






【Pytorch】深度学习快速上手心得
前言
本文环境是在win10系统上搭建的。除了环境搭建,其他内容和Linux系统一致。使用的环境是Pytorch
学习资料:李沫《动手学深度学习》(该书所有代码都有Tensorflow、Pytorch、Mxnet 3个版本)
b站视频:动手学深度学习Pytorch版 (视频和上面的书是对应的)
一、环境安装
1.1 安装Anaconda
环境安装是进行深度学习的基础。一般推荐使用Anaconda来进行python工具包管理。
Anaconda官网
更详细安装教程见以下文章:超详细Anaconda安装教程
1.2 Anaconda 常见指令
- pip升级
python -m pip install --upgrade pip
- conda 换源
常见的镜像源:
https://mirrors.tuna.tsinghua.edu.cn/anaconda/cloud/pytorch/
https://mirrors.tuna.tsinghua.edu.cn/anaconda/pkgs/main/
https://mirrors.tuna.tsinghua.edu.cn/anaconda/pkgs/free/
https://mirrors.tuna.tsinghua.edu.cn/anaconda/cloud/msys2/
添加源指令
conda config --add channels https://mirrors.tuna.tsinghua.edu.cn/anaconda/pkgs/free
conda config --add channels https://mirrors.tuna.tsinghua.edu.cn/anaconda/pkgs/main
conda config --add channels https://mirrors.tuna.tsinghua.edu.cn/anaconda/cloud/pytorch/
conda config --add channels https://mirrors.tuna.tsinghua.edu.cn/anaconda/cloud/msys2/
查看并使源生效
conda config --show channels
conda config --set show_channel_urls yes
- 创建新环境
conda create -n learn python=3.6 // 创建一个名为learn的环境并指定python版本为3.6
- 切换环境
activate + 环境
- 查看所有的环境
conda env list
- 查看当前环境的所有包
conda list // 列出当前环境的所有包
- 其他指令
deactivate + 环境
conda install/remove/update + 库
tf.test.is_gpu_available()
pip install tensorflow-gpu==2.2.0 安装TensorFlow-gpu版本的
activate // 切换到base环境
conda update -n base -c defaults conda 更新conda命令
conda create -n learn python=3 // 创建一个名为learn的环境并指定python版本为3(的最新
版本)
conda env list // 列出conda管理的所有环境
conda list // 列出当前环境的所有包
conda install requests 安装requests包
conda remove requests 卸载requets包
conda remove -n learn --all // 删除learn环境及下属所有包
conda update requests 更新requests包
conda env export > environment.yaml // 导出当前环境的包信息
conda env create -f environment.yaml // 用配置文件创建新的虚拟环境
1.4 Pytorch环境安装
首先创建一个包含python的环境(如果1.2节已经创建完成,可以跳过这步)
conda create -n learn python=3.8 // 创建一个名为learn的环境并指定python版本为3.8
切换到learn环境
activate learn
安装pytorch环境
Pytorch官网有各种环境安装的指令。
本文安装的是Pytorch 1.5.0,python环境使用的是python 3.8
conda install pytorch==1.5.0 torchvision==0.6.0 cudatoolkit=10.1 -c pytorch
1.3 Jupyter安装
本文代码都是在Jupyter上编写并执行的,其安装非常简单,只需一行代码:
conda install jupyter notebook
安装jupyter扩展
pip install jupyter_contrib_nbextensions
更多Jupyter介绍可以看以下文章Jupyter Notebook介绍、安装及使用教程
安装完成后,我们需要将上面的learn内核添加到jupyter中,执行以下3条命令
conda activate learn
然后安装pip install ipykernel
pip install ipykernel
之后还是在这个虚拟环境下输入(下面这行中的learn可以更改你想要的名字)
python -m ipykernel install --name learn
- jupyter 启动
安装完成jupyter后通过以下指令启动。
jupyter notebook
启动成功后,就可以在浏览器中打开了,一般默认的是端口8888。
然后在新建New中就可以选择对应的内核了。

二、一个简单的demo快速入门深度学习
本章节我们将通过一个序列到序列(Seq2Seq)的数据预测的demo,来对深度学习有一个基础的认识。更详细内容可以通过前言里面的知识来学习。
demo代码:链接:https://pan.baidu.com/s/1JRCmj7RTHmUfM6oSlI7PWA
提取码:1234
一般来说,我们在做深度学习时候,可以将代码分为以下几个部分:
1. 环境依赖
2. 数据预处理
3. 数据加载
4. 模型定义
5. 定义损失函数和优化器
6. 训练模型
7. 模型准确度评估
8. 评估结果可视化
下面内容就是按照上面步骤展开。
2.1 环境依赖
首先导入一些基本的numpy和matplotlib绘图依赖
import numpy as np
import os
import torch
import matplotlib.pyplot as plt
from IPython import display
2.2 数据预处理
良好的数据是深度学习的基础。在数据处理前,我们先定义一个绘图方法,方便后续可视化的调用。
def myplot(x, y, label=None, xlimit=None, size=(9, 3), save_path=None, file_name=None):
display.set_matplotlib_formats('svg')
if len(x) != len(y):
raise ValueError('x和y的长度不一致,无法绘制图像')
else:
plt.figure(figsize=size)
if xlimit and isinstance(xlimit, tuple):
plt.xlim(xlimit)
plt.plot(x, y, label=label)
if label and isinstance(label, str):
plt.legend(loc="upper left")
if file_name and save_path:
if not os.path.isdir(save_path):
os.mkdir(save_path)
plt.savefig(os.path.join(save_path,file_name))
plt.show()
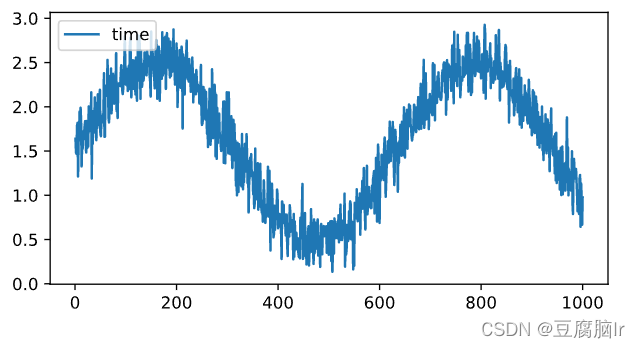
通过sin函数+随机噪声来模拟1000个数据点,最后+1.5保证数据都是正数
T = 1000 # 总共产生1000个点
x= torch.arange(1, T + 1, dtype=torch.float32)
y = torch.sin(0.01 * x) + torch.normal(0, 0.2, (T,)) + 1.5
可视化
myplot(x, y, label='time', size=(6, 3))
2.3 数据加载
在深度学习中,对数据进行预处理时候,当数据量比较大的时候,一般需要将数据集划分成多个batch。
这时可以通过实现一个torch自带的DataSet类,来完成常见的batch划分以及shuffle操作。
关于【Pytorch】DataLoader和 DataSet快速入门 可以查看这篇文章。
定义一个数据集类来对数据进行划分,把数据集划分成训练集和测试集,比例为8:2。
from torch.utils.data import Dataset,DataLoader,TensorDataset
class myDataSet(Dataset):
def __init__(self, data, history_length, predict_length, train_mode):
# 划分训练和测试集比例
self.train_length, self.test_length = 500,500
# 历史数据步长
self.history_length = history_length
# 预测长度
self.predict_length = predict_length
# 训练模式
self.train_mode = train_mode
self.data = data
def __getitem__(self, index: int):
if self.train_mode == 'train':
index = index
elif self.train_mode == 'test':
# test 模式有一个偏移量
index += self.train_length
else:
raise ValueError('train mode {} is not defined '.format(self.train_mode))
data_x, data_y = myDataSet.slice_data(data=self.data,
history_length=self.history_length,
predict_length=self.predict_length,
index=index,
train_mode=self.train_mode)
data_x= myDataSet.to_tensor(data_x).squeeze()
data_y = myDataSet.to_tensor(data_y).squeeze()
return data_x, data_y
def __len__(self) -> int:
if self.train_mode == 'train':
return self.train_length - self.history_length -self.predict_length
elif self.train_mode == 'test':
# 每一个样本都可以测试
return self.test_length - self.predict_length
else:
raise ValueError('train mdoe : {} is not defined'.format(self.train_mode))
@staticmethod
def slice_data(data, history_length, predict_length, index, train_mode): #根据历史长度,下标来划分数据样本
if train_mode == "train":
start_index = index #开始下标就是时间下标本身,这个是闭区间
end_index = index + history_length #结束下标,这个是开区间
elif train_mode == "test":
start_index = index - history_length # 开始下标,这个最后面贴图了,可以帮助理解
end_index = index # 结束下标
else:
raise ValueError(
"train model {} is not defined".format(train_mode))
data_x = data[start_index:end_index] # 不包括end_index
data_y = data[end_index :end_index + predict_length] # 把上面的end_index取上
return data_x, data_y
@staticmethod
def to_tensor(data):
return torch.tensor(data, dtype=torch.float)
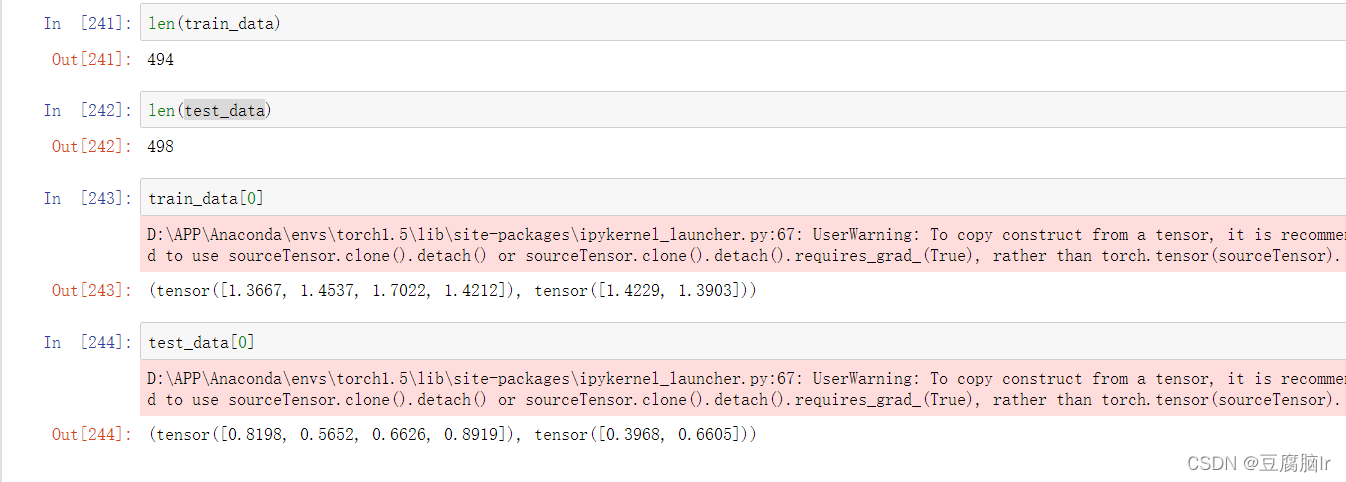
测试数据加载类
# Seq2Seq 过去4个 =》 未来2个数据
train_data = myDataSet(data=y,history_length=4,predict_length=2,train_mode="train")
test_data = myDataSet(data=y,history_length=4,predict_length=2,train_mode="test")
接着将数据送入加载器中。进行分batch_size,和随机打乱的操作。方便后续训练。
train_loader = DataLoader(dataset=train_data, shuffle=True,batch_size=64)
test_loader = DataLoader(dataset=test_data, shuffle=False,batch_size=64)
然后我们验证一下输入格式,是我们想要的格式。

2.4定义模型
import torch.nn as nn
定义一个最简单的多层感知机模型,包含一个输入层,一个输出层,一个隐藏层
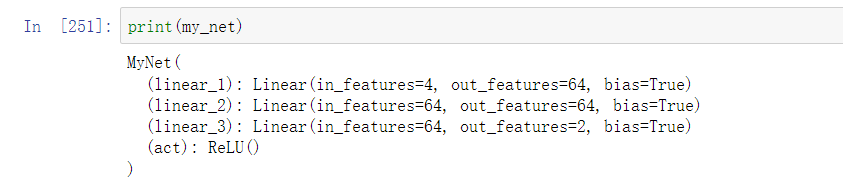
class MyNet(nn.Module):
def __init__(self, in_c, hid_c, out_c):
super(MyNet, self).__init__() # 表示继承父类的所有属性和方法
self.linear_1 = nn.Linear(in_c, hid_c) # 定义一个输入层
self.linear_2 = nn.Linear(hid_c, hid_c) # 定义一个隐藏层
self.linear_3 = nn.Linear(hid_c,out_c) # 输出层
self.act = nn.ReLU() # 定义激活函数
def forward(self, data):
output_1 = self.linear_1(data)
output_1 = self.act(output_1)
output_2 = self.linear_2(output_1)
output_2 = self.act(output_2)
output_3 = self.linear_3(output_2)
output_3 = self.act(output_3)
return output_3
实例化模型,并打印模型结构
my_net = MyNet(in_c =4, hid_c= 64, out_c =2)
2.5 定义优化函数和损失函数
import torch.optim as optim
device = torch.device("cuda" if torch.cuda.is_available() else "cpu") # 定义设备
print(device) # 查看自己电脑是否能使用GPU,能的画会显示 “cuda“
my_net = my_net.to(device) # 模型送入设备
criterion = nn.MSELoss() # 均方损失函数
# 自适应的调整学习率
optimizer = optim.Adam(params=my_net.parameters(), lr=0.001)# 没写学习率,表示使用的是默认的,也就是lr=1e-3
# 第四步:训练+测试
# Train model
Epoch = 20 # 训练的次数
2.6 开始训练
import time
my_net.train() # 打开训练模式,可以更新模型的参数
for epoch in range(Epoch):
epoch_loss = 0.0
start_time = time.time()
# 每一个epoch训练的过程
for data_x, data_y in train_loader:
my_net.zero_grad() # 梯度清零
data_x = data_x.to(device) # 送入GPU
predict_value = my_net(data_x).to(torch.device("cpu")) # 由于标签flow_y在cpu中,所以最后的预测值要放回到cpu中
loss = criterion(predict_value, data_y) # 计算损失,切记这个loss不是标量
epoch_loss += loss.item() # 这里是把一个epoch的损失都加起来,最后再除训练数据长度,用平均loss来表示
loss.backward() # 反向传播
optimizer.step() # 更新参数
end_time = time.time()
print("Epoch: {:04d}, Loss: {:02.4f}, Time: {:02.2f} mins".format(epoch,epoch_loss,
(end_time - start_time) / 60))
从下面训练结果可以看出,由于这个原始数据比较简单(sin函数+随机误差),容易学习到特征,20轮的训练,损失基本上就不下降了。
Epoch: 0000, Loss: 16.0825, Time: 0.00 mins
Epoch: 0001, Loss: 7.6827, Time: 0.00 mins
Epoch: 0002, Loss: 1.8094, Time: 0.00 mins
Epoch: 0003, Loss: 0.8466, Time: 0.00 mins
Epoch: 0004, Loss: 0.9263, Time: 0.00 mins
Epoch: 0005, Loss: 0.5050, Time: 0.00 mins
Epoch: 0006, Loss: 0.5427, Time: 0.00 mins
Epoch: 0007, Loss: 0.4794, Time: 0.00 mins
Epoch: 0008, Loss: 0.4482, Time: 0.00 mins
Epoch: 0009, Loss: 0.4348, Time: 0.00 mins
Epoch: 0010, Loss: 0.4206, Time: 0.00 mins
Epoch: 0011, Loss: 0.4145, Time: 0.00 mins
Epoch: 0012, Loss: 0.4030, Time: 0.00 mins
Epoch: 0013, Loss: 0.3962, Time: 0.00 mins
Epoch: 0014, Loss: 0.3987, Time: 0.00 mins
Epoch: 0015, Loss: 0.3987, Time: 0.00 mins
Epoch: 0016, Loss: 0.3950, Time: 0.00 mins
Epoch: 0017, Loss: 0.3953, Time: 0.00 mins
Epoch: 0018, Loss: 0.3899, Time: 0.00 mins
Epoch: 0019, Loss: 0.3926, Time: 0.00 mins
2.7 模型误差评估
首先我们要获取预测结果。从下面代码中可以看出,获取结果的代码和训练的代码差不多,最主要区别就是 训练的过程中是有模型反向传播和参数更新的,而测试的过程中没有。也就是没有loss.backward() # 反向传播 和optimizer.step() # 更新参数这两行代码,同时模型一定要开启测试模式,即my_net.eval()。
# 开启测试模式,这个模式不会更新模型的参数
my_net.eval()
with torch.no_grad():
# data_target_tensor = data_target_tensor.cpu().numpy()
loader_length = len(test_loader) # number of batch
prediction = [] # 存储所有batch的output
real_labels = [] # 存储所有的batch的真实值
for batch_index, batch_data in enumerate(test_loader):
encoder_inputs, labels = batch_data
encoder_inputs = encoder_inputs.to(device)
outputs = my_net(encoder_inputs).to(torch.device("cpu"))
# 将恢复后的数据存入数组中
real_labels.append(labels)
prediction.append(outputs)
# 每100个batch打印一下,方便知道测试了多少数据了。
if batch_index % 100 == 0:
print('predicting data set batch %s / %s' % (batch_index + 1, loader_length))
# 将list合并成 np数组
prediction = np.concatenate(prediction, 0) # (batch, T', 1)
real_labels = np.concatenate(real_labels, 0) # (batch, T', 1)
print('real_labels:',real_labels.shape)
print('prediction:', prediction.shape)
定义模型评估函数,这里用的最常用的MAE,RMSE,MAPE来评估模型误差。
# 这里的评估方法都是带 掩码mask的,掩盖住原始数据里的0。避免计算相对误差时候,分母为0使得程序报错
def masked_mape_np(y_true, y_pred, null_val=np.nan):
with np.errstate(divide='ignore', invalid='ignore'):
if np.isnan(null_val):
mask = ~np.isnan(y_true)
else:
mask = np.not_equal(y_true, null_val)
mask = mask.astype('float32')
mape = np.abs(np.divide(np.subtract(y_pred, y_true).astype('float32'),y_true))
mape = np.nan_to_num(mask * mape)
return np.mean(mape)
def masked_mae_test(y_true, y_pred, null_val=np.nan):
with np.errstate(divide='ignore', invalid='ignore'):
if np.isnan(null_val):
mask = ~np.isnan(y_true)
else:
mask = np.not_equal(y_true, null_val)
mask = mask.astype('float32')
mae = np.abs(np.subtract(y_pred, y_true).astype('float32'))
mae = np.nan_to_num(mask * mae)
return np.mean(mae)
def masked_rmse_test(y_true, y_pred, null_val=np.nan):
with np.errstate(divide='ignore', invalid='ignore'):
if np.isnan(null_val):
mask = ~np.isnan(y_true)
else:
mask = np.not_equal(y_true, null_val)
mask = mask.astype('float32')
mse = ((y_pred- y_true)**2)
mse = np.nan_to_num(mask * mse)
return np.sqrt(np.mean(mse))
计算误差
# 计算误差
prediction_length = prediction.shape[1]
# 多步预测,评估每一步的误差
for i in range(prediction_length):
assert real_labels.shape[0] == prediction.shape[0]
print('current predict %s points' % (i))
mae = masked_mae_test(real_labels[:, i], prediction[:, i],0.0)
rmse = masked_rmse_test(real_labels[:, i], prediction[ :, i],0.0)
mape = masked_mape_np(real_labels[:, i], prediction[:, i], 0.0)
print('MAE: %.2f' % (mae))
print('RMSE: %.2f' % (rmse))
print('MAPE: %.3f' % (mape))
# 评估整体误差
mae = masked_mae_test(real_labels.reshape(-1, 1), prediction.reshape(-1, 1), 0.0)
rmse = masked_rmse_test(real_labels.reshape(-1, 1), prediction.reshape(-1, 1), 0.0)
mape = masked_mape_np(real_labels.reshape(-1, 1), prediction.reshape(-1, 1), 0)
print('all MAE: %.2f' % (mae))
print('all RMSE: %.2f' % (rmse))
print('all MAPE: %.3f' % (mape))
2.8 评估结果可视化
定义一个可视化绘图函数
def visualize_result(prediction, target, time_step, time_range, title=None):
'''
prediction : 预测值
target : 真实值
time_step : 可视化第几步的预测结果
time_range: 可视化的数据范围
title : 标题
'''
prediction = prediction[:, time_step]
target = target[:, time_step]
plot_prediction = prediction[time_range[0]:time_range[1]]
plot_target = target[time_range[0]:time_range[1]]
plt.figure(figsize=(12, 3))
if title and isinstance(title, str):
plt.title(title)
plt.grid(True, linestyle="-.", linewidth=0.5)
plt.plot(np.array([t for t in range(time_range[1] - time_range[0])]),
plot_prediction,
ls="-",
marker=" ",
color="r")
plt.plot(np.array([t for t in range(time_range[1] - time_range[0])]),
plot_target,
ls="-",
marker=" ",
color="b")
plt.legend(["prediction", "target"], loc="upper left")
plt.axis([
0, time_range[1] - time_range[0],
np.min(np.array([np.min(plot_prediction),
np.min(plot_target)])),
np.max(np.array([np.max(plot_prediction),
np.max(plot_target)]))
])
plt.show()
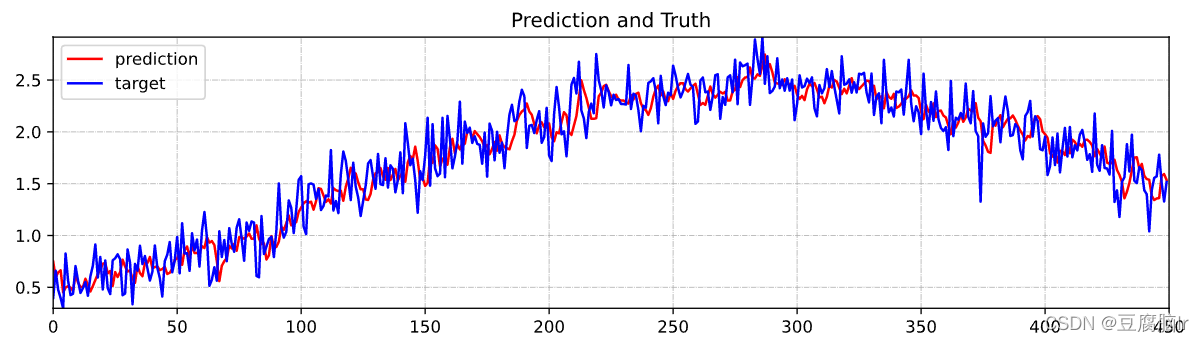
对未来一个时间步的预测可视化:
visualize_result(prediction=prediction,
target=real_labels,
time_step=0,
time_range=[0, 450],
title="Prediction and Truth")
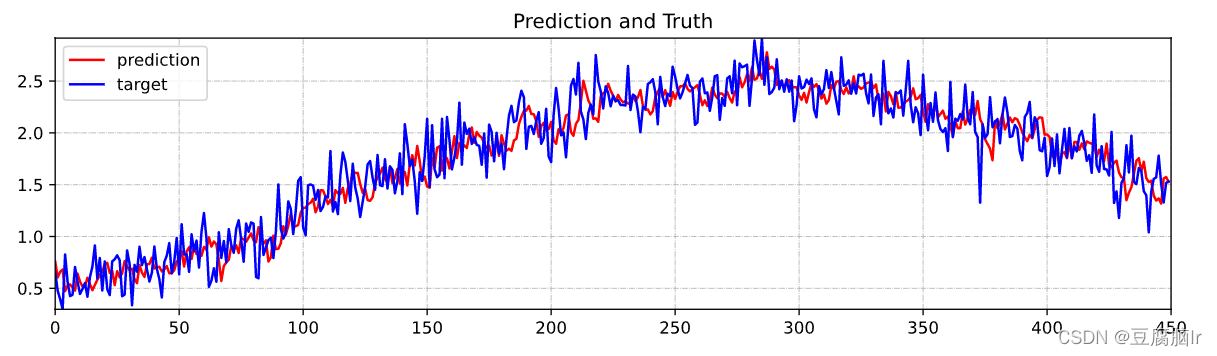
对来来两个时间步的预测结果可视化
3. 总结
本文通过一个简单的demo,基于一个3层感知机,来实现了seq2seq的时间序列预测模型,并在一个随机生成的数据样本上得到了较好的结果。其实更为复杂的模型跟这个demo相比,无非就是网络层变得复杂了一些,数据加载变得复杂了一些,但是殊途同归,万变不离其宗,期望能够一些深度学习的新人一些启发。
















 1274
1274











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









