






一、决策树简介
决策树,顾名思义,就是帮我们做出决策的树。现实生活中我们往往会遇到各种各样的抉择,把我们的决策过程整理一下,就可以发现,该过程实际上就是一个树的模型。
决策树分为分类树和回归树两种,分类树对离散变量做决策树,回归树对连续变量做决策树,这里我们只讨论分类树。
比如选择好瓜的时候: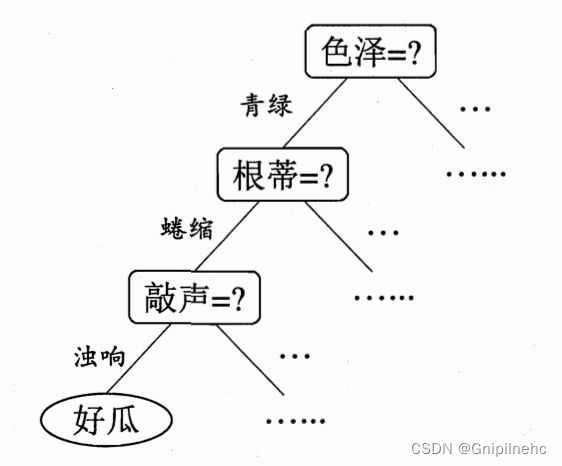
我们可以认为色泽、根蒂、敲声是一个西瓜的三个特征,每次我们做出抉择都是基于这三个特征来把一个节点分成好几个新的节点。
在上面的例子中,色泽、根蒂、声音特征选取完成后,开始进行决策,在我们的问题中,决策的内容实际上是将结果分成两类,即是(1)否(0)好瓜。这一类智能决策问题称为分类问题,决策树是一种简单的处理分类问题的算法。
二、决策树原理
1、决策树原理:归纳推理
2、归纳:是从特殊到一般的过程
3、归纳推理:从若干个事实表现出的特征、特性或属性中,通过比较、总结、概括而得出一个规律性的结论。
4、归纳推理的基本假定:任一假设如果能在足够大的训练样本集中很好地逼近目标函数,则它也能在未见样本中很好地逼近目标函数。
三、生成算法
1. ID3(信息增益)
从信息论的知识中我们知道:信息熵越大,样本的纯度越低。ID3 算法的核心思想就是以信息增益来度量特征选择,选择信息增益最大的特征进行分裂。
信息增益 = 信息熵 - 条件熵:
也可以表示为H0 - H1,比如上面实例中我选择纹理作为根节点,将根节点一分为三,则:
意思是,没有选择纹理特征前,是否是好瓜的信息熵为0.998,在我选择了纹理这一特征之后,信息熵下降为0.764,信息熵下降了0.234,也就是信息增益为0.234。
2. C4.5(信息增益率)
![]()
C4.5算法最大的特点是克服了ID3对特征数目的偏重这一缺点,引入信息增益率来作为分类标准。
信息增益率=信息增益/特征本身的熵:
信息增益率对可取值较少的特征有所偏好(分母越小,整体越大),因此C4.5并不是直接用增益率最大的特征进行划分,而是使用一个启发式方法:先从候选划分特征中找到信息增益高于平均值的特征,再从中选择增益率最高的。
例如上述的例子,我们考虑纹理本身的熵,也就是是否是好瓜的熵。
纹理本身有三种可能,每种概率都已知,则纹理的熵为:
那么选择纹理作为分类依据时,信息增益率为:
3. CART(基尼指数)
![]()
基尼指数(基尼不纯度):表示在样本集合中一个随机选中的样本被分错的概率。
基尼系数越小,不纯度越低,特征越好。这和信息增益(率)正好相反。基尼指数可以用来度量任何不均匀分布,是介于0-1之间的数,0是完全相等,1是完全不相等。
四、剪枝处理
决策树算法很容易过拟合,剪枝算法就是用来防止决策树过拟合,提高泛华性能的方法。剪枝分为预剪枝与后剪枝。
1. 预剪枝
预剪枝是指在决策树的生成过程中,对每个节点在划分前先进行评估,若当前的划分不能带来泛化性能的提升,则停止划分,并将当前节点标记为叶节点。
预剪枝方法有:
(1)当叶节点的实例个数小于某个阈值时停止生长;
(2)当决策树达到预定高度时停止生长;
(3)当每次拓展对系统性能的增益小于某个阈值时停止生长;
预剪枝不足就是剪枝后决策树可能会不满足需求就被过早停止决策树的生长。
2. 后剪枝
后剪枝是指先从训练集生成一颗完整的决策树,然后自底向上对非叶节点进行考察,若将该节点对应的子树替换为叶节点,能带来泛化性能的提升,则将该子树替换为叶节点。
后剪枝决策树通常比预剪枝决策树保留了更多的分枝,一般情形下,后剪枝决策树的欠拟合风险很小,泛化能力往往优于预剪枝决策树。但后剪枝决策树是在生产完全决策树之后进行的,并且要自底向上地对所有非叶子节点进行逐一考察,因此其训练时间开销比未剪枝的决策树和预剪枝的决策树都要大很多。
五、决策树优缺点
1.优点:
容易理解,可解释性较好
可以用于小数据集
时间复杂度较小
可以处理多输入问题,可以处理不相关特征数据
对缺失值不敏感
2.缺点:
在处理特征关联性比较强的数据时,表现得不太好
当样本中各类别不均匀时,信息增益会偏向于那些具有更多数值的特征
对连续性的字段比较难预测
容易出现过拟合
当类别太多时,错误可能会增加得比较快
六、python应用
在sklearn库中提供了DecisionTreeClassifier函数来实现决策树算法,其函数原型如下:
sklearn.tree.DecisionTreeClassifier(criterion='gini',max_deepth=None,random_state=None)
参数说明:
在python中决策数中默认的是gini系数,也可以选择信息增益的熵’entropy’
max_depth:树的深度大小
random_state:随机数种子
测试代码如下:
from sklearn.datasets import load_iris
from sklearn.model_selection import train_test_split
from sklearn.metrics import accuracy_score
from sklearn import tree
iris = load_iris() # 数据集导入
features = iris.data # 属性特征
labels = iris.target # 分类标签
train_features, test_features, train_labels, test_labels = \
train_test_split(features, labels, test_size=0.3, random_state=1) # 训练集,测试集分类
clf = tree.DecisionTreeClassifier(criterion='entropy',max_depth=3)
clf = clf.fit(train_features, train_labels) #X,Y分别是属性特征和分类label
test_labels_predict = clf.predict(test_features) # 预测测试集的标签
score = accuracy_score(test_labels, test_labels_predict) # 将预测后的结果与实际结果进行对比
print("CART分类树的准确率 %.4lf" % score) # 输出结果
dot_data = tree.export_graphviz(clf, out_file='iris_tree.dot') # 生成决策树可视化的dot文件
输出结果如下:
CART分类树的准确率 0.9556
















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









