









基于哈夫曼树的英文文本数据压缩算法
(1)问题描述
输入一串字符串,根据给定的字符串中字符出现的频率建立相应的哈夫曼树,构造哈夫曼编码表,在此基础上可以对压缩文件进行压缩(即编码),同时可以对压缩后的二进制编码文件进行解压(即译码)。
(2)输入要求
多组数据,每组数据1行,为一个字符串(只考虑26个小写字母即可)。当输入字符串为“0”时,输入结束。
(3)输出要求
每组数据输出2n+3行(n为输入串中字符类别的个数。第1行为统计出来的字符出现频率(只输出存在的字符,格式为:字符:频度),每两组字符之间用一个空格分隔,字符按照 ASCII 码从小到大的顺序排列。第2行至第2n行为哈夫曼树的存储结构的终态,如主教材139页表5.2(b),一行当中的数据用空格分隔。第2n+1行为每个字符的哈夫曼编码(只输出存在的字符,格式为:
字符:编码),每两组字符之间用一个空格分隔,字符按照ASCII码从小到大的顺序排列。第2n+2行为编码后的字符串,第2n+3行为解码后的字符串(与输入的字符串相同)。
(4)输入样式
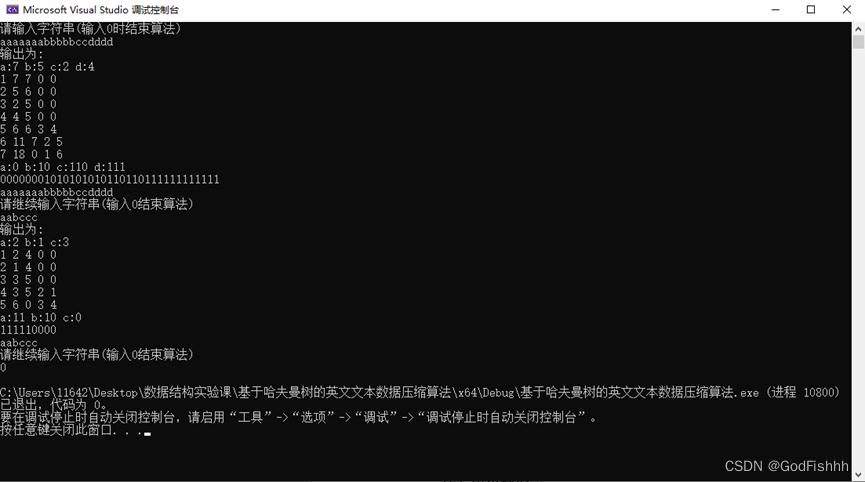
aaaaaaabbbbbccdddd (案例1)
aabccc (案例2)
0
(5)输出样例
a:7 b:5 c:2 d:4 (案例1)
1 7 7 0 0
2 5 6 0 0
3 2 5 0 0
4 4 5 0 0
5 6 6 3 4
6 11 7 2 5
7 18 0 1 6
a:0 b:10 c:110 d:111
00000001010101010110110111111111111
aaaaaaabbbbbccdddd
a:2 b:l c:3 (案例2)
1 2 4 0 0
2 1 4 0 0
3 3 5 0 0
4 3 5 2 1
5 6 0 3 4
a:11 b:10 c:0
111110000
aabccc
代码如下(包含注释解释部分代码):
#include<iostream>
#include<cstring>
#include<string>
using namespace std;
struct Num
{
char ch; //字符
int num; //字符对应个数
}an[7000], temp;
//sort1根据字符个数从大到小进行排序
void sort1(Num* bn)
{
Num te; //相当于一个临时变量,用作保存数据来完成数据的交换
int i, j;
//冒泡排序:
for (j = 0; j < 26; j++) //总共二十六个字母,则大循环进行二十六次(0-25共二十六次)
for (i = 0; i < 26-j-1; i++)
{
if (bn[i].num < bn[i + 1].num)
{
te = bn[i];
bn[i] = bn[i + 1];
bn[i + 1] = te;
}
}
}
//sort2根据字符的ASCII码值从小到大进行排序
void sort2(Num* bn, int n) //n为统计的所输入数据中的字符种类数
{
Num te;
int i, j;
//冒泡排序:
for (j = 0; j < n; j++)
for (i = 0; i < n-j-1; i++)
{
if (bn[i].ch > bn[i + 1].ch && bn[i + 1].num > 0) //交换条件为当前字符的权重大于下一个字符的权重,且下一个字符的数量大于0,即下一个字符存在
{
te = bn[i];
bn[i] = bn[i + 1];
bn[i + 1] = te;
}
}
}
//哈夫曼数的结构体
typedef struct
{
int weight; //权重
int parent, lchild, rchild; //父节点,左右孩子节点
int vis; //作为一个标识符使用(防止重复进行select过程)
char ch; //节点对应的字符
char strc[60]; //哈夫曼编码
int len;
int num; //某个字符在哈夫曼树中的个数
}HTNode, * HuffmanTree; //HTNode == * HuffmanTree(解引用)
//Select根据权重来安排哈夫曼树中节点的位置
//第一个参数为指向哈夫曼树的指针的引用,第二个参数为所处哈夫曼树中节点的个数,第三第四个参数为两个标识符,且参数为引用传递,可以通过函数改变该标识符的值
void Select(HuffmanTree& HT, int k, int& s1, int& s2)
{
int i;
HTNode h1, h2; //HTNode对应的应该是指向哈夫曼树的指针
int t1, t2; //作为标记,分别标记h1,h2对应节点所处的位置
t1 = t2 = 0;
h1 = HT[1];
h1.weight = 999999;
for (i = 1; i <= k; i++) //循环共k个节点,分别与现有的h1.weight比较权重,从而选出所含权重最小的节点值并将该值赋值给h1.weight
{
if (HT[i].weight <= h1.weight && HT[i].vis == 0)
{
h1 = HT[i];
t1 = i;
}
}
h2 = HT[2];
h2.weight = 999999;
for (i = 1; i <= k; i++) //再对h2进行和h1相同的选择赋值过程
{
if (HT[i].weight <= h2.weight && t1 != i && HT[i].vis == 0)
{
h2 = HT[i];
t2 = i;
}
}
//在h1和h2权重相同的情况下,将所含字符数更少的字符放在前面
if (h1.weight == h2.weight && HT[t1].num > HT[t2].num)
{
int temp;
temp = t1;
t1 = t2;
t2 = temp;
}
//将更新后的t1,t2分别赋值给s1,s2
s1 = t1;
s2 = t2;
//令vis=1,标识HT[s1]和HT[s2]这两个节点以及经过了Select作用,防止重复进行该过程
HT[s1].vis = 1;
HT[s2].vis = 1;
return;
}
//哈夫曼树的编码函数
//第一个参数是指向哈夫曼树指针的引用,第二个参数是字符串的长度,第三个参数为字符串,第四个参数是哈夫曼树中的第n个节点,第五个参数为编码(左孩子为'0',右孩子为'1')
void code(HuffmanTree& HT, int len, const char str[], int n, char cc)
{
int i;
//HT[n].strc的前len-2个字符都设置为str[i],第len-1个字符设置为编码值cc,第len个字符设置为空'\0'
for (i = 0; i < len - 1; i++)
HT[n].strc[i] = str[i];
HT[n].strc[i] = cc;
HT[n].strc[i + 1] = '\0';
//利用递归完成整棵树的编码
//如果左子树不为空,则一直编码直到左子树为空
if (HT[n].lchild != 0)
code(HT, len + 1, HT[n].strc, HT[n].lchild, '0');
//如果右子树不为空,则一直编码直到右子树为空
if (HT[n].rchild != 0)
code(HT, len + 1, HT[n].strc, HT[n].rchild, '1');
}
//哈夫曼树的构造(利用了Select函数进行选择排序以及Code函数进行编码)
//第一个参数是一个指向哈夫曼树的指针的引用,第二个参数为n个子叶节点(即没有左右孩子的节点),第三个参数为
void CreateHuffmanTree(HuffmanTree& HT, int n, char* str, int n1)
{
int s1, s2;
s1 = s2 = 0;
if (n <= 1) //如果子叶节点小于一,则直接返回,完成哈夫曼树的构造
return;
int m = 2 * n - 1; //n个叶子节点的哈夫曼树有2n-1个节点
//通过new语法创建哈夫曼树节点
HT = new HTNode[m + 1];
//初始化哈夫曼树中的所有节点
for (int i = 1; i <= m; i++)
{
HT[i].parent = 0;
HT[i].lchild = 0;
HT[i].rchild = 0;
HT[i].vis = 0;
HT[i].len = 0;
HT[i].num = i;
HT[i].weight = 0;
}
for (int i = 1; i <= n; i++)
{
//an[]是创建的结构体数组
//将结构体数组中的数据依次赋值给哈夫曼树中的节点
HT[i].weight = an[i - 1].num;
HT[i].ch = an[i - 1].ch;
}
//总共m个节点,其中有n个叶子节点,则循环从n+1开始,到m截至,对n+1 -- m 中的节点进行排序
for (int i = n + 1; i <= m; i++)
{
Select(HT, i - 1, s1, s2);
//同一个父节点推出两个左右子节点HT[s1],HT[s2]
HT[s1].parent = i;
HT[s2].parent = i;
//父节点的左孩子为s1
HT[i].lchild = s1;
//父节点的右孩子为s2
HT[i].rchild = s2;
//父节点的权重为左孩子的权重加上右孩子的权重
HT[i].weight = HT[s1].weight + HT[s2].weight;
}
int len = HT[m].len;
HT[m].strc[len] = '1';
//根据 左--0,右--1 来进行哈夫曼树的编码
if (HT[m].lchild)
code(HT, 1, "", HT[m].lchild, '0');
if (HT[m].rchild)
code(HT, 1, "", HT[m].rchild, '1');
return;
}
int main()
{
HuffmanTree h;
int n, n1;
char str[700], str2[700];
cout << "请输入字符串(输入0时结束算法)" << endl;
while (cin >> str) //为字符串str完成输入,当输入'0'时结束while循环
{
if (str[0] == '0' && str[1] == '\0')
break;
n1 = 0;
for (int i = 0; i < 27; i++)
{
an[i].num = 0; //初始化所有字母的个数为0
//将an[0-25]分别填放a~z这二十六个字母
an[i].ch = 'a' + i;
}
n = strlen(str); //n为字符串str的长度
for (int i = 0; i < n; i++)
{
//根据输出的字符串str来获取其中每个字母所含的个数
//eg.如果某个str[i] == b ,则str[i]-'a' ==1 -- 根据ASCII码计算,即为an[1].num加一同时an[1]对应的字母字符也是b,相当于记录了str字符串中所含字母b的个数加一
an[str[i] - 'a'].num++;
str2[i] = str[i];
str2[i + 1] = '\0';
}
//根据字符个数从大到小进行排序
sort1(an);
for (int i = 0; i < 26; i++)
{
if (an[i].num != 0)
n1++;//n1统计an中所含的字符数(如果an[i].num == 0 则说明an[i]对应的字符字母不存在)
}
//根据字符的ASCII码值从小到大进行排序
sort2(an, n1);
//创建哈夫曼数(CreateHuffmanTree中包含Select和Code函数)
CreateHuffmanTree(h, n1, str, n1);
//如果字符串str中只有一个字符
if (n1 == 1)
{
h = new HTNode[3];
h[1].weight = n;
h[1].parent = h[1].lchild = h[1].rchild = 0;
h[1].ch = str[0];
h[1].strc[0] = '0';
h[1].strc[1] = '\0';
}
//输出:
cout << "输出为: " << endl;
//输出每个字符在字符串中出现了几次
int f = 0;
for (int i = 0; i < 26; i++)
if (an[i].num > 0)
{
f++;
cout << an[i].ch << ":" << an[i].num;
if (f == n1)
cout << endl;
else
cout << " ";
}
//输出哈夫曼数的储存结构的终态
for (int i = 1; i <= 2 * n1 - 1; i++)
{
cout << i << " " << h[i].weight << " " << h[i].parent << " " << h[i].lchild << " " << h[i].rchild << endl;
}
//输出每个字符的哈夫曼编码
for (int i = 1; i < n1; i++)
cout << h[i].ch << ":" << h[i].strc << " ";
cout << h[n1].ch << ":" << h[n1].strc;
cout << endl;
//输出解码后的字符串
for (int i = 0; i < n; i++)
{
for (int j = 1; j <= n1; j++)
if (h[j].ch == str[i])
cout << h[j].strc;
}
cout << endl;
cout << str << endl;
//重置哈夫曼数中的数据
for (int i = 1; i <= 2 * n1 - 1; i++)
{
h[i].parent = 0;
h[i].lchild = 0;
h[i].rchild = 0;
h[i].vis = 0;
h[i].len = 0;
h[i].num = i;
}
cout << "请继续输入字符串(输入0结束算法)" << endl;
}
return 0;
}
程序运行结果:















 942
942











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









