









1 关系型数据库
数据库排名地址:https://db-engines.com/en/ranking
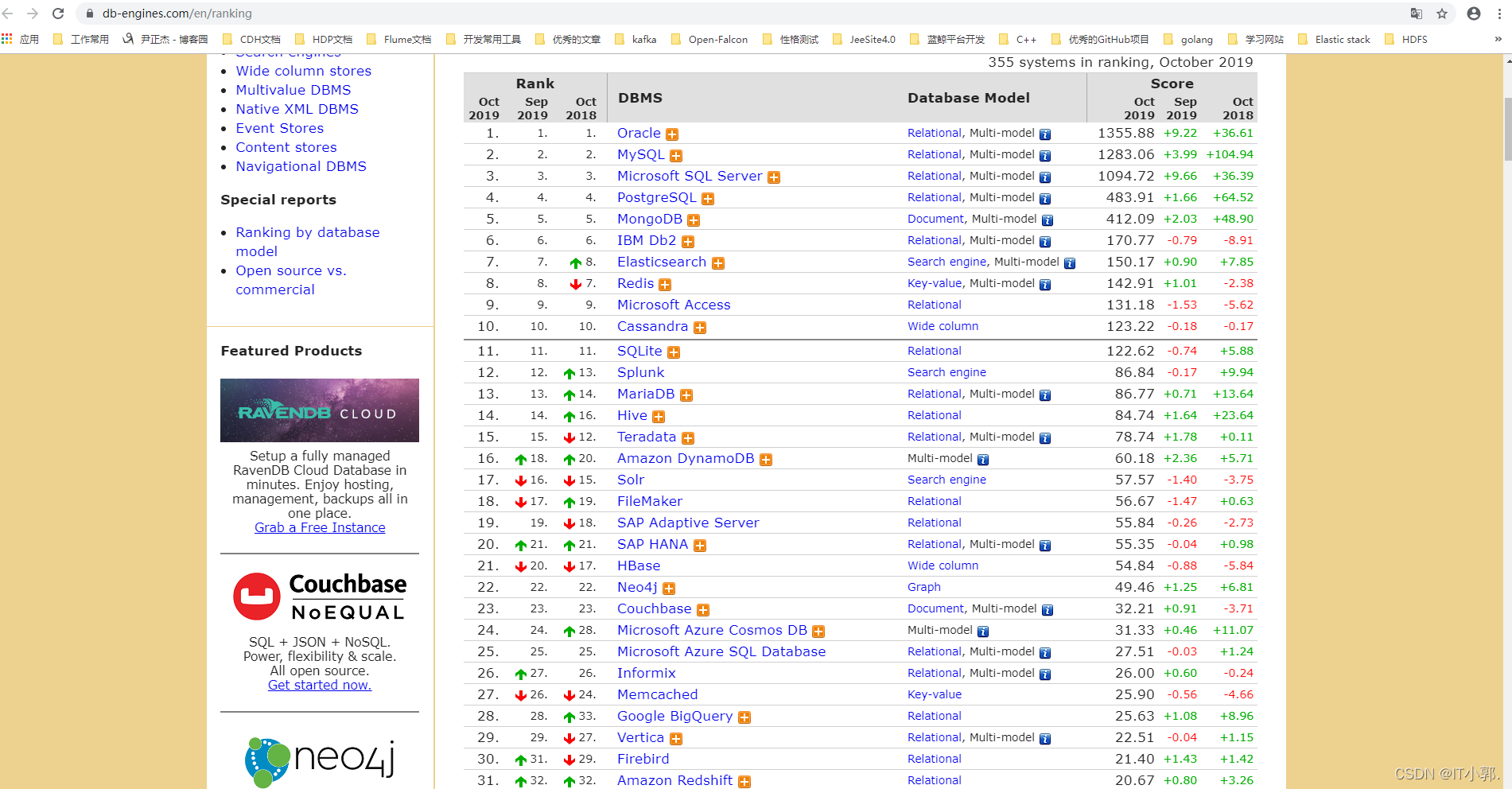
数据库分类

虽然网状数据库和层次数据库已经很好的解决了数据的集中和共享问题,但是在数据库独立性和抽象级别上扔有很大欠缺。用户在对这两种数据库进行存取时,仍然需要明确数据的存储结构,指出存取路径。而关系型数据库就可以较好的解决这些问题。
关系型数据库模型是把复杂的数据结构归结为简单的二元关系(即二维表格形式)。在关系型数据库中,对数据的操作几乎全部建立在一个或多个关系表格上,通过对这些关联的表格分类、合并、连接或选取等运算来实现数据库的管理。
关系型数据库诞生40多年了,从理论产生发展到现实产品,
例如:Oracle和MySQL,Oracle在数据库领域上升到霸主地位,形成每年高达数百亿美元的庞大产业市场。
2 非关系型数据库
2.1 非关系型数据库诞生背景
NoSQL,泛指非关系型的数据库。随着互联网web2.0网站的兴起,传统的关系数据库在应付web2.0网站,特别是超大规模和高并发的SNS类型的web2.0纯动态网站已经显得力不从心,暴露了很多难以克服的问题,而非关系型的数据库则由于其本身的特点得到了非常迅速的发展。NoSql数据库在特定的场景下可以发挥出难以想象的高效率和高性能,它是作为对传统关系型数据库的一个有效的补充。
NoSQL(NoSQL = Not Only SQL ),意即“不仅仅是SQL”,是一项全新的数据库革命性运动,早期
就有人提出,发展至2009年趋势越发高涨。NoSQL的拥护者们提倡运用非关系型的数据存储,相对
于铺天盖地的关系型数据库运用,这一概念无疑是一种全新的思维的注入。
1、NOSQL不是否定关系数据库,而是作为关系数据库的一个重要补充
2、NOSQL为了高性能、高并发而生,忽略影响高性能,高并发的功能
3、NOSQL典型产品memcached (纯内存),redis(持久化缓存),mongodb(文档的数据库)
2.2 非关系型数据库种类
2.2.1 键值存储数据库(key-value)
键值数据库就类似传统语言中使用的哈希表。可以通过key来添加、查询或者删除数据库,因为使用key主键访问,所以会获得很高的性能及扩展性。
键值数据库主要使用一个哈希表,这个表中有一个特定的键和一个指针指向特定的数据。Key/value模型对于IT系统来说的优势在于简单、易部署、高并发。
典型产品:Memcached、Redis、MemcacheDB
有谁在使用:GitHub (Riak)、BestBuy (Riak)、Twitter (Redis和Memcached)、StackOverFlow (Redis)、 Instagram (Redis)、Youtube (Memcached)、Wikipedia(Memcached)
适用的场景:
储存用户信息,比如会话、配置文件、参数、购物车等等。这些信息一般都和ID(键)挂钩,这种情景下键值数据库是个很好的选择。
不适用场景:
取代通过键查询,而是通过值来查询。Key-Value数据库中根本没有通过值查询的途径。
需要储存数据之间的关系。在Key-Value数据库中不能通过两个或以上的键来关联数据。
事务的支持。在Key-Value数据库中故障产生时不可以进行回滚。
(1)Memcached
Memcaced是一个开源的、高性能的、具有分布式内存对象的缓存系统。通过它可以减轻数据库负载,加速动态的
web应用,最初版本由LiveJoumal 的Brad Fitzpatrick在2003年开发完成。目前全球有非常多的用户都在使用它来架构
主机的大负载网站或提升主机的高访问网站的响应速度。注意:Memcache 是这个项目的名称,而Memcached是服
务端的主程序文件名。
缓存一般用来保存一些进程被存取的对象或数据,通过缓存来存取对象或数据要比在磁盘上存取快很多,前者是内
存,后者是磁盘,Memcached是一种纯内存缓存系统,把经常存取的对象或数据缓存在memcached的内存中,这些
被缓存的数据被程序通过API的方式被读取,memcached里面的数据就像一张巨大的hash表,数据以key-value对的方
式存在。Memcached通过缓存经常被存取的对象或数据,从而减轻频繁读取数据库的压力,提高网站的响应速度,构
建出快速更快的可扩展的Web应用。
官网:http://memcached.org/
由于memcached为纯内存缓存软件,一旦重启所有数据都会丢失,因此,新浪网基于Memcached开发了一个开源项目
Memcachedb。通过为Memcached增加Berkeley
DB的特久化存储机制和异步主复制机制,使Memcached具备了事务恢复能力、持久化数据能力和分布式复制能力,memcached非常适合需要超高性能读写速度、持久化保存的应用场景,但是最近几年逐渐被其他的持久化产品替代如Redis
Memcached小结:
1、key-value行数据库
2、纯内存数据库
3、持久化memcachedb(sina)
(2)Redis
和Memcached类似,redis也是一个开源、Linux平台、key-value型存储系统。但redis支持的存储value类型相对更多,包括string(字符串)、list(链表)、set(集合)和zset(有序集合)等。这些数据类型都支持push/pop、add/remove及取交集、并集和差集及更丰富的操作,而且这些操作都是原子性的。为了保证效率,redis的数据都是缓存在内存中。区别是redis会周期性的把更新的数据写入磁盘或者把修改操作写入追加的记录文件,并且在基础上实现了master-slave(主从)同步。
redis是一个高性能的key-value数据库。redis的出现、很大程度补偿了memcached这类key/value存储的不足,在部分场合可以对关系数据库起到很好的补充作用。它提供了Python、Ruby、Erlang、PHP客户端,使用方便。
官方:http://www.redis.io/documentation
redis特点:
1)支持内存缓存,这个功能相当于memcached
2)支持持久化存储,这个功能相当于memcachedb,ttserver
3)数据库类型更丰富。比其他key-value库功能更强
4)支持主从集群、分布式 5)支持队列等特殊功能
应用:缓存从存取memcached更改存取redis
适用场景:
缓存
基础消息队列系统
排行榜系统
计数器使用
社交网站的点赞、粉丝、下拉刷新等应用;
选择注意,Redis的使用场景,是redis适合的解决的问题,也有不适合解决的问题。
从数据规模角度讲,小数据规模使用redis比较合适,大数据规模使用redis不合适;(大数据规模,在一定程度上,可以用SSDB替代redis使用);
从数据冷热角度看,热数据适合放在redis中,冷数据不适合放在redis中。
(3)Cassandra
Apache Cassndra是一套开源分布式Key-Value存储系统。它最初由Facebook开发,用于存储特别大的数据。Facebook目前在使用此系统。
主要特点:
1、分布式
2、基于column的结构化
3、高伸展性
Cassandra的主要特点就是它不是一个数据库,而是由一堆数据库节点共同构成一个分布式网络服务,对Cassandra的一个写操作,会被复制到其他节点上去,对Cassandra的读操作。也会被路由到某个节点上面去读取。
Cassandir是一个混合型的非关系的数据库,类似于Google的BigTable。其主要功能比Dynomie(分布式的key-value存储系统)更丰富,Cassandra最初由Facebook开发,后转变成了开源项目。
2.2.2 列存储(Column-oriented)数据库
列存储数据库将数据存储在列族中,一个列族存储经常被一起查询的相关数据,比如人类,我们经常会查询某个人的姓名和年龄,而不是薪资。这种情况下姓名和年龄会被放到一个列族中,薪资会被放到另一个列族中。
这种数据库通常用来应对分布式存储海量数据。
典型产品:Cassandra、HBase(HBase是Apache的Hadoop项目的子项目)
有谁在使用:Ebay (Cassandra)、Instagram (Cassandra)、NASA (Cassandra)、Twitter (Cassandra and HBase)、Facebook (HBase)、Yahoo!(HBase)
适用的场景:
日志。因为我们可以将数据储存在不同的列中,每个应用程序可以将信息写入自己的列族中。
博客平台。我们储存每个信息到不同的列族中。举个例子,标签可以储存在一个,类别可以在一个,而文章则在另一个。
不适用场景:
如果我们需要ACID事务。Vassandra就不支持事务。
原型设计。如果我们分析Cassandra的数据结构,我们就会发现结构是基于我们期望的数据查询方式而定。在模型设计之初,我们根本不可能去预测它的查询方式,而一旦查询方式改变,我们就必须重新设计列族。
HBase:
1、定位:开源、Linux平台、列存储nosql数据库
可用于海量数据存储、与Hadoop生态圈结合、定位于“大”的列存储nosql数据库
2、特点:
功能:命令执行速度非常看,读写性能可达10万/秒;数据结构是key-value类似字典的功能,可以键过期-缓存,发布订阅-消息系统,简单的事物功能;
部署:相对其他数据库,hbase的部署比较复杂,依赖Hadoop,zookeeper等组件,Hbase集群包括一个mater节点,多个regionServer,zookeeper管理所有regionServer,需要依次部署Hadoop、zookeeper之后,再部署HBASE集群;
使用:用redis-cli客户端连接,一般用简单的 set ,get,del 进行数据管理; 在单实例redis的基础上,进行可以数据持久化,主从复制,高可用和分布式等功能;
监控:在命令行界面有一些常用的命令显示状态和性能,在图形界面方面,有开源监控工具来监控和记录数据库的状态,比如cachecloud;
备份:Hbase一般用作海量数据的仓库,本身通过多层副本来保证数据安全性,不用进行专门的备份
高可用:HBASE集群基于Hadoop,需要依次部署Hadoop单机模式、集群模式、HA模式,通过Hadoop HA实现高可用;
扩展:HBASE以集群形式,依次是单机模式,伪分布模式,完全分布模式,底层基于HDFS,zookeeper可以很好地进行扩展;
3、适用场景:
用于简单数据写入和海量、结构简单数据查询的业务场景;
用于成为其他数据库备份和下沉的数据库;
4、Hbase不适合的场景:
对数据分析需求高,需要能够用sql或者简单的MapReduce实现分析需求的业务场景,不适合用Hbase;
单表数据量,不超过千万时,使用Hbase,体现不出Hbase的优势,而且会比较慢,不适合用Hbase。
2.2.3 面向文档(Document-Oriented)数据库
文档型数据库的灵感是来自于Lotus Notes办公软件,而且它同第一种键值数据库类似。该类型的数据模型是版本化的文档,半结构化的文档以特定的格式存储,比如JSON。文档型数据库可以看作是键值数据库的升级版,允许之间嵌套键值。而且文档型数据库比键值数据库的查询效率更高。
面向文档数据库会将数据以文档形式存储。每个文档都是自包含的数据单元,是一系列数据项的集合。每个数据项都有一个名词与对应值,值既可以是简单的数据类型,如字符串、数字和日期等;也可以是复杂的类型,如有序列表和关联对象。数据存储的最小单位是文档,同一个表中存储的文档属性可以是不同的,数据可以使用XML、JSON或JSONB等多种形式存储。
典型产品:MongoDB、CouchDB
有谁在使用:SAP (MongoDB)、Codecademy (MongoDB)、Foursquare (MongoDB)、NBC News (RavenDB)
适用的场景:
日志。企业环境下,每个应用程序都有不同的日志信息。Document-Oriented数据库并没有固定的模式,所以我们可以使用它储存不同的信息。
分析。鉴于它的弱模式结构,不改变模式下就可以储存不同的度量方法及添加新的度量。
不适用场景:
在不同的文档上添加事务。Document-Oriented数据库并不支持文档间的事务,如果对这方面有需求则不应该选用这个解决方案。
(1)MongoDB
MongoDB是一个介于关系型数据库和非关系型数据库之间的产品,是非关系型数据库当中功能最丰富,最像关系数据库的。他支持的数据库结构非常松散,类似json的bjson格式,因此可以存储比较复杂的数据类型。Mongodb最大的特点是他支持的查询语言非常强大,其语法有点类似于面向对象的查询语言,几乎可以实现类似关系数据库单表查询的绝大部分功能,而且还支持对数据建立索引。
特点: 高性能、易部署、易使用、存储数据非常方便
主要功能特性:
面向集合存储,易存储对象类型的数据 。“面向集合”(Collenction-Orented)意思是数据库被分组存储在数据集中,被称为一个集合(Collenction)每个 集合在数据库中都有一个唯一的标识名,并且可以包含无限数目的文档,集合的概念类似关系型数据库(RDBMS)里的表(table)不同的是它不需要定义任何模式(schema) 模式自由 。模式自由(schema-free)意为着存储在mongodb数据库中的文件,我们不需要知道它的任何结构定义。
1、支持动态查询
2、支持完全索引,包含内部对象
3、支持查询
4、支持复制和故障恢复
5、使用高效的二进制数据存储,包括大型对象
6、自动处理碎片、以支持云计算层次的扩展性
功能:数据文件存储格式为BSON,模式自由,整体架构与关系型数据库有对应关系,具有较好的高可用性和伸缩性,有插件式存储引擎,新版本默认是writedtiger存储引擎;
部署: 部署比较简答,下载软件,设置好配置文件即可启动服务;
使用:不支持SQL语句,使用与SQL对应的json方式管理数据库;
监控:有比较丰富的监控和性能命令,官方有比较完善的图形监控系统,但需要购买;
备份:支持冷备份和热备份,可以使用mongoexport/mongimport进行逻辑备份,也可以使用基于oplog的mongodump/mongorestore物理热备份;
高可用:MongoDB master-slave主从复制:在master节点上加 --master参数,从数据库加 -slave和-source参数,就可以实现同步,这种目前不建议;
适用场景:
网站后台数据库:mongodb非常适合插入、更新与查询,并可以实时复制和高伸缩性,适合更新迭代快、需求变更多、以对象为主的网站应用;
小文件系统:对于json文件,二进制数据,适合用mongodb进行存储和查询
日志分析系统:对于数据量大的日志文件,IM会话消息记录,适合用mongodb来保存和查询;
缓存系统:mongodb数据库也会使用大量的内存,合理的设计,也可以作为缓存系统使用;不过目前缓存系统使用更多的方案是 memcached和redis。
Mongodb不适合的场景:
高度事务性的系统:即传统的OLTP业务,mongodb,乃至其他nosql,对事务性支持都不太好;
传统的统计分析应用:即传统的OLAP业务,需要高度优化的查询方式,mongodb支持不好;
使用SQL语句比较方便的业务:mongodb是json类型的查询方式,虽然也灵活,但不如用SQL方便,如果业务和适合SQL,则就不太合适mongodb了。
2.2.4 图形数据库
图形数据库允许我们将数据以图的方式存储。实体会被作为顶点,而实体之间的关系则会被作为边。比如我们有三个实体,Steve Jobs、Apple和Next,则会有两个“Founded by”的边将Apple和Next连接到Steve Jobs。
典型产品:Neo4J、InforGrid
有谁在使用:Adobe (Neo4J)、Cisco (Neo4J)、T-Mobile (Neo4J)
适用的场景:
在一些关系性强的数据中 推荐引擎。如果我们将数据以图的形式表现,那么将会非常有益于推荐的制定
不适用场景:
不适合的数据模型。图数据库的适用范围很小,因为很少有操作涉及到整个图。















 2938
2938











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











