







文本处理的基本方法
分词
概念
分词就是将连续的字序列按照一定的规范重新组合成词序列的过程。在英文的行文中,单词之间是以空格作为自然分界符的,而中文只是字、句和段能通过明显的分界符来简单划界,唯独词没有一个形式上的分界符。分词过程就是找到这样分界符的过程.
作用
词作为语言语义理解的最小单元, 是人类理解文本语言的基础. 因此也是AI解决NLP领域高阶任务, 如自动问答, 机器翻译, 文本生成的重要基础环节.
jieba
安装
pip install jieba
结巴识别模式
精确模式:
试图将语句最精确的切分,不存在冗余数据,适合做文本分析。
import jieba
content = "感谢您阅读本文"
word_list = jieba.lcut(content,cut_all = False)
word_list
运行结果:
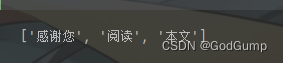
全模式:
将语句中所有可能是词的词语都切分出来,速度很快,但是存在冗余数据。
import jieba
content = "感谢您阅读本文"
word_list = jieba.lcut(content,cut_all = True)
word_list
运行结果:

搜索引擎模式:
在精确模式的基础上,对长词再次进行切分,提高召回率,适合用于搜索引擎分词。
import jieba
content = "感谢您阅读本文"
word_list = jieba.lcut_for_search(content)
word_list
运行结果:
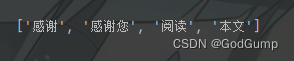
全模式和搜索引擎模式的区别:
全模式是按照逐字遍历作为词语第一个字的方式;
搜索引擎模式只会对精确模式结果中长的词,再按照全模式切分一遍。
向切分依据的字典中添加、删除词语

为什么要搞这个?看这样一个列子:我们在“感谢您阅读本文”前面加上“非常”,怎么加?用join嘛?我们试试
import jieba
content = "感谢您阅读本文"
word_list = "非常".join( jieba.lcut_for_search(content) )
word_list
我们看下结果:
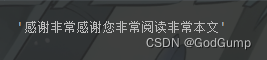
jieba.load_userdict("./user_dict.txt")
content = "感谢您阅读本文"
word_list = jieba.lcut(content, cut_all=True)
word_list = jieba.add_word("非常")
print(word_list)
现在再看看

用户自定义词典(utf-8最佳)
添加自定义词典后, jieba能够准确识别词典中出现的词汇,提升整体的识别准确率
格式:
word1 freq1 word_type1
word表示单词、freq表示频率、word_type表示文本类型。其中只有word没有默认值。
文本:
阅读 1 n
代码:
jieba.load_userdict("./user_dict.txt")
content = "感谢您阅读本文"
word_list = jieba.lcut(content, cut_all=True)
word_list
停用词
停用词就是那些语气词,口头禅之类的,对于研究并无实际贡献,需要删除。可以选择手动删除,也可以使用jieba.analyse里的函数。(由于和字典使用大同小异就不列举了)
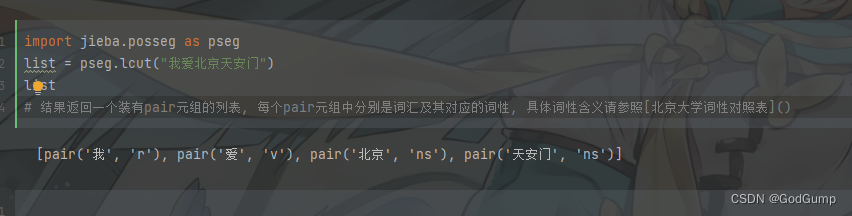
词性标注
顾名思义, 词性标注(Part-Of-Speech tagging, 简称POS)就是标注出一段文本中每个词汇的词性.
文本张量表示
文本张量表示的方法:
one-hot编码
Word2vec
Word Embedding
one-hot编码
import jieba
# 导入keras中的词汇映射器Tokenizer
# keras开源人工神经网络库
from tensorflow.keras.preprocessing.text import Tokenizer
# 导入用于对象保存与加载的joblib
import joblib
# 思路分析 生成onehot
# 1 准备语料 vocabs
# 2 实例化词汇映射器Tokenizer, 使用映射器拟合现有文本数据 (内部生成 index_word word_index)
# 2-1 注意idx序号-1
# 3 查询单词idx 赋值 zero_list,生成onehot
# 4 使用joblib工具保存映射器 joblib.dump()
def dm_onehot_gen():
# 1 准备语料 vocabs
vocabs = {"周杰伦", "陈奕迅", "王力宏", "李宗盛", "吴亦凡", "鹿晗"}
# 2 实例化词汇映射器Tokenizer, 使用映射器拟合现有文本数据 (内部生成 index_word word_index)
# 2-1 注意idx序号-1
mytokenizer = Tokenizer()
mytokenizer.fit_on_texts(vocabs)
# 3 查询单词idx 赋值 zero_list,生成onehot
for vocab in vocabs:
zero_list = [0] * len(vocabs)
idx = mytokenizer.word_index[vocab] - 1
zero_list[idx] = 1
print(vocab, '的onehot编码是', zero_list)
# 4 使用joblib工具保存映射器 joblib.dump()
mypath = './mytokenizer'
joblib.dump(mytokenizer, mypath)
print('保存mytokenizer End')
# 注意5-1 字典没有顺序 onehot编码没有顺序 []-有序 {}-无序 区别
# 注意5-2 字典有的单词才有idx idx从1开始
# 注意5-3 查询没有注册的词会有异常 eg: 狗蛋
print(mytokenizer.word_index)
print(mytokenizer.index_word)
dm_onehot_gen()
报错ImportError: cannot import name ‘joblib’ from ‘sklearn.externals’
请参考:
点我跳转
Word2vec
word2vec是一种流行的将词汇表示成向量的无监督训练方法, 该过程将构建神经网络模型, 将网络参数作为词汇的向量表示, 它包含CBOW和skipgram两种训练模式.
CBOW模式
假设我们给定的训练语料只有一句话: Hope can set you free (愿你自由成长),窗口大小为3,因此模型的第一个训练样本来自Hope can set,因为是CBOW模式,所以将使用Hope和set作为输入,can作为输出,在模型训练时, Hope,can,set等词汇都使用它们的one-hot编码.
skipgram模式
给定一段用于训练的文本语料, 再选定某段长度(窗口)作为研究对象, 使用目标词汇预测上下文词汇.
代码示例
fasttext数据集以及的下载
在这里, 我们将研究英语维基百科的部分网页信息, 它的大小在300M左右。这些语料已经被准备好, 我们可以通过Matt Mahoney的网站下载。
点我下载
# 使用wikifil.pl文件处理脚本来清除XML/HTML格式的内容
# perl wikifil.pl data/enwik9 > data/fil9 #该命令已经执行
fasttext 是 facebook 开源的一个词向量与文本分类工具。下面是该工具包的安装方法
# 训练词向量工具库的安装
# 方法1 简洁版
pip install fasttext
# 方法2:源码安装(推荐)
# 以linux安装为例: 目录切换到虚拟开发环境目录下,再执行git clone 操作
git clone https://github.com/facebookresearch/fastText.git
cd fastText
# 使用pip安装python中的fasttext工具包
sudo pip install .
fasttext的几个简单使用
训练保存加载
# 导入fasttext
import fasttext
def dm_fasttext_train_save_load():
# 1 使用train_unsupervised(无监督训练方法) 训练词向量
mymodel = fasttext.train_unsupervised('../data/fil9')
print('训练词向量 ok')
# 2 save_model()保存已经训练好词向量
# 注意,该行代码执行耗时很长
mymodel.save_model("../data/fil9.bin")
print('保存词向量 ok')
# 3 模型加载
mymodel = fasttext.load_model('../data/fil9.bin')
print('加载词向量 ok')
dm_fasttext_train_save_load()
查看词向量
def dm_fasttext_get_word_vector():
mymodel = fasttext.load_model('./data/fil9.bin')
myvector = mymodel.get_word_vector('the')
print('myvector->', type(myvector), myvector.shape, myvector)
报错:
ValueError:cannot be opened for training fasttext
检查一下是不是路径包含中文
Word Embedding
通过一定的方式将词汇映射到指定维度(一般是更高维度)的空间.
广义的word embedding包括所有密集词汇向量的表示方法,如之前学习的word2vec, 即可认为是word embedding的一种.
狭义的word embedding是指在神经网络中加入的embedding层, 对整个网络进行训练的同时产生的embedding矩阵(embedding层的参数), 这个embedding矩阵就是训练过程中所有输入词汇的向量表示组成的矩阵.
word embedding的可视化分析
import torch
from tensorflow.keras.preprocessing.text import Tokenizer
from torch.utils.tensorboard import SummaryWriter
import jieba
import torch.nn as nn
# 注意:
# fs = tf.io.gfile.get_filesystem(save_path)
# AttributeError: module 'tensorflow._api.v2.io.gfile' has no attribute 'get_filesystem'
# 错误原因分析:
# 1 from tensorboard.compat import tf 使用了tf 如果安装tensorflow,默认会调用它tf的api函数
import tensorflow as tf
import tensorboard as tb
tf.io.gfile = tb.compat.tensorflow_stub.io.gfile
# 实验:nn.Embedding层词向量可视化分析
# 1 对句子分词 word_list
# 2 对句子word2id求my_token_list,对句子文本数值化sentence2id
# 3 创建nn.Embedding层,查看每个token的词向量数据
# 4 创建SummaryWriter对象, 可视化词向量
# 词向量矩阵embd.weight.data 和 词向量单词列表my_token_list添加到SummaryWriter对象中
# summarywriter.add_embedding(embd.weight.data, my_token_list)
# 5 通过tensorboard观察词向量相似性
# 6 也可通过程序,从nn.Embedding层中根据idx拿词向量
def dm02_nnembeding_show():
# 1 对句子分词 word_list
sentence1 = '传智教育是一家上市公司,旗下有黑马程序员品牌。我是在黑马这里学习人工智能'
sentence2 = "我爱自然语言处理"
sentences = [sentence1, sentence2]
word_list = []
for s in sentences:
word_list.append(jieba.lcut(s))
# print('word_list--->', word_list)
# 2 对句子word2id求my_token_list,对句子文本数值化sentence2id
mytokenizer = Tokenizer()
mytokenizer.fit_on_texts(word_list)
# print(mytokenizer.index_word, mytokenizer.word_index)
# 打印my_token_list
my_token_list = mytokenizer.index_word.values()
print('my_token_list-->', my_token_list)
# 打印文本数值化以后的句子
sentence2id = mytokenizer.texts_to_sequences(word_list)
print('sentence2id--->', sentence2id, len(sentence2id))
# 3 创建nn.Embedding层
embd = nn.Embedding(num_embeddings=len(my_token_list), embedding_dim=8)
# print("embd--->", embd)
# print('nn.Embedding层词向量矩阵-->', embd.weight.data, embd.weight.data.shape, type(embd.weight.data))
# 4 创建SummaryWriter对象 词向量矩阵embd.weight.data 和 词向量单词列表my_token_list
summarywriter = SummaryWriter()
summarywriter.add_embedding(embd.weight.data, my_token_list)
summarywriter.close()
# 5 通过tensorboard观察词向量相似性
# cd 程序的当前目录下执行下面的命令
# 启动tensorboard服务 tensorboard --logdir=runs --host 0.0.0.0
# 通过浏览器,查看词向量可视化效果 http://127.0.0.1:6006
print('从nn.Embedding层中根据idx拿词向量')
# # 6 从nn.Embedding层中根据idx拿词向量
for idx in range(len(mytokenizer.index_word)):
tmpvec = embd(torch.tensor(idx))
print('%4s'%(mytokenizer.index_word[idx+1]), tmpvec.detach().numpy())
Warning : load_model does not return WordVectorModel or SupervisedModel any more, but a FastText
点我跳转
当然这里已经加上了补丁
在终端启动tensorboard服务
$ cd ~
$ tensorboard --logdir=runs --host 0.0.0.0
# 通过http://192.168.88.161:6006访问浏览器可视化页面
文件数据分析
文本数据分析的作用
文本数据分析能够有效帮助我们理解数据语料, 快速检查出语料可能存在的问题, 并指导之后模型训练过程中一些超参数的选择。
数据集下载以及说明
中文酒店评论语料:属于二分类的中文情感分析语料, 该语料存放在github上,需要的可以去下载。文件chinese_bar_word_data中
点我下载
其中train.tsv代表训练集, dev.tsv代表验证集, 二者数据样式相同.train.tsv中的数据内容共分为2列, 第一列数据代表具有感情色彩的评论文本; 第二列数据, 0或1, 代表每条文本数据是积极或者消极的评论, 0代表消极, 1代表积极.
查看数据集的01分布情况
# 导入必备工具包
import seaborn as sns
import pandas as pd
import matplotlib.pyplot as plt
# 思路分析 : 获取标签数量分布
# 0 什么标签数量分布:求标签0有多少个 标签1有多少个 标签2有多少个
# 1 设置显示风格plt.style.use('fivethirtyeight')
# 2 pd.read_csv(path, sep='\t') 读训练集 验证集数据
# 3 sns.countplot() 统计label标签的0、1分组数量
# 4 画图展示 plt.title() plt.show()
# 注意1:sns.countplot()相当于select * from tab1 group by
def dm_label_sns_countplot():
# 1 设置显示风格plt.style.use('fivethirtyeight')
plt.style.use('fivethirtyeight')
# 2 pd.read_csv 读训练集 验证集数据
train_data = pd.read_csv(filepath_or_buffer = '../data/chinese_bar_word_data/train.tsv', sep='\t')
dev_data = pd.read_csv(filepath_or_buffer = '../data/chinese_bar_word_data/dev.tsv', sep='\t')
# 3 sns.countplot() 统计label标签的0、1分组数量
sns.countplot(x='label', data = train_data)
# 4 画图展示 plt.title() plt.show()
plt.title('train_label')
plt.show()
# 验证集上标签的数量分布
# 3-2 sns.countplot() 统计label标签的0、1分组数量
sns.countplot(x='label', data = dev_data)
# 4-2 画图展示 plt.title() plt.show()
plt.title('dev_label')
plt.show()
dm_label_sns_countplot()
获取句子长度分布
思路分析 : 获取句子长度分布 -绘制句子长度分布-柱状图
def dm_len_sns_countplot_distplot():
# 1 设置显示风格plt.style.use('fivethirtyeight')
plt.style.use('fivethirtyeight')
# 2 pd.read_csv 读训练集 验证集数据
train_data = pd.read_csv(filepath_or_buffer='../data/chinese_bar_word_data/train.tsv', sep='\t')
dev_data = pd.read_csv(filepath_or_buffer='../data/chinese_bar_word_data/dev.tsv', sep='\t')
# 3 求数据长度列 然后求数据长度的分布
train_data['sentence_length'] = list( map(lambda x: len(x), train_data['sentence']) )
# 4 绘制数据长度分布图-柱状图
sns.countplot(x='sentence_length', data=train_data)
# sns.countplot(x=train_data['sentence_length'])
plt.xticks([]) # x轴上不要提示信息
# plt.title('sentence_length countplot')
plt.show()
# 验证集
# 3 求数据长度列 然后求数据长度的分布
dev_data['sentence_length'] = list(map(lambda x: len(x), dev_data['sentence']))
# 4 绘制数据长度分布图-柱状图
sns.countplot(x='sentence_length', data=dev_data)
# sns.countplot(x=dev_data['sentence_length'])
plt.xticks([]) # x轴上不要提示信息
# plt.title('sentence_length countplot')
plt.show()
dm_len_sns_countplot_distplot()
获取不同词汇总数统计
itertools.chain()
from itertools import chain
x = [ i for i in range(1,6,1) ]
y = ['A','B','C',"D","E"]
z = chain(x, y)
z2 = chain( *[x, y] )
for x in z:
print(x)
print(type(z))
for x in z2:
print(x)
print(type(z2))
总结可以当拼接以后换个容器,这样理解
统计上面数据集的词汇总数
# 导入jieba用于分词
# 导入chain方法用于扁平化列表
import jieba
from itertools import chain
# pd.read_csv 读训练集 验证集数据
train_data = pd.read_csv(filepath_or_buffer='../data/chinese_bar_word_data/train.tsv', sep='\t')
valid_data = pd.read_csv(filepath_or_buffer='../data/chinese_bar_word_data/dev.tsv', sep='\t')
# 进行训练集的句子进行分词, 并统计出不同词汇的总数
train_vocab = set(chain(*map(lambda x: jieba.lcut(x), train_data["sentence"])))
print("训练集共包含不同词汇总数为:", len(train_vocab))
# 进行验证集的句子进行分词, 并统计出不同词汇的总数
valid_vocab = set(chain(*map(lambda x: jieba.lcut(x), valid_data["sentence"])))
print("训练集共包含不同词汇总数为:", len(valid_vocab))
获取训练集高频形容词词云
pip install wordcloud失败
pip install "刚才下载文件的绝对路径"
pip install wordcloud
即可解决问题
关于map的用法
x = [i for i in range(1,4,1)]
def get_doubel(x):
return x**2
# del list
double_list = list( map(get_doubel, x) )
double_list
double_list2 = list( map(lambda x: x ** 2, [1, 2, 3, 4, 5]) )
double_list2
训练集词云实现
# 使用jieba中的词性标注功能
import jieba.posseg as pseg
from wordcloud import WordCloud
# 每句话产生形容词列表
def get_a_list(text):
r = []
# 使用jieba的词性标注方法切分文本 找到形容词存入到列表中返回
for g in pseg.lcut(text):
if g.flag == "a":
r.append(g.word)
return r
# 根据词云列表产生词云
def get_word_cloud(keywords_list):
# 实例化词云生成器对象
wordcloud = WordCloud(font_path="./SimHei.ttf", max_words=100, background_color='white')
# 准备数据
keywords_string = " ".join (keywords_list)
# 产生词云
wordcloud.generate(keywords_string)
# 画图
plt.figure()
plt.imshow(wordcloud, interpolation="bilinear")
plt.axis('off')
plt.show()
# 思路分析 训练集正样本词云 训练集负样本词云
# 1 获得训练集上正样本 p_train_data
# eg: 先使用逻辑==操作检索符合正样本 train_data[train_data['label'] == 1]
# 2 获取正样本的每个句子的形容词 p_a_train_vocab = chain(*map(a,b))
# 3 调用绘制词云函数
def dm_word_cloud():
# 1 获得训练集上正样本p_train_data
# eg: 先使用逻辑==操作检索符合正样本 train_data[train_data['label'] == 1]
train_data = pd.read_csv(filepath_or_buffer='./cn_data/train.tsv', sep='\t')
p_train_data = train_data[train_data['label'] == 1 ]['sentence']
# 2 获取正样本的每个句子的形容词 p_a_train_vocab = chain(*map(a,b))
p_a_train_vocab = chain(*map(lambda x: get_a_list(x) , p_train_data))
# print(p_a_train_vocab)
# print(list(p_a_train_vocab))
# 3 调用绘制词云函数
get_word_cloud(p_a_train_vocab)
print('*' * 60 )
# 训练集负样本词云
n_train_data = train_data[train_data['label'] == 0 ]['sentence']
# 2 获取正样本的每个句子的形容词 p_a_train_vocab = chain(*map(a,b))
n_a_train_vocab = chain(*map(lambda x: get_a_list(x) , n_train_data) )
# print(n_a_dev_vocab)
# print(list(n_a_dev_vocab))
# 3 调用绘制词云函数
get_word_cloud(n_a_train_vocab)
n-gram特征(特征处理)
N-gram 是一种基于统计语言模型的算法,又被称为一阶马尔科夫链。它的基本思想是将文本里面的内容按照字节进行大小为 N 的滑动窗口操作,形成了长度是 N 的字节片段序列。每一个字节片段称为 gram,对所有的 gram 的出现频度进行统计,并且按照事先设定好的阈值进行过滤,形成关键 gram 列表,也就是这个文本的向量特征空间。列表中的每一种 gram 就是一个特征向量维度。
注意:中文(简体繁体通用)、英语均可
处理流程:
1.首先对文档进行粗切分,得到语段序列。
2.对语段序列进行 gram 切分,得到gram 频度列表。并选择频度大于设定阈值的 gram 片段作为特征向量。
3.每个gram 片段就是一个维度,形成特征向量表。















 896
896











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









