






一、Logistic回归概述
逻辑回归也称作logistic回归分析,是一种广义的线性回归分析模型,属于机器学习中的监督学习。其推导过程与计算方式类似于回归的过程,但实际上主要是用来解决二分类问题(也可以解决多分类问题)。通过给定的n组数据(训练集)来训练模型,并在训练结束后对给定的一组或多组数据(测试集)进行分类。其中每一组数据都是由p 个指标构成。
Logistic回归是众多分类算法中的一员。通常,Logistic回归用于二分类问题,例如预测明天是否会下雨。当然它也可以用于多分类问题,不过为了简单起见,本文暂先讨论二分类问题。首先,让我们来了解一下,什么是Logistic回归。
假设现在有一些数据点,我们利用一条直线对这些点进行拟合(该线称为最佳拟合直线),这个拟合过程就称作为回归,如下图所示:
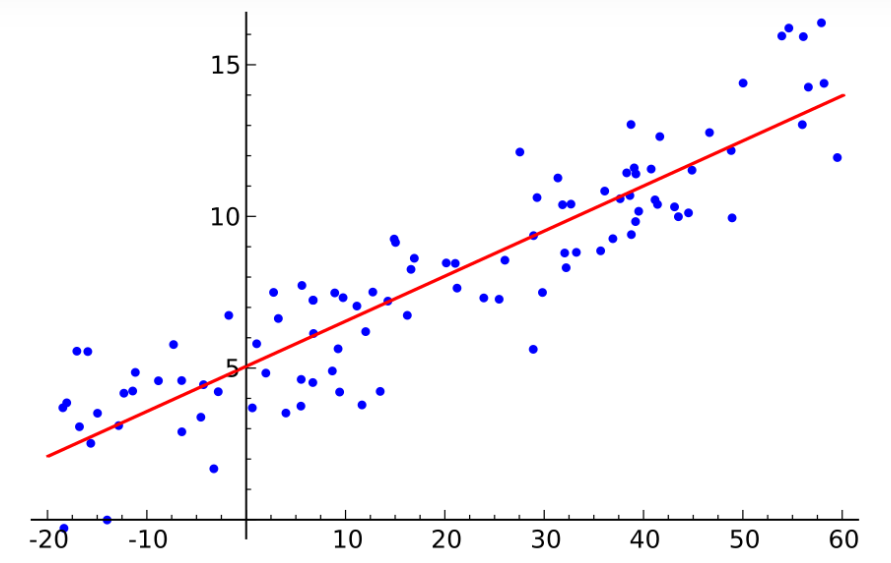
Logistic回归一种二分类算法,它利用的是Sigmoid函数阈值在[0,1]这个特性。Logistic回归进行分类的主要思想是:根据现有数据对分类边界线建立回归公式,以此进行分类。其实,Logistic本质上是一个基于条件概率的判别模型(Discriminative Model)。
二、Logistic回归
1.线性回归
逻辑回归在本质上其实是由线性回归衍变而来的,因此想要更好地理解逻辑回归,先让我们复习一下线性回归。线性回归的原理其实就是用一个线性回归方程来描述一个线性回归的问题。而线性回归的方程可以写作一个几乎大家都熟悉的方程:
在这个方程中,w0被称作截距,w1 ~ wn 被称作系数,这个线性回归方程也可以用矩阵来表示: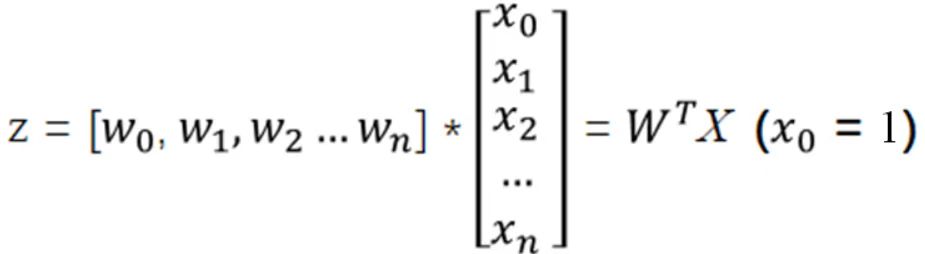
通过求出函数z,线性回归便完成了使用输入的特征矩阵X得到了一组连续型的标签值y_pred的操作,从而就可以完成对各种连续型变量的预测任务了。
但是线性回归模型更多地被用于对连续型数据进行预测,很少甚至是不被用于对离散型数据进行分类。因此为了实现回归模型可以对离散型数据进行分类操作,就有了逻辑回归这个回归模型。在逻辑回归算法中,为了实现分类的效果,我们通常使用的就是sigmoid函数。
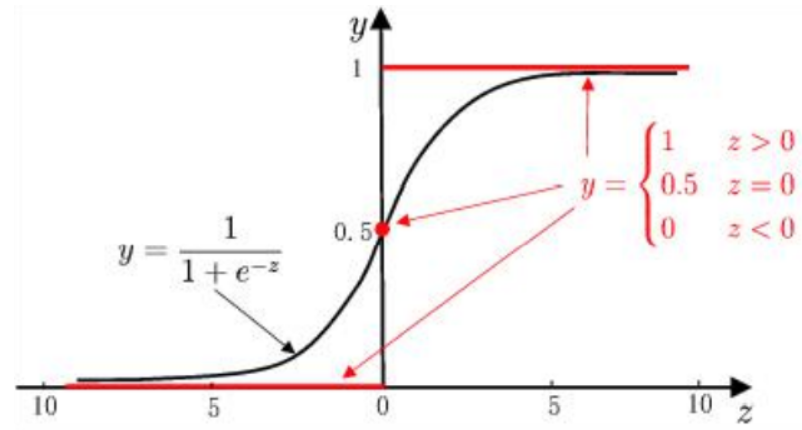
2.Sigmoid函数
为了实现Logistic回归分类,我们可以在每个特征上都乘以一个回归系数,然后把所有的结果值相加,将这个总和代入Sigmoid函数中,进而得到一个范围在0~1之间的数值。任何大于0.5的数据被分入1类,小于0.5即被归入0类。所以,Logistic回归也可以被看成是一种概率估计。
预测值与输出标记: ![]()
其中Sigmoid函数的输入值为z、向量x是分类器的输入数据,向量w和常数b是通过极大似然估计最佳系数、常数。
运用Sigmoid函数:
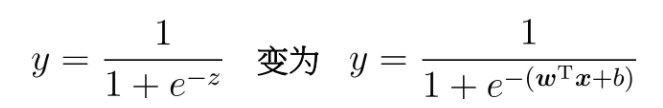
对数几率(log odds):样本作为正例的相对可能性的对数 ![]()
![]()
因此有:
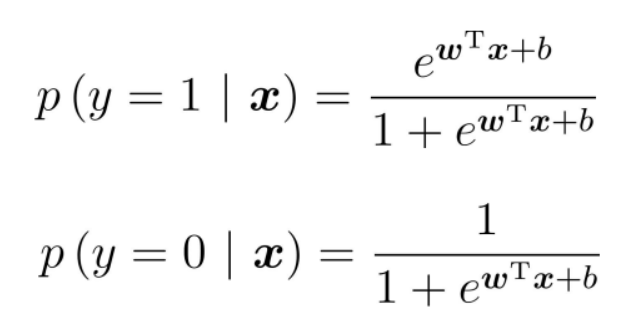
上面两个式子分别表示y=1和y=0的概率。通过,我们获得z值,再通过Sigmoid函数把z值映射到0~1之间,获得数值之后就可进行分类。比如定义,大于0.5的分类为1,反之,即分类为0。所以我们要解决的问题就是获得最佳回归系数,即求解w和b得值。
3.极大似然估计
逻辑回归与极大似然估计的关系:
最大似然估计就是通过已知结果去反推最大概率导致该结果的参数。极大似然估计是概率论在统计学中的应用,它提供了一种给定观察数据来评估模型参数的方法,即 “模型已定,参数未知”,通过若干次试验,观察其结果,利用实验结果得到某个参数值能够使样本出现的概率为最大,则称为极大似然估计。逻辑回归是一种监督式学习,是有训练标签的,就是有已知结果的,从这个已知结果入手,去推导能获得最大概率的结果参数θ,只要我们得出了这个参数,那我们的模型就自然可以很准确的预测未知的数据了。
之前提到了![]() 可以视为类1的后验概率,所以有:
可以视为类1的后验概率,所以有:
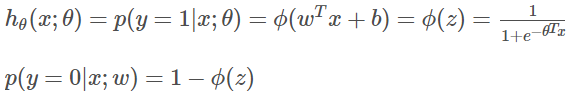
将上面两式写为一般形式:
![]()
接下来使用极大似然估计来根据给定的训练集估计出参数w:
![]()
为了简化运算,我们对上述等式两边取一个对数:
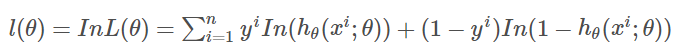
现在要求使得最大的
,在
前面加一个负号就变为最小化负对数似然函数:
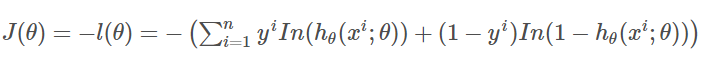
如此就得到了代价函数。让我们更好地理解这个代价函数:

等价于:
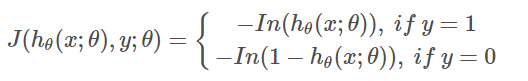
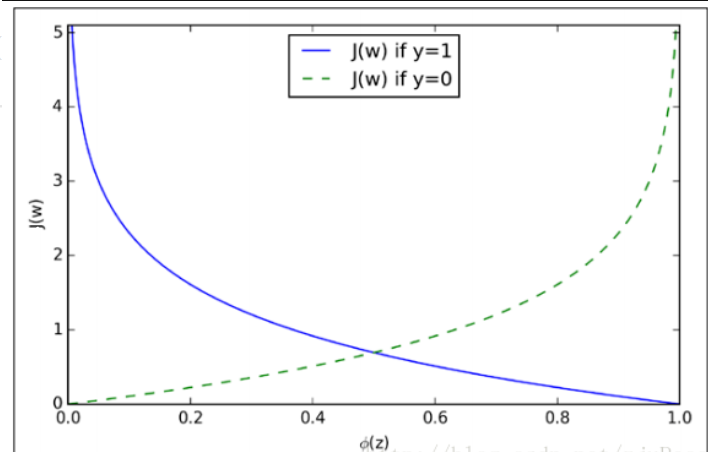
可以看出,如果样本的类别为1,估计值ϕ(z)越接近1付出的代价越小,反之越大。
同理,如果样本的值为0的话,估计值ϕ(z)越接近于0付出的代价越小,反之越大。
4.利用梯度下降法求解参数w
首先解释一些问什么梯度的负方向就是代价函数下降最快的方向,借助于泰勒展开:
![]()
和
![]() 均为向量,那么两者的内积就等于:
均为向量,那么两者的内积就等于:
![]()
当θ=π时,也就是在f′(x)的负方向时,取得最小值,也就是下降的最快方向了。
梯度下降:
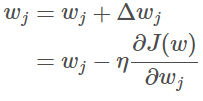
η为学习率,用来控制步长
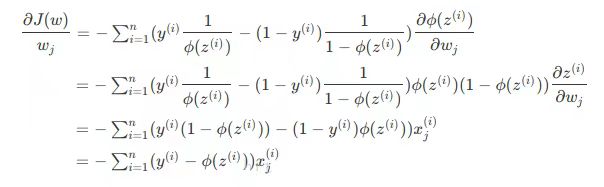
所以,在使用梯度下降法更新权重时,只要根据下式即可:
![]()
(xj代表第j列特征,wj代表第j个特征对应的参数)
当样本量极大的时候,每次更新权重都需要遍历整个数据集,会非常耗时,这时可以采用随机梯度下降法:
![]()
每次仅用一个样本点来更新回归系数,这种方法被称作随机梯度上升法。(由于可以在新样本到来时对分类器进行增量式更新,因此随机梯度算法是一个在线学习算法。)它与梯度上升算法效果相当,但占用更少的资源。
四、逻辑回归的优缺点
1、优点
(1)适合分类场景
(2)计算代价不高,容易理解实现。
(3)不用事先假设数据分布,这样避免了假设分布不准确所带来的问题。
(4)不仅预测出类别,还可以得到近似概率预测。
(5)目标函数任意阶可导。
2、缺点
(1)容易欠拟合,分类精度不高。
(2)数据特征有缺失或者特征空间很大时表现效果并不好。















 3108
3108











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









