






 本文详细阐述了朴素贝叶斯算法,包括其在判别式和生成式模型中的角色,条件概率和贝叶斯公式的运用,以及在垃圾邮件分类中的具体实现步骤,涉及拉普拉斯修正和概率计算的防溢出策略。
本文详细阐述了朴素贝叶斯算法,包括其在判别式和生成式模型中的角色,条件概率和贝叶斯公式的运用,以及在垃圾邮件分类中的具体实现步骤,涉及拉普拉斯修正和概率计算的防溢出策略。
一、朴素贝叶斯介绍
朴素贝叶斯算法的核心思想是通过考虑特征概率来预测分类,即对于给出的待分类样本,求解在此样本出现的条件下各个类别出现的概率,哪个最大,就认为此待分类样本属于哪个类别。朴素贝叶斯是一种分类算法,经常被用于文本分类,它的输出结果是某个样本属于某个类别的概率。
例子:
举个例子:眼前有100个西瓜,好瓜和坏瓜个数差不多,现在要用这些西瓜来训练一个「坏瓜识别器」,我们要怎么办呢?
一般挑西瓜时通常要「敲一敲」,听听声音,是清脆声、浊响声、还是沉闷声。所以,我们先简单点考虑这个问题,只用敲击的声音来辨别西瓜的好坏。根据经验,敲击声「清脆」说明西瓜还不够熟,敲击声「沉闷」说明西瓜成熟度好,更甜更好吃。
所以,坏西瓜的敲击声是「清脆」的概率更大,好西瓜的敲击声是「沉闷」的概率更大。当然这并不绝对——我们千挑万选地「沉闷」瓜也可能并没熟,这就是噪声了。当然,在实际生活中,除了敲击声,我们还有其他可能特征来帮助判断,例如色泽、跟蒂、品类等。
朴素贝叶斯把类似「敲击声」这样的特征概率化,构成一个「西瓜的品质向量」以及对应的「好瓜/坏瓜标签」,训练出一个标准的「基于统计概率的好坏瓜模型」,这些模型都是各个特征概率构成的。
这样,在面对未知品质的西瓜时,我们迅速获取了特征,分别输入「好瓜模型」和「坏瓜模型」,得到两个概率值。如果「坏瓜模型」输出的概率值大一些,那这个瓜很有可能就是个坏瓜。
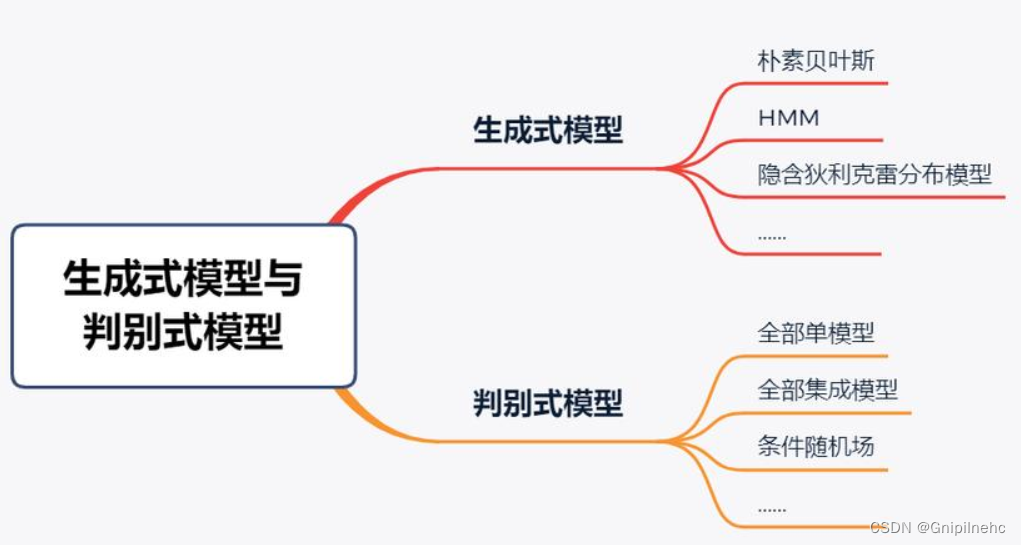
二、机器学习的两个视角
判别式模型
判别式模型,又称非概率模型,是指通过学习输入和输出之间的映射关系来建立模型y=f(x),然后利用该模型来预测新的输出。判别式模型的典型代表是支持向量机模型,该模型通过学习输入和输出之间的映射关系来建立分类模型,然后利用该模型来预测新的分类结果。
常见判别式模型:感知机、支持向量机、K临近、Adaboost、K均值、潜在语义分析、神经网络;逻辑回归既可以看做是生成式也可以看做是判别式。
生成式模型
生成式模型,又称概率模型,是指通过学习数据的分布来建立模型P(y|x),然后利用该模型来生成新的数据。生成式模型的典型代表是朴素贝叶斯模型,该模型通过学习数据的分布来建立概率模型,然后利用该模型来生成新的数据。
常见生成式模型:决策树、朴素贝叶斯、隐马尔可夫模型、条件随机场、概率潜在语义分析、潜在狄利克雷分配、高斯混合模型;
逻辑回归既可以看做是生成式也可以看做是判别式。
实例
问题:确定一个瓜(Z)是好瓜还是坏瓜?
判别式模型:用判别模型的方法是从历史数据中学习到模型,因为是有监督学习,映射成瓜的特征(x1,x2,x3...xn)到y1(好瓜)或者是y2(坏瓜)的映射关系。然后通过提取这只瓜(Z)的特征(x1,x2,x3...xn)来预测出这只瓜是好瓜的概率,是坏瓜的概率。
生成式模型:利用生成模型是根据好瓜的特征(x1,x2,x3...xn)首先学习出一个好瓜的模型,然后根据坏瓜的特征(x1,x2,x3...xn)学习出一个坏瓜的模型,然后从要判定的这个瓜(Z)中提取特征,放到好瓜模型中看概率是多少,在放到坏瓜模型中看概率是多少,哪个大就是哪个。
三、条件概率与贝叶斯公式
条件概率定义:
条件概率是指事件A在事件B发生的条件下发生的概率,记作:P(A|B)
条件概率公式
贝叶斯公式:
由条件概率公式推导出
四、朴素贝叶斯分类器
1.朴素贝叶斯公式
朴素贝叶斯公式是在贝叶斯公式的基础上,引入了"朴素"假设,假设特征之间相互独立。根据朴素贝叶斯公式,可以计算在给定一组特征的条件下,某个类别的后验概率。朴素贝叶斯公式如下:
其中,P(y|x1, x2, …, xn) 表示在给定特征 x1, x2, …, xn 的条件下,类别 y 的后验概率;P(x1|y), P(x2|y), …, P(xn|y) 表示在类别 y 的条件下,特征 x1, x2, …, xn 出现的概率;P(y) 表示类别 y 的先验概率;P(x1, x2, …, xn) 表示特征 x1, x2, …, xn 的联合概率。
2.朴素贝叶斯分类器
朴素贝叶斯分类器(Naïve Bayes Classifier)采用了“属性条件独立性假设” ,即每个属性独立地对分类结果发生影响。为方便公式标记,不妨记P(C=c|X=x)为P(c|x),基于属性条件独立性假设,贝叶斯公式可重写为:
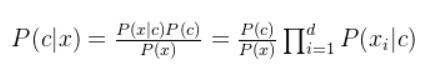
其中d为属性数目,为
在第
个属性上的取值。
由于对所有类别来说 P(x)相同,因此MAP判定准则可改为:
其中 和
为目标参数。
朴素贝叶斯分类器的训练器的训练过程就是基于训练集D估计类先验概率 ,并为每个属性估计条件概率
。
令 表示训练集D中第c类样本组合的集合,则类先验概率:
3.拉普拉斯修正
若某个属性值在训练集中没有与某个类同时出现过,则训练后的模型会出现 over-fitting 现象。比如训练集中没有该样例,因此连乘式计算的概率值为0,这显然不合理。因为样本中不存在(概率为0),不代该事件一定不可能发生。所以为了避免其他属性携带的信息,被训练集中未出现的属性值“ 抹去” ,在估计概率值时通常要进行“拉普拉斯修正”。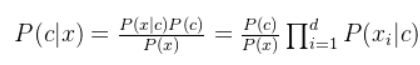 ,我们要修正
,我们要修正 的值。
令 N 表示训练集 D 中可能的类别数, 表示第i个属性可能的取值数,则贝叶斯公式可修正为:
![]()
4.防溢出策略
条件概率乘法计算过程中,因子一般较小(均是小于1的实数)。当属性数量增多时候,会导致累乘结果下溢出的现象。
在代数中有 ,因此可以把条件概率累乘转化成对数累加。分类结果仅需对比概率的对数累加法运算后的数值,以确定划分的类别。
五、垃圾邮件分类实战
测试:
import os
import re
import string
import math
import numpy as np
# 过滤数字
def replace_num(txt_str):
txt_str = txt_str.replace(r'0', '')
txt_str = txt_str.replace(r'1', '')
txt_str = txt_str.replace(r'2', '')
txt_str = txt_str.replace(r'3', '')
txt_str = txt_str.replace(r'4', '')
txt_str = txt_str.replace(r'5', '')
txt_str = txt_str.replace(r'6', '')
txt_str = txt_str.replace(r'7', '')
txt_str = txt_str.replace(r'8', '')
txt_str = txt_str.replace(r'9', '')
return txt_str
def get_filtered_str(category):
email_list = []
translator = re.compile('[%s]' % re.escape(string.punctuation))
for curDir, dirs, files in os.walk(f'./email/{category}'):
for file in files:
file_name = os.path.join(curDir, file)
with open(file_name, 'r', encoding='utf-8') as f:
txt_str = f.read()
# 全部小写
txt_str = txt_str.lower()
# 过滤掉所有符号
txt_str = translator.sub(' ', txt_str)
# 过滤掉全部数字
txt_str = replace_num(txt_str)
# 把全体的邮件文本 根据换行符把string划分成列表
txt_str_list = txt_str.splitlines()
# 把获取的全体单词句子列表转成字符串
txt_str = ''.join(txt_str_list)
# print(txt_str)
email_list.append(txt_str)
return email_list
def get_dict_spam_dict_w(spam_email_list):
'''
:param email_list: 每个邮件过滤后形成字符串,存入email_list
:param all_email_words: 列表。把所有的邮件内容,分词。一个邮件的词 是它的一个列表元素
:return:
'''
all_email_words = []
# 用set集合去重
word_set = set()
for email_str in spam_email_list:
# 把每个邮件的文本 变成单词
email_words = email_str.split(' ')
# 把每个邮件去重后的列表 存入列表
all_email_words.append(email_words)
for word in email_words:
if(word!=''):
word_set.add(word)
# 计算每个垃圾词出现的次数
word_dict = {}
for word in word_set:
# 创建字典元素 并让它的值为1
word_dict[word] = 0
# print(f'word={word}')
# 遍历每个邮件,看文本里面是否有该单词,匹配方法不能用正则.邮件里面也必须是分词去重后的!!! 否则 比如出现re是特征, 那么remind 也会被匹配成re
for email_words in all_email_words:
for email_word in email_words:
# print(f'spam_email={email_word}')
# 把从set中取出的word 和 每个email分词后的word对比看是否相等
if(word==email_word):
word_dict[word] += 1
# 找到一个就行了
break
# 计算垃圾词的概率
# spam_len = len(os.listdir(f'./email/spam'))
# print(f'spam_len={spam_len}')
# for word in word_dict:
# word_dict[word] = word_dict[word] / spam_len
return word_dict
def get_dict_ham_dict_w(spam_email_list,ham_email_list):
'''
:param email_list: 每个邮件过滤后形成字符串,存入email_list
:param all_email_words: 列表。把所有的邮件内容,分词。一个邮件的词 是它的一个列表元素
:return:
'''
all_ham_email_words = []
# 用set集合去重 得到垃圾邮件的特征w
word_set = set()
#获取垃圾邮件特征
for email_str in spam_email_list:
# 把每个邮件的文本 变成单词
email_words = email_str.split(' ')
for word in email_words:
if (word != ''):
word_set.add(word)
for ham_email_str in ham_email_list:
# 把每个邮件的文本 变成单词
ham_email_words = ham_email_str.split(' ')
# print(f'ham_email_words={ham_email_words}')
# 把每个邮件分割成单词的 的列表 存入列表
all_ham_email_words.append(ham_email_words)
# print(f'all_ham_email_words={all_ham_email_words}')
# 计算每个垃圾词出现的次数
word_dict = {}
for word in word_set:
# 创建字典元素 并让它的值为1
word_dict[word] = 0
# print(f'word={word}')
# 遍历每个邮件,看文本里面是否有该单词,匹配方法不能用正则.邮件里面也必须是分词去重后的!!! 否则 比如出现re是特征, 那么remind 也会被匹配成re
for email_words in all_ham_email_words:
# print(f'ham_email_words={email_words}')
for email_word in email_words:
# 把从set中取出的word 和 每个email分词后的word对比看是否相等
# print(f'email_word={email_word}')
if(word==email_word):
word_dict[word] += 1
# 找到一个就行了
break
return word_dict
# 获取测试邮件中出现的 垃圾邮件特征
def get_X_c1(spam_w_dict,file_name):
# 获取测试邮件
# file_name = './email/spam/25.txt'
# 过滤文本
translator = re.compile('[%s]' % re.escape(string.punctuation))
with open(file_name, 'r', encoding='utf-8') as f:
txt_str = f.read()
# 全部小写
txt_str = txt_str.lower()
# 过滤掉所有符号
txt_str = translator.sub(' ', txt_str)
# 过滤掉全部数字
txt_str = replace_num(txt_str)
# 把全体的邮件文本 根据换行符把string划分成列表
txt_str_list = txt_str.splitlines()
# 把获取的全体单词句子列表转成字符串
txt_str = ''.join(txt_str_list)
# 把句子分成词
email_words = txt_str.split(' ')
# 去重
x_set = set()
for word in email_words:
if word!='':
x_set.add(word)
# print(f'\ntest_x_set={x_set}')
spam_len = len(os.listdir(f'./email/spam'))
# 判断测试邮件的词有哪些是垃圾邮件的特征
spam_X_num = []
for xi in x_set:
for wi in spam_w_dict:
if xi == wi:
spam_X_num.append(spam_w_dict[wi])
# print(f'\nspam_X_num={spam_X_num}')
w_appear_sum_num = 1
for num in spam_X_num:
w_appear_sum_num += num
# print(f'\nham_w_appear_sum_num={w_appear_sum_num}')
# 求概率
w_c1_p = w_appear_sum_num / (spam_len + 2)
return w_c1_p
# 获取测试邮件中出现的 垃圾邮件特征
def get_X_c2(ham_w_dict,file_name):
# 过滤文本
translator = re.compile('[%s]' % re.escape(string.punctuation))
with open(file_name, 'r', encoding='utf-8') as f:
txt_str = f.read()
# 全部小写
txt_str = txt_str.lower()
# 过滤掉所有符号
txt_str = translator.sub(' ', txt_str)
# 过滤掉全部数字
txt_str = replace_num(txt_str)
# 把全体的邮件文本 根据换行符把string划分成列表
txt_str_list = txt_str.splitlines()
# 把获取的全体单词句子列表转成字符串
txt_str = ''.join(txt_str_list)
# 把句子分成词
email_words = txt_str.split(' ')
# 去重
x_set = set()
for word in email_words:
if word!='':
x_set.add(word)
# print(f'\ntest_x_set={x_set}')
# 判断测试邮件的词有哪些是垃圾邮件的特征
ham_X_num = []
for xi in x_set:
for wi in ham_w_dict:
if xi == wi:
ham_X_num.append(ham_w_dict[wi])
# print(f'\nham_X_num={ham_X_num}')
# 先求分子 所有词出现的总和
ham_len = len(os.listdir(f'./email/ham'))
w_appear_sum_num = 1
for num in ham_X_num:
w_appear_sum_num += num
# print(f'\nspam_w_appear_sum_num={w_appear_sum_num}')
# 求概率
w_c2_p = w_appear_sum_num / (ham_len+2)
return w_c2_p
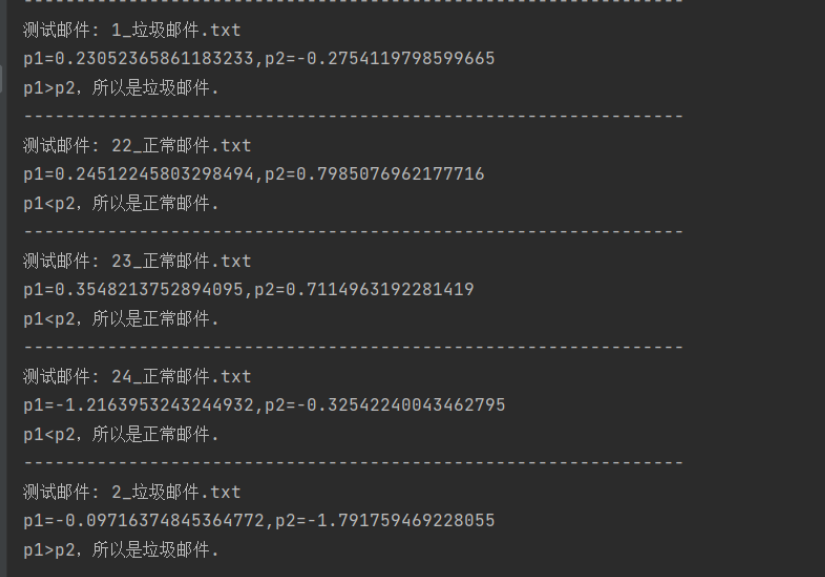
def email_test(spam_w_dict,ham_w_dict):
for curDir, dirs, files in os.walk(f'./email/test'):
for file in files:
file_name = os.path.join(curDir, file)
print('---------------------------------------------------------------')
print(f'测试邮件: {file}')
# 获取条件概率 p(X|c1)
p_X_c1 = get_X_c1(spam_w_dict,file_name)
# 获取条件概率 p(X|c2)
p_X_c2 = get_X_c2(ham_w_dict,file_name)
# print(f'\nX_c1={p_X_c1}')
# print(f'\nX_c2={p_X_c2}')
# #注意:Log之后全部变为负数
A = np.log(p_X_c1) + np.log(1 / 2)
B = np.log(p_X_c2) + np.log(1 / 2)
# 除法会出现问题,-1 / 负分母 结果 < -2/同一个分母
print(f'p1={A},p2={B}')
# 因为分母一致,所以只比较 分子即可
if A > B:
print('p1>p2,所以是垃圾邮件.')
if A <= B:
print('p1<p2,所以是正常邮件.')
if __name__=='__main__':
spam_email_list = get_filtered_str('spam')
ham_email_list = get_filtered_str('ham')
spam_w_dict = get_dict_spam_dict_w(spam_email_list)
ham_w_dict = get_dict_ham_dict_w(spam_email_list,ham_email_list)
# print(f'\n从垃圾邮件中提取的特征及每个特征出现的邮件数:')
# print(f'spam_w_dict={spam_w_dict}')
# print(f'\n普通邮件中垃圾邮件特征出现的邮件数为:')
# print(f'ham_w_dict={ham_w_dict}')
email_test(spam_w_dict, ham_w_dict)
结果:

















 6158
6158

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









