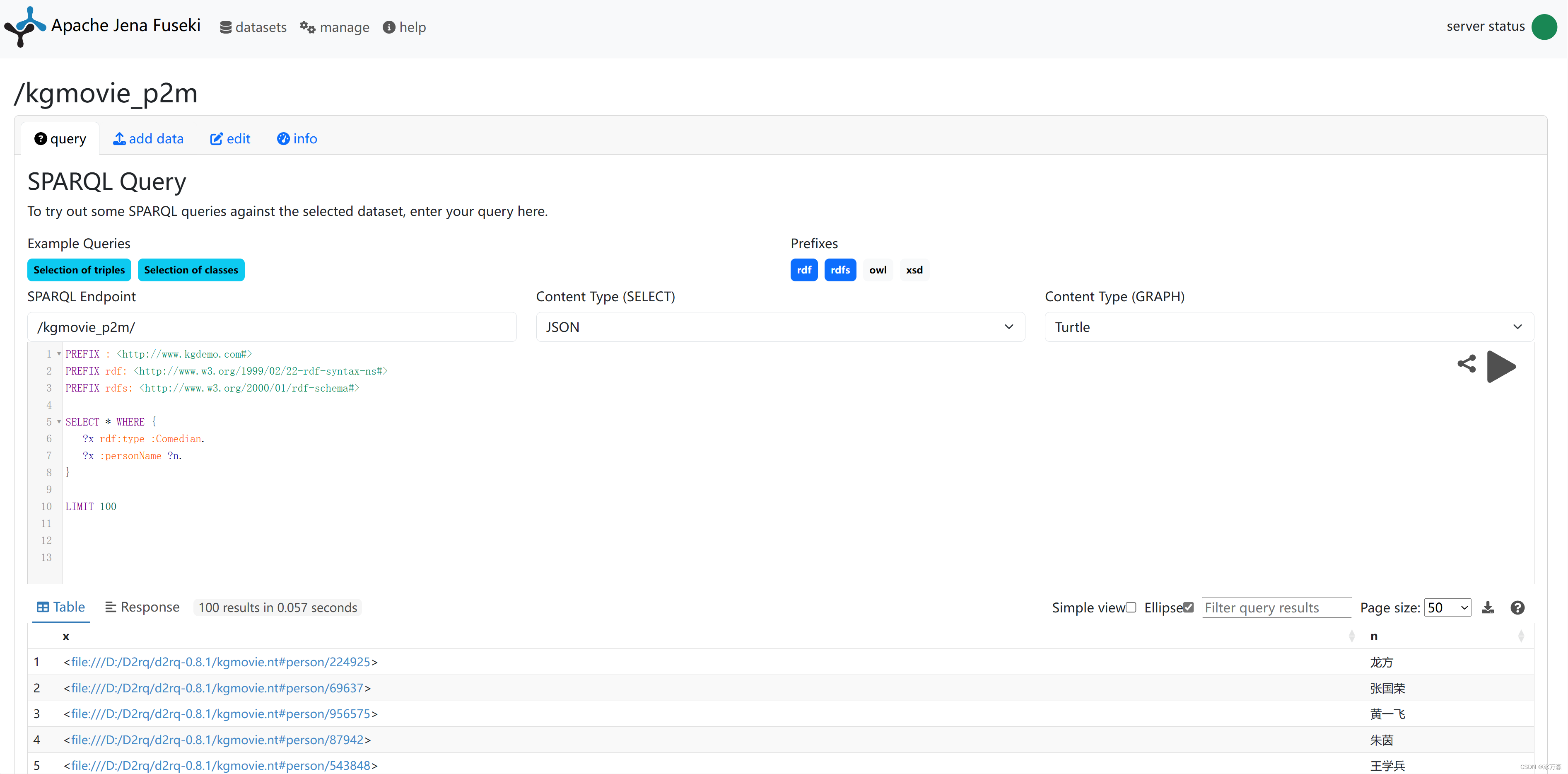
例:查询,喜剧演员有哪些:
PREFIX : <http://www.kgdemo.com#>
PREFIX rdf: <http://www.w3.org/1999/02/22-rdf-syntax-ns#>
PREFIX rdfs: <http://www.w3.org/2000/01/rdf-schema#>
SELECT * WHERE {
?x rdf:type :Comedian.
?x :personName ?n.
}
LIMIT 100


















 6万+
6万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









