









文章目录
前言
Transformer 最开始是应用于 NLP 的翻译任务,而后续的实践则证明了 Vision Transformer 也能够用于物体探测等 CV 任务。
本文基于 Vision Transformer,创建了一个不使用卷积、无预设框 anchor free 的物体探测器,下面是用该探测器在 COCO 2017 数据集上做探测任务的效果。




训练环境配置: Keras/TensorFlow 2.9,Python 3.10,WIN 10,Anaconda,Pycharm 以及 Jupyter Lab.
1. Vision Transformer 架构
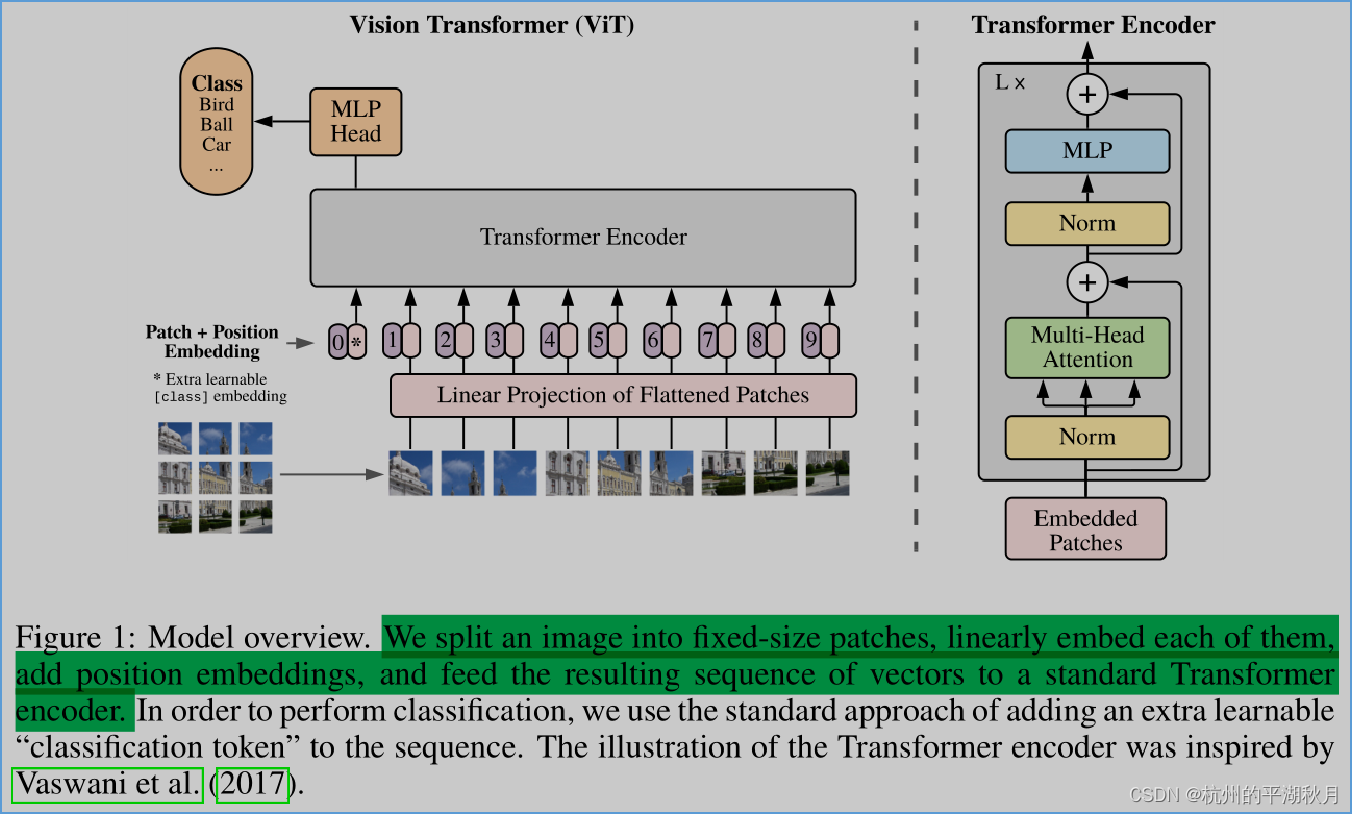
根据原作论文 《An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale》→ https://arxiv.org/abs/2010.11929,Vision Transformer 的架构如下图。
Vision Transformer 主要由 3 大部分组成:
- 第 1 部分是预处理 preprocessing,包括将图片切成小块,并加上位置编码 positional encoding 等操作。
- 第 2 部分是 Transformer Encoder,其作用是获取输入图片的整体信息和局部信息。
- 第 3 部分是 MLP Head,其作用是通过对张量进行不断地变换,最终得到设定的输出张量。
2. Multi-Head Attention
包括 Vision Transformer 在内的各种 Transformer 模型,其最关键的特点,是使用了 Multi-Head Attention 机制。Multi-Head Attention 的主要作用,是把输入的每一个局部信息进行组合,得到整体信息。
而每一个 Multi-Head Attention,都包含了几个 self attention。
2.1 self attention
Transformer 论文中,attention 的表达式如下:
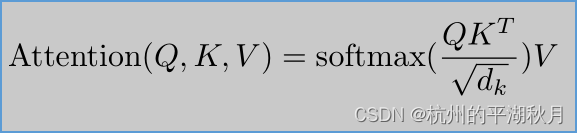
上式是一个很抽象的表达。不过因为 self attention 本身借用了数据库中的名词 query,key,value 进行类比,所以也可以从直观 intuition 的角度来帮助理解。
在将图片切割成多个小块 patches 之后, self attention 操作的 5 个要点如下:
- 对每一个图片块,提出 1 个问题 q(query)。比如问题 q 可能是 “图片块中是否有猫”,“图片块中是否有狗” 等等。
- k(key)是关键字,它可以是表示图片块内的物体。如果一个图片块中有猫或狗,那么它的 key 就可以是 “猫” 或 “狗”。
- 将 q 和 k(key)相乘,得到的是相似度,然后使用 softmax 得到概率值,可以把这个概率值理解为权重。这个概率值(权重)表示的意思是 “对于问题 q,当前图片块 patch 的相关度权重”。
- 最后将概率值(权重)和 v(value)相乘,就得到了 Attention(Q, K, V)。这个 Attention 的值就可以表示 “对于问题 q,各个图片块的相互关系”。并且当 Q, K, V 都相同时,就是 self attention 。
- 很重要的一点是:self attention 不仅表示一个图片块,它也包含了整个图片的信息。这是因为在计算过程中,是把各个图片块的权重和 v 一起进行了计算。
关于 self attention 的详细解释,可以参看吴恩达讲解 Transformer 的几个视频:→ https://www.bilibili.com/video/BV1Co4y1279R?p=34
2.2 Multi-Head Attention
Multi-Head Attention 就是把多个 self attention 拼接 concatenate 起来,再乘以一个权重矩阵 WO 即可。Head 的数量,就是 self attention 的数量。
直观上来理解,Multi-Head Attention 可以表示对图片提出的多个问题,以及对不同问题的答案编码。这些问题可能是 “图片中是否有猫”,“图片的颜色是什么” 等等。
——————————————————————————————————————————————————————————————
在 2021 年 v2 版的 Vision Transformer 论文中,是把 ViT(Vision Transformer) 用于物体分类任务。而如果要把 ViT 用于物体探测任务,并且要设计成无预设框的物体探测器 anchor free object detector,则需要在 Vision Transformer 的基础上,对模型、标签以及损失函数等进行重新设计。
3. 设计模型阶段
要得到一个可用的深度学习模型,需要经过 2 个阶段:
第 1 个阶段是设计模型阶段,该阶段的目标是使得模型具备过拟合 overfitting 的能力(这个阶段也常叫做 optimization)。
第 2 个阶段是大规模训练阶段,目标是提高模型的泛化能力 generalization,一般通过使用海量的数据进行训练,以及数据增强手段来实现。
下面主要介绍设计模型阶段的内容。为了快速展现模型的过拟合能力,只使用了 COCO 2017 数据集的 8 张图片,即训练集的第 8 张到第 15 张图片进行训练。
3.1 选择模型架构
使用 Vision Transformer 作为模型主体。2 个需要改动的地方包括:
- 在前处理部分,因为不是做分类任务,就没有使用 ViT 论文中提到的 “classification token”。
- 在 MLP 部分,同样因为不是分类任务,所以要把输出结果张量设定为 3D 张量,以配合标签的格式。此外,MLP 部分还需要使用 reshape 或 transpose 等操作,来实现对结果张量形状的控制。具体操作可参见我上传的 vision_transformer_detector.py 文件。
3.2 设计训练数据的格式
训练样本因为是图片,所以是 4D 张量。
而标签部分,则需要用 3D 张量。张量形状为 (batch_size, objects_quantity, 6)。其中 objects_quantity 表示需要探测的物体数量。
对于每一个物体,使用一个长度为 6 的向量来表示。第 0 位表示是否有物体,第 1 位表示类别,后面 4 位则用来表示物体框。
这里并没有使用常见的 one-hot 编码来表示类别。我的考虑是:当使用 one-hot 编码来表示 COCO 数据集的 80 个类别时,类别编码将会是一个稀疏矩阵 sparse tensor,其中大部分数值为 0,这并不是一个很高效的编码方式。因此我只使用了 1 个数值来表示类别。
如果使用 one-hot 编码,通常会配合使用多类别交叉熵 Categorical Crossentropy 来计算损失值。这里因为使用了 1 个数值来表示类别,则需要另外设计一个损失函数来计算分类损失。
3.3 损失函数
模型的完整损失值可以表达为下式:
Ltotal = Ldata + Lregularization
其中 Ltotal 为总的损失值。Ldata 代表数据损失,即模型预测值与标签之间的差距导致损失。而 Lregularization 则代表权重的正则 regularization 损失(对权重进行 L1 或 L2 regularization 导致的损失)。
3.3.1 设计 Ldata 部分的损失函数
在 Ldata 部分,Vision Transformer 的损失函数包括 3 部分。这一点和 YOLOv4 系列模型的损失函数类似:
- objectness 损失。即判断物体框内是否有物体,计算对应的损失。用二元交叉熵即可。
- 分类损失 classification loss,需要专门设计。下面单独讨论。
- 物体框的损失。用 CIOU 损失即可。
对于分类损失,常用的是多类别交叉熵 Categorical Crossentropy,但并不是一定要用 Categorical Crossentropy 来计算分类损失。
损失函数的作用,是 表达预测结果和标签之间的差距。因此,只要设计的函数能够很好地表达这个差距,就能够用来做损失函数。下面的实践也证明,用其它函数来计算分类损失,同样可以有较好的效果。
这个分类损失函数,可以表达为:
classification_loss = [c * (xpred - xlabel)]exponent,其中 exponent = 2n (n ≥ 1),即一个偶数。c 是一个常数。
xpred 是预测结果,而 xlabel 则是标签。
上面式子要求 exponent 是一个偶数,是为了保证损失函数关于直线 x = xlabel 对称。
下面是用 plotly 画的几个分类损失函数曲线,其中 xlabel = 8,即标签的类别编号是 8。
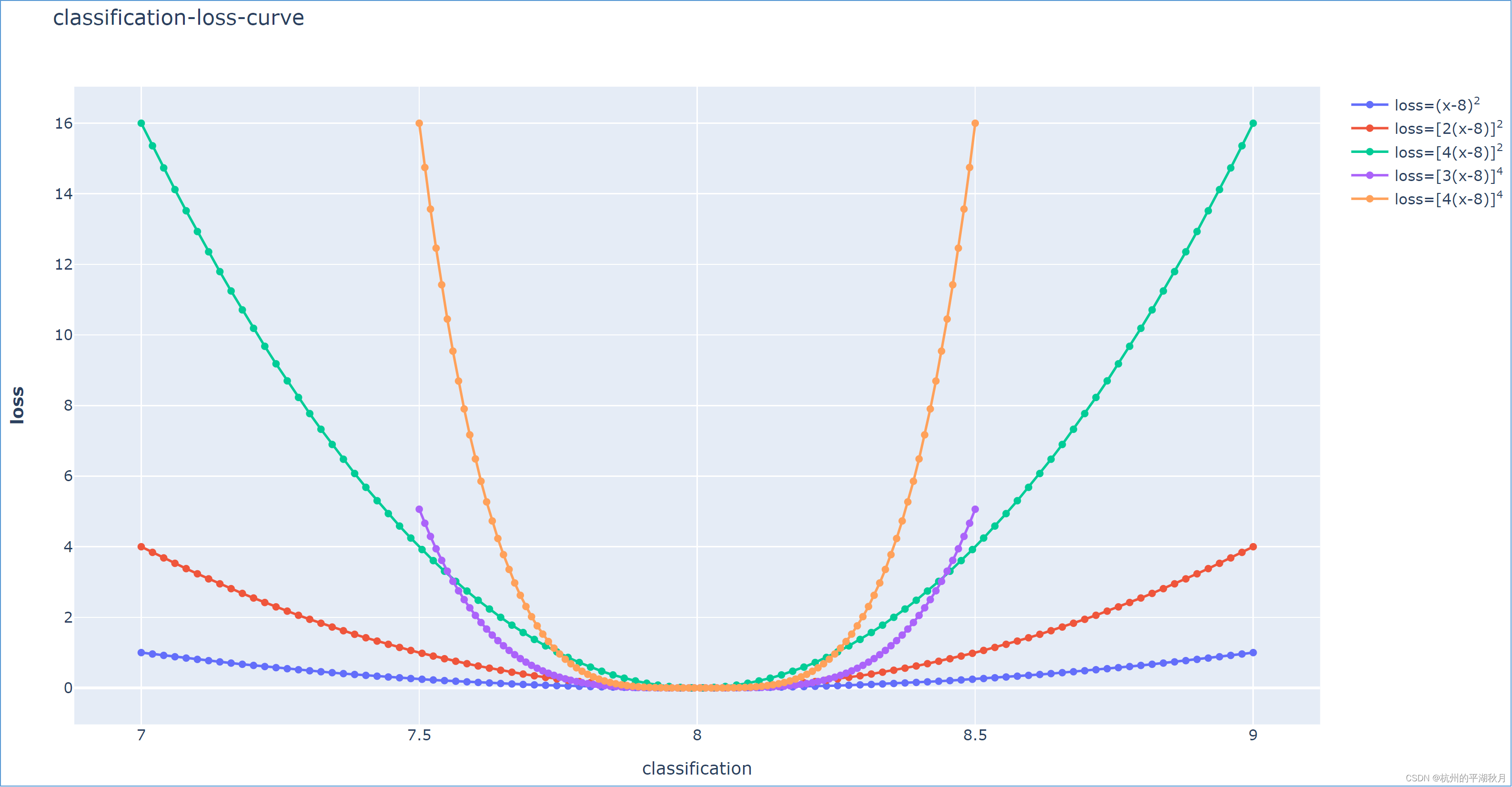
当预测结果和标签的距离大于 0.5 时(| xpred - xlabel | > 0.5),应该把预测结果理解为另一个类别,认为此时预测发生了错误。设计的损失函数,应该使得此时的损失值很大。
反之,当预测结果和标签的距离小于 0.5 时(| xpred - xlabel | < 0.5),则认为此时预测正确。设计的损失函数,应该使得此时的损失值很小。
3.3.2 避免权重的正则损失 Lregularization
使用权重约束 weight constraint 代替 weight regularization(包括 L1 和 L2 regularization),就可以避免权重的正则损失 Lregularization。
之所以要避免权重的正则损失 Lregularization,是因为当权重的正则损失比较大时,它会对训练模型产生干扰。具体解释如下:
损失值的完整表达式是: Ltotal = Ldata + Lregularization
在反向传播的过程中,这两部分损失起的作用不同。Ldata 会使得模型的预测值越来越接近标签,即模型变得越来越准确。而 Lregularization 则会使得权重越来越接近 0(因为只要权重不为 0,就会有 Lregularization 损失。)
假设在训练的某一时刻,模型达到完美,AP 指标为 100%,Ldata = 0,此时权重也达到了最优化。但是因为 Lregularization 始终存在,会使得权重继续不断地发生变化。如果权重的正则损失 Lregularization 比较大,就会使得本来完美的模型再次变得不完美,模型也就永远达不到完美的状态。所以说使用 weight regularization,容易对训练模型产生干扰。
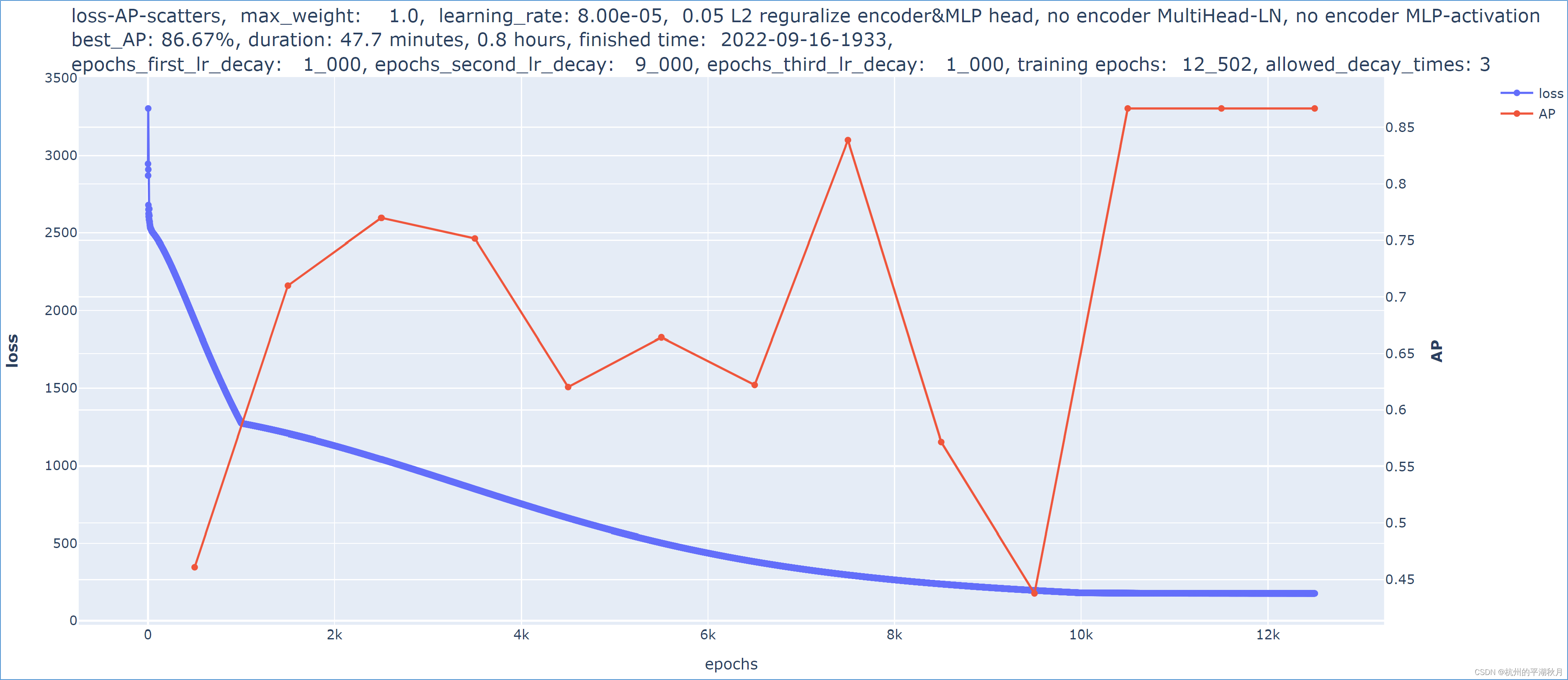
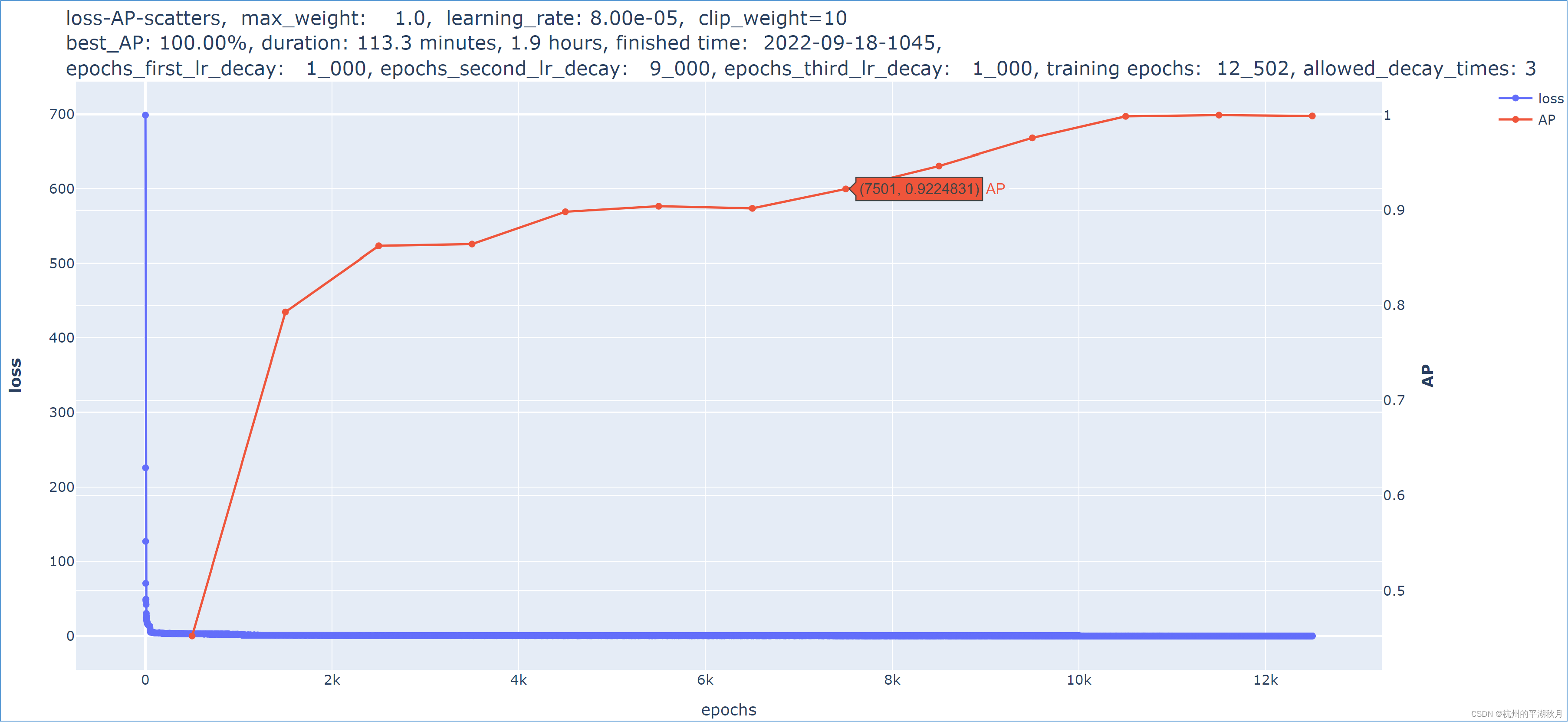
下面是 2 个模型的对比。两个模型基本完全相同,唯一的差异在于:第二个模型对权重使用了 0.05 的 L2 regularization,使得第二个模型的 AP 指标发生了下降。所以从实验的结果也能够看出,当权重的正则损失 Lregularization 较大时,它会对训练模型产生干扰。
这是第一个模型训练过程的损失曲线和指标曲线,AP 指标达到了 100%。
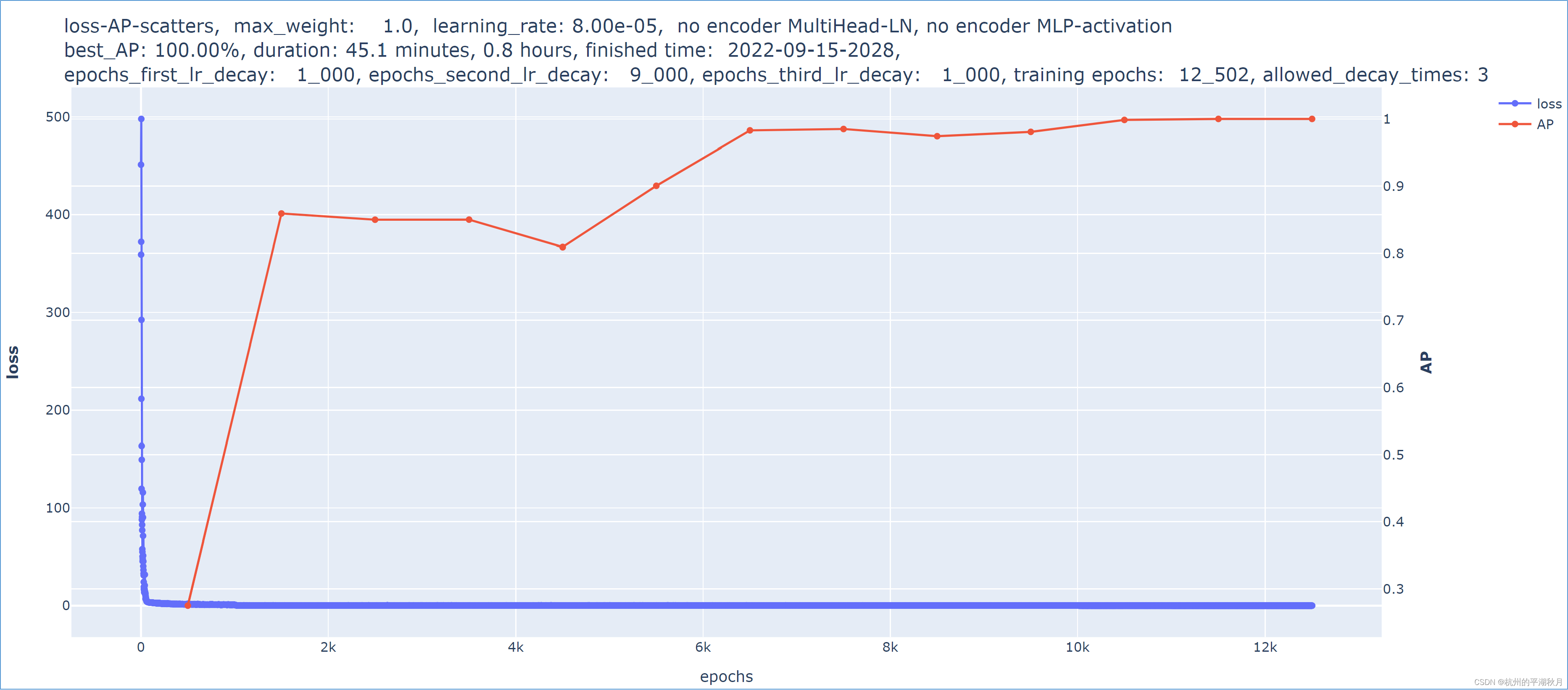
下面是第 2 个模型,对权重使用了 0.05 的 L2 regularization。在所有其它条件都完全相同的情况下,AP 指标只能达到 86.67%。
weight regularization 的作用是限制过大的权重,使得模型更简单。而如果将其替换为权重约束 weight constraint,可以达到同样的效果。
一个使用 keras.constraints.Constraint 进行权重约束的例子如下。使用 tf.clip_by_value,即可把权重限制在一个较小的范围。
class ClipWeight(keras.constraints.Constraint):
"""限制权重在一个固定的范围,避免出现过大权重和 NaN。
Attributes:
min_weight: 一个浮点数,是权重的最小值。
max_weight: 一个浮点数,是权重的最大值。
"""
def __init__(self, max_weight):
self.min_weight = -max_weight
self.max_weight = max_weight
def __call__(self, w):
# 下面 4 行代码,用于找出权重为 NaN 的位置,把 NaN 权重替换为数值 1。
nan_weight = tf.math.is_nan(w)
w = tf.cond(tf.reduce_any(nan_weight),
true_fn=lambda: tf.where(nan_weight, 1.0, w),
false_fn=lambda: w)
return tf.clip_by_value(w, clip_value_min=self.min_weight,
clip_value_max=self.max_weight)
def get_config(self):
config = super().get_config()
config.update({'max_weight': self.max_weight})
return config
3.4 选择指标
对于物体探测器,可以使用 COCO 2017 数据集进行训练,并使用 COCO 的 AP 指标。
为了在训练过程中,看到 AP 指标实时的变化情况,可以用 Keras 创建一个 AP 指标。并且最后可以将训练过程的 AP 指标和损失值一起画出来。
创建 AP 指标的方法,可以参见我的另外一篇文章:→
《用 Keras/TensorFlow 2.8 创建 COCO 的 average precision 指标》,https://blog.csdn.net/drin201312/article/details/123615334
4. 训练过程
4.1 使用 tf.data.Dataset
对训练数据的前处理操作,包括把 COCO 数据集的图片从硬盘加载到内存,并生成训练样本及标签等。
这些前处理操作,涉及到大量的 I/O bound 和 CPU bound 操作,最高效的方式是用 TensorFlow 的 tf.data.Dataset 来做这些前处理。如果是手动编写一个生成器来做这些前处理,效率会比较低。
具体来说,把大量图片从硬盘加载到内存,这是一个很慢的 I/O 过程(相比于 CPU 的计算速度来说),一般可以用异步编程 asynchronous programming 来提高效率。
而把训练数据提供给模型之后,这些前处理操作就处在了等待状态,要一直等待到模型把这批次数据训练结束,才会开始对下一个批次数据做前处理。对这种“等待”的情况,也应该用异步编程 asynchronous programming 来提高效率。
另一方面,把图片转换为张量,并从 COCO 数据集的 annotation 生成标签,则涉及到大量的 CPU 操作,属于 CPU bound 类型的任务。一般可以使用并发多个 Python 进程 processes 的方法,来提高效率。
要使用异步编程,可以用 Python 的 asyncio 模块。而要并发多个 Python 进程,则可以用 Python 的 concurrent.futures 模块。如果想自己手动做这些前处理操作,并且用异步编程和并发多进程来提高效率,可以参见文章:
→ 《Python 中的并发编程和异步编程》, https://blog.csdn.net/drin201312/article/details/126393423
当然,最简便的方法,是直接使用 tf.data.Dataset,可以省去自己很多的编程工作;而且它使用了多进程并发和异步操作,效率很高。tf.data.Dataset 的具体使用方法,可以参看我上传的 vision_transformer_utilities.py 文件。
4.2 用 callback 计算 AP 指标
要想在训练过程中计算实时的 AP 指标,可以用 keras.callbacks.Callback 实现,3 个步骤如下:
- 在 keras.callbacks.Callback 中创建一个 “评价模型” evaluation_model,该 “评价模型” evaluation_model 专门用于计算 AP 指标,并且它的各种参数和正在训练的模型完全一样。
- 将 “评价模型” evaluation_model 运行在 eager 模式下。
- 经过若干个 epochs 训练之后(比如 50 或 100),把正在训练模型的权重,复制给 “评价模型” evaluation_model,再用 “评价模型” 计算一次 AP 指标。
之所以要单独创建一个 “评价模型” evaluation_model,是因为计算 AP 的模型计算图极大,实际无法用图模式来实现。因此要在 eager 模式下,用另外一个 “评价模型” evaluation_model 来计算 AP。
要在 keras.callbacks.Callback 中创建一个模型,可以参见:
→ 《用 Keras/TensorFlow 2.9 创建深度学习模型的方法总结》, https://blog.csdn.net/drin201312/article/details/125098197
4.3 调参
前面的步骤都设置好了之后,就可以开始调参。
调参时可以使用 2 个策略,第一个策略是分组,第二个策略是使用快速排序算法和网格搜索。
4.3.1 分组策略
训练模型中通常会有很多的超参,可以将它们先分成几个组,每一个组的超参和其它组基本无关。然后分组搜索超参,在搜索一个组时,其它组的超参保持不变。
例如某个模型有 20 个超参,可以把它们分成 6 个组,不同组之间的超参没有直接关系。进行超参搜索时,可以先搜索一个组内部的 3 到 4 个超参,其它 5 个组的超参保持不变。这样就可以避免同时搜索 20 个超参,这 20 个超参组合带来的庞大搜索空间的问题。
4.3.2 快速排序算法 quick sort 和网格搜索 grid search
将超参进行分组之后,下一步就是使用快速排序算法和网格搜索。
- 快速排序算法的要点是:每一次搜索之后,都应该把搜索空间缩小一半,这样就能以最快速度找到最佳的超参。
快速排序算法应用最明显的例子,是猜数字游戏。
假设有 1 到 100 之间的 100 个数字,最佳超参是这 100 个数字中的某一个。要求你以最快速度猜出最佳超参。你在猜了一次之后,会告知你猜的结果比最佳超参更大或者更小。
此时使用快速排序算法,就应该每次都猜中间的数字。比如说第一次猜 50,假如反馈的结果是最佳超参比 50 小,那么可以立即将搜索空间缩小一半,变为 [0, 50] 之间。
下一次则直接猜 25,继续把搜索空间缩小一半。如此不断循环,就能以最快速度找出最佳超参。
具体实施时,每次使用 4 或是 5 个数值,把搜索空间均匀地划分为 3 段或 4 段。
例如对于 [1, 100] 这个搜索空间,使用 1, 25, 50, 75, 100,这 5 个数字进行尝试。如果数字 25 使得模型的损失值最小,则可以把搜索空间缩小到 [1, 50] 这个范围,即搜索空间缩小了一半。然后不断重复这个搜索方式即可。
- 网格搜索 grid search。
使用网格搜索的原因在于,有些参数是直接相关的,它们要相互组合才能得出最佳结果。在经过前面参数分组之后,就可以使用网格搜索。
例如损失函数由 3 部分组成:objectness 损失,分类损失和 CIOU 损失。假设这 3 个损失的比例系数为 a, b, c,且 a + b + c = 1。这种情况下,3 个超参 a, b, c 就是直接相关,它们的某一个组合能使得模型的性能最好。所以应该同时搜索这 3 个超参 a, b, c。
和网格搜索相对的是随机搜索 random search。随机搜索的问题是,对于那些相关度很高的超参,它可能会错过超参的最佳组合。比如上面的损失函数比例系数 a, b, c 的情况。
使用网格搜索时,会面临搜索次数较大的问题。此时可以配合使用更少量的数据,以及较少的迭代次数,来加快超参的搜索。
比如对于 COCO 数据集的 12 万张图片,搜索超参时可以使用 50 张或 100 张图片,并且使用 5 或 6 个 epochs。这是因为一个好的超参组合,在图片数量不多,迭代次数也不多的情况下,依然能够最快地降低模型的损失值。
4.4 画出损失和指标
训练结束后,可以用 plotly,画出训练过程的损失值和 AP 指标。如下图。
和 matplotlib 相比,plotly 更为好用。plotly 有 3 个特点:
- 交互显示。即把光标移动到折线图的任一数据点,能够显示该点的 epochs,损失值或指标信息。并且 plotly 能够把损失值和指标画在同一个图上。
- 生成的折线图是一个 html 文件,会在浏览器一个单独的页面中打开。并且在折线图的顶部,能够自定义显示自己需要的汇总信息,比如最佳指标,learning rate,epochs 等等。
- 因为是一个 html 文件,它可以自动保存到硬盘上,方便后续查看对比。
5. ablation test 切除实验
Ablation test 是切除实验,也就是切除掉模型中的某个部分,看模型的性能是否发生变化。如果模型性能基本不变,则说明被切除的部分可能作用不大。
5 个有意思的发现如下:
- position encoding 似乎作用不大。在切除 ablate 掉 position encoding 之后,模型的性能几乎没有变化。这或许是因为,对于 NLP 的语言模型来说,单词的顺序很重要。但是对于图片来说,顺序没有那么重要。即假设一个图片块中有只猫,那么不论该图片块是在图片的左上角还是右下角,都不会改变 “图片块中有猫” 的这个性质。
- Multi-Head Attention 是关键组成。
- 在 Encoder 部分:MLP 前面的 layer normalization 是关键,而 Multi-Head Attention 前面的 layer normalization 则似乎作用不大。
- 在 Encoder 部分的 MLP 中,激活函数 activation 似乎作用不大。
- 在 MLP Head 部分,激活函数 activation 也是关键组成。
需要注意的是,上面 5 个 ablation test 是针对物体探测任务的。如果是其它任务,这些 ablation test 也可能不成立。
这也说明,Vision Transformer 本身,还有很多有趣的地方可以研究。
从 ablation test 可以得到的启发,或许有 2 点:
- Vision Transformer 模型需要通过 Multi-Head Attention,才能获取图片的整体信息。
- 使用了足够的非线性变换之后,才能把模型变为一个足够复杂的方程,使其能够完成 CV 任务。
6. 下载地址
一共有 8 个相关文件,如下图。下载地址是:
Gitee →: https://gitee.com/drin202209/vision_transformer_detector
GitHub →:https://github.com/westlake-moonlight/vision_transformer_detector
6.1 设置文件路径
将 8 个文件放在同一个文件夹,然后要在 2 个 Python 文件中进行设置。
- 在 vision_transformer_utilities.py 中,设置 4 个文件路径:PATH_IMAGE_TRAIN,PATH_IMAGE_VALIDATION,TRAIN_ANNOTATIONS 和 VALIDATION_ANNOTATIONS。它们都是存放 COCO 2017 数据集的文件路径。
- 在 coco_statistics.py 中,设置 5 个文件路径:
PATH_IMAGE_TRAIN,PATH_IMAGE_VALIDATION,它们都是存放 COCO 2017 数据集的文件路径。
另外 3 个路径是 PATH_TRAIN_ANNOTATIONS_DICT,PATH_VAL_ANNOTATIONS_DICT 和 PATH_FULL_CATEGORIES。它们对应的是下载的 8 个文件中的 3 个,这 3 个文件主要用于对 COCO 数据集进行统计。
6.2 使用文件
6.2.1 训练模型
训练模型时,用 Jupyter Lab 打开下载的 vision_transformer_detector.ipynb,直接运行即可。
6.2.2 对 COCO 2017 数据集进行统计
在计算 AP 指标时,计算会比较慢。为了避免浪费时间,可以使用较小的参数来计算 AP,这时就需要对 COCO 数据集进行统计。
具体操作如下:
- 在 vision_transformer_detector.ipynb 中,最底部的 cell,是对 COCO 数据集进行统计的部分。当图片数量大于 1 万张时,它会并发多个 Python 进程来进行计算(如果用单进程计算 COCO 的 12 万张图片,耗时极长)。
- 运行这个 cell,可以看到如下统计结果(这里假设用了 1 万张图片进行训练)。根据统计结果,对 vision_transformer_detector.py 中的模块常量 Constants 进行下面 3 项设置。
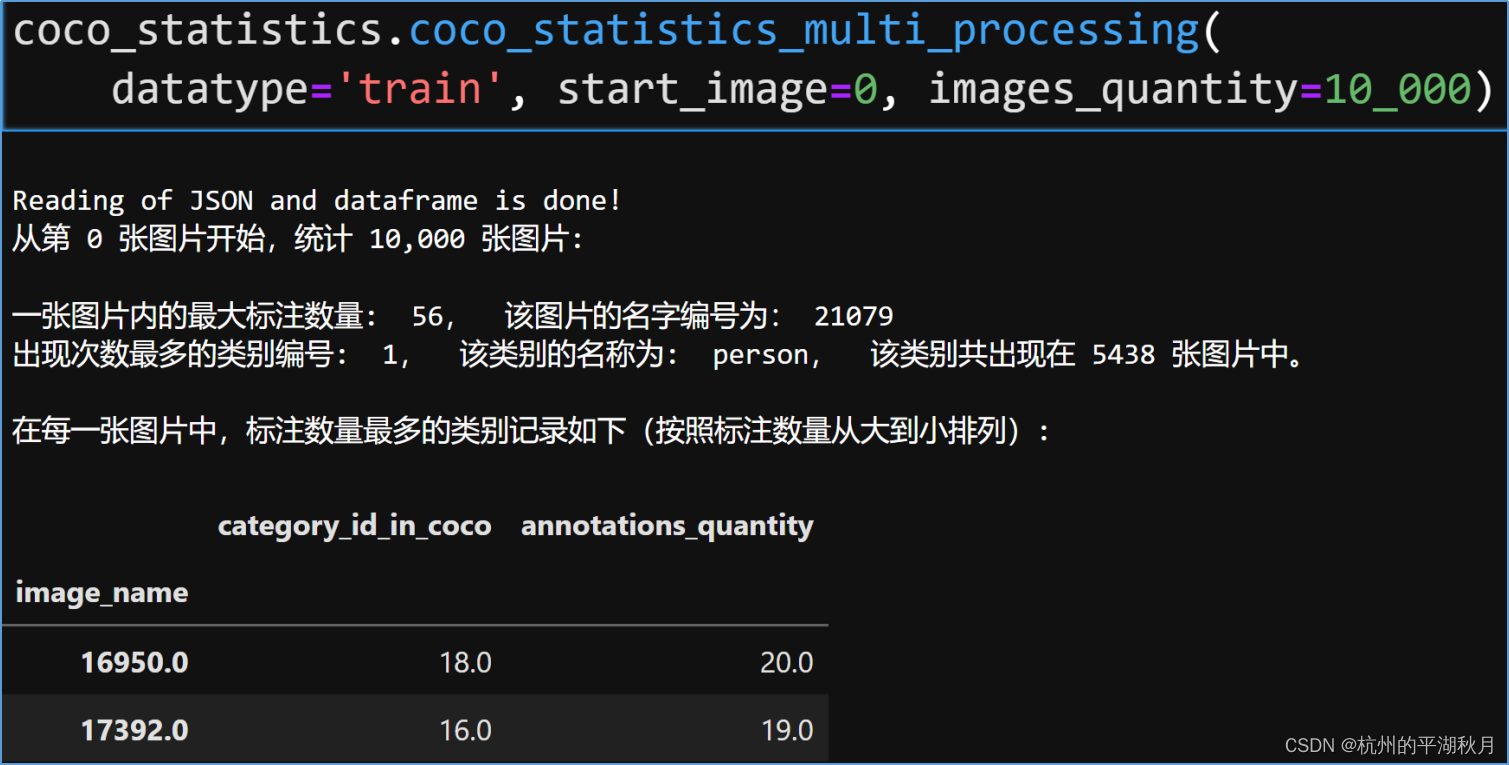
- 设置 MAX_DETECT_OBJECTS_QUANTITY,可以设为 57,大于统计的最大标注数量 56 即可(这个统计数字 56 是针对一张图片,不区分类别的统计)。
- 设置 BBOXES_PER_IMAGE,可以设为 21,大于统计的最大标注数量 20 即可(这个统计数字 20 是在一张图片之内,针对各个类别的统计,比如图中编号为 18 和编号为 16 的类别)。
- 对于 LATEST_RELATED_IMAGES,可以考虑设置一个较小的数,比如 10 或者 20。这是因为 person 这个类别,数量极大,如果使用统计的 5438,会使得 AP 计算极为缓慢(有超级计算机的除外)。
6.2.3 测试文件
testcases_vision_transformer_detector.py 是一个测试文件。里面放了 2 个测试盒 testcase,一个盒子用来测试 AP 指标,另外一个盒子用来测试损失函数。
如果需要修改 AP 指标或者是损失函数,那么在修改完成后,应该用测试盒测试一下,尽量减少程序中的 bug。在企业中,还需要测试团队进行完整的测试。
7. 主要参考资料
7.1 Vision Transformer 论文:
《An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale》→ https://arxiv.org/abs/2010.11929
7.2 Transformer 论文:
《Attention Is All You Need》→ https://arxiv.org/abs/1706.03762
7.3 吴恩达教授讲解的 Multi-Head Attention:
《Self Attention》 → https://www.bilibili.com/video/BV1Co4y1279R?p=34
《Multi-Head Attention》 → https://www.bilibili.com/video/BV1Co4y1279R?p=35
吴恩达教授总是能够深入浅出,用简单的语言解释清楚复杂的概念。非常好!
7.4 《Deep Learning with Python, Second Edition》 →https://www.manning.com/books/deep-learning-with-python-second-edition
在 Transformer 模型中,FRANÇOIS CHOLLET 没有使用原论文硬编码方式的 positonal encoding,而是使用了一个更简单高效的 embedding 向量来进行 positonal encoding,是一个很巧妙的做法。
7.5 Keras 官网示例代码:
《Object detection with Vision Transformers》 → https://keras.io/examples/vision/object_detection_using_vision_transformer/
这个官网代码展示了一个简单的 Vision Transformer 模型,它能够预测出一个物体框。可以作为学习 Vision Transformer 的入门代码。
虽然它只能用于 1 个类别,但是它展现了一种可能,即可以把 Vision Transformer 应用到物体探测任务上。
——————————本文结束——————————















 1073
1073











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









